Εξόρυξη Γνώσης Από Χωρικά Δεδομένα Αγγελική Σκούρα (skoura@ceid.upatras.gr) Παναγιώτης Αντωνέλλης (adonel@ceid.upatras.gr)
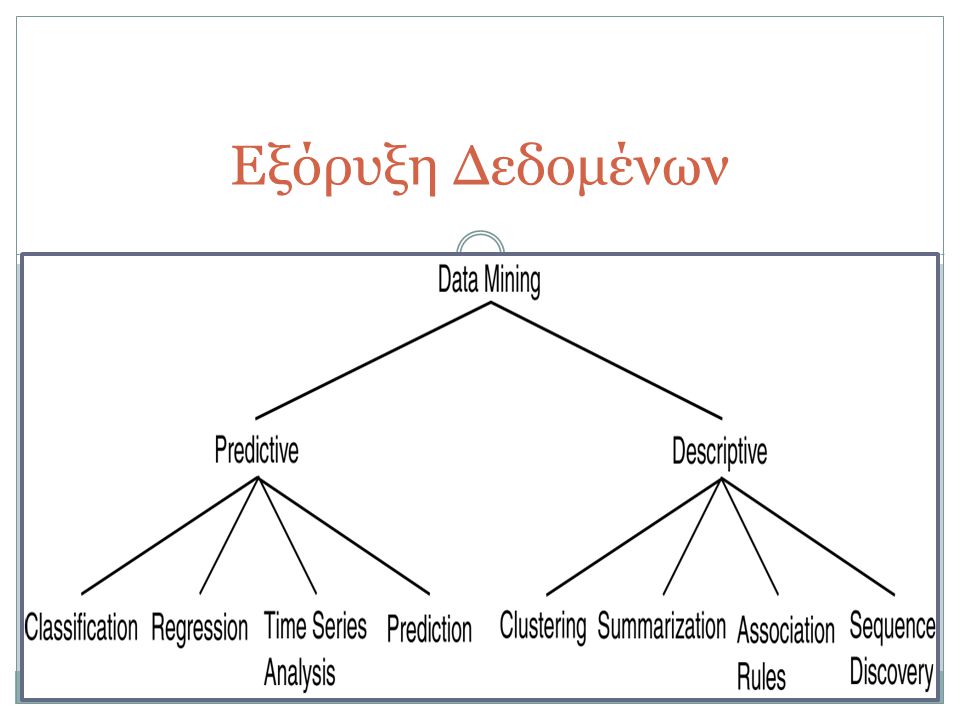
Εξόρυξη Δεδομένων
Χωρικά vs. μη-χωρικά δεδομένα Παραδείγματα μη-χωρικών δεδομένων – Ονόματα, τηλέφωνα, διευθύνσεις email, ... • Παραδείγματα χωρικών δεδομένων – Δημογραφικά δεδομένα – Μετεωρολογικά δεδομένα – Κτηματολόγιο, δασολόγιο, κλπ. – Ιατρικές εικόνες
Χωρικό Αντικείμενο και Χωρική Περιοχή Είναι αντικείμενο με μια χωρική συνιστώσα Περιγράφεται από χωρικά και μη χωρικά γνωρίσματα Σε αυτά μπορεί να περιλαμβάνεται κάποιος τύπος σχετικός με θέση: Γεωγραφικό Μήκος και Πλάτος Ταχυδρομικός Κωδικός Διεύθυνση Η ανάκτηση του αντικειμένου θα πρέπει να είναι δυνατή με χρήση χωρικών ή/και μη χωρικών γνωρισμάτων Χωρική Περιοχή Η περιοχή που εσωκλείει τις τοποθεσίες όλων των χωρικών δεδομένων
Εξόρυξη γνώσης από χωρικά δεδομένα Η χωρική εξόρυξη γνώσης είναι η συστηματική και ημι-αυτόματη αναζήτηση για χρήσιμα, μη-τετριμμένα πρότυπα σε μεγάλες χωρικές βάσεις δεδομένων • Στόχοι Ανάλυσης Χωρικών Δεδομένων: – Deductive Querying, e.g. searching, sorting, overlays – Inductive Mining, e.g. statistics, correlation, clustering, classification.. • Παραδείγματα Εφαρμογών: – Infer land-use classification from satellite imagery – Identify cancer clusters and geographic factors with high correlation – Identify crime hotspots to assign police patrols and social workers
Εφαρμογές εξόρυξης γνώσης από χωρικά δεδομένα Γεωλογία Συστήματα Γεωγραφικών Πληροφοριών (GIS) Περιβαλλοντολογική Επιστήμη Γεωργία Ιατρική Ρομποτική Οπουδήποτε συνδυάζεται η χρονική με τη χωρική διάσταση
Απόσταση μεταξύ Χωρικών Αντικειμένων Σημειακά αντικείμενα Ευκλείδεια, Manhattan Μη σημειακά αντικείμενα Κάθε χωρικό αντικείμενο θεωρείται ως μια συστάδα των σημείων εντός του
Χωρική Εξόρυξη Γνώσης Εξόρυξη Γνώσης από Χωρικά Δεδομένα Χωρική Συσταδοποίηση STING DBSCAN Χωρική Κατηγοριοποίηση Επέκταση του ID3 Χωρικό Δένδρο Απόφασης
STING STatistical Information Grid-based Χρησιμοποιεί μια ιεραρχική τεχνική για τη διαίρεση των χωρικών περιοχών σε ορθογώνια κελιά Κάθε κόμβος στη δομή πλέγματος συνοψίζει την πληροφορία για τα στοιχεία εντός της Μπορεί να θεωρηθεί ως τεχνική ιεραρχικής συσταδοποίησης
STING
Ο Αλγόριθμος STING Build
Παράδειγμα STING Build
Ο Αλγόριθμος STING
STING (Εισαγωγή) Ο STING χρησιμοποιείται για τη συσταδοποίηση χωρικών δεδομένων Ο STING χρησιμοποιεί ένα ιεραρχικό πλέγμα δεδομένων το οποίο διαμερίζει τη χωρική περιοχή Το πλεονέκτημα του STING είναι ότι επεξεργάζεται πολλά κοινά “region oriented” ερωτήματα πάνω σε ένα σύνολο σημείων αποδοτικά Ο στόχος είναι η συσταδοποίηση (ως προς την θέση) των εγγραφών που υπάρχουν σε ένα πίνακα Η τοποθέτηση μιας εγγραφής σε ένα grid cell καθορίζεται πλήρως από τη φυσική του θέση
Ιεραρχική Δομή κάθε Grid Cell Η χωρική περιοχή χωρίζεται σε τετραγωνικά cells (χρησιμοποιώντας latitude και longitude) Κάθε κελί σχηματίζει μια ιεραρχική δομή Αυτό σημαίνει ότι κάθε κελί στο υψηλότερο επίπεδο διαχωρίζεται σε 4 μικρότερα κελιά στο χαμηλότερο επίπεδο Με άλλα λόγια, κάθε κελί στο i-οστό επίπεδο (εκτός από τα φύλλα) έχει 4 παιδία στο i+1 επίπεδο Η ένωση των 4 παιδιών-cells θα επιστρέψει το γονικό κελί του προηγούμενου επιπέδου
Ιεραρχική Δομή κάθε Grid Cell Το μέγεθος των cells του επιπέδου των φύλλων και το πλήθος των επιπέδων εξαρτάται από το βαθμό «κοκοποίησης» (granularity) που επιθυμεί ο χρήστης Γιατί χρειάζεται η ιεραρχική δομή των κελιών? Τα χρειαζόμαστε για να παραχθεί μια καλύτερη granularity, ή υψηλότερη ανάλυση
Η Ιεραρχική Δομή της Συσταδοποίησης Sting
Στατιστικοί Παράμετροι Για κάθε κελί σε κάθε επίπεδο, έχουμε γνωρίσματα εξαρτώμενα και ανεξάρτητα των παραμέτρων Attribute Independent Parameter: Count : number of records in this cell Attribute Dependent Parameter: We are assuming that our attribute values are real numbers
Στατιστικές Παράμετροι Για κάθε γνώρισμα κάθε κελιού, αποθηκεύονται οι ακόλουθες παράμετροι: M mean of all values of each attribute in this cell S Standard Deviation of all values of each attribute in this cell Min The minimum value for each attribute in this cell Max The maximum value for each attribute in this cell Distribution The type of distribution that the attribute value in this cell follows. (e.g. normal, exponential, etc.) None is assigned to “Distribution” if the distribution is unknown
Αποθήκευση Στατιστικών Παραμέτρων Η στατιστική πληροφορία σχετικά με τα γνωρίσματα σε κάθε grid cell, για κάθε επίπεδο προ-υπολογίζονται και αποθηκεύονται χειρωνακτικά Οι στατιστικές παράμετροι για τα κελιά του χαμηλότατου επιπέδου υπολογίζονται κατευθείαν από τις τιμές που υπάρχουν στον πίνακα Οι στατιστικές παράμετροι για τα κελιά όλων των άλλων επιπέδων υπολογίζονται από τα αντίστοιχα κελιά των παιδιών του χαμηλότερου επιπέδου
Επεξεργασία Ερωτημάτων Ο STING μπορεί να απαντήσει αρκετά ερωτήματα, (ιδίως χωρικά ερωτήματα) αποδοτικά, διότι δεν χρειάζεται να αποκτήσουμε πρόσβαση στην πλήρη βάση δεδομένων Πως επεξεργάζονται τα ερωτήματα? Χρησιμοποιούμε μια top-down προσέγγιση Ξεκινάμε από ένα προ-επιλεγμένο επίπεδο Το προ-επιλεγμένο επίπεδο δεν είναι απαραίτητα το πιο ψηλό επίπεδο Για κάθε κελί του τρέχοντος επιπέδου, υπολογίζεται το confidence interval (ή εύρος πιθανότητας) που αντανακλά τα σχετικά κελία με το δεδομένο ερώτημα
Επεξεργασία Ερωτημάτων Το confidence interval υπολογίζεται χρησιμοποιώντας τις στατιστικές παραμέτρους κάθε κελιού Απομάκρυνση μη σχετικών κελιών από επιπλέον επεξεργασία Όταν ολοκληρωθεί η επεξεργασία του τρέχοντος επιπέδου, συνέχισε στο επόμενο, πιο χαμηλό, επίπεδο Η επεξεργασία του επόμενου, πιο χαμηλού, επιπέδου εξετάζει τα υπόλοιπα σχετικά κελιά Η διαδικασία αυτή επαναλαμβάνεται μέχρι να φτάσουμε σε χαμηλότατο επίπεδο
Διάφορα Επίπεδα Grid κατά την επεξεργασία ερωτήματος
Απλά Παραδείγματα Ερωτημάτων Υπόθεσε ότι η χωρική περιοχή είναι ένας χάρτης των περιοχών Ρίου, Αγυιάς και Αγ. Σοφίας Οι εγγραφές μας αναπαριστούν διαμερίσματα που βρίσκονται στην παραπάνω χωρική περιοχή Ερώτημα: “ Βρες όλα τα διαμερίσματα που είναι προς ενοικίαση κοντά (10 χιλιόμετρα) στο Πανεπιστήμιο Πατρών και που το εύρος ενοικίου κυμαίνεται από €400 έως €600 ”
Πλεονεκτήματα και Μειονεκτήματα τουSTING Πολύ αποδοτικός Η υπολογιστική πολυπλοκότητα είναι O(k) όπου k είναι το πλήθος των grid cells του χαμηλότατου επιπέδου. Συνήθως k << N, όπου N είναι το πλήθος των εγγραφών Ο STING είναι μια προσέγγιση ανεξάρτητη του ερωτήματος, αφού η στατιστική πληροφορία υπάρχει ανεξάρτητα από τα ερωτήματα Μειονεκτήματα Όλα τα όρια των συστάδων είναι είτε οριζόντια είτε κάθετα. Δεν υπάρχουν διαγώνια
Χωρική Κατηγοριοποίηση Στοχεύει στη διαμέριση συνόλων χωρικών αντικειμένων Μπορεί να γίνει κατηγοριοποίηση με χρήση μη χωρικών ή/και χωρικών γνωρισμάτων Τεχνικές γενίκευσης και προοδευτικής βελτίωσης μπορούν να χρησιμοποιηθούν
Επέκταση του ID3 Γράφος Γειτνίασης Ο ορισμός του «γείτονα» ποικίλει Κόμβοι – αντικείμενα Ακμές – συνδέουν γείτονες Ο ορισμός του «γείτονα» ποικίλει Μπορεί να οριστεί βάσει μιας μετρικής απόστασης μεταξύ των χωρικών αντικειμένων Ο ID3 για τους σκοπούς κατηγοριοποίησης υπολογίζει όχι μόνο τα μη χωρικά γνωρίσματα του αντικείμενου-στόχου αλλά και των γειτονικών αντικειμένων
Δένδρο Χωρικής Απόφασης Παρόμοια προσέγγιση με αυτή που χρησιμοποιείται στους κανόνες χωρικών συσχετίσεων Η ιδέα βασίζεται στο ότι τα χωρικά αντικείμενα μπορούν να περιγραφούν βάση των αντικειμένων που είναι κοντά σε αυτά – Ενδιάμεση Ζώνη (buffer) Περιγραφή των κλάσεων βασισμένη σε μια συνάθροιση των πιο σχετικών κατηγορημάτων για κοντινά αντικείμενα
Ο Αλγόριθμος του Δένδρου Χωρικής Απόφασης
Χωρική Συσταδοποίηση Εντοπισμός συστάδων από διαφορετικά σχήματα Ένας αλγόριθμος που δουλεύει χρησιμοποιώντας κέντρα βάρους και απλές μετρήσεις απόστασης πιθανόν δεν θα είναι σε θέση να αναγνωρίζει ασυνήθιστα σχήματα Οι συστάδες πρέπει να προκύπτουν ανεξάρτητα της σειράς με την οποία εξετάστηκαν τα σημεία στο χώρο
DBCLASD Επέκταση του αλγορίθμου DBSCAN, Distribution Based Clustering of LArge Spatial Databases (συσταδοποίηση μεγάλων βάσεων χωρικών δεδομένων βασισμένη σε κατανομές) Υποθέτει ότι τα στοιχεία εντός μιας συστάδας είναι ομοιόμορφα κατανεμημένα Επιχειρεί να προσδιορίσει την κατανομή που ικανοποιείται από τις αποστάσεις μεταξύ πλησιέστερων γειτόνων Στοιχεία προστίθενται στη συστάδα, όσο το σύνολο των πλησιέστερων – βάσει της απόστασης – γειτόνων, ικανοποιεί την υπόθεση της ομοιόμορφης κατανομής
Ο Αλγόριθμος DBCLASD
Αρχιτεκτονικές GIS 1η εναλλακτική: Δύο βάσεις δεδομένων : μία χωρική και μια θεματική (σχεσιακή) Αρκετά διαδεδομένη (ArcGIS, MapInfo,…)
Αρχιτεκτονικές GIS 2η εναλλακτική: Ένα εκτεταμένο αντικειμενοστραφές ΣΔΒΔ (objectrelational DBMS) φιλοξενεί και διαχειρίζεται χωρικά και θεματικά δεδομένα – π.χ. Oracle Spatial Cartridge, Informix Spatial Datablade, Microsoft SpatialWare
Υποστήριξη Spatial Data Types σε DBMS – Υποστηρίζουν απλούς τύπους δεδομένων, π.χ. number, varchar[], date – Υποστήριξη χωρικών δεδομένων μπορεί να γίνει απλοϊκά Π.χ. ένα σημείο ως δύο αριθμοί, ένα πολύγωνο ως ... Πέρα από τα σχεσιακά DBMS Object oriented (OO) vs. Object relational (OR) DBMS Υποστηρίζουν abstract data types (ADT’s) που ορίζονται από το χρήστη Οπότε είναι εφικτή η προσθήκη χωρικών τύπων δεδομένων (π.χ. polygon)
Εφαρμογή Χωρικής Κατηγοριοποίησης σε ιατρικές εικόνες Ένα δίκτυο αγωγών στο μαστό: (a) γαλακτόγραμμα με a contrast-enhanced δίκτυο αγωγών, (b) μέρος του γαλακτογράμματος που δείχνει μεγαλύτερο το δίκτυο αγωγών, (c) το δίκτυο 1 2 7 6 3 4 5 10 11 12 9 8 (a) (b) (c) Prufer {1 2 2 6 6 6 1 1 4 4 4 } Προεπεξεργασία (προσδιορισμός ορίων χωρικών περιοχών, σκελετοποίηση, κανονικοποίηση (ισόμορφα δένδρα) Labeling και αναπαράσταση δέντρων με σειρές χαρακτήρων – κωδικοποίηση Prüfer [ V. Megalooikonomou, D. Kontos, J. Danglemaier, A. Javadi, P. A. Bakic, A.D.A. Maidment, Proceedings of the SPIE Conference on Medical Imaging, 2006.]
Ποσοτικός Χαρακτηρισμός Δενδροειδών δομών και Ταξινόμηση … αναπαράσταση δέντρων με σειρές χαρακτήρων Χρήση τεχνικών tf-idf εξόρυξης γνώσης από κείμενα για ανάθεση βάρους σπουδαιότητας σε κάθε όρο- label To βάρoς wij του όρου i στη σειρά j προσδιορίζεται ως εξής: wij = tfij idfi = tfij log2 (N/ dfi) όπου fij είναι η συχνότητα εμφάνισης του όρου i στη σειρά j, tfij = fij / max{fij} dfi = αριθμός των σειρών που περιλαμβάνουν τον όρο i, idfi = αντίστροφο της dfi, = log2 (N/ dfi) και N: ο συνολικός αριθμός σειρών H κάθε σειρά αναπαρίστανται ως ένα t-dimensional διάνυσμα: dj = (w1j, w2j, …,wtj), όπου t = |vocabulary|=διάσταση Δύο σειρές είναι παρεμφερείς με βάση το cosine similarity measure των διανυσμάτων που υπολογίζεται ως εξής: CosSim(dj, q) =
Ποσοτικός Χαρακτηρισμός Δενδροειδών δομών και Ταξινόμηση Similarity searches: Υπολογίζουμε το pairwise cosine distance matrix για όλα τα tf-idf διανύσματα. Χρησιμοποιούμε κάθε δένδρο (δηλ. tf-idf διάνυσμα) σαν query και βρίσκουμε τα k πιο όμοια δέντρα με βάση το cosine distance matrix. Precision: το ποσοστό των σχετικών δένδρων (relevant trees) μεταξύ αυτών που βρέθηκαν – μέσος όρος για όλα τα similarity queries που κάναμε (σχετικά: τα δένδρα που ανήκουν στην ίδια ομάδα με το query tree (NF vs. RF)). Prufer Encoding k Precision NF RF Total 1 100% 100 % 2 90.00 % 70.83 % 79.55 % 3 80.00 % 66.67 % 72.73 % 4 72.50 % 64.58 % 68.18 % 5 68.00 % 65.00 % 66.36 %
Ευχαριστώ…