Κατέβασμα παρουσίασης
Η παρουσίαση φορτώνεται. Παρακαλείστε να περιμένετε

1
Τι είναι η Κατανομή (Distribution)
Η στατιστική μέθοδος για την περιγραφή/συστηματοποίηση μιας ομάδας δεδομένων. Η πιο συνήθης μορφή κατανομής για αυτό τον σκοπό και την παρουσίαση δεδομένων είναι η κατανομή συχνότητας: Δείχνει πόσο συχνά (πόσες φορές) απαντάται η κάθε τιμή της κατανομής. Αυτό μπορεί να φανεί είτε από τη συγκεντρωτική παρουσίαση των δεδομένων σε ένα πίνακα, είτε από τη γραφική παράσταση των δεδομένων όπου έχω συχνότητα στον άξονα των y και τις τιμές στον άξονα των x.
 απαντάται η κάθε τιμή της κατανομής. Αυτό μπορεί να φανεί είτε από τη συγκεντρωτική παρουσίαση των δεδομένων σε ένα πίνακα, είτε από τη γραφική παράσταση των δεδομένων όπου έχω συχνότητα στον άξονα των y και τις τιμές στον άξονα των x.")
8
Ο παρακάτω πίνακας δείχνει τους αριθμούς λαθών σε κάθε συνθήκη
Παράδειγμα Κατανομής Ο παρακάτω πίνακας δείχνει τους αριθμούς λαθών σε κάθε συνθήκη Subject Two Beers Five Beers No Beer 1 5 8 2 4 9 3 7 6 12 15 10

9
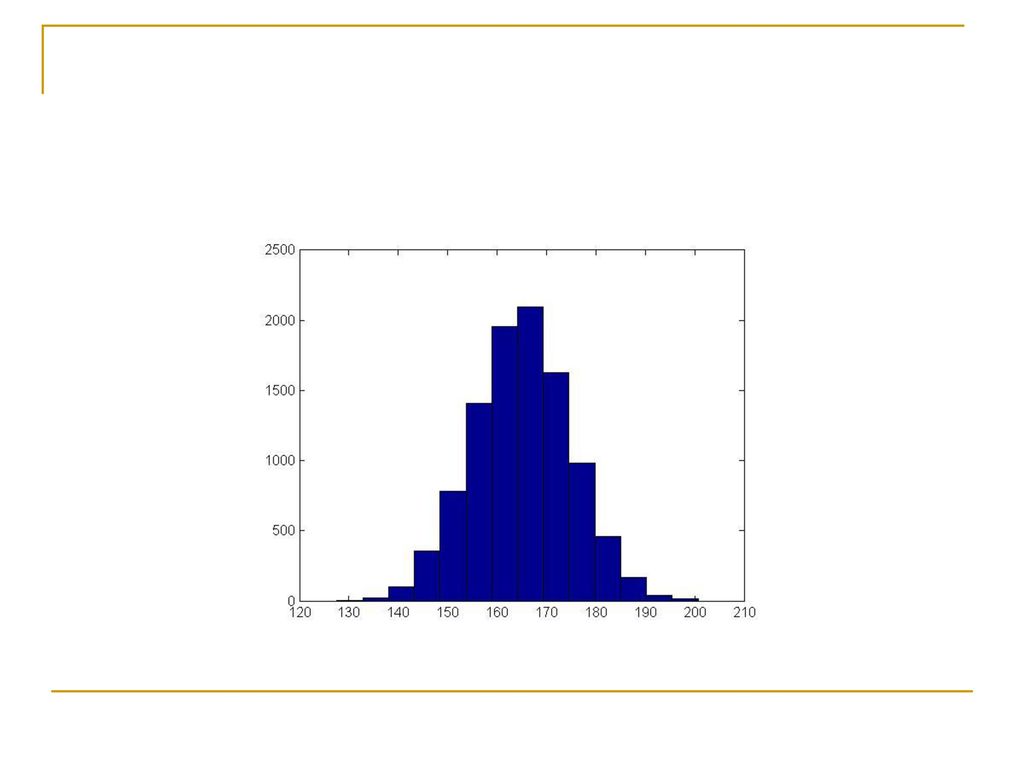
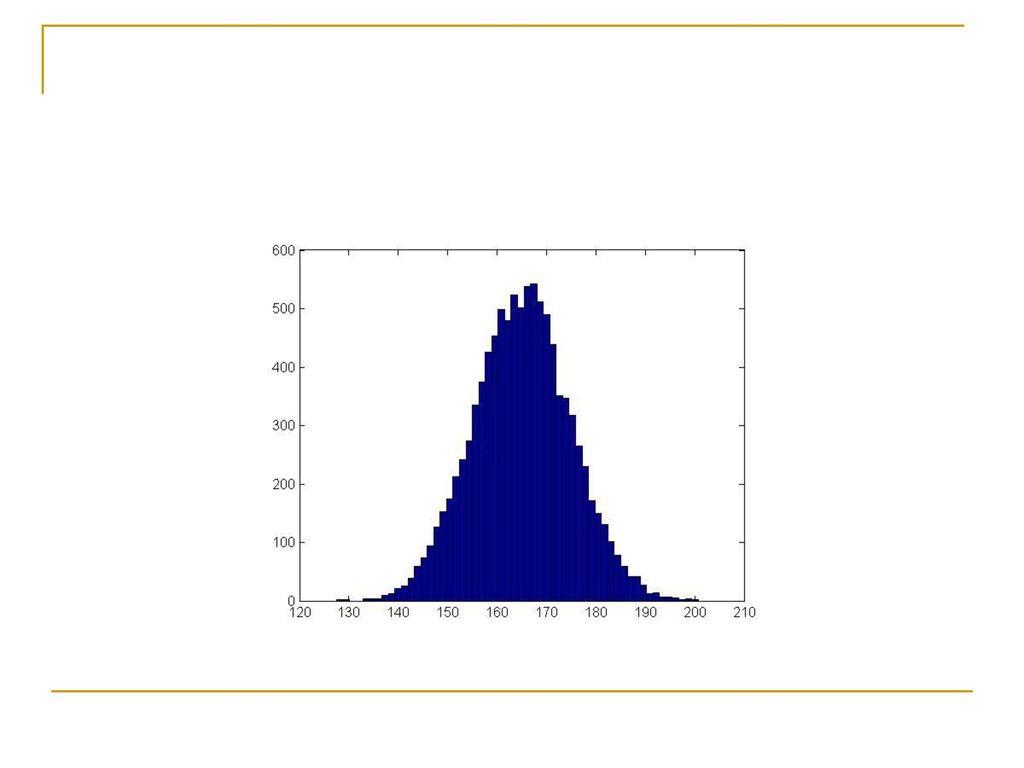
Ιστογράμματα Συχνότητας για κάθε ένα από τα επίπεδα της μεταβλητής «ποσότητα αλκοόλ»

10
…Λίγη Περιγραφική Στατιστική
Από κάθε μια από τις παραπάνω κατανομές, μπορούμε να εξάγουμε πολύ χρήσιμες περιγραφικές στατιστικές πληροφορίες. Για τους σκοπούς του μαθήματος Πειραματικής Ψυχολογίας θα περιοριστούμε: στο Μέσο Όρο – Mean - (είναι ένας από τους δείκτες «κεντρικής τάσης») και στην Τυπική Απόκλιση - Standard Deviation - (είναι ένας από τους δείκτες «διασποράς»). Για περισσότερες πληροφορίες σχετικά με τους δείκτες κεντρικής τάσης και διασποράς καλό θα είναι να θυμηθούμε ένα εγχειρίδιο στατιστικής…
 και. στην Τυπική Απόκλιση - Standard Deviation - (είναι ένας από τους δείκτες «διασποράς»). Για περισσότερες πληροφορίες σχετικά με τους δείκτες κεντρικής τάσης και διασποράς καλό θα είναι να θυμηθούμε ένα εγχειρίδιο στατιστικής…")
11
…Λίγη Περιγραφική Στατιστική
Έτσι, για κάθε ομάδα που ελέγχουμε στο πείραμά μας (πέντε μπύρες, δύο μπύρες, καμία μπύρα) μπορούμε να υπολογίσουμε το Μέσο Όρο (Μ.Ο.) λαθών στην οδήγηση. Ο Μ.Ο. υπολογίζεται αν αθροίσουμε όλες τις τιμές και διαιρέσουμε δια το συνολικό αριθμό τιμών που είχαμε στην κατανομή. Ο Μ.Ο. στην ομάδα «2 μπύρες» είναι 3.4 λάθη Ο Μ.Ο. στην ομάδα «5 μπύρες» είναι 9.5 λάθη Ο Μ.Ο. στην ομάδα «0 μπύρες» είναι 1.7 λάθη
 μπορούμε να υπολογίσουμε το Μέσο Όρο (Μ.Ο.) λαθών στην οδήγηση. Ο Μ.Ο. υπολογίζεται αν αθροίσουμε όλες τις τιμές και διαιρέσουμε δια το συνολικό αριθμό τιμών που είχαμε στην κατανομή. Ο Μ.Ο. στην ομάδα «2 μπύρες» είναι 3.4 λάθη. Ο Μ.Ο. στην ομάδα «5 μπύρες» είναι 9.5 λάθη. Ο Μ.Ο. στην ομάδα «0 μπύρες» είναι 1.7 λάθη.")
12
…Λίγη Περιγραφική Στατιστική
Ας πάρουμε σαν παράδειγμα την ομάδα «5 μπύρες» με Μ.Ο. = 9.5. Κάθε τιμή της ομάδας απέχει από το Μ.Ο. ορισμένη απόσταση. Η τιμή 15 απέχει από το Μ.Ο = 5.5 μονάδες. Η τιμή 7 απέχει από το Μ.Ο μονάδες…κ.ο.κ. Η απόσταση κάθε τιμής από τον Μ.Ο. λέγεται απόκλιση (deviation) (x - M.O.). Επειδή όμως οι αποκλίσεις είναι και θετικές και αρνητικές, το άθροισμα τους είναι μηδέν και άρα δεν μπορούμε να τις προσθέσουμε και να βγάλουμε το Μ.Ο., τους ως ένα αντιπροσωπευτικό δείκτη διασποράς. Για αυτό το λόγο, αθροίζουμε τα τετράγωνά τους (ώστε να απαλειφθούν τα πρόσημα) και υπολογίζουμε ύστερα το Μ.Ο. τους. Αυτός ο Μ.Ο. των τετραγώνων λέγεται διακύμανση – variance - (ή μέσο τετράγωνο των αποκλίσεων). H τετραγωνική ρίζα της διακύμανσης λέγεται τυπική απόκλιση (standard deviation). Μια σημαντική χρησιμότητα της τυπικής απόκλισης είναι ότι μας δείχνει το ποσοστό των τιμών της ομάδας που συγκεντρώνονται γύρω από το Μ.Ο. δηλ. το πόσο αντιπροσωπευτικός είναι ο Μ.Ο. για τα δεδομένα που παρατηρήσαμε.
 (x - M.O.). Επειδή όμως οι αποκλίσεις είναι και θετικές και αρνητικές, το άθροισμα τους είναι μηδέν και άρα δεν μπορούμε να τις προσθέσουμε και να βγάλουμε το Μ.Ο., τους ως ένα αντιπροσωπευτικό δείκτη διασποράς. Για αυτό το λόγο, αθροίζουμε τα τετράγωνά τους (ώστε να απαλειφθούν τα πρόσημα) και υπολογίζουμε ύστερα το Μ.Ο. τους. Αυτός ο Μ.Ο. των τετραγώνων λέγεται διακύμανση – variance - (ή μέσο τετράγωνο των αποκλίσεων). H τετραγωνική ρίζα της διακύμανσης λέγεται τυπική απόκλιση (standard deviation). Μια σημαντική χρησιμότητα της τυπικής απόκλισης είναι ότι μας δείχνει το ποσοστό των τιμών της ομάδας που συγκεντρώνονται γύρω από το Μ.Ο. δηλ. το πόσο αντιπροσωπευτικός είναι ο Μ.Ο. για τα δεδομένα που παρατηρήσαμε.")
13
Κανονική Κατανομή (Normal or Gaussian distribution)
Κανονική κατανομή υπάρχει όταν σε μια κατανομή συχνότητας η πλειοψηφία των τιμών συγκεντρώνεται γύρω από το κέντρο (Μ.Ο.) της κατανομής. Μια τέτοια κατανομή είναι συμμετρική γύρω από το Μ.Ο: Το 50% των τιμών είναι πάνω, και το 50% των τιμών είναι κάτω από το Μ.Ο. Ο μαθηματικός Gauss έδειξε, με το αντίστοιχο θεώρημά του, ότι σε μια κανονική κατανομή, περίπου το 68.3% των (μετρηθέντων) τιμών περιέχεται στο διάστημα μεταξύ μιας τυπικής απόκλισης πάνω και μιας τυπικής απόκλισης κάτω από το Μ.Ο. Το περίπου 95.4% των τιμών περιέχεται στο διάστημα μεταξύ δύο τυπικών αποκλίσεων πάνω και δύο τυπικών αποκλίσεων κάτω από το Μ.Ο. και Το περίπου 99.7% των τιμών περιέχεται στο διάστημα μεταξύ τριών τυπικών αποκλίσεων πάνω και τριών τυπικών αποκλίσεων κάτω από το Μ.Ο.
 της κατανομής. Μια τέτοια κατανομή είναι συμμετρική γύρω από το Μ.Ο: Το 50% των τιμών είναι πάνω, και το 50% των τιμών είναι κάτω από το Μ.Ο. Ο μαθηματικός Gauss έδειξε, με το αντίστοιχο θεώρημά του, ότι σε μια κανονική κατανομή, περίπου το 68.3% των (μετρηθέντων) τιμών περιέχεται στο διάστημα μεταξύ μιας τυπικής απόκλισης πάνω και μιας τυπικής απόκλισης κάτω από το Μ.Ο. Το περίπου 95.4% των τιμών περιέχεται στο διάστημα μεταξύ δύο τυπικών αποκλίσεων πάνω και δύο τυπικών αποκλίσεων κάτω από το Μ.Ο. και. Το περίπου 99.7% των τιμών περιέχεται στο διάστημα μεταξύ τριών τυπικών αποκλίσεων πάνω και τριών τυπικών αποκλίσεων κάτω από το Μ.Ο.")
14
Κανονική Κατανομή Δηλαδή, αν για παράδειγμα ο Μ.Ο. σε μια κατανομή είναι 30 και η τυπική απόκλιση είναι 8, τότε… Το σημείο που αντιστοιχεί σε μια τυπική απόκλιση πάνω από το Μ.Ο. είναι 30+8=38. Το σημείο που αντιστοιχεί σε μια τυπική απόκλιση κάτω από το Μ.Ο. είναι 30-8=22. Συνεπώς το 68% των τιμών αυτής της κατανομής θα βρίσκεται μεταξύ των τιμών 22 και 38.

15
Τυπικές Τιμές (z Scores)
η πιθανότητα να πάρουμε (ακριβώς) μια συγκεκριμένη τιμή είναι 0 η πιθανότητα να πάρουμε μια μέτρηση μεγαλύτερη (ή μικρότερη) από μια συγκεκριμένη τιμή εξαρτάται από την τυπική τιμή της τιμής αυτής η τυπική τιμή δείχνει πόσες τυπικές αποκλίσεις απέχει μια αρχική τιμή από το ΜΟ της κατανομής. …δηλ. δείχνει τη θέση που κατέχει μια τιμή μέσα στην κατανομή, σε σχέση με το ΜΟ z = (χ - MO) / ΤΑ (ΜΟ: μέσος όρος ΤΑ: τυπική απόκλιση) Έτσι, κάποιος συμμετέχων που, στην υπό μελέτη μεταβλητή, έχει αρχική τιμή ίση με τον ΜΟ, έχει τυπική τιμή = 0. Κάποιος που έχει αρχική τιμή ίση με μια τυπική απόκλιση πάνω από το ΜΟ έχει τυπική τιμή +1. Κάποιος που έχει αρχική τιμή ίση με μια τυπική απόκλιση κάτω από το ΜΟ έχει τυπική τιμή -1. κλπ.
 μια συγκεκριμένη τιμή είναι 0. η πιθανότητα να πάρουμε μια μέτρηση μεγαλύτερη (ή μικρότερη) από μια συγκεκριμένη τιμή εξαρτάται από την τυπική τιμή της τιμής αυτής. η τυπική τιμή δείχνει πόσες τυπικές αποκλίσεις απέχει μια αρχική τιμή από το ΜΟ της κατανομής. …δηλ. δείχνει τη θέση που κατέχει μια τιμή μέσα στην κατανομή, σε σχέση με το ΜΟ. z = (χ - MO) / ΤΑ (ΜΟ: μέσος όρος ΤΑ: τυπική απόκλιση) Έτσι, κάποιος συμμετέχων που, στην υπό μελέτη μεταβλητή, έχει αρχική τιμή ίση με τον ΜΟ, έχει τυπική τιμή = 0. Κάποιος που έχει αρχική τιμή ίση με μια τυπική απόκλιση πάνω από το ΜΟ έχει τυπική τιμή +1. Κάποιος που έχει αρχική τιμή ίση με μια τυπική απόκλιση κάτω από το ΜΟ έχει τυπική τιμή -1. κλπ.")
16
Τυπικές Τιμές (z Scores)
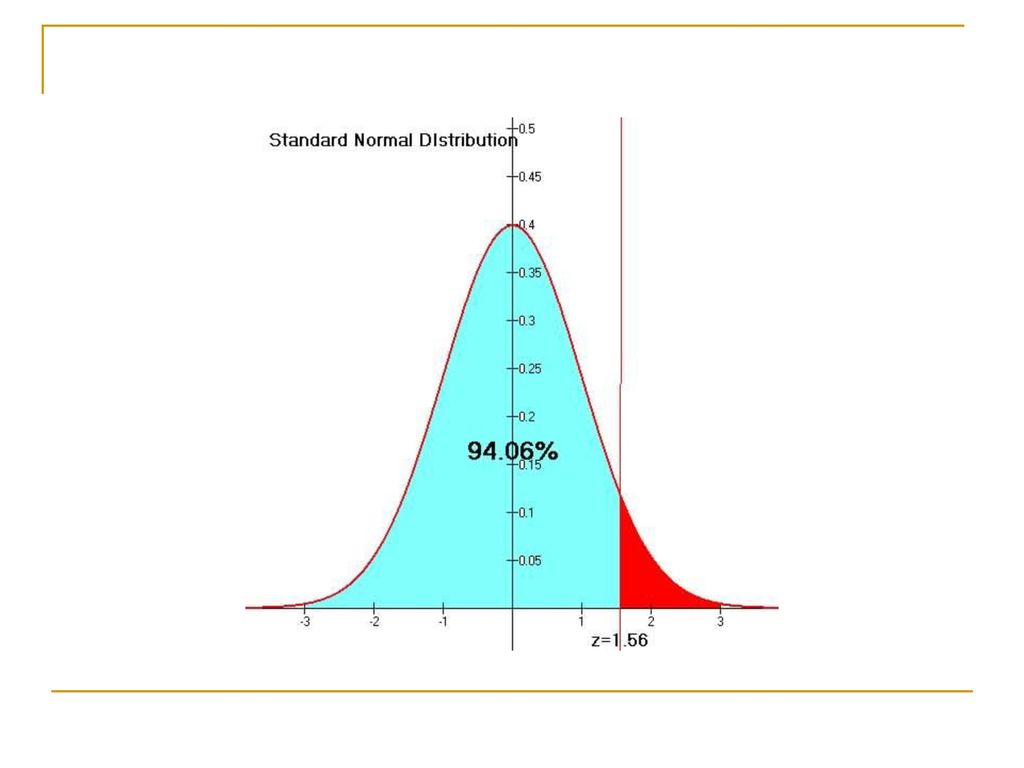
Αν υπολογίσουμε την ακριβή τυπική τιμή στην οποία αντιστοιχεί η εκάστοτε τιμή που μετρήσαμε (αρχική τιμή), τότε, μέσω των κατάλληλων πινάκων πιθανότητας, μπορούμε να πληροφορηθούμε το ακριβές ποσοστό των τιμών της κατανομής που είναι ψηλότερες (ή χαμηλότερες) από την τιμή αυτή. Πληροφορούμαστε δηλαδή για τη πιθανότητα που υπάρχει να βρεθεί η συγκεκριμένη, ή μικρότερη τιμή στην κατανομή. Η πιθανότητα αυτή (ποσοστό), –έστω το που αντιστοιχεί στην τυπική τιμή 1-, ουσιαστικά δείχνει ότι αν από τη συγκεκριμένη κατανομή διαλέξουμε μια τιμή στην τύχη, τότε στο 84.1 % των περιπτώσεων η τιμή αυτή θα είναι κάτω από 1. (ή πάνω από 1 για το 15.9 % των περιπτώσεων). Οι πίνακες αυτοί χρησιμεύουν τόσο για να μετατρέπουμε τις τυπικές τιμές (z-scores) σε πιθανότητες (p-values) όσο και το αντίστροφο Έτσι μπορούμε και να δούμε την πιθανότητα να πάρουμε μια τιμή τόσο μεγάλη (η μικρή) σαν αυτή που μετρήσαμε (μετατρέποντας τη τιμή μας σε τυπική τιμή με βάση τη φόρμουλα και μετά σε πιθανότητα με βάση τους πίνακες)… …ή αντίστροφα να δούμε ποια είναι η συγκεκριμένη τιμή που αντιστοιχεί σε μια συγκεκριμένη πιθανότητα (π.χ. top 10% σε ύψος), μετατρέποντας την πιθανότητα αυτή πρώτα σε τυπική τιμή (μέσω πίνακα) και μετά την τυπική τιμή σε κανονική τιμή (μέσω φόρμουλας)
, τότε, μέσω των κατάλληλων πινάκων πιθανότητας, μπορούμε να πληροφορηθούμε το ακριβές ποσοστό των τιμών της κατανομής που είναι ψηλότερες (ή χαμηλότερες) από την τιμή αυτή. Πληροφορούμαστε δηλαδή για τη πιθανότητα που υπάρχει να βρεθεί η συγκεκριμένη, ή μικρότερη τιμή στην κατανομή. Η πιθανότητα αυτή (ποσοστό), –έστω το που αντιστοιχεί στην τυπική τιμή 1-, ουσιαστικά δείχνει ότι αν από τη συγκεκριμένη κατανομή διαλέξουμε μια τιμή στην τύχη, τότε στο 84.1 % των περιπτώσεων η τιμή αυτή θα είναι κάτω από 1. (ή πάνω από 1 για το 15.9 % των περιπτώσεων). Οι πίνακες αυτοί χρησιμεύουν τόσο για να μετατρέπουμε τις τυπικές τιμές (z-scores) σε πιθανότητες (p-values) όσο και το αντίστροφο. Έτσι μπορούμε και να δούμε την πιθανότητα να πάρουμε μια τιμή τόσο μεγάλη (η μικρή) σαν αυτή που μετρήσαμε (μετατρέποντας τη τιμή μας σε τυπική τιμή με βάση τη φόρμουλα και μετά σε πιθανότητα με βάση τους πίνακες)… …ή αντίστροφα να δούμε ποια είναι η συγκεκριμένη τιμή που αντιστοιχεί σε μια συγκεκριμένη πιθανότητα (π.χ. top 10% σε ύψος), μετατρέποντας την πιθανότητα αυτή πρώτα σε τυπική τιμή (μέσω πίνακα) και μετά την τυπική τιμή σε κανονική τιμή (μέσω φόρμουλας)")
17
Ένα παράδειγμα εκφρασμένο σε Z Scores
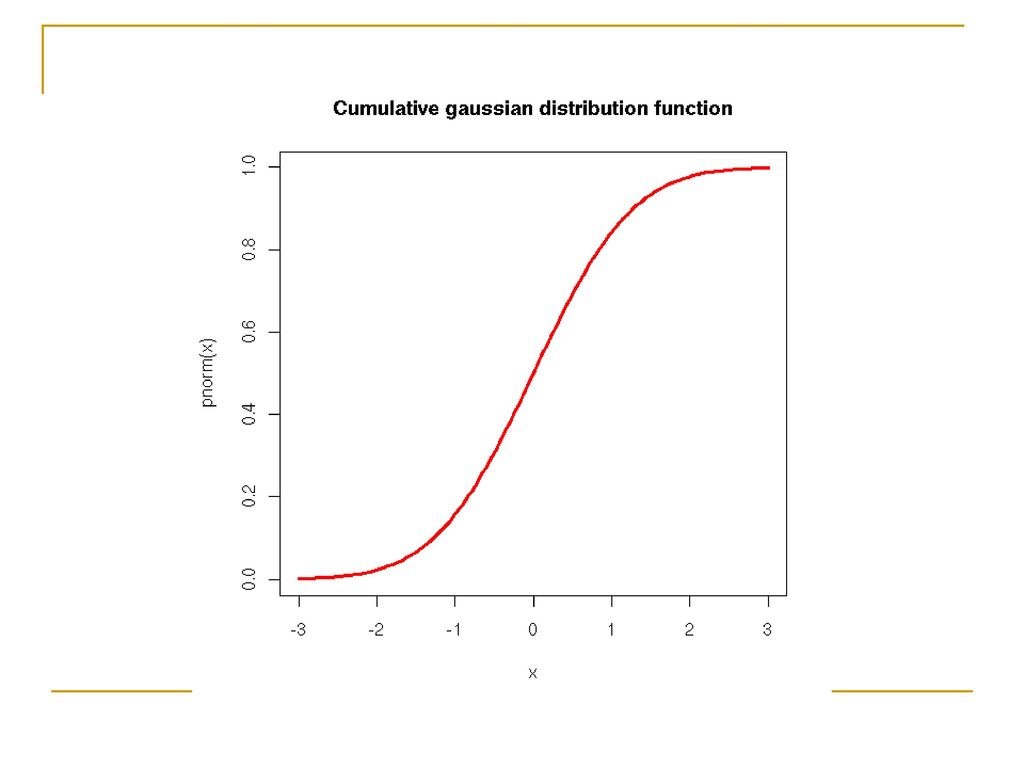
Οι τιμές του δείκτη νοημοσύνης (IQ) παρουσιάζουν κανονική κατανομή και θεωρείται ότι έχουν Μ.Ο. = 100 και Τ.Α. = 15. Έστω ότι θέλουμε να δούμε το ποσοστό των ατόμων που έχουν IQ μεγαλύτερο από 127. Πρώτα μετατρέπουμε την αρχική τιμή που μας ενδιαφέρει (την τιμή 127) σε z τιμή: z = ( ) / 15 = 1.8. Αυτό σημαίνει ότι η IQ (αρχική) τιμή 127 είναι 1.8 μονάδες (δηλαδή 1.8 τυπικές αποκλίσεις) πάνω από το Μ.Ο. Όπως φαίνεται από τον παρακάτω πίνακα αθροιστικών πιθανοτήτων κανονικής κατανομής, η αθροιστική πιθανότητα που αντιστοιχεί σε z = 1.8 είναι δηλαδή το 96.4% των ατόμων του πληθυσμού έχει IQ μικρότερο ή ίσο με 127 και άρα το ποσοστό που ψάχνουμε είναι 3.6% Αν, αντίστροφα, θέλαμε να δούμε ποιο είναι το IQ που σε κάνει να ανήκεις στο κορυφαίο 3.6% του πληθυσμού, μετατρέπουμε (με τη βοήθεια του πίνακα) το 3.6% σε z = 1.8 και υπολογίζουμε (με βάση τη φόρμουλα για το z-score) *15=127 που είναι η τιμή που ψάχνουμε!
 παρουσιάζουν κανονική κατανομή και θεωρείται ότι έχουν Μ.Ο. = 100 και Τ.Α. = 15. Έστω ότι θέλουμε να δούμε το ποσοστό των ατόμων που έχουν IQ μεγαλύτερο από 127. Πρώτα μετατρέπουμε την αρχική τιμή που μας ενδιαφέρει (την τιμή 127) σε z τιμή: z = ( ) / 15 = 1.8. Αυτό σημαίνει ότι η IQ (αρχική) τιμή 127 είναι 1.8 μονάδες (δηλαδή 1.8 τυπικές αποκλίσεις) πάνω από το Μ.Ο. Όπως φαίνεται από τον παρακάτω πίνακα αθροιστικών πιθανοτήτων κανονικής κατανομής, η αθροιστική πιθανότητα που αντιστοιχεί σε z = 1.8 είναι δηλαδή το 96.4% των ατόμων του πληθυσμού έχει IQ μικρότερο ή ίσο με 127 και άρα το ποσοστό που ψάχνουμε είναι 3.6% Αν, αντίστροφα, θέλαμε να δούμε ποιο είναι το IQ που σε κάνει να ανήκεις στο κορυφαίο 3.6% του πληθυσμού, μετατρέπουμε (με τη βοήθεια του πίνακα) το 3.6% σε z = 1.8 και υπολογίζουμε (με βάση τη φόρμουλα για το z-score) *15=127 που είναι η τιμή που ψάχνουμε!")
18
Πίνακας αθροιστικών πιθανοτήτων κανονικής κατανομής

19
Κανονική Κατανομή

24
PDF vs CDF

Παρόμοιες παρουσιάσεις









>")

 π.χ. Να συγκριθούν οι.>")

 ΕΠΙΒΛΕΠΟΥΣΑ ΚΑΘΗΓΗΤΡΙΑ: ΣΤΑΦΥΛΑ ΑΜΑΛΙΑ ΤΡΥΦΩΝΟΠΟΥΛΟΥ ΙΩΑΝΝΑ.>")
 και επιχειρηματική δραστηριότητα φορολογείται.>")



 Κατανομή των Ακραίων Τιμών Τύπου Ι (Gumbel) Όρια Εμπιστοσύνης.>")






