Κατέβασμα παρουσίασης
1
Βασική Στατιστική Επεξεργασία. Ερμηνεία Δεδομένων.
© 2010 Demetrios Halazonetis. Δημήτρης Χαλαζωνίτης

2
Περιεχόμενα Είδη δεδομένων Κατανομές Περιγραφικά στοιχεία
Κεντρικό θεώρημα ορίου Μηδενική Υπόθεση - πιθανότητες Ένα δείγμα Δύο δείγματα

3
Είδη δεδομένων Ποιοτικά (categorical - qualitative)
Μη διατάξιμα (nominal) Διατάξιμα (ordinal) Ποσοτικά (numerical - quantitative) Διακριτά (discrete) Συνεχή (continuous - interval)
 Διατάξιμα (ordinal) Ποσοτικά (numerical - quantitative) Διακριτά (discrete) Συνεχή (continuous - interval)")
4
Είδη δεδομένων Οριζόντια πρόταξη Ηλικία SNA Φύλο
Τάξη κατά Angle: I, II, III Πόνος

5
Κατανομές Κανονική (normal) (ύψος) Lognormal (βάρος)
Binomial (2 κατηγορίες) Poisson F t
 Poisson. F. t.")
6
Κανονική κατανομή y = 2πσ2 1 e παράμετροι: μ, σ y = a e -(x - μ)2 2σ2
wikipedia y = 2πσ2 1 e 2σ2 -(x - μ)2 παράμετροι: μ, σ y = a e -bx2
2. παράμετροι: μ, σ. y = a. e. -bx2.")
7
Κανονική κατανομή y = 2πσ2 1 e παράμετροι: μ, σ y = a e -(x - μ)2 2σ2
-bx2

8
Περιγραφικά στοιχεία πληθυσμού
μ = ∑x / n var = ∑(x - μ)2 / n σ = √var Οι τύποι ισχύουν για οποιοδήποτε είδος κατανομής (όχι μόνο για την κανονική)
2 / n. σ = √var. Οι τύποι ισχύουν για οποιοδήποτε είδος κατανομής (όχι μόνο για την κανονική)")
9
Δείγμα από τον πληθυσμό.

10
μ1

11
Περιγραφικά στοιχεία δείγματος
m = ∑x / n var = ∑(x - m)2 / (n - 1) s = √var
2 / (n - 1) s = √var.")
12
Πολλά δείγματα. Οι μέσες τιμές τους έχουν κανονική κατανομή, όπως προβλέπει το κεντρικό θεώρημα του ορίου.

13
Central Limit Theorem Κανονική κατανομή
Η κατανομή τείνει σε κανονική καθώς αυξάνεται το μέγεθος και ο αριθμός των δειγμάτων. Κανονική κατανομή

14
Central Limit Theorem m = μ sem = s / √n Κανονική κατανομή
Πολλά και μεγάλα δείγματα. sem: standard error of the mean m = μ Κανονική κατανομή sem = s / √n

15
Central Limit Theorem m = μ sem = s / √n Κανονική κατανομή
Ανεξαρτήτως του είδους της κατανομής στον πληθυσμό. m = μ Κανονική κατανομή sem = s / √n

16
s m = μ sem = s / √n sem

17
s m = μ sem = s / √n 1.28 sem

18
s m = μ sem = s / √n 80% 1.28 sem (από πίνακες ή εξίσωση της κανονικής κατανομής)
")
19
s m = μ sem = s / √n 95% 1.96 sem

20
s m = μ sem = s / √n 95% 1.96 sem Test statistic = (observed – hypothesized) / sem
 / sem")
21
6 -3 9 -8 -1 -9 7 2 10 8 3 4 -2 -9 -8 -3 -2 -1 2 3 4 6 7 8 9 10 -9 -8 -3 -2 -1 2 3 4 6 7 8 9 10 2.85 m = 2.85 sem = 1.27 s = 5.67 Παράδειγμα δείγματος με μέσο όρο 2.85.

22
97.6% 2.4% /2 Test statistic = (observed – hypothesized) / sem
2.85 s = 5.67 sem = 1.27 97.6% 2.4% /2 1 2 2.25 sem Test statistic = ( ) / 1.27 = 2.25
 / 1.27 =")
23
97.6% 2.4% /2 Test statistic = (observed – hypothesized) / sem
t distribution m = 2.85 2.85 s = 5.67 sem = 1.27 97.6% 2.4% /2 1 2 2.25 sem Test statistic = ( ) / 1.27 = 2.25
 / 1.27 =")
24
Test statistic = (observed – hypothesized) / sem
t distribution m = 2.85 2.85 s = 5.67 sem = 1.27 97.6% 2.4% /2 96.3% 3.7% /2 1 2 2.25 sem Test statistic = ( ) / 1.27 = 2.25
 / 1.27 =")
25
t distribution βαθμοί ελευθερίας - degrees of freedom

26
Μηδενική Υπόθεση (null hypothesis)
The hypothesis to be nullified – H0 Null Hypothesis Significance Testing (NHST)
")
27
Μηδενική Υπόθεση (null hypothesis)
Και όμως συνέβη! Επομένως, H0 απίθανη. ΛΑΘΟΣ, αλλά συνήθως ίσως ισχύει

28
p(H0|D) ≠ p(D|H0) p(H0|D): πιθανότητα H0 όταν D.
p(D|H0): πιθανότητα D όταν H0.
: πιθανότητα D όταν H0.")
29
Το ότι ένα δείγμα παρουσιάζει ακραίες τιμές δεν σημαίνει ότι δεν μπορεί να ανήκει στην κατανομή της μηδενικής υπόθεσης. Απλώς είναι σπάνιο.

30
Σε άλλη κατανομή μπορεί να είναι πιο σπάνιο.

31
Και σε άλλη, πολύ πιθανό.

32
Εάν έχει όντως συλλεχθεί από την πορτοκαλί κατανομή τότε η πιθανότητα να έχει την παρατηρούμενη μέση τιμή, ή πιο ακραία από αυτήν, είναι 1. Αυτό, όμως δεν σημαίνει ότι η πιθανότητα να έχει προέλθει από την πορτοκαλί κατανομή είναι 1 (δηλαδή βεβαιότητα). Άρα, η πιθανότητα που εκφράζεται από ένα στατιστικό τεστ δεν είναι η πιθανότητα αλήθειας της μηδενικής υπόθεσης.
. Άρα, η πιθανότητα που εκφράζεται από ένα στατιστικό τεστ δεν είναι η πιθανότητα αλήθειας της μηδενικής υπόθεσης..")
33
Αν p(D|HA) = 0.5 τότε p(H0|D) ≈ 2 p(D|H0)
p(H0|D): πιθανότητα H0 όταν D. p(D|H0): πιθανότητα D όταν H0. Αν p(D|HA) = 0.5 τότε p(H0|D) ≈ 2 p(D|H0)
: πιθανότητα H0 όταν D. p(D|H0): πιθανότητα D όταν H0. Αν p(D|HA) = 0.5 τότε p(H0|D) ≈ 2 p(D|H0)")
34
Μηδενική Υπόθεση (null hypothesis)
Και όμως συνέβη! Επομένως, H0 απίθανη. Type I error: false positive, α Type II error: false negative, β ΛΑΘΟΣ, αλλά συνήθως ίσως ισχύει

35
H0 True H0 False Rejected Type I, α OK Not Rejected Type II, β

36
Περιεχόμενα Είδη δεδομένων Κατανομές Περιγραφικά στοιχεία
Κεντρικό θεώρημα ορίου Μηδενική Υπόθεση - πιθανότητες Ένα δείγμα Δύο δείγματα

37
Ένα δείγμα Test statistic = (m – μ) / se se: τυπικό σφάλμα se = s / √n
P: από την κατανομή του t (df = n - 1)
")
38
96.3% 3.7% /2 Test statistic = (2.85 - 0) / 1.27 = 2.25 t distribution
m = 2.85 2.85 s = 5.67 sem = 1.27 96.3% 3.7% /2 1 2 2.25 sem

39
96.3% 3.7% /2 P = 0.037 Test statistic = (2.85 - 0) / 1.27 = 2.25
t distribution m = 2.85 2.85 s = 5.67 sem = 1.27 96.3% 3.7% /2 1 2 P = 0.037 2.25 sem

40
Confidence interval Αν υπολογίσουμε το όριο αξιοπιστίας για πολλά παρόμοια δείγματα, τα 95% θα περιέχουν τον πραγματικό μέσο όρο του πληθυσμού.

41
96.3% 3.7% /2 P = 0.037 Test statistic = (2.85 - 0) / 1.27 = 2.25
t distribution m = 2.85 2.85 s = 5.67 sem = 1.27 96.3% 3.7% /2 1 2 P = 0.037 2.25 sem t0.975 = (df = 20-1 = 19) 95%CI = 2.85 – x 1.27 to x 1.27
 95%CI = 2.85 – x 1.27 to x")
42
Ένα δείγμα Test statistic = (m – μ) / se se: τυπικό σφάλμα se = s / √n
P: από την κατανομή του t (df = n - 1) 95%CI = (m - t0.975 se) έως (m + t0.975 se)
 95%CI = (m - t0.975 se) έως (m + t0.975 se)")
43
Δύο δείγματα Test statistic = (m1 – m2) / se(m1-m2)
var = (n1 - 1) var1 + (n2 - 1) var2 / (n1 + n2 - 2) (n1 - 1) s12 + (n2 - 1) s22 / (n1 + n2 - 2) se(m1-m2) = √(var (1 / n1 + 1 / n2))
 var1 + (n2 - 1) var2 / (n1 + n2 - 2) (n1 - 1) s12 + (n2 - 1) s22 / (n1 + n2 - 2) se(m1-m2) = √(var (1 / n1 + 1 / n2))")
44
t-test Student’s t-test (Gosset, μπύρα)
Paired – Unpaired (independent samples) Προϋποθέσεις: Quantitative (interval) Normal distribution Equal variance (F test)
 Προϋποθέσεις: Quantitative (interval) Normal distribution. Equal variance (F test)")
45
F test F = var1 / var2 F distribution df: n1, n2

47
Για τις τιμές που σημειώνονται, το t-test δίνει τα εξής αποτελέσματα: t = 4.14, P = 0.0003.

48
Is this normally distributed (lognormal?). Same for areas.
. Same for areas.")
49
Simulation of volume data.

50
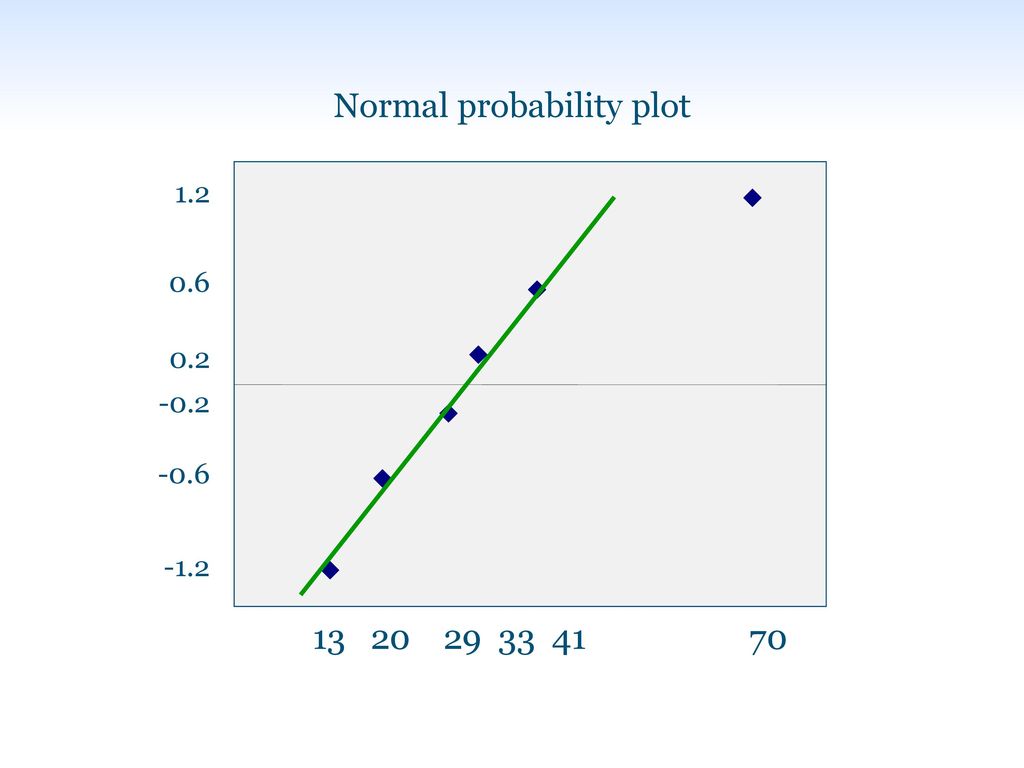
Έλεγχος κανονικότητας κατανομής:
Shapiro-Wilk test ή normal plot 13 20 29 33 41 70 0.2 0.6 1.2 -0.2 -0.6 -1.2

51
= (B1-1/3)/(6+1/3) =NORMSINV(C1)
Υπολογισμός των rankits με το Excel. Βλέπε:

52
Normal probability plot
1.2 0.6 0.2 -0.2 -0.6 -1.2
53
Ασκήσεις Διαφέρει το μήκος από το πλάτος;
Διαφέρει ο λόγος μήκος/πλάτος από τον λόγο μήκος/ύψος; Είναι κανονική η κατανομή του όγκου; Βλέπε αρχείο StatTests.xls



















>")

>")