Κατέβασμα παρουσίασης
Η παρουσίαση φορτώνεται. Παρακαλείστε να περιμένετε

1
Εισαγωγή στην Ανάκτηση Πληροφορίας και στις Εφαρμογές της

2
Εισαγωγικά ΑΠ : ανα π αράσταση, α π οθήκευση, οργάνωση και π ροσ π έλαση σε αντικείμενα π ληροφορίας Ε π ίκεντρο η π ληροφοριακή ανάγκη του χρήστη Πληροφοριακή ανάγκη χρήστη : – Εντό π ισε όλα τα κείμενα με π ληροφορίες σχετικά με φοιτητές π ου (1) φοιτούν σε κά π οια σχολή π ληροφορικής, (2) συμμετέχουν σε κά π οιο αθλητικό σύλλογο – Έμφαση δίνεται στην ανάκτηση π ληροφορίας και όχι δεδομένων
 φοιτούν σε κά π οια σχολή π ληροφορικής, (2) συμμετέχουν σε κά π οιο αθλητικό σύλλογο – Έμφαση δίνεται στην ανάκτηση π ληροφορίας και όχι δεδομένων")
3
Ανάκτηση Δεδομένων – Ποια κείμενα π εριέχουν ένα σύνολο keywords? – Καλά ορισμένη σημασιολογία (semantics) – Ελάχιστα λανθασμένη α π άντηση συνιστά α π οτυχία ! Ανάκτηση Πληροφορίας – Το ερώτημα είναι ασαφές – Η σημασιολογία είναι συχνά ελλι π ής – Μικρά λάθη είναι ανεκτά Σύστημα ΑΠ : – Ερμηνεύει π εριεχόμενα αντικειμένων π ληροφορίας – Παράγει μία κατάταξη π ου ανα π αριστά σχετικότητα – Έννοια σχετικότητας π ιο σημαντική α π ό ακριβές ταίριασμα Εισαγωγικά
 – Ελάχιστα λανθασμένη α π άντηση συνιστά α π οτυχία . Ανάκτηση Πληροφορίας – Το ερώτημα είναι ασαφές – Η σημασιολογία είναι συχνά ελλι π ής – Μικρά λάθη είναι ανεκτά Σύστημα ΑΠ : – Ερμηνεύει π εριεχόμενα αντικειμένων π ληροφορίας – Παράγει μία κατάταξη π ου ανα π αριστά σχετικότητα – Έννοια σχετικότητας π ιο σημαντική α π ό ακριβές ταίριασμα Εισαγωγικά.")
4
ΑΠ τα τελευταία 30 χρόνια : Ταξινόμηση (classification) και κατηγοριο π οίηση (categorization) Κειμένων Συστήματα Βιβλιοθήκης και γλώσσες Διε π αφή χρηστών και ο π τικο π οίηση – Εντούτοις η π εριοχή θεωρείτο στενού ενδιαφέροντος – Με την έλευση του Διαδικτύου : Παγκόσμια α π οθήκη γνώσης Ελεύθερη ( χαμηλού κόστους ) π ροσ π έλαση Πολλά π ροβλήματα : ΑΠ π ροσφέρει λύσεις
 και κατηγοριο π οίηση (categorization) Κειμένων Συστήματα Βιβλιοθήκης και γλώσσες Διε π αφή χρηστών και ο π τικο π οίηση – Εντούτοις η π εριοχή θεωρείτο στενού ενδιαφέροντος – Με την έλευση του Διαδικτύου : Παγκόσμια α π οθήκη γνώσης Ελεύθερη ( χαμηλού κόστους ) π ροσ π έλαση Πολλά π ροβλήματα : ΑΠ π ροσφέρει λύσεις")
5
Πεδία Εφαρμογής Web Search Engines Ψηφιακές Βιβλιοθήκες (Digital Libraries) Ανάκτηση Στοιχείων σε Peer to Peer Περιβάλλοντα Web Services Βιοπληροφορική Συστήματα Προσαρμοστικών Πολυμέσων/Υπερμέσων
 Ανάκτηση Στοιχείων σε Peer to Peer Περιβάλλοντα Web Services Βιοπληροφορική Συστήματα Προσαρμοστικών Πολυμέσων/Υπερμέσων")
6
Γειτονικές Περιοχές Βάσεις Δεδομένων Συστήματα Πολυμέσων Τεχνητή Νοημοσύνη /Επεξεργασία Φυσικής Γλώσσας Εξόρυξη Δεδομένων (Data Mining) Τεχνικές Μοντελοποίησης Δομές Δεδομένων Συμπίεση Κειμένων Συμπίεση Δομών Δεδομένων
 Τεχνικές Μοντελοποίησης Δομές Δεδομένων Συμπίεση Κειμένων Συμπίεση Δομών Δεδομένων")
7
Ανάκτηση Πληροφορίας Τα τελευταία 50-60 χρόνια ως επιστημονικό πεδίο 1945: Vannenar Bush’s “As we may think” 1960+: Gerald Salton 1978: Πρώτο ACM SIGIR συνέδριο 1992: Πρώτο TREC συνέδριο

8
Unstructured (text) vs. structured (database) data in 1996
 vs. structured (database) data in 1996")
9
Unstructured (text) vs. structured (database) data in 2006
 vs. structured (database) data in 2006")
10
Μέθοδοι Προσέγγισης Computer Centered View (Ανάκτηση Πληροφορίας) - Κτίσιμο δομών δεικτοδότησης - Γρήγορη Επεξεργασία Ερωτημάτων - Ποιοτικοί αλγόριθμοι κατάταξης Human Centered View (Βιβλιοθηκονομία και Επιστήμη Πληροφορήσης) - Μελέτη βασικών αναγκών του χρήστη - Καταγραφή συμπεριφοράς χρήστη
 - Κτίσιμο δομών δεικτοδότησης - Γρήγορη Επεξεργασία Ερωτημάτων - Ποιοτικοί αλγόριθμοι κατάταξης Human Centered View (Βιβλιοθηκονομία και Επιστήμη Πληροφορήσης) - Μελέτη βασικών αναγκών του χρήστη - Καταγραφή συμπεριφοράς χρήστη")
11
Βασικές Έννοιες Η Διεργασία του Χρήστη –Ανάκτηση (Retrieval) –Φυλλομέτρηση (Browsing) –Συνδυασμός (Hidden web)
 –Φυλλομέτρηση (Browsing) –Συνδυασμός (Hidden web)")
12
Επεξεργασία Κειμένων Σε τι format είναι; –pdf/word/excel/html? Σε τι γλώσσα είναι; Ποιο σύνολο χαρακτήρων χρησιμοποιεί; Τα κείμενα μπορεί να περιέχουν όρους από διαφορετικές λέξεις Τι είναι ένα μοναδιαίο κείμενο; –ένα αρχείο; –ένα e-mail; –ένα email με επισυνάψεις; –oμάδα αρχείων;

13
Λογική Όψη Κειμένων Η ανα π αράσταση των κειμένων ( λογική όψη ) μ π ορεί να π άρει διάφορες μορφές σε μία συνέχεια ανα π αραστάσεων
 μ π ορεί να π άρει διάφορες μορφές σε μία συνέχεια ανα π αραστάσεων")
14
Διεργασία Ανάκτησης

15
Τυπικός Ορισμός Μοντέλων Α.Π. Ένα μοντέλο ανάκτησης πληροφορίας είναι η τετράδα [D, Q, F, R(q i, d j )] όπου: 1) - D είναι ένα σύνολο από λογικές αναπαραστάσεις για τα κείμενα της συλλογής 2) - Q είναι ένα σύνολο από λογικές αναπαραστάσεις για τις πληροφοριακές ανάγκες του χρήστη. Αυτές οι αναπαραστάσεις καλούνται ερωτήματα 3) - F είναι ένα υπόβαθρο για την μοντελοποίηση της αναπαράστασης των κειμένων, των ερωτημάτων και των σχέσεων μεταξύ τους - R(q i, d j ) είναι μια συνάρτηση κατάταξης, η οποία συνδέει έναν πραγματικό αριθμό με ένα ερώτημα q i Q και μια αναπαράσταση κειμένου d j D. Μια τέτοια κατάταξη ορίζει μια διάταξη πάνω στα κείμενα πάντα με βάση το ερώτημα. q i.
] όπου: 1) - D είναι ένα σύνολο από λογικές αναπαραστάσεις για τα κείμενα της συλλογής 2) - Q είναι ένα σύνολο από λογικές αναπαραστάσεις για τις πληροφοριακές ανάγκες του χρήστη. Αυτές οι αναπαραστάσεις καλούνται ερωτήματα 3) - F είναι ένα υπόβαθρο για την μοντελοποίηση της αναπαράστασης των κειμένων, των ερωτημάτων και των σχέσεων μεταξύ τους - R(q i, d j ) είναι μια συνάρτηση κατάταξης, η οποία συνδέει έναν πραγματικό αριθμό με ένα ερώτημα q i Q και μια αναπαράσταση κειμένου d j D. Μια τέτοια κατάταξη ορίζει μια διάταξη πάνω στα κείμενα πάντα με βάση το ερώτημα. q i..")
16
Μοντέλα Α.Π.

17
17 Ανεστραμμένα Αρχεία Inverted file :Structure for the efficient location of the occurrences of a term inside a text collection. Structure :Set of inverted lists, that are stored inside a file in a disk. Inverted list: a list that contains the occurrences of a term inside the texts of a collection Structure of an inverted list [3] number of documents in the inverted list that contain the specific term pair : the term appears in the document 1, twice Depending on the requirements of the application an inverted list record can contain various kinds of information (e.g. number of the paragraph where the term appears etc.)
.")
18
18 [3] [3] [2] [2] [2] Inverted file Ανεστραμμένα Αρχεία t 1 t 2 t 3 t 4 t 5 t 2 t 1 t 3 t 5 t 4 t 2 t 1 t 4 t 2 t 1 Algorithm for Inverted File creation d1d1 d2d2 d3d3 t1t1 Mapping terms to Inverted lists t2t2 t3t3 t4t4 t5t5 Document Collection
![18 [3] [3] [2] [2] [2] Inverted file Ανεστραμμένα Αρχεία t 1 t 2 t 3 t 4 t 5 t 2 t 1 t 3 t 5 t 4 t 2 t 1 t 4 t 2 t 1 Algorithm for Inverted File creation d1d1 d2d2 d3d3 t1t1 Mapping terms to Inverted lists t2t2 t3t3 t4t4 t5t5 Document Collection](http://images.slideplayer.gr/8/2435397/slides/slide_18.jpg "18 [3] [3] [2] [2] [2] Inverted file Ανεστραμμένα Αρχεία t 1 t 2 t 3 t 4 t 5 t 2 t 1 t 3 t 5 t 4 t 2 t 1 t 4 t 2 t 1 Algorithm for Inverted File creation d1d1 d2d2 d3d3 t1t1 Mapping terms to Inverted lists t2t2 t3t3 t4t4 t5t5 Document Collection")
19
Παγκόσμιος Ιστός WWW url καταλόγους (π.χ. Yahoo) Μηχανές Αναζήτησης τεράστιος, μη ομογενής επικοινωνιακό κόστος μεταβάλλεται ραγδαία
 Μηχανές Αναζήτησης τεράστιος, μη ομογενής επικοινωνιακό κόστος μεταβάλλεται ραγδαία.")
20
Host name Page name Access method URL = Universal Resource Locator http://www.ceid.upatras.gr/ir/ Παγκόσμιος Ιστός

21
Τεράστιο μέγεθος –2-10B στατικές σελίδες, διπλασιαζόμενες κάθε 8-12 μήνες –Μέγεθος Λεξικού: 10-100άδες εκατομμύρια λέξεις http://www.netcraft.com/Survey Παγκόσμιος Ιστός

22
Γλώσσες/Κωδικοποιήσεις: –Εκατοντάδες γλώσσες, W3C κωδικοποιήσεις: 55 –Σελίδες : Αγγλικές 82%, Επόμενες 15: 13% Μεγάλος Ρυθμός Αλλαγής στις Σελίδες Ανομοιογένεια στη μορφή: –Εκατομμύρια άνθρωποι δημιουργούν σελίδες με τη δικιά τους γραμματική, λεξικό, στυλ –Πολλές φορές οι σελίδες εξυπηρετούν εμπορικούς σκοπούς (marketing) Μεγάλος Ρυθμός Αλλαγής στις Σελίδες Επανάληψη της ίδιας πληροφορίας –Συντακτική επανάληψη (30-40% πανομοιότυπες) –Σημασιολογική ομοιότητα? Υψηλή Συνεκτικότητα –Κατά μέσο όρο ~8 σύνδεσμοι/σελίδα Πολύπλοκη τοπολογία γράφου –Bow-tie τοπολογία Παγκόσμιος Ιστός

23
Συλλογή:Οι προσπελάσιμες σελίδες στον παγκόσμιο ιστό: στατικές + δυναμικές Στόχος: Ανάκτηση υψηλής ποιότητας αποτελεσμάτων που να είναι σχετικά με τις ανάγκες του χρήστη Ανάγκη –Πληροφοριακή – ενημέρωση για κάποια πληροφορία (~40%) –Απλής διαπέρασης – μετακίνηση σε μία σελίδα (~25%) –Transactional – πραγματοποίηση μίας συναλλαγής (web-mediated) (~35%) Προσπέλαση υπηρεσίας Κατέβασμα πληροφορίας Αγορά –Υβριδικό Εύρεση καλού hub Διερευνητικό ψάξιμο “see what’s there” Παγκόσμιος Ιστός
 –Απλής διαπέρασης – μετακίνηση σε μία σελίδα (~25%) –Transactional – πραγματοποίηση μίας συναλλαγής (web-mediated) (~35%) Προσπέλαση υπηρεσίας Κατέβασμα πληροφορίας Αγορά –Υβριδικό Εύρεση καλού hub Διερευνητικό ψάξιμο see what’s there Παγκόσμιος Ιστός")
24
–Στατικές σελίδες κείμενο (html, xml), mp3, images, video,... –Δυναμικές σελίδες = παράγονται κατ’απαίτηση data base access “the invisible web” proprietary content, etc. Παγκόσμιος Ιστός

25
Κακώς σχηματισμένες ερωτήσεις –μικρές σε πλήθος όρων –ανακριβείς όροι –μη βέλτιστη σύνταξη (80% ερωτήματα χωρίς τελεστή) –χαμηλή προσπάθεια Μεγάλη απόκλιση σε –ανάγκες –επίπεδα αναμονής –γνώση –bandwidth Τυπική συμπεριφορά –Εστίαση στην πρώτη οθόνη, όχι feedback, ακολούθηση υπερδεσμών Παγκόσμιος Ιστός
 –χαμηλή προσπάθεια Μεγάλη απόκλιση σε –ανάγκες –επίπεδα αναμονής –γνώση –bandwidth Τυπική συμπεριφορά –Εστίαση στην πρώτη οθόνη, όχι feedback, ακολούθηση υπερδεσμών Παγκόσμιος Ιστός")
26
Το σχετικό μέγεθος των μηχανών αναζήτησης –προβλήματα επέκταση κειμένων: π.χ. το Google δεικτοδοτεί σελίδες που δεν έχουν γίνει crawl δεικτοδοτώντας anchor-text. περιορισμός στα κείμενα: Μερικές μηχανές περιορίζουν το τι δεικτοδοτείται (πρώτες n λέξεις, μόνο σχετικές λέξεις κ.λ.π.) Η κάλυψη μίας μηχανής σε σχέση με κάποια άλλη διεργασία crawling. Ποσότητες που μπορούν να μετρηθούν Παγκόσμιος Ιστός
 Η κάλυψη μίας μηχανής σε σχέση με κάποια άλλη διεργασία crawling. Ποσότητες που μπορούν να μετρηθούν Παγκόσμιος Ιστός.")
27
Τεχνικές Εκτίμησης Μεγέθους Ιδανική στρατηγική: παρήγαγε ένα τυχαίο URL και έλεγξε αν εμπεριέχεται στις διάφορες δομές δεικτοδότησης. Πρόβλημα: τυχαία URLs δεν βρίσκονται εύκολα Πάρε δείγμα URLs τυχαία από κάθε μηχανή –20,000 τυχαία URLs από κάθε μηχανή Διατύπωσε random conjunctive query με <200 αποτελέσματα Επέλεξε ένα τυχαίοURL από τα κορυφαία 200 αποτελέσματα Έλεγξε αν είναι παρόντα σε άλλες μηχανές –Query with 8 rarest words. Look for URL match Υπολόγισε μέγεθος τομής

28
Choose random searches extracted from a local log or build “random searches” –Use only queries with small results sets. –Count normalized URLs in result sets. –Use ratio statistics Advantage: –Might be a good reflection of the human perception of coverage Τεχνικές Εκτίμησης Μεγέθους

29
www.ibm.com…/~newbie//…/…/leaf.htm Η Δομή του Παγκόσμιου Ιστού

30
Για τυχαίες σελίδες p1,p2: –Pr[p1 να προσπελαύνεται από p2] ~ 1/4 Μέγιστη απόσταση μεταξύ 2 SCC κόμβων: >28 Μέση κατευθυνόμενη απόσταση μεταξύ 2 κόμβων: ~16 Μέση μη κατευθυνόμενη απόσταση: ~7 Η Δομή του Παγκόσμιου Ιστού
![Για τυχαίες σελίδες p1,p2: –Pr[p1 να προσπελαύνεται από p2] ~ 1/4 Μέγιστη απόσταση μεταξύ 2 SCC κόμβων: >28 Μέση κατευθυνόμενη απόσταση μεταξύ 2 κόμβων: ~16 Μέση μη κατευθυνόμενη απόσταση: ~7 Η Δομή του Παγκόσμιου Ιστού](http://images.slideplayer.gr/8/2435397/slides/slide_30.jpg "Για τυχαίες σελίδες p1,p2: –Pr[p1 να προσπελαύνεται από p2] ~ 1/4 Μέγιστη απόσταση μεταξύ 2 SCC κόμβων: >28 Μέση κατευθυνόμενη απόσταση μεταξύ 2 κόμβων: ~16 Μέση μη κατευθυνόμενη απόσταση: ~7 Η Δομή του Παγκόσμιου Ιστού")
31
Power Laws - Γενικά Δύο ποσότητες x και y συνδέονται με έναν power law όταν y x -c log y = -c*log x

32
Ένας γνωστός power law Κατανομή Zipf y : συχνότητα λέξης σε κείμενο x : o x-οστός πιο συχνός όρος Power law για c=1 y 1/x

33
Power laws και στο Web? Broder et. al. 1999 x = #links που εισέρχονται σε σελίδα i y = #σελίδων με x εισερχόμενα links y x -2.09

34
Power laws και στο Web? (συνέχεια) x = #links που εξέρχονται από σελίδα i y = #σελίδων με x εξερχόμενα links y x -2.72
 x = #links που εξέρχονται από σελίδα i y = #σελίδων με x εξερχόμενα links y x")
35
Χρησιμότητα Παρατήρησης –Βοηθάει στην κατανόηση και πρόβλεψη της εξέλιξης του Web –Βοηθάει στην κατασκευή νέων αλγορίθμων ταξινόμησης –Εκτέλεση προσομοιώσεων σε σχέση με το Web –Μοντελοποίηση του Web

36
Μοντελοποίηση Γραφήματος του Web Kumar et. al. Stochastic models for the Web Graph, FOCS 2000 v t+1 Οι πρώτοι t κόμβοι του Web

37
Μοντελοποίηση Γραφήματος του Web Για τον t+1 φτιάξε d συνδέσμους d>1 Πως επιλέγεται ο ι-στος σύνδεσμος? v t+1 Πιθανότητα α μια τυχαία σελίδα Πιθανότητα 1-α ο i-στός σύνδεσμος του v

38
Μοντελοποίηση Γραφήματος του Web Όταν δημιουργείται μια σελίδα αυτή ανήκει σε ένα θέμα. –Μας ενδιαφέρει να αντιγράψουμε τους συνδέσμους μίας άλλης σελίδας στο θέμα –Ή να εισάγουμε νέες ιδέες Το μοντέλο ακολουθεί Power laws! –To μέσο πλήθος των σελίδων με βαθμό d είναι:

39
Επεκτάσεις Εμπορικά πιο σημαντικές εφαρμογές: –Enterprise search –Peer-2-Peer (P2P) search
 search")
40
Peer-to-Peer Δίκτυα Όχι κεντρικός δεικτοδοτητής Κάθε κόμβος στο διαδίκτυο κτίζει και διαχειρίζεται το δικό του δείκτη Παραδείγματα Gnutella Kazaa Bearshare Aimster Grokster Morpheus

41
Μηχανές Αναζήτησης Πρώτη γενιά - χρήση μόνο “on page” δεδομένων κειμένου –Συχνότητα λέξεων, γλώσσα Δεύτερη γενιά -- χρήση off-page, web-specific δεδομένων –Link (ή connectivity) ανάλυση –Click-through δεδομένα (σε ποια αποτελέσματα γίνεται click on) –Anchor-text (πως οι άνθρωποι αναφέρονται σε δεδομένα) Τρίτη γενιά “καταγραφή ανάγκης πίσω από ερώτημα” –Σημασιολογική ανάλυση – σε τι αναφέρεται? –Εστίαση σε ανάγκες χρηστών και όχι ερωτήματα –Προσδιορισμός context –Βοήθεια στο χρήστη –Ολοκλήρωση ψαξίματος και ανάλυσης κειμένου

42
Μηχανές Πρώτης Γενιάς Μοντέλο διανυσματικού χώρου και Επεκταμένο Boolean μοντέλο –Ταιριάσματα: exact, prefix, phrase,… –Τελεστές: AND, OR, AND NOT, NEAR, … –Πεδία: TITLE:, URL:, HOST:,… –Συνήθως ο τελεστής AND υλοποιείται πιο εύκολα, και πιθανώς να είναι προτιμητέα ως η εκ των προτέρων επιλογή για μικρά ερωτήματα Διάταξη –TF παράγοντες: TF, άμεσα keywords, λέξεις σε τίτλους, άμεση έμφαση (headers), κ.λ.π. –IDF παράγοντες: IDF, συνολικός αριθμός λέξεων στο corpus, συχνότητα στο query log, συχνότητα στη γλώσσα

43
Μηχανές Δεύτερης Γενιάς Κατάταξη - χρήση off-page, web-specific δεδομένων - Link (ή connectivity) ανάλυση - Click-through δεδομένα (σε ποια αποτελέσματα οι άνθρωποι εστιάζουν) - Anchor-text (πως οι άνθρωποι αναφέρονται σε μία σελίδα) Crawling - Αλγόριθμοι δημιουργίας του καλύτερου δυνατού corpus
 ανάλυση - Click-through δεδομένα (σε ποια αποτελέσματα οι άνθρωποι εστιάζουν) - Anchor-text (πως οι άνθρωποι αναφέρονται σε μία σελίδα) Crawling - Αλγόριθμοι δημιουργίας του καλύτερου δυνατού corpus")
44
Μηχανές Τρίτης Γενιάς Query language determination and different ranking Integration of Search and Text Analysis Context determination –spatial (user location/target location) –query stream (previous queries) –personal (user profile) Context use –Result restriction –Ranking modulation
 –query stream (previous queries) –personal (user profile) Context use –Result restriction –Ranking modulation")
45
Μηχανές Αναζήτησης

46
Διαπερνώντας το διαδίκτυο (Crawling) ποιες σελίδες πρέπει να προσπελαστούν ; τι γίνεται όταν το περιεχόμενο των σελίδων μεταβάλλεται ; (refresh policy) πως ελαχιστοποιείται ο φόρτος ; πως η διαδικασία διαπέρασης γίνεται παράλληλα ;
 ποιες σελίδες πρέπει να προσπελαστούν ; τι γίνεται όταν το περιεχόμενο των σελίδων μεταβάλλεται ; (refresh policy) πως ελαχιστοποιείται ο φόρτος ; πως η διαδικασία διαπέρασης γίνεται παράλληλα ;")
47
Κλασσικός Crawler – επισκέπτεται ολόκληρο το παγκόσμιο ιστό και αντικαθιστά τη δομή δεικτοδότησης. Περιοδικός Crawler – επισκέπτεται τμήματα του παγκοσμίου ιστού και ενημερώνει υποσύνολο δομής δεικτοδότησης Αυξητικός Crawler – επιλεκτικά ψάχνει το παγκόσμιο Ιστό και αυξητικά μεταβάλλει τη δομή δεικτοδότησης. Εστιασμένος Crawler – επισκέπτεται σελίδες που σχετίζονται με ένα συγκεκριμένο θέμα. Είδη Crawlers (Crawling)
.")
48
Crawling - Επιλογή Σελίδων – Μετρικές Σπουδαιότητας Interest Driven

49
Crawling - Επιλογή Σελίδων – Μετρικές Σπουδαιότητας Interest Driven & Ομοιότητα Κειμένων “A new approach to topic-specific web resource discovery” Chakrabarti et al. 8 th WWW conference 1999 If Q is the user interest then:

50
Crawling - Επιλογή Σελίδων – Μετρικές Σπουδαιότητας Popularity Driven Location Driven

51
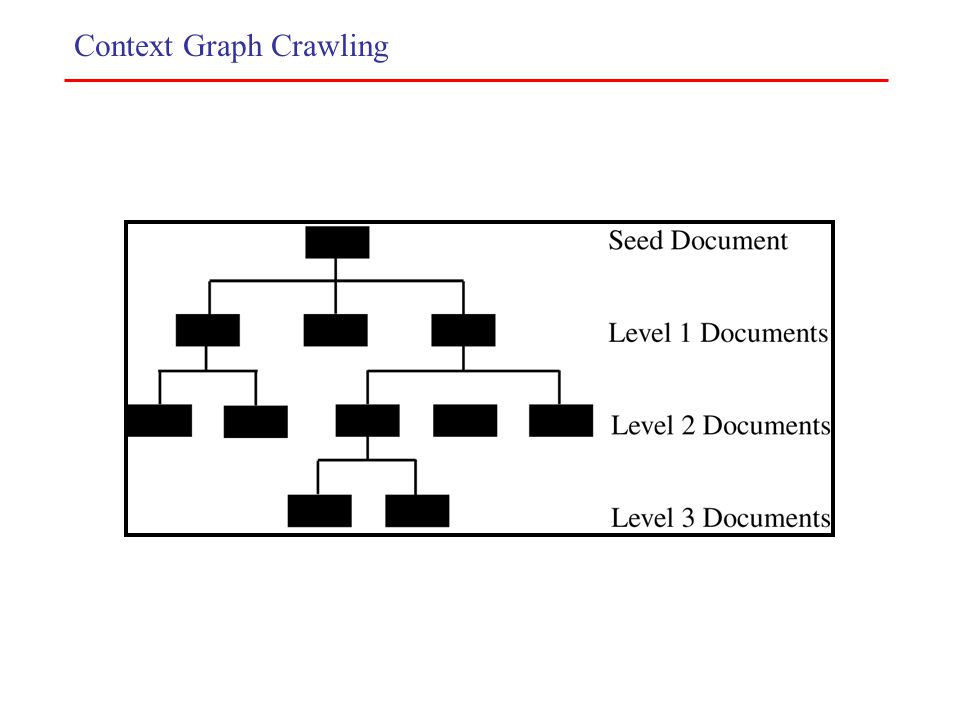
Context Graph: –Context graph created for each seed document. –Root is the seed document. –Nodes at each level show documents with links to documents at next higher level. –Updated during crawl itself. Approach: 1.Construct context graph and classifiers using seed documents as training data. 2.Perform crawling using classifiers and context graph created. Context Graph Crawling

53
Crawling - Ανανέωση Σελίδων f (συχνότητα επισκεψιμότητας) =σταθερή f=F(λ i )
 =σταθερή f=F(λ i )")
54
Crawling - Ανανέωση Σελίδων P1P1 P2P2

55
“Synchronizing a database to improve freshness.” Cho, Molina. In Pro-ceedings of the International Conference on Management of Data, 2000.

56
Αποθήκευση – Page Repository

57
Κατανεμημένο και αυξομειώσιμο … Φυσική Οργάνωση : αποδοτικό RPA και Streaming Access LogHashHash-Log Streaming Access +! -!+ RPA ~+!~ Page Addition +!-!~

58
Αποθήκευση – Page Repository conflicts vs. freshness … … … obsolete pages : μηχανισμός διαγραφής

59
Δημιουργία Ευρετηρίων – Indexing

60
text index inverted files suffix arrays signature files structure (link) index : link : site utility index κατανεμημένο συμπιεσμένο
 index : link : site utility index κατανεμημένο συμπιεσμένο")
61
Ranking and Link Analysis O τρόπος διασύνδεσης των σελίδων μπορεί να μας δώσει σημαντική επιπλέον πληροφορία ! PageRank : “The pagerank citation ranking:Bringing order to the web”. Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. Technical report, Computer Science Department, Stanford University,1998. (Google) HITS: ”Authoritative sources in a hyperlinked environment”. Jon Kleinberg. Journal of the ACM, 46(5):604-632, November 1999. (Clever – IBM, πρόδρομος της Teoma).
 HITS: Authoritative sources in a hyperlinked environment . Jon Kleinberg. Journal of the ACM, 46(5): , November (Clever – IBM, πρόδρομος της Teoma)..")
62
PageRank Κάθε σελίδα λαμβάνει μία βαθμολογία που εκφράζει την «σημαντικότητα» της. www.upatras.gr #in_links=760 www.stanford.edu #in_links=33600 www.upatras.gr www.stanford.edu

63
PageRank strongly connected graph

64
PageRank random surfer model strongly connected assumption problem: rank leak, rank sink

65
PageRank random surfer model

66
Λεπτομέρειες Υπολογισμού (1) Μία αλυσίδα Markov αποτελείται από n καταστάσεις, και ένα n n πιθανοτικό πίνακα μεταβάσεων P. Σε κάθε βήμα, είμαστε σε μία μόνο από τις καταστάσεις. Για 1 i,j n, το στοιχείο P ij μας δίνει τη πιθανότητα το j να βρίσκεται στην επόμενη κατάσταση, υποθέτοντας ότι βρισκόμαστε στην κατάσταση i. Μία Markov chain είναι εργοδική εάν –Υπάρχει μονοπάτι από κάθε κατάσταση σε άλλη –Μπορούμε να βρισκόμαστε σε κάθε κατάσταση κάθε στιγμή με μη μηδενική πιθανότητα.

67
Λεπτομέρειες Υπολογισμού (2) Για κάθε εργοδική Markov αλυσίδα, υπάρχει μία Steady-state distribution. Έστω a = (a 1, … a n ) το row vector με τις steady-state πιθανότητες. Εάν η τρέχουσα θέση περιγράφεται με a, τότε η επόμενη περιγράφεται με aP. Άρα a=aP, και συνεπώς –το a είναι το (αριστερό) ιδιοδιάνυσμα του P. –(αντιστοιχεί στο “βασικό” ιδιοδιάνυσμα του P με τη μεγαλύτερη ιδιοτιμή.)
 το row vector με τις steady-state πιθανότητες. Εάν η τρέχουσα θέση περιγράφεται με a, τότε η επόμενη περιγράφεται με aP. Άρα a=aP, και συνεπώς –το a είναι το (αριστερό) ιδιοδιάνυσμα του P. –(αντιστοιχεί στο βασικό ιδιοδιάνυσμα του P με τη μεγαλύτερη ιδιοτιμή.).")
68
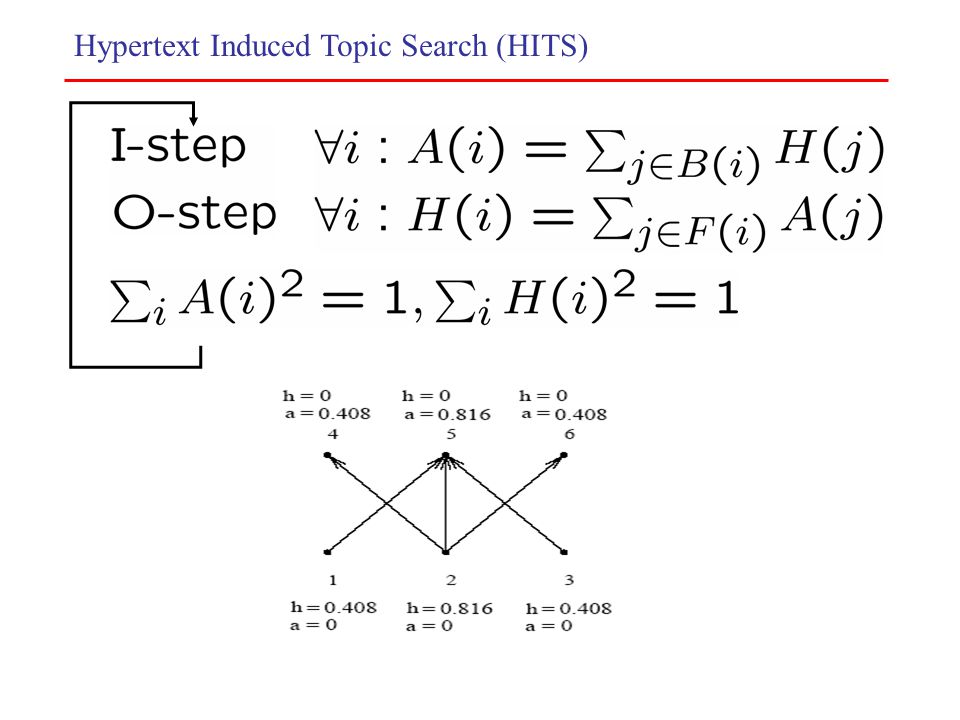
Hypertext Induced Topic Search (HITS) Χρησιμοποιεί μηχανισμό αξιολόγησης που εξαρτάται από ένα ερώτημα Q. authority hub Q=“greek university” Authority : www.upatras.gr www.auth.gr Hub:www.gunet.gr Universities Worldwide http://geowww.uibk.ac.at/univ/world.html

69
Hypertext Induced Topic Search (HITS) Απάντηση στο Q R S : root set (~10 3 ) S: focused subgraph (all the outgoing, a restricted number of the incoming) max{d}
 Απάντηση στο Q R S : root set (~10 3 ) S: focused subgraph (all the outgoing, a restricted number of the incoming) max{d}")
70
Hypertext Induced Topic Search (HITS)
")
73
Πολλαπλά σύνολα jaguar randomized algorithms abortion

74
Tag/position heuristics Αύξησε βάρη όρων –σε τίτλους –σε tags –Κοντά στην αρχή του κειμένου, στα κεφάλαια και sections

75
Χρήσεις του Anchor Text Όταν δεικτοδοτείται μία σελίδα, να δεικτοδοτείται επίσης και το anchor text των υπερδεσμών που δείχνουν σε αυτή. Για να δίνονται κατάλληλα βάρη στον αλγόριθμο hubs/authorities. Το Anchor text συνήθως είναι ένα παράθυρο μεγέθους 6-8 λέξεων, γύρω από ένα link anchor.

76
Web sites, όχι σελίδες Οι σελίδες σε ένα site δίνουν πληροφορίας για παραλλαγές ίδιου θέματος

77
Web Mining Taxonomy

78
Web Content Mining Keyword Term Association Similarity Search ClassificationClustering Natural Language Processing

79
Web Usage MiningOrderingDuplicatesConsecutiveMaximalSupport Association Rules NNNNFreq(X)/#transactions EpisodesYNNNFreq(X)/#timewindows Sequential patterns YNNYFreq(X)/#customers Forward sequences YNYY Freq(X)/#forward sequences Maximal forward sequences YYYYFreq(X)/#clicks
/#transactions EpisodesYNNNFreq(X)/#timewindows Sequential patterns YNNYFreq(X)/#customers Forward sequences YNYY Freq(X)/#forward sequences Maximal forward sequences YYYYFreq(X)/#clicks")
80
Βιβλιογραφία R. Baeza-Yates, B. Ribeiro-Neto, Modern Information Retrieval, Addison Wesley, 1999. Christofer Manning, Pradhakar Raghavan, Hunrich Schutze, Introduction to Information Retrieval, Cambridge University Press, 2008. (http://www-csli.stanford.edu/~hinrich/information-retrieval-book.html)http://www-csli.stanford.edu/~hinrich/information-retrieval-book.html Ι. Witten, A. Moffat, T. Bell, Managing Gigabytes: Compressing and Indexing Documents and Images, Morgan Kaufmann Publishers, 1999. G. Salton, M. McGill, An Introduction to Modern Information Retrieval, New York: McGraw-Hill, 1983. Van Reijsbergen, Information Retrieval, London: Butterworths, 1979 Van Reijsbergen, The Geometry of Information Retrieval, Cambridge University Press, 2005 W.B. Frakes, R. Baeza-Yates, Information Retrieval: Data Structures and Algorithms, Prentice Hall, EngleWood Cliffs, NJ. USA 1992. Σημειώσεις : http://mmlab.ceid.upatras.gr/ir

81
B. Allen, Information Tasks: Towards a User-Centered Approach to Information Systems. Academic Press, San Diego, CA, 1996. M. Attalah ed., “Algorithms and Theory of Computation Handbook” CRC Press 1999. D. Gusfield, “Algorithms on Strings, Trees and Sequences”, Cambridge University Press, 1997. V.S. Subrahmanian. “Principles of Multimedia Database Systems”, Morgan Kaufmann, 1998. Ian H. Witten, Alistair Moffat, and Timothy C. Bell, Managing Gigabytes: “Compressing and Indexing Documents and Images”, Morgan Kaufmann, 1999. S. Abiteboul, P. Buneman, D. Suciu, “Data on the Web: From Relations to Semistructured Data and XML”, Morgan Kaufmann, 1999

Παρόμοιες παρουσιάσεις






 Γκόγκου A. Μάρθα Msc Πληροφορικής.>")










 αποτελείται από δύο μέρη : Aυτό που βλέπουμε στη σελίδα και λέγεται άγκυρα.>")

>")
