Κατέβασμα παρουσίασης
1
IΟΝΙΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΡΟΓΡΑΜΜΑ ΜΕΤΑΠΤΥΧΙΑΚΩΝ ΣΠΟΥΔΩΝ ΣΤΗΝ ΕΠΙΣΤΗΜΗ ΤΗΣ ΠΛΗΡΟΦΟΡΙΑΣ: «ΔΙΟΙΚΗΣΗ & ΟΡΓΑΝΩΣΗ ΒΙΒΛΙΟΘΗΚΩΝ ΜΕ ΕΜΦΑΣΗ ΣΤΙΣ ΝΕΕΣ ΤΕΧΝΟΛΟΓΙΕΣ ΤΗΣ ΠΛΗΡΟΦΟΡΙΑΣ» «Συνεργατικά ερωτήματα για τον εμπλουτισμό του IR» βασισμένο στο άρθρο των Lin Fu et. al.: ‘Collaborative Querying for Enhanced Information Retrieval’ Εργασία στα πλαίσια του μαθήματος «Ηλεκτρονική Δημοσίευση» Ρόδη Ασημίνα Επιβλέποντες καθηγητές: Καπιδάκης Σαράντος Γεργατσούλης Μανώλης

2
Σύντομη επισκόπηση Εισαγωγή Συστήματα αλληλεπιδραστικού ανασχηματισμού ερωτημάτων Προσεγγίσεις για το clustering ερωτημάτων Σύστημα συνεργατικών ερωτημάτων Αρχιτεκτονική συστήματος Πρόταση ερωτήματος Συμπεράσματα & Προβληματισμοί

3
Εισαγωγή Πληροφοριακή αναζήτηση (αναζήτηση, αξιολόγηση, επιλογή, χρήση) Αλληλεπίδραση με πληροφοριακά συστήματα & συνεργατικότητα Συνεργατικά ερωτήματα: αξιοποίηση εμπειρίας & γνώσης άλλων χρηστών Συστοιχία ερωτημάτων (query clustering): αυτόματη ομαδοποίηση παρόμοιων ερωτημάτων χωρίς προκαθορισμένες περιγραφές κατηγοριών. Logs, εξαγωγή, clustering, πρόταση Π.χ. ως απάντηση σε ένα ερώτημα Q, ο αλγόριθμος παρέχει μια λίστα από προτάσεις & τα άλλα μέλη της συστοιχίας που περιέχουν το Q Δείκτες ομοιότητας κατά το clustering ερωτημάτων Υβριδική προσέγγιση: αξιοποίηση όρων & URLs αποτελεσμάτων για πιο ισορροπημένες συστοιχίες

4
Συστήματα Αλληλεπιδραστικού Ανασχηματισμού Ερωτημάτων (Interactive Query Reformulation Systems) Στόχος: σχηματισμός ακριβούς ερωτήματος i.Εντοπισμός ενδιαφερόντων χρήστη από τα υποβαλλόμενα ερωτήματα & δυνατότητα ανασύνταξης αυτών με εναλλακτικά ερωτήματα ii.Χρήση όρων που έχουν εξαχθεί από τα έγγραφα στα αποτελέσματα αναζήτησης (Π.χ. Paraphrase, Alta Vista Prisma, HiB: ανάλυση λίστας & χρήση των πιο συχνά εμφανιζόμενων όρων ως προτεινόμενους - Alta Vista, Askjeeves, Eurekster : συγχώνευση λειτουργιών προτεινόμενων όρων & τοποθέτηση σχετικού περιεχομένου) iii.Συνεργατικά ερωτήματα: υπολογισμός βάσει των logs, πρόταση ή επέκταση υποψήφιων όρων στο αρχικό ερώτημα Υπολογισμός ομοιότητας διαφορετικών ερωτημάτων & αυτόματο clustering
 iii.Συνεργατικά ερωτήματα: υπολογισμός βάσει των logs, πρόταση ή επέκταση υποψήφιων όρων στο αρχικό ερώτημα Υπολογισμός ομοιότητας διαφορετικών ερωτημάτων & αυτόματο clustering.")
5
Προσεγγίσεις για το clustering ερωτημάτων Με βάση το περιεχόμενο o Σύγκριση διανυσμάτων όρων βάσει συνημιτόνου ομοιότητας (Jaccard, Dice) o Καλά αποτελέσματα στο clustering λόγω του μεγάλου αριθμού όρων του εγγράφου o Προβλήματα: σύντομα ερωτήματα στις ΜΑ (2.35), πολλή πληροφορία, ένας όρος για διάφορες σημασίες, πολλοί όροι για μία σημασία Με βάση το αποτέλεσμα o Επικάλυψη επιστρεφόμενων εγγράφων o Πως; Μετατροπή αποτελεσμάτων εγγράφων σε διανύσματα συχνότητας όρων o Fitzpatrick & Dent: η σχετικότητα του εγγράφου εξαρτάται από την θέση του στην λίστα αποτελεσμάτων o Glance: επικάλυψη στα αποτελέσματα των URLs. Χρήση ενός αριθμού κοινών URLs στα 50 πρώτα επιστρεφόμενα αποτελέσματα από την ΜΑ

6
Σύστημα Συνεργατικών Ερωτημάτων Βασισμένο στις συστοιχίες ερωτημάτων που παράχθηκαν χρησιμοποιώντας ως μέτρο την υβριδική ομοιότητα ερωτήματος (hybrid query similarity) Διαδικασίες: i.Το σύστημα ‘αιχμαλωτίζει ’ το νέο ερώτημα ii.Ψάχνει για σχετικά έγγραφα iii.Αναγνωρίζει παρόμοια ερωτήματα & τα χρησιμοποιεί ως προτεινόμενα μαζί με τα αποτελέσματα αναζήτησης Οι χρήστες εξερευνούν περαιτέρω τα προτεινόμενα ερωτήματα μέσω της οπτικοποίησής τους (αρχικό & προτεινόμενα) Το σχήμα γραφικής οπτικοποίησης είναι ανεξάρτητος agent Γενικά: παρέχει πρόσθετη πληροφορία για την οποία ο χρήστης είχε αρχικά άγνοια & μπορεί να χρησιμοποιηθεί για τον σχηματισμό καλύτερου ερωτήματος ως προς την πληροφοριακή του ανάγκη.
 Διαδικασίες: i.Το σύστημα ‘αιχμαλωτίζει ’ το νέο ερώτημα ii.Ψάχνει για σχετικά έγγραφα iii.Αναγνωρίζει παρόμοια ερωτήματα & τα χρησιμοποιεί ως προτεινόμενα μαζί με τα αποτελέσματα αναζήτησης Οι χρήστες εξερευνούν περαιτέρω τα προτεινόμενα ερωτήματα μέσω της οπτικοποίησής τους (αρχικό & προτεινόμενα) Το σχήμα γραφικής οπτικοποίησης είναι ανεξάρτητος agent Γενικά: παρέχει πρόσθετη πληροφορία για την οποία ο χρήστης είχε αρχικά άγνοια & μπορεί να χρησιμοποιηθεί για τον σχηματισμό καλύτερου ερωτήματος ως προς την πληροφοριακή του ανάγκη.")
7
Αρχιτεκτονική συστήματος συνεργατικών ερωτημάτων

8
Δόμηση αποθετηρίου ερωτημάτων Δημιουργία cluster σχετικών ερωτημάτων & αποθήκευση σε αποθετήριο ερωτημάτων 2 ερωτήματα είναι παρόμοια αν: Περιέχουν έναν ή περισσότερους κοινούς όρους (προσέγγιση με βάση το περιεχόμενο) Έχουν αποτελέσματα που περιέχουν ένα ή περισσότερα αντικείμενα κοινά (προσέγγιση με βάση το αποτέλεσμα) Υβριδική προσέγγιση: Αντιστάθμιση των μειονεκτημάτων των παραπάνω μεθόδων με συνδυασμό των όρων ερωτήματος & των επιστρεφόμενων αποτελεσμάτων Λιγότερο χρονοβόρα μέθοδος Εναλλακτικοί αλγόριθμοι Πείραμα 20.000 ερωτήματα από την ΨΒ του Τεχνολογικού Παν/μίου Nanyang στην Σιγκαπούρη 16.000 ερωτήματα
 Έχουν αποτελέσματα που περιέχουν ένα ή περισσότερα αντικείμενα κοινά (προσέγγιση με βάση το αποτέλεσμα) Υβριδική προσέγγιση: Αντιστάθμιση των μειονεκτημάτων των παραπάνω μεθόδων με συνδυασμό των όρων ερωτήματος & των επιστρεφόμενων αποτελεσμάτων Λιγότερο χρονοβόρα μέθοδος Εναλλακτικοί αλγόριθμοι Πείραμα ερωτήματα από την ΨΒ του Τεχνολογικού Παν/μίου Nanyang στην Σιγκαπούρη ερωτήματα")
9
Πρωτόκολλο πειράματος Δημιουργία διαφορετικών συνόλων clusters ερωτημάτων βάσει διαφόρων προσεγγίσεων Υποβολή ερωτήματος σε μια ΜΑ (ΨΒ Nanyang) & ανάκτηση των URLs από τα επιστρεφόμενα αποτελέσματα 10 πρώτα URLs από τα επιστρεφόμενα αποτελέσματα Τα URLs χρησιμοποιήθηκαν για τον υπολογισμό της ομοιότητας Καθορισμός τιμών & παραμέτρων του αλγορίθμου Μέτρηση ποιότητας των clusters ερωτημάτων με το F-measure (συνδυασμός ακρίβειας & ανάκλησης με εύρος τιμών 0-1) Όσο αυξάνει το F-measure τόσο καλύτερη είναι η ποιότητα του cluster ερωτημάτων
 & ανάκτηση των URLs από τα επιστρεφόμενα αποτελέσματα 10 πρώτα URLs από τα επιστρεφόμενα αποτελέσματα Τα URLs χρησιμοποιήθηκαν για τον υπολογισμό της ομοιότητας Καθορισμός τιμών & παραμέτρων του αλγορίθμου Μέτρηση ποιότητας των clusters ερωτημάτων με το F-measure (συνδυασμός ακρίβειας & ανάκλησης με εύρος τιμών 0-1) Όσο αυξάνει το F-measure τόσο καλύτερη είναι η ποιότητα του cluster ερωτημάτων")
10
F-measure για διαφορετικές προσεγγίσεις

11
Πρόταση ερωτήματος – Εντοπισμός σχετικών ερωτημάτων Μεθοδολογία: Το σύστημα εντοπίζει τα cluster του ερωτήματος που περιέχουν το αρχικό ερώτημα Όλα τα μέλη σχετίζονται απευθείας με το cluster του ερωτήματος (1 ο επίπεδο) Εκτός από το cluster του ερωτήματος, το σύστημα θα βρει & άλλα cluster ερωτημάτων που περιέχουν τα μέλη του αρχικού cluster. Παράδειγμα: αν το Q1 είναι μέλος στο cluster G(Qi), το σύστημα θα υπολογίσει το cluster ερωτήματος G(Q1) – 2 ο επίπεδο
, το σύστημα θα υπολογίσει το cluster ερωτήματος G(Q1) – 2 ο επίπεδο.")
12
Εντοπισμός σχετικών ερωτημάτων

13
Ενημέρωση αποθετηρίου ερωτημάτων Το σύστημα ενσωματώνει τα νέα ερωτήματα & προτείνει τα πιο πρόσφατα χρησιμοποιούμενα Γίνεται offline Τα νέα ερωτήματα θα συγκριθούν με τα ήδη υπάρχοντα & θα ενσωματωθούν στην ΒΔ μόνο αν είναι μοναδικά

14
Ενημέρωση αποθετηρίου ερωτημάτων

15
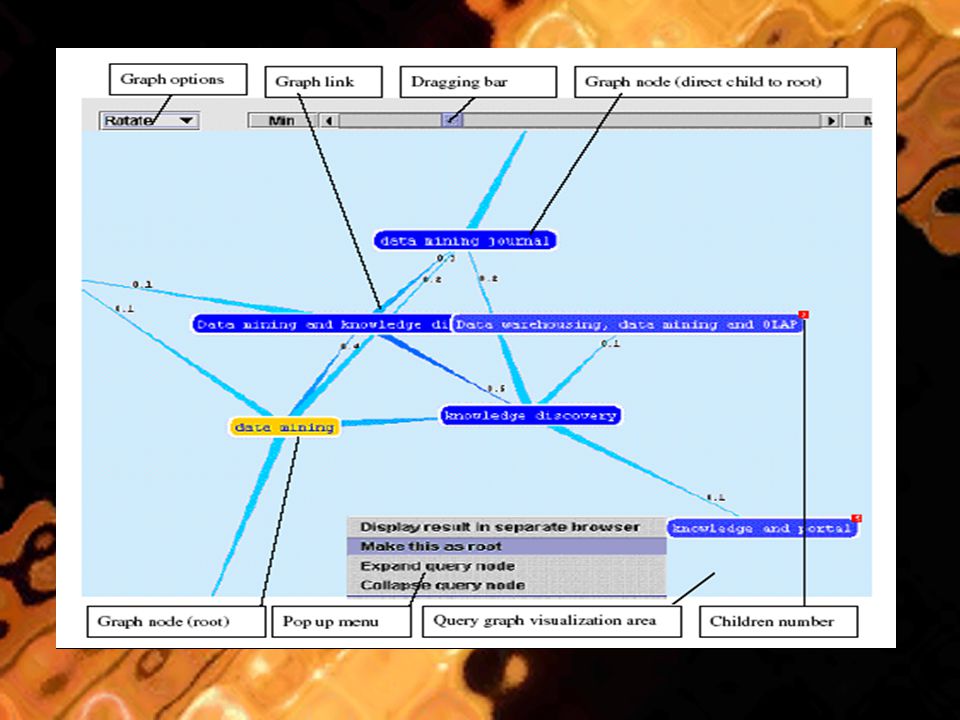
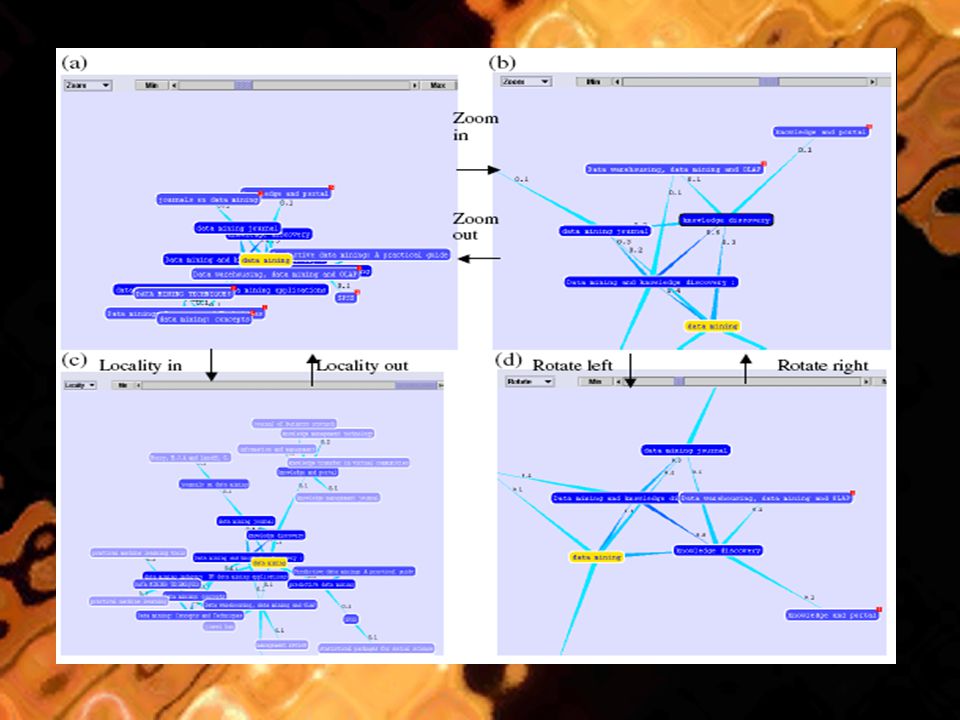
Οπτικοποίηση του cluster ερωτήματος Εμφάνιση των clusters ερωτημάτων με μορφή γράφου Οι άκρες δείχνουν την σχέση μεταξύ 2 κόμβων του γράφου & η τιμή δηλώνει την δύναμη της σχέσης Μπάρα ελέγχου (εστίαση, περιστροφή, τοπική εστίαση) Με δεξί κλικ στον κόμβο ο χρήστης μπορεί να το χρησιμοποιήσει σε μια ΜΑ Μπορεί να διεξαχθεί νέα αναζήτηση στο αποθετήριο ερωτημάτων με το ίδιο ερώτημα Κάθε κόμβος ερωτήματος στον γράφο μπορεί να επεκταθεί ή να καταργηθεί Ο αριθμός δίπλα στον κόμβο δηλώνει πόσα παιδιά του κόμβου δεν έχουν ακόμα επεκταθεί
 Με δεξί κλικ στον κόμβο ο χρήστης μπορεί να το χρησιμοποιήσει σε μια ΜΑ Μπορεί να διεξαχθεί νέα αναζήτηση στο αποθετήριο ερωτημάτων με το ίδιο ερώτημα Κάθε κόμβος ερωτήματος στον γράφο μπορεί να επεκταθεί ή να καταργηθεί Ο αριθμός δίπλα στον κόμβο δηλώνει πόσα παιδιά του κόμβου δεν έχουν ακόμα επεκταθεί")
18
Συμπεράσματα - Προβληματισμοί Με την υβριδική προσέγγιση παράγονται καλύτερα clusters σε σχέση με κάθε μέθοδο ξεχωριστά Για κάθε ερώτημα δημιουργείται cluster ερωτημάτων με την υβριδική μέτρηση ομοιότητας (hybrid query similarity measure) σε συστήματα συνεργατικών ερωτημάτων Η καινοτομία: οι υπόλοιπες προσεγγίσεις για την οπτικοποίηση ενσωματώνουν μόνο κείμενο ή HTML Μπορούν να χρησιμοποιηθούν τα συστήματα συνεργατικών ερωτημάτων σε συνδυασμό με την Εξατομίκευση; Μπορούν να παραχθούν καλύτερα αποτελέσματα χρησιμοποιώντας την Διαγλωσσική Ανάκτηση;
 σε συστήματα συνεργατικών ερωτημάτων Η καινοτομία: οι υπόλοιπες προσεγγίσεις για την οπτικοποίηση ενσωματώνουν μόνο κείμενο ή HTML Μπορούν να χρησιμοποιηθούν τα συστήματα συνεργατικών ερωτημάτων σε συνδυασμό με την Εξατομίκευση; Μπορούν να παραχθούν καλύτερα αποτελέσματα χρησιμοποιώντας την Διαγλωσσική Ανάκτηση;")













 Βαρειά Βασιλική (Β2002066) Βαρειά Βασιλική (Β2002066)>")
 (Ι) Είναι μια δομή στην οποία αποθηκεύονται τα ονόματα ενός προγράμματος και.>")





