Κατέβασμα παρουσίασης
1
ΕΞΌΡΥΞΗ ΔΕΔΟΜΈΝΩΝ ΚΑΙ ΑΛΓΌΡΙΘΜΟΙ ΜΆΘΗΣΗΣ Κατηγοριοποίηση 4 ο Φροντιστήριο Σκούρα Αγγελική skoura@ceid.upatras.gr

2
Κατηγοριοποίηση (Classification) Σκοπός: Learn a method for predicting the instance class from pre-labeled (classified) instances Συνήθεις Τεχνικές: 1) Δέντρα Αποφάσεων (Decision Trees) 2) Νευρωνικά Δίκτυα (Neural Networks) 3) K-πλησιέστερων γειτόνων (k-Nearest Neighbors, k- NN) 4) Μηχανές Υποστήριξης Διανυσμάτων (Support Vector Machines, SVMs) 5) Bayesian μέθοδοι Στηρίζεται στην ιδέα της «εκπαίδευσης» με τη βοήθεια ενός υποσυνόλου δεδομένων (σύνολο εκπαίδευσης)
 Σκοπός: Learn a method for predicting the instance class from pre-labeled (classified) instances Συνήθεις Τεχνικές: 1) Δέντρα Αποφάσεων (Decision Trees) 2) Νευρωνικά Δίκτυα (Neural Networks) 3) K-πλησιέστερων γειτόνων (k-Nearest Neighbors, k- NN) 4) Μηχανές Υποστήριξης Διανυσμάτων (Support Vector Machines, SVMs) 5) Bayesian μέθοδοι Στηρίζεται στην ιδέα της «εκπαίδευσης» με τη βοήθεια ενός υποσυνόλου δεδομένων (σύνολο εκπαίδευσης)")
3
Classification process Classifier Training Training dataModel Testing dataModel Predicted scores/labels Training Phase Testing Phase Classifier parameters

4
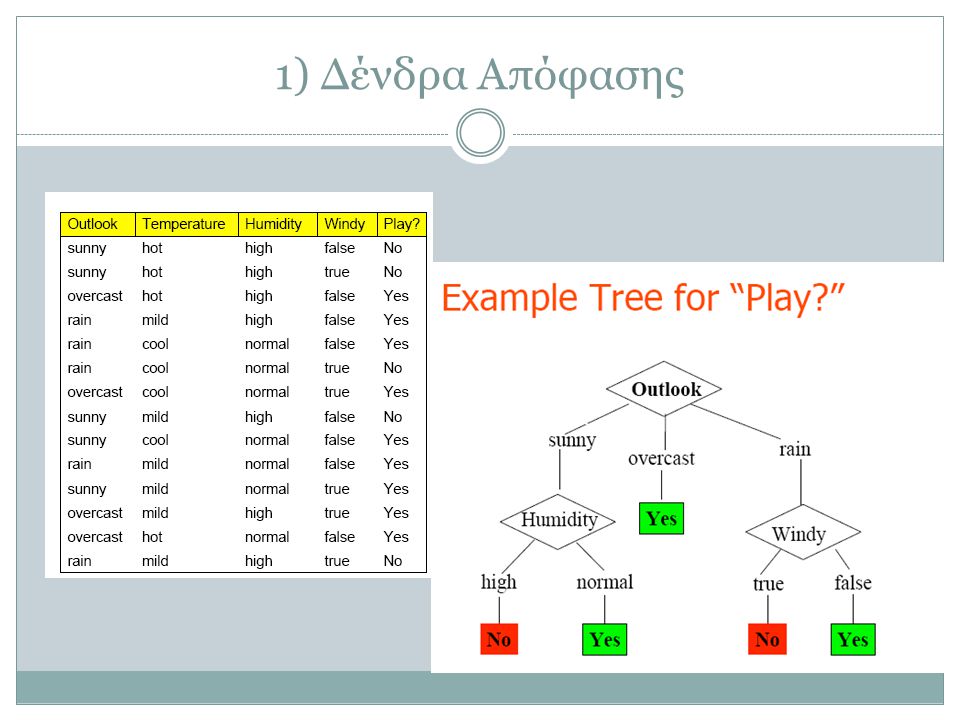
1) Δένδρα Απόφασης
 Δένδρα Απόφασης")
6
2) Νευρωνικά Δίκτυα
 Νευρωνικά Δίκτυα")
7
Οι νευρώνες είναι το δομικό στοιχείο του δικτύου. Υπάρχουν δύο είδη νευρώνων, οι νευρώνες εισόδου και οι υπολογιστικοί νευρώνες. – Οι νευρώνες εισόδου δεν υπολογίζουν τίποτα, μεσολαβούν ανάμεσα στις εισόδους του δικτύου και τους υπολογιστικούς νευρώνες. – Οι υπολογιστικοί νευρώνες πολλαπλασιάζουν τις εισόδους τους με τα συναπτικά βάρη και υπολογίζουν το άθροισμα του γινομένου. Το άθροισμα που προκύπτει είναι το όρισμα της συνάρτησης μεταφοράς. Συνάρτηση μεταφοράς, η οποία μπορεί να είναι: – βηματική (step), – γραμμική (linear), – μη γραμμική (non-linear), – στοχαστική (stochastic).
, – γραμμική (linear), – μη γραμμική (non-linear), – στοχαστική (stochastic)..")
8
3) k-πλησιέστεροι γείτονες The k-NN Rule: If the number of pre-classified points is large it makes good sense to use, instead of the single nearest neighbor, the majority vote of the nearest k neighbors. This method is referred to as the k-NN rule. The number k should be: large to minimize the probability of misclassifying x small (with respect to the number of samples) so that the points are close enough to x to give an accurate estimate of the true class of x Παραλλαγές: Weighted K-nn
 so that the points are close enough to x to give an accurate estimate of the true class of x Παραλλαγές: Weighted K-nn.")
9
4) Μηχανές Διανυσμάτων Υποστήριξης Οι Μηχανές Υποστήριξης Διανυσμάτων είναι μια μέθοδος μηχανικής μάθησης για δυαδικά προβλήματα κατηγοριοποίησης Προβάλλουν τα σημεία του συνόλου εκπαίδευσης σε έναν χώρο περισσοτέρων διαστάσεων και βρίσκουν το υπερεπίπεδο το οποίο διαχωρίζει βέλτιστα τα σημεία των δύο τάξεων Τα άγνωστα σημεία ταξινομούνται σύμφωνα με την πλευρά του υπερεπίπεδου στην οποία βρίσκονται Τα διανύσματα τα οποία ορίζουν το υπερεπίπεδο που χωρίζει τις δύο τάξεις ονομάζονται διανύσματα υποστήριξης (support vectors)
 Μηχανές Διανυσμάτων Υποστήριξης Οι Μηχανές Υποστήριξης Διανυσμάτων είναι μια μέθοδος μηχανικής μάθησης για δυαδικά προβλήματα κατηγοριοποίησης Προβάλλουν τα σημεία του συνόλου εκπαίδευσης σε έναν χώρο περισσοτέρων διαστάσεων και βρίσκουν το υπερεπίπεδο το οποίο διαχωρίζει βέλτιστα τα σημεία των δύο τάξεων Τα άγνωστα σημεία ταξινομούνται σύμφωνα με την πλευρά του υπερεπίπεδου στην οποία βρίσκονται Τα διανύσματα τα οποία ορίζουν το υπερεπίπεδο που χωρίζει τις δύο τάξεις ονομάζονται διανύσματα υποστήριξης (support vectors)")
10
5) Bayesian Μέθοδοι Βασίζεται στη πιθανοτική θεωρία κατηγοριοποίησης του κανόνα του Bayes Στόχος είναι να κατηγοριοποιηθεί ένα δείγμα Χ σε μια από τις δεδομένες κατηγορίες C1,C2,..,Cn χρησιμοποιώντας ένα μοντέλο πιθανότητας που ορίζεται σύμφωνα με τη θεωρία του Bayes Πρόκειται για κατηγοριοποιητές που κάνουν αποτίμηση πιθανοτήτων και όχι πρόβλεψη Αυτό πολλές φορές είναι πιο χρήσιμο και αποτελεσματικό Εδώ οι προβλέψεις έχουν έναν βαθμό και σκοπός είναι το αναμενόμενο κόστος να ελαχιστοποιείται
 Bayesian Μέθοδοι Βασίζεται στη πιθανοτική θεωρία κατηγοριοποίησης του κανόνα του Bayes Στόχος είναι να κατηγοριοποιηθεί ένα δείγμα Χ σε μια από τις δεδομένες κατηγορίες C1,C2,..,Cn χρησιμοποιώντας ένα μοντέλο πιθανότητας που ορίζεται σύμφωνα με τη θεωρία του Bayes Πρόκειται για κατηγοριοποιητές που κάνουν αποτίμηση πιθανοτήτων και όχι πρόβλεψη Αυτό πολλές φορές είναι πιο χρήσιμο και αποτελεσματικό Εδώ οι προβλέψεις έχουν έναν βαθμό και σκοπός είναι το αναμενόμενο κόστος να ελαχιστοποιείται")
11
Evaluation which method works best for classification No classification model is uniformly the best Comparison by means of Accuracy, precision, sensitivity, specificity, … Speed of training Speed of model application Noise tolerance Explanation ability Many times: hybrid, integrated models

12
Μετρικές Αξιολόγησης Μεθόδων Κατηγοριοποίησης Χρόνος Εκπαίδευσης Χρόνος Εκτέλεσης Ανοχή στο Θόρυβο Χρήση Προϋπάρχου σας Γνώσης Ακρίβεια Κατανοησιμ ότητα Δέντρα Απόφασης Μικρός ΜικρήΌχιΜέτριαΚαλή Νευρωνικά Δίκτυα Μεγάλος Μικρός ΚαλήΌχιΚαλήΜικρή Bayesian Μέθοδοι ΜεγάλοςΜικρός ΚαλήΝαιΚαλή “Αδρή” Σύγκριση Βασικών Μεθόδων Κατηγοριοποίησης

13
Evaluation: Is my model good? Evaluation metrics: accuracy, precision-recall, Area Under ROC Curve (AUC)… Evaluation options: Train-Test Split Use train Use test Random split Cross Validation 3/5/10 folds Leave-one-out 13
… Evaluation options: Train-Test Split Use train Use test Random split Cross Validation 3/5/10 folds Leave-one-out 13.")
14
Evaluation metrics Sensitivity or True Positive Rate (TPR) eqv. with hit rate, recall TPR = TP / P = TP / (TP + FN) False Positive Rate (FPR) eqv. with fall out FPR = FP / N = FP / (FP + TN) Accuracy ACC = (TP + TN) / (P + N) Positive Predictive Value (PPV) eqv. with precision PPV = TP / (TP + FP) actual value pntotal prediction outcome p' True Positive False Positive P' n' False Negative True Negativ e N' totalPN
 False Positive Rate (FPR) eqv. with fall out FPR = FP / N = FP / (FP + TN) Accuracy ACC = (TP + TN) / (P + N) Positive Predictive Value (PPV) eqv. with precision PPV = TP / (TP + FP) actual value pntotal prediction outcome p True Positive False Positive P n False Negative True Negativ e N totalPN.")
15
Evaluation metrics: F - score The F score can be interpreted as a weighted average of the precision and recall F score reaches its best value at 1 and worst score at 0 The traditional F-measure or balanced F-score (F score) is the harmonic mean of precision and recall:
 is the harmonic mean of precision and recall:")
16
Παράδειγμα υπολογισμού μετρικών ακρίβειας Έχοντας ως δεδομένα τα ακόλουθα αποτελέσματα ενός αλγορίθμου κατηγοριοποίησης, υπολογίστε τις μετρικές TPrate FPrate Precision Recall F-measure === Confusion Matrix === a b c d e f g <-- classified as 41 0 0 0 0 0 0 | a 0 20 0 0 0 0 0 | b 0 0 3 1 0 1 0 | c 0 0 0 13 0 0 0 | d 0 0 1 0 3 0 0 | e 0 0 0 0 0 5 3 | f 0 0 0 0 0 2 8 | g

17
Διαφορά μεταξύ Precision και Accuracy Accuracy is how close a measurement comes to the truth Precision is how close a measurement comes to another measurement Low precision implies uncertainty

18
ROC καμπύλη In signal detection theory, a receiver operating characteristic (ROC) or simply ROC curve, is a graphical plot of true positive rate vs. false positive rate for a binary classifier system as its discrimination threshold is variedsignal detection theory graphical binary classifier Ο κατακόρυφος άξονας: Tprate = Sensitivity Ο οριζόντιος άξονας: Fprate = 1- Specificity Accuracy is measured by the area under the ROC curve an area of 1 represents a perfect test an area of.5 represents a worthless test

19
Παράδειγμα κατασκευής ROC καμπύλης Ερώτημα Υποθέτουμε ότι υπάρχουν 2 κλάσεις για τα δεδομένα diseased (“positive”, P) and healthy (“negative”, N). Δεδομένα 20 παρατηρήσεις εκ των οποίων 10 είναι Ν και 10 είναι P οι 10 Ν παρατηρήσεις έχουν τιμές N = {0.3,0.4,0.5,0.5,0.5,0.6,0.7,0.7,0.8,0.9}; οι 10 P παρατηρήσεις έχουν τιμές P = {0.5,0.6,0.6,0.8,0.9,0.9,0.9,1.0,1.2,1.4} Έστω ο αλγόριθμος κατηγοριοποίησης For a given value of the threshold, t, the classification rule predicts that an observation belongs to P if it is greater than t Να κατασκευαστεί η ROC καμπύλη Λύση To construct the ROC curve, they first set the threshold, t, to be a large value. Consider progressively lowering the value of t. For any value greater than or equal to 1.4, all 20 observations are allocated to group N, so no P individuals are allocated to P (hence tp = 0.0) and all the N individuals are allocated to N (hence fp = 0.0). Μoving t down to 1.2, one individual (the last) in group P is now allocated to N (hence tp = 0.1) while all the N individuals are still allocated to N (hence fp = 0.0 again). Continuing in this fashion generates the ROC curve.
 and all the N individuals are allocated to N (hence fp = 0.0). Μoving t down to 1.2, one individual (the last) in group P is now allocated to N (hence tp = 0.1) while all the N individuals are still allocated to N (hence fp = 0.0 again). Continuing in this fashion generates the ROC curve..")
20
Evaluation options

22
Επιπλέον σημεία που απαιτούν προσοχή κατά την κατηγοριοποίηση Υπερταύτιση (Overfitting) Unbalanced datasets
 Unbalanced datasets")
23
Overfitting Η «υπερταύτιση» αποτελεί ένα σύνηθες πρόβλημα κατά την κατασκευή κατηγοριοποιητών Overfitting/Overtraining in supervised learning (e.g. neural network). Training error is shown in blue, validation error in red. If the validation error increases while the training error steadily decreases then a situation of overfitting may have occurred.neural network
. Training error is shown in blue, validation error in red. If the validation error increases while the training error steadily decreases then a situation of overfitting may have occurred.neural network.")
24
Unbalanced datasets

25
Making most of the data

26
Not only Weka…Many classification tools Kernel SVM: libsvm, svmlightlibsvmsvmlight Linear SVM/LogReg: liblinearliblinear LogReg: BBKBBK Naïve Bayes, Decision Trees: WekaWeka Bagging, Boosting on trees: FESTFEST rpart package, Orange, Waffle, Shogun, Sgd, etc. 26

27
Ευχαριστώ για την προσοχή σας…












 Χωρικές / χρονικές π ολυ π λοκότητες δομών δεικτοδότησης Ε π ικοινωνία με το.>")









