Κατέβασμα παρουσίασης
Η παρουσίαση φορτώνεται. Παρακαλείστε να περιμένετε

1
Εξόρυξη Δεδομένων και Αλγόριθμοι Μάθησης
Κατηγοριοποίηση Εξόρυξη Δεδομένων και Αλγόριθμοι Μάθησης 5ο Φροντιστήριο Αντωνέλλης Παναγιώτης Σκούρα Αγγελική

2
Βασικοί Στόχοι της Εξόρυξης Δεδομένων
Classification: predicting an item class Clustering: finding clusters in data Associations: e.g. A & B & C occur frequently Visualization: to facilitate human discovery Summarization: describing a group Deviation Detection: finding changes Estimation: predicting a continuous value Link Analysis: finding relationships …

3
Data Mining Data Mining is an interdisciplinary field involving:
– Databases – Statistics – Machine Learning – High Performance Computing – Visualization – Mathematics

4
Κατηγοριοποίηση (Classification)
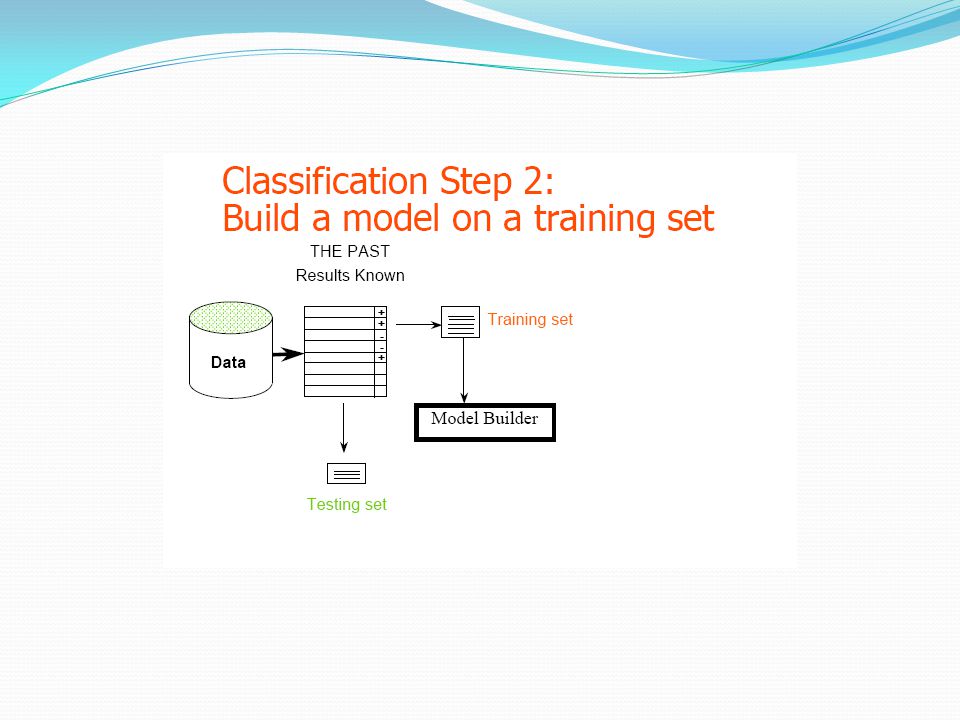
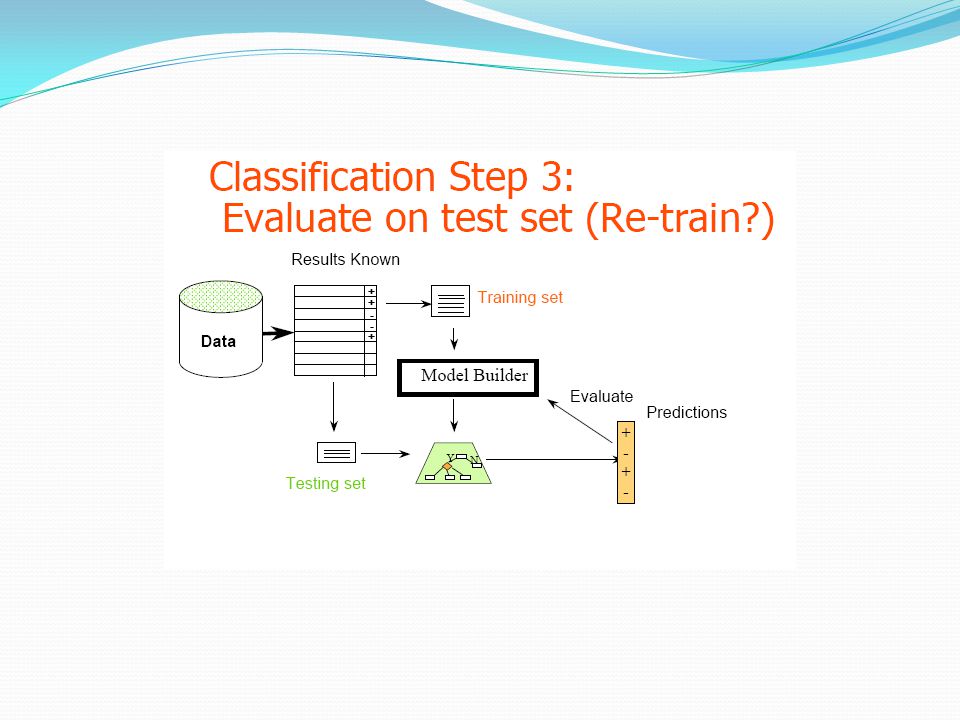
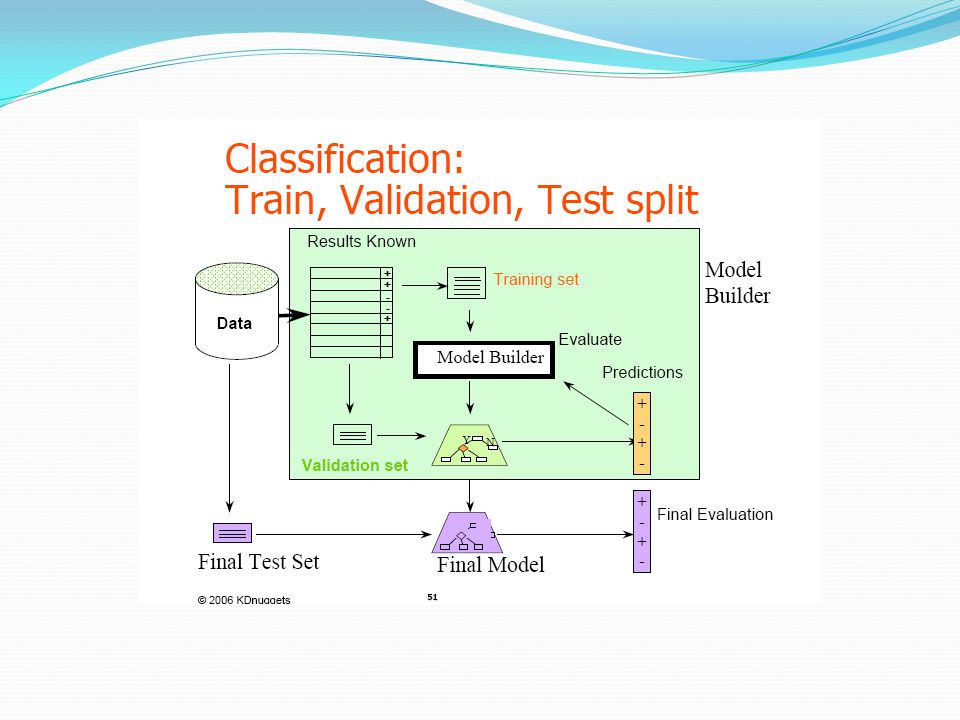
Σκοπός: Learn a method for predicting the instance class from pre-labeled (classified) instances Συνήθεις Τεχνικές: Δέντρα Αποφάσεων (Decision Trees) Νευρωνικά Δίκτυα (Neural Networks) K-πλησιέστερων γειτόνων (k-Nearest Neighbors, k-NN) Μηχανές Υποστήριξης Διανυσμάτων (Support Vector Machines, SVM) Bayesian μέθοδοι Στηρίζονται στην ιδέα της «εκπαίδευσης» με τη βοήθεια ενός υποσυνόλου δεδομένων (σύνολο εκπαίδευσης)
 instances. Συνήθεις Τεχνικές: Δέντρα Αποφάσεων (Decision Trees) Νευρωνικά Δίκτυα (Neural Networks) K-πλησιέστερων γειτόνων (k-Nearest Neighbors, k-NN) Μηχανές Υποστήριξης Διανυσμάτων (Support Vector Machines, SVM) Bayesian μέθοδοι. Στηρίζονται στην ιδέα της «εκπαίδευσης» με τη βοήθεια ενός υποσυνόλου δεδομένων (σύνολο εκπαίδευσης)")
5
Συσταδοποίηση (Clustering)
Σκοπός: Find “natural” grouping of instances given un-labeled data Συνήθεις Τεχνικές: Διαιρετικοί αλγόριθμοι (K-Means) Ιεραρχικοί αλγόριθμοι (Cure) Βασισμένοι σε γράφους αλγόριθμοι (Chameleon) Βασισμένοι στην πυκνότητα (DBSCAN) Βασισμένοι σε πλέγμα (WaveCluster) Στηρίζονται στην ιδέα της «εκπαίδευσης» με τη βοήθεια ενός υποσυνόλου δεδομένων (σύνολο εκπαίδευσης)
 Ιεραρχικοί αλγόριθμοι (Cure) Βασισμένοι σε γράφους αλγόριθμοι (Chameleon) Βασισμένοι στην πυκνότητα (DBSCAN) Βασισμένοι σε πλέγμα (WaveCluster) Στηρίζονται στην ιδέα της «εκπαίδευσης» με τη βοήθεια ενός υποσυνόλου δεδομένων (σύνολο εκπαίδευσης)")
6
Classification VS Clustering
Supervised Learning Unsupervised Learning

7
Κανόνες Συσχέτισης (Association Rules)
")
8
Οπτικοποίηση (Visulization)
Σκοπός: Η οπτικοποίηση των δεδομένων για να διευκολυνθεί η κατανόηση συσχετίσεων Π.χ. Self-Organizes Maps (SOMs) SOMs are commonly used as visualization aids. They can make it easy for us humans to see relationships between vast amounts of data A SOM has been used to classify statistical data describing various quality-of-life factors such as state of health, nutrition, educational services etc.
 SOMs are commonly used as visualization aids. They can make it easy for us humans to see relationships between vast amounts of data. A SOM has been used to classify statistical data describing various quality-of-life factors such as state of health, nutrition, educational services etc.")
9
Οπτικοποίηση (Visulization)
Countries with similar quality-of-life factors end up clustered together. The countries with better quality-of-life are situated toward the upper left and the most poverty stricken countries are toward the lower right. Each hexagon represents a node in the SOM.

10
Οπτικοποίηση (Visulization)
This colour information can then be plotted onto a map of the world like so:

11
Τεχνικές Κατηγοριοποίησης
Συνήθεις Τεχνικές: Συσχέτιση (Regression) Δέντρα Απόφασης (Decision Trees) Νευρωνικά Δίκτυα (Neural Networks) K-πλησιέστερων γειτόνων (k-Nearest Neighbors, k-NN) Μηχανές Υποστήριξης Διανυσμάτων (Support Vector Machines, SVM) Bayesian μέθοδοι Εργαλείο Weka Attribute-Relation File Format (ARFF)
 Δέντρα Απόφασης (Decision Trees) Νευρωνικά Δίκτυα (Neural Networks) K-πλησιέστερων γειτόνων (k-Nearest Neighbors, k-NN) Μηχανές Υποστήριξης Διανυσμάτων (Support Vector Machines, SVM) Bayesian μέθοδοι. Εργαλείο Weka. Attribute-Relation File Format (ARFF)")
12
1) Γραμμική Συσχέτιση
 Γραμμική Συσχέτιση")
13
2) Δένδρα Απόφασης
 Δένδρα Απόφασης")
14
2) Δένδρα Απόφασης
 Δένδρα Απόφασης")
15
3) Νευρωνικά Δίκτυα
 Νευρωνικά Δίκτυα")
16
3) Νευρωνικά Δίκτυα Συνάρτηση Μεταφοράς, η οποία μπορεί να είναι:
Οι νευρώνες είναι το δομικό στοιχείο του δικτύου. Υπάρχουν δύο είδη νευρώνων, οι νευρώνες εισόδου και οι υπολογιστικοί νευρώνες. Οι νευρώνες εισόδου δεν υπολογίζουν τίποτα, μεσολαβούν ανάμεσα στις εισόδους του δικτύου και τους υπολογιστικούς νευρώνες. Οι υπολογιστικοί νευρώνες πολλαπλασιάζουν τις εισόδους τους με τα συναπτικά βάρη και υπολογίζουν το άθροισμα του γινομένου. Το άθροισμα που προκύπτει είναι το όρισμα της συνάρτησης μεταφοράς. Συνάρτηση Μεταφοράς, η οποία μπορεί να είναι: βηματική (step), γραμμική (linear), μη γραμμική (non-linear), στοχαστική (stochastic).
, γραμμική (linear), μη γραμμική (non-linear), στοχαστική (stochastic).")
17
4) k-πλησιέστεροι γείτονες
The k-NN Rule: If the number of pre-classified points is large it makes good sense to use, instead of the single nearest neighbor, the majority vote of the nearest k neighbors. This method is referred to as the k-NN rule. The number k should be: 1) large to minimize the probability of misclassifying x 2) small (with respect to the number of samples) so that the points are close enough to x to give an accurate estimate of the true class of x Παραλλαγές: Weighted K-nn
 large to minimize the probability of misclassifying x 2) small (with respect to the number of samples) so that the points are close enough to x to give an accurate estimate of the true class of x. Παραλλαγές: Weighted K-nn.")
18
5) Μηχανές Διανυσμάτων Υποστήριξης
Οι Μηχανές Υποστήριξης Διανυσμάτων είναι μια μέθοδος μηχανικής μάθησης για δυαδικά προβλήματα ταξινόμησης Προβάλλουν τα σημεία του συνόλου εκπαίδευσης σε έναν χώρο περισσοτέρων διαστάσεων και βρίσκουν το υπερεπίπεδο το οποίο διαχωρίζει βέλτιστα τα σημεία των δύο τάξεων Τα άγνωστα σημεία ταξινομούνται σύμφωνα με την πλευρά του υπερεπίπεδου στην οποία βρίσκονται Τα διανύσματα τα οποία ορίζουν το υπερεπίπεδο που χωρίζει τις δύο τάξεις ονομάζονται διανύσματα υποστήριξης (support vectors)
")
19
6) Bayesian Μέθοδοι Βασίζεται στη πιθανοτική θεωρία κατηγοριοποίησης του κανόνα του Bayes Στόχος είναι να κατηγοριοποιηθεί ένα δείγμα Χ σε μια από τις δεδομένες κατηγορίες C1,C2,..,Cn χρησιμοποιώντας ένα μοντέλο πιθανότητας που ορίζεται σύμφωνα με τη θεωρία του Bayes Πρόκειται για κατηγοριοποιητές που κάνουν αποτίμηση πιθανοτήτων και όχι πρόβλεψη Αυτό πολλές φορές είναι πιο χρήσιμο και αποτελεσματικό Εδώ οι προβλέψεις έχουν έναν βαθμό και σκοπός είναι το αναμενόμενο κόστος να ελαχιστοποιείται

21
Σύγκριση Βασικών Μεθόδων Κατηγοριοποίησης
Μετρικές Αξιολόγησης Μεθόδων Κατηγοριοποίησης Χρόνος Εκπαίδευσης Χρόνος Εκτέλεσης Ανοχή στο Θόρυβο Χρήση Προϋπάρχουσας Γνώσης Ακρίβεια Κατανοησιμότητα Δέντρα Απόφασης Μικρός Μικρή Όχι Μέτρια Καλή Νευρωνικά Δίκτυα Μεγάλος Bayesian Μέθοδοι Ναι

22
Μετρικές Ακρίβειας Sensitivity or true positive rate (TPR) eqv. with hit rate, recall TPR = TP / P = TP / (TP + FN) False positive rate (FPR) eqv. with fall out FPR = FP / N = FP / (FP + TN) Accuracy ACC = (TP + TN) / (P + N) Positive predictive value (PPV) eqv. with precision PPV = TP / (TP + FP) actual value p n total prediction outcome p' True Positive False Positive P' n' False Negative True Negative N' P N
 eqv. with fall out. FPR = FP / N = FP / (FP + TN) Accuracy. ACC = (TP + TN) / (P + N) Positive predictive value (PPV) eqv. with precision. PPV = TP / (TP + FP) actual value. p. n. total. prediction. outcome. p True Positive. False Positive. P n False Negative. True Negative. N P. N.")
23
F - score The F score can be interpreted as a weighted average of the precision and recall, where an F score reaches its best value at 1 and worst score at 0. The traditional F-measure or balanced F-score (F score) is the harmonic mean of precision and recall:
 is the harmonic mean of precision and recall:")
24
Overfitting/Overtraining in supervised learning (e. g. neural network)
Overfitting/Overtraining in supervised learning (e.g. neural network). Training error is shown in blue, validation error in red. If the validation error increases while the training error steadily decreases then a situation of overfitting may have occurred.
. Training error is shown in blue, validation error in red. If the validation error increases while the training error steadily decreases then a situation of overfitting may have occurred.")
37
Ευχαριστώ για την προσοχή σας…

Παρόμοιες παρουσιάσεις















>")

 Εξόρυξη Γνώσης Από Χωρικά Δεδομένα Φροντιστήριο Αγγελική Σκούρα (skoura@ceid.upatras.gr)>")
>")




:το αντικείμενο μάθησης Υπόδειγμα(instance):το ξεχωριστό και ανεξάρτητο παράδειγμα(example) ενός concept Χαρακτηριστικό(attribute):η.>")





