Κατέβασμα παρουσίασης
Η παρουσίαση φορτώνεται. Παρακαλείστε να περιμένετε

2
ΠΡΟΛΟΓΟΣ Η ερώτηση: Μπορεί μια ενιαία στατιστική μεθοδολογία να απαντήσει σε προβλήματα επεξεργασίας φυσικής γλώσσας πού εμφανίζουν μια ομοιότητα ως προς το στόχο, ο οποίος είναι η επιλογή μεταξύ ανταγωνιζόμενων οντοτήτων; Παραδείγματα Ανταγωνιζόμενα έγγραφα στην ανάκτηση πληροφορίας. (Information Retrieval) ‘Έννοιες μιας λέξης στο πλαίσιο (context) που εμφανίζεται. (Word Sense Disambiguation) Ανταγωνισμός λέξεων για την δημιουργία Collocations (Συνεκφερόμενες λέξεις)
 ‘Έννοιες μιας λέξης στο πλαίσιο (context) που εμφανίζεται. (Word Sense Disambiguation) Ανταγωνισμός λέξεων για την δημιουργία Collocations (Συνεκφερόμενες λέξεις).")
3
ΠΡΟΛΟΓΟΣ Στατιστική: Ο κλάδος που εφαρμόστηκε με την μεγαλύτερη επιτυχία στην Επεξεργασία Φυσικής Γλώσσας (Natural Language Processing) Παραδείγματα Στα συστήματα για αναζήτηση πληροφορίας (Information Retrieval: IR) Αποσαφήνιση της έννοιας μιας λέξης (Word Sense Disambiguation: WSD) O σχηματισμός συνεκφερόμενων λέξεων (Collocation) Αλλά και Κατηγοριοποίηση Κειμένου (Text Categorization) Απλοποίηση Κειμένου (Text Simplification)
 Παραδείγματα Στα συστήματα για αναζήτηση πληροφορίας (Information Retrieval: IR) Αποσαφήνιση της έννοιας μιας λέξης (Word Sense Disambiguation: WSD) O σχηματισμός συνεκφερόμενων λέξεων (Collocation) Αλλά και Κατηγοριοποίηση Κειμένου (Text Categorization) Απλοποίηση Κειμένου (Text Simplification)")
4
ΠΡΟΛΟΓΟΣ Σκοπός της Διατριβής: Να αναδείξει την εφαρμογή μιας ενιαίας Στατιστικής μεθοδολογίας για τους παραπάνω τομείς έρευνας Συγκεκριμένα, ανάπτυξη συστημάτων για: Την εύρεση συνεκφερόμενων λέξεων (collocations) σε κείμενα φυσικής γλώσσας, Την αναζήτηση πληροφορίας με βάση το ερώτημα ενός χρήστη (information retrieval), και Την αποσαφήνιση της έννοιας μιας λέξης από τα συμφραζόμενά της (word sense disambiguation).
 σε κείμενα φυσικής γλώσσας, Την αναζήτηση πληροφορίας με βάση το ερώτημα ενός χρήστη (information retrieval), και Την αποσαφήνιση της έννοιας μιας λέξης από τα συμφραζόμενά της (word sense disambiguation).")
5
ΠΡΟΛΟΓΟΣ Η ανάκτηση πληροφορίας (Information Retrieval) είναι κλάδος της Επεξεργασίας Φυσικής Γλώσσας πού ασχολείται με την ανάπτυξη αλγορίθμων και μοντέλων για την αναζήτηση πληροφορίας από διάφορες συλλογές κειμένων (Internet, document depositories). Με την αναγέννηση των ποσοτικών μεθόδων επεξεργασίας φυσικής γλώσσας, οι στατιστικές μέθοδοι έγιναν η κυρίαρχη προσέγγιση ανάπτυξης συστημάτων για ανάκτηση πληροφορίας.

6
ΠΡΟΛΟΓΟΣ Word Sense Disambiguation: Ο κλάδος που ασχολείται με την αποσαφήνιση της έννοιας μιας λέξης μέσα στα συμφραζόμενα της Οι στατιστικές μέθοδοι θεωρούνται ως το αποκλειστικό εργαλείο για την ανάπτυξη συστημάτων Αποσαφήνισης Εννοιών. Τέτοια συστήματα είναι πολύ χρήσιμα και βοηθούν τη μηχανική μετάφραση και την κατανόηση κειμένου

7
ΠΡΟΛΟΓΟΣ Collocations: Eίναι η εύρεση συνεκφερόμενων λέξεων (collocations), λέξεων δηλαδή πού εμφανίζονται πολύ συχνά μαζί και σχηματίζουν ένα νέο σημασιολογικό όρο με σημασία διαφορετική των σημασιών των συνιστωσών μερών. Παραδείγματος χάριν η έκφραση «Γερό Ποτήρι»

8
Κίνητρο Η Επεξεργασία Φυσικής Γλώσσας είναι αναμφισβήτητα επιστημονικός κλάδος με προοπτική. Όλα τα προηγούμενα προβλήματα είναι εξαιρετικά δύσκολα και η επίλυσή τους αναμένεται να επηρεάσει καταλυτικά τις εφαρμογές Υπολογιστικής Γλωσσολογίας και ιδιαίτερα τον κλάδο της Τεχνητής Νοημοσύνης Μέχρι τώρα πολλές μέθοδοι και συστήματα έχουν προταθεί στην διεθνή βιβλιογραφία για την επίλυση τέτοιων προβλημάτων αλλά με τρόπο αποσπασματικό. Διαχωρίζοντας μεταξύ τους τα προβλήματα, παρατηρείται ανάπτυξη διαφορετικών μεθόδων για το κάθε πρόβλημα Αποτέλεσμα: αλγόριθμοι και τεχνικές που δουλεύουν για μια περιοχή της Επεξεργασίας Φυσικής Γλώσσας να μην μπορούν να εφαρμοσθούν σε άλλη.

9
Η ιδέα Τα περισσότερα προβλήματα επεξεργασίας φυσικής γλώσσας εμφανίζουν ένα κοινό χαρακτηριστικό, αυτό της επιλογής μεταξύ ανταγωνιζόμενων οντοτήτων για κάποιο συγκεκριμένο στόχο. Παραδείγματα Ανταγωνιζόμενα έγγραφα στην ανάκτηση πληροφορίας που ανταγωνίζονται ως προς τον στόχο πού είναι η συνάφεια με το ερώτημα (query) ενός χρήστη, ανταγωνιζόμενες έννοιες στην αποσαφήνιση της έννοιας μιας λέξης, ή ανταγωνιζόμενα ζευγάρια λέξεων για τον σχηματισμό collocations. Η παρούσα διατριβή αναδεικνύει αυτό το χαρακτηριστικό και απαντάει με μία ενιαία στατιστική μεθοδολογία για την επίλυση των παραπάνω προβλημάτων, συμβάλλοντας στην ολιστική αξιοποίηση της επιστημονικής γνώσης.
 ενός χρήστη, ανταγωνιζόμενες έννοιες στην αποσαφήνιση της έννοιας μιας λέξης, ή ανταγωνιζόμενα ζευγάρια λέξεων για τον σχηματισμό collocations. Η παρούσα διατριβή αναδεικνύει αυτό το χαρακτηριστικό και απαντάει με μία ενιαία στατιστική μεθοδολογία για την επίλυση των παραπάνω προβλημάτων, συμβάλλοντας στην ολιστική αξιοποίηση της επιστημονικής γνώσης..")
10
Η μεθοδολογία Στη Στατιστική είναι πολύ καλά θεμελιωμένοι οι έλεγχοι καλού ταιριάσματος (Goodness of statistical tests), οι οποίοι ελέγχουν κατά πόσο καλά ταιριάζουν τα δεδομένα σε μια υποκείμενη θεωρητική υπόθεση που θεωρούμε ότι τα διέπει. Στη διατριβή χρησιμοποιείται ο ‘Χ-τετράγωνον’ στατιστικός έλεγχος «καλού ταιριάσματος», (Chi-square Goodness of Fit Statistical Test) για την αποτίμηση της σχετικότητας με το στόχο της κάθε ανταγωνιζόμενης οντότητας. Πιο συγκεκριμένα, διατυπώνεται μια μηδενική υπόθεση (null hypothesis) ότι οι διάφορες ανταγωνιζόμενες οντότητες δεν επιδεικνύουν καμία ιδιαίτερη συμπεριφορά έναντι του στόχου πέραν της τυχαίας. Αυτή είναι η θεωρητική υπόθεση που γίνεται για τα δεδομένα
 για την αποτίμηση της σχετικότητας με το στόχο της κάθε ανταγωνιζόμενης οντότητας. Πιο συγκεκριμένα, διατυπώνεται μια μηδενική υπόθεση (null hypothesis) ότι οι διάφορες ανταγωνιζόμενες οντότητες δεν επιδεικνύουν καμία ιδιαίτερη συμπεριφορά έναντι του στόχου πέραν της τυχαίας. Αυτή είναι η θεωρητική υπόθεση που γίνεται για τα δεδομένα.")
11
Η μεθοδολογία Από τα πραγματικά δεδομένα καταγράφεται η πραγματική συμπεριφορά της κάθε ανταγωνιζόμενης οντότητας και πιστοποιείται έτσι μια διαφορά (discrepancy) μεταξύ της πραγματικής συμπεριφοράς και αυτής πού απορρέει από την θεωρητική υπόθεση. Η διαφορά αυτή ποσοτικοποιείται με την βοήθεια της ‘X2 κατανομής’ και αυτή η ποσοτικοποίηση είναι ικανή να χρησιμοποιηθεί ως μέτρο της αποτίμησης της σχετικότητας της ανταγωνιζόμενης οντότητας με το στόχο (ranking criterion).
..")
12
Τι ακολουθεί Αρχικά, παρουσιάζουμε μια εισαγωγή των στατιστικών μοντέλων που χρησιμοποιούνται στην επεξεργασία φυσικής γλώσσας καθώς επίσης κα των μέτρων αποτίμησης της αποδοτικότητας των συστημάτων αυτών Ακολουθεί η εφαρμογή των στατιστικών ελέγχων στην ανάκτηση πληροφορίας (Information Retrieval). Μέσα στο ίδιο στατιστικό πλαίσιο, παρουσιάζουμε ένα σύστημα για αναζήτηση κειμενικής πληροφορίας από “δεξαμενές” εγγράφων (document repositories) με βάση το ερώτημα ενός χρήστη. Στην συνέχεια, παρουσιάζουμε στατιστικές μεθόδους για την “ανακάλυψη” συνεκφερόμενων λέξεων μέσα σε Ελληνικά κείμενα (Collocations) και ‘θεμελιώνουμε ένα τρόπο εφαρμογής των στατιστικών ελέγχων στην περιοχή αυτή
 με βάση το ερώτημα ενός χρήστη. Στην συνέχεια, παρουσιάζουμε στατιστικές μεθόδους για την ανακάλυψη συνεκφερόμενων λέξεων μέσα σε Ελληνικά κείμενα (Collocations) και ‘θεμελιώνουμε ένα τρόπο εφαρμογής των στατιστικών ελέγχων στην περιοχή αυτή.")
13
Τι ακολουθεί Τέλος εφαρμόζουμε τους στατιστικούς ελέγχους στην περιοχή της αποσαφήνισης της έννοιας μιας λέξης (Word Sense Disambiguation). Ένα στατιστικό σύστημα αναπτύσσεται για την αποσαφήνιση της έννοιας μια λέξης από τα συμφραζόμενά της κάνοντας χρήση του ηλεκτρονικού λεξικού WordNet σαν λεξικολογική πηγή. Τα συμπεράσματα που προκύπτουν μετά από αποτίμηση των μεθόδων πού αναπτύξαμε πάνω σε πειραματικά δεδομένα ελέγχου, είναι ότι τα στατιστικά αυτά συστήματα αποδεικνύονται “εύρωστα” και ικανά να δώσουν αποτελέσματα καλύτερα από αυτά των κλασσικών μεθόδων

14
ΕΙΣΑΓΩΓΗ Η στατιστική είναι ο κλάδος της μαθηματικής επιστήμης που έχει χρησιμοποιηθεί ευρύτατα στην Επεξεργασία Φυσικής Γλώσσας (ΕΦΓ) Η αλματώδη εξέλιξη της πληροφορικής τα τελευταία χρόνια και η διαθεσιμότητα μεγάλου όγκου κειμένων σε ψηφιακή μορφή, δημιούργησαν τις συνθήκες για την αναγέννηση των ποσοτικών μεθόδων στην (ΕΦΓ) Με την αναγέννηση των ποσοτικών μεθόδων επεξεργασίας φυσικής γλώσσας, οι στατιστικές μέθοδοι έγιναν η κυρίαρχη προσέγγιση ανάπτυξης συστημάτων για ανάκτηση πληροφορίας
 Η αλματώδη εξέλιξη της πληροφορικής τα τελευταία χρόνια και η διαθεσιμότητα μεγάλου όγκου κειμένων σε ψηφιακή μορφή, δημιούργησαν τις συνθήκες για την αναγέννηση των ποσοτικών μεθόδων στην (ΕΦΓ) Με την αναγέννηση των ποσοτικών μεθόδων επεξεργασίας φυσικής γλώσσας, οι στατιστικές μέθοδοι έγιναν η κυρίαρχη προσέγγιση ανάπτυξης συστημάτων για ανάκτηση πληροφορίας")
15
ΕΙΣΑΓΩΓΗ Οι στατιστικές μέθοδοι θεωρούνται ως το αποκλειστικό εργαλείο για την ανάπτυξη συστημάτων για την Αναζήτηση Πληροφορίας (Word Sense Disambiguation), αποσαφήνιση λεκτικής σημασίας (Word Sense Disambiguation), κατηγοριοποίηση κειμένου, εύρεση Collocations κλπ Οι στατιστικές μέθοδοι θεωρούνται ως το αποκλειστικό εργαλείο για την ανάπτυξη συστημάτων για την Αναζήτηση Πληροφορίας (Word Sense Disambiguation), αποσαφήνιση λεκτικής σημασίας (Word Sense Disambiguation), κατηγοριοποίηση κειμένου, εύρεση Collocations κλπ Τα προβλήματα αυτά αναγνωρίζονται σαν υπολογιστικά πολύπλοκα προβλήματα στην επεξεργασία φυσικής γλώσσας και η επίλυσή τους αναμένεται να επηρεάσει καταλυτικά την εξέλιξη του κλάδου της υπολογιστικής γλωσσολογίας (Computational Linguistics) Τα προβλήματα αυτά αναγνωρίζονται σαν υπολογιστικά πολύπλοκα προβλήματα στην επεξεργασία φυσικής γλώσσας και η επίλυσή τους αναμένεται να επηρεάσει καταλυτικά την εξέλιξη του κλάδου της υπολογιστικής γλωσσολογίας (Computational Linguistics)
, αποσαφήνιση λεκτικής σημασίας (Word Sense Disambiguation), κατηγοριοποίηση κειμένου, εύρεση Collocations κλπ Οι στατιστικές μέθοδοι θεωρούνται ως το αποκλειστικό εργαλείο για την ανάπτυξη συστημάτων για την Αναζήτηση Πληροφορίας (Word Sense Disambiguation), αποσαφήνιση λεκτικής σημασίας (Word Sense Disambiguation), κατηγοριοποίηση κειμένου, εύρεση Collocations κλπ Τα προβλήματα αυτά αναγνωρίζονται σαν υπολογιστικά πολύπλοκα προβλήματα στην επεξεργασία φυσικής γλώσσας και η επίλυσή τους αναμένεται να επηρεάσει καταλυτικά την εξέλιξη του κλάδου της υπολογιστικής γλωσσολογίας (Computational Linguistics) Τα προβλήματα αυτά αναγνωρίζονται σαν υπολογιστικά πολύπλοκα προβλήματα στην επεξεργασία φυσικής γλώσσας και η επίλυσή τους αναμένεται να επηρεάσει καταλυτικά την εξέλιξη του κλάδου της υπολογιστικής γλωσσολογίας (Computational Linguistics)")
16
Στατιστικά Μοντέλα στην επεξεργασία φυσικής γλώσσας Η έρευνα στα στατιστικά συστήματα επεξεργασίας φυσικής γλώσσας ασχολείται με την ανάπτυξη αλγορίθμων και συστημάτων για την αναπαράσταση, αποθήκευση, οργάνωση, επεξεργασία και προσπέλαση των στοιχείων της πληροφορίας. Η έρευνα στα στατιστικά συστήματα επεξεργασίας φυσικής γλώσσας ασχολείται με την ανάπτυξη αλγορίθμων και συστημάτων για την αναπαράσταση, αποθήκευση, οργάνωση, επεξεργασία και προσπέλαση των στοιχείων της πληροφορίας. Οι πρώτες προσπάθειες για αναπαράσταση και ανάκτηση πληροφορίας ξεκίνησαν με τα συστήματα αναζήτησης πληροφορίας. Αν και παραδοσιακά ο κλάδος ασχολιόταν μόνο με την αναζήτηση κειμένων και την εύρεση εγγράφων, σήμερα, υπάρχει έντονο ενδιαφέρον και για άλλες μορφές πληροφορίας. Οι πρώτες προσπάθειες για αναπαράσταση και ανάκτηση πληροφορίας ξεκίνησαν με τα συστήματα αναζήτησης πληροφορίας. Αν και παραδοσιακά ο κλάδος ασχολιόταν μόνο με την αναζήτηση κειμένων και την εύρεση εγγράφων, σήμερα, υπάρχει έντονο ενδιαφέρον και για άλλες μορφές πληροφορίας. Η αναπαράσταση της πληροφορίας σε υπολογίσιμη μορφή παίζει καθοριστικό ρόλο στην ανάπτυξη συστημάτων επεξεργασίας φυσικής γλώσσας. Η αναπαράσταση της πληροφορίας σε υπολογίσιμη μορφή παίζει καθοριστικό ρόλο στην ανάπτυξη συστημάτων επεξεργασίας φυσικής γλώσσας.

17
Μοντέλα Αναπαράστασης Πληροφορίας Ανάλογα με την φύση της διαδικασίας αναπαράστασης ενός κειμένου σαν σύνολο από λέξεις κλειδιά, μπορούμε να κατατάξουμε τα πιο σημαντικά μοντέλα αναπαράστασης πληροφορίας στις εξής κύριες κατηγορίες: Δυαδικά μοντέλα (Boolean models) Διανυσματικά μοντέλα (Vector models) Πιθανοτικά μοντέλα (probabilistic models)
 Διανυσματικά μοντέλα (Vector models) Πιθανοτικά μοντέλα (probabilistic models)")
18
Μοντέλα Αναπαράστασης Πληροφορίας Δυαδικά μοντέλα: Το δυαδικό μοντέλο είναι το πιο απλό μοντέλο το οποίο βασίζεται στην θεωρία συνόλων και την Boolean άλγεβρα Η πληροφορία αναπαρίσταται υπό μορφή σειράς ψηφίων 0 και 1. Το 1 δηλώνει την παρουσία ενός όρου και το 0 την απουσία υποφέρει από αρκετά μειονεκτήματα. Πχ, δυσκολία που υπάρχει στο Information Retrieval να εκφρασθεί ένα ερώτημα σε Boolean έκφραση από τον χρήστη

19
Μοντέλα Αναπαράστασης Πληροφορίας Το διανυσματικό μοντέλο Το διανυσματικό μοντέλο [1], [2], είναι το πρώτο μοντέλο που εφαρμόστηκε πρώτα στην αναζήτηση πληροφορίας. Σύμφωνα με το διανυσματικό μοντέλο, κάθε όρος k j σε μια κειμενική πληροφορία, χαρακτηρίζεται με ένα θετικό μη μηδενικό πραγματικό αριθμό που καλείται βάρος (weight) και εκφράζει την σημαντικότητα τού όρου στον προσδιορισμό της σημασιολογίας του κειμένου
![Μοντέλα Αναπαράστασης Πληροφορίας Το διανυσματικό μοντέλο Το διανυσματικό μοντέλο [1], [2], είναι το πρώτο μοντέλο που εφαρμόστηκε πρώτα στην αναζήτηση πληροφορίας.](http://images.slideplayer.gr/10/2849982/slides/slide_19.jpg " Σύμφωνα με το διανυσματικό μοντέλο, κάθε όρος k j σε μια κειμενική πληροφορία, χαρακτηρίζεται με ένα θετικό μη μηδενικό πραγματικό αριθμό που καλείται βάρος (weight) και εκφράζει την σημαντικότητα τού όρου στον προσδιορισμό της σημασιολογίας του κειμένου.")
20
Το διανυσματικό μοντέλο στην Αναζήτηση Πληροφορίας Στην Αναζήτηση Πληροφορίας Μπορούμε να αναπαραστήσουμε ένα έγγραφο dj σαν ένα διάνυσμα (w 1j, w 2j, …, w t,j ), όπου t το πλήθος όρων Ένα ερώτημα q σαν (w 1q, w 2q, …, w tq ),
, όπου t το πλήθος όρων Ένα ερώτημα q σαν (w 1q, w 2q, …, w tq ),")
21
Το διανυσματικό μοντέλο στην Αναζήτηση Πληροφορίας Μπορούμε έπειτα να χρησιμοποιήσουμε το συνημίτονο της γωνίας (cosine) μεταξύ των δύο διανυσμάτων για να βρούμε την ομοιότητα μεταξύ των δύο πληροφοριών
 μεταξύ των δύο διανυσμάτων για να βρούμε την ομοιότητα μεταξύ των δύο πληροφοριών")
22
Τα βάρη στην σημασιολογία του κειμένου Για τον καθορισμό του βάρους ενός όρου καθοριστικό ρόλο παίζουν η συχνότητα του όρου στο κείμενο του εγγράφου Ο αριθμός του εγγράφων στα οποία συμμετέχει ο όρος Αυτά θα μπορούσαμε να τα συνδυάσουμε σε ένα μοναδικό βάρος Tf-idf σχήματα

23
Πιθανοτικά Μοντέλα Στα πιθανοτικά μοντέλα η εμφάνιση ενός όρου μοντελοποιείται σαν ένα “συμβάν” και του αποδίδεται μια πιθανότητα. Όσο μεγαλύτερη είναι η πιθανότητα εμφάνισης ενός όρου, τόσο πιο σημαντικός είναι ο ρόλος του στον καθορισμό της σημασιολογίας της πληροφορίας.

24
Πιθανοτικά Μοντέλα Πρόσφατα μια νέα προσέγγιση, η μοντελοποίηση γλώσσας (language Modeling) έχει προταθεί στα παραδοσιακά διανυσματικά και τα άλλα πιθανοτικά μοντέλα. Έχει εφαρμοσθεί με επιτυχία στα συστήματα Αναζήτησης Πληροφορίας [8], [9], [10], [11]. Ένα στατιστικό μοντέλο γλώσσας είναι ένας πιθανοτικός μηχανισμός παραγωγής κειμένου.

25
Πιθανοτικά Μοντέλα Η καταγωγή του μοντέλου γλώσσας ανάγεται στην εποχή του Shannon [12], ο οποίος διατύπωσε την πολύ γνωστή θεωρία του στον τομέα των επικοινωνιών (source channel perspective) O Shannon μελέτησε κατά πόσο τα απλά (ν- γράμματα) μοντέλα (n-gram models) μπορούν να προβλέψουν φυσικό κείμενο Έχει εφαρμοσθεί με επιτυχία στην Αναγνώριση Λόγου (Speech Recognition)
![Πιθανοτικά Μοντέλα Η καταγωγή του μοντέλου γλώσσας ανάγεται στην εποχή του Shannon [12], ο οποίος διατύπωσε την πολύ γνωστή θεωρία του στον τομέα των επικοινωνιών (source channel perspective) O Shannon μελέτησε κατά πόσο τα απλά (ν- γράμματα) μοντέλα (n-gram models) μπορούν να προβλέψουν φυσικό κείμενο Έχει εφαρμοσθεί με επιτυχία στην Αναγνώριση Λόγου (Speech Recognition)](http://images.slideplayer.gr/10/2849982/slides/slide_25.jpg "Πιθανοτικά Μοντέλα Η καταγωγή του μοντέλου γλώσσας ανάγεται στην εποχή του Shannon [12], ο οποίος διατύπωσε την πολύ γνωστή θεωρία του στον τομέα των επικοινωνιών (source channel perspective) O Shannon μελέτησε κατά πόσο τα απλά (ν- γράμματα) μοντέλα (n-gram models) μπορούν να προβλέψουν φυσικό κείμενο Έχει εφαρμοσθεί με επιτυχία στην Αναγνώριση Λόγου (Speech Recognition)")
26
Πιθανοτικά Μοντέλα Το μοντέλο γλώσσας εφαρμόστηκε για πρώτη φορά σε εφαρμογές επεξεργασίας πληροφορίας κειμένου από τους Ponte και Croft το 1998 στην Ανάκτηση Πληροφορίας [8]. Στα κλασικά πιθανοτικά μοντέλα Αναζήτησης Πληροφορίας [3], [5], [13], [14], υπάρχει η ανάγκη να κατανείμουμε μια μάζα πιθανότητας (Probability mass) πάνω σε ένα τεράστιο χώρο πιθανών τιμών (εκβάσεων) για τον κάθε όρο (unigram language model) Εξαιρετικά Δύσκολο. Η μόνη ένδειξη τις περισσότερες φορές είναι οι όροι του ερωτήματος
![Πιθανοτικά Μοντέλα Το μοντέλο γλώσσας εφαρμόστηκε για πρώτη φορά σε εφαρμογές επεξεργασίας πληροφορίας κειμένου από τους Ponte και Croft το 1998 στην Ανάκτηση Πληροφορίας [8].](http://images.slideplayer.gr/10/2849982/slides/slide_26.jpg "Στα κλασικά πιθανοτικά μοντέλα Αναζήτησης Πληροφορίας [3], [5], [13], [14], υπάρχει η ανάγκη να κατανείμουμε μια μάζα πιθανότητας (Probability mass) πάνω σε ένα τεράστιο χώρο πιθανών τιμών (εκβάσεων) για τον κάθε όρο (unigram language model) Εξαιρετικά Δύσκολο. Η μόνη ένδειξη τις περισσότερες φορές είναι οι όροι του ερωτήματος.")
27
Πιθανοτικά Μοντέλα Οι Ponte και Croft [8], αντιμετώπισαν το ζήτημα με μια αντίστροφη προσέγγιση. Χρησιμοποιώντας μια smoothed εκδοχή του unigram language model, πρότειναν μια μέθοδο να αποδώσουν μια τιμή πιθανοφάνειας (likelihood score), από το έγγραφο στο ερώτημα. Αυτή η προσέγγιση είναι γνωστή σαν “language modeling Approach” Ένα μοντέλο γλώσσας θεωρείται σαν ένα θορυβώδες κανάλι ή “noisy channel” ή “translation channel”, το οποίο απεικονίζει τα έγγραφα στα ερωτήματα
![Πιθανοτικά Μοντέλα Οι Ponte και Croft [8], αντιμετώπισαν το ζήτημα με μια αντίστροφη προσέγγιση.](http://images.slideplayer.gr/10/2849982/slides/slide_27.jpg "Χρησιμοποιώντας μια smoothed εκδοχή του unigram language model, πρότειναν μια μέθοδο να αποδώσουν μια τιμή πιθανοφάνειας (likelihood score), από το έγγραφο στο ερώτημα. Αυτή η προσέγγιση είναι γνωστή σαν language modeling Approach Ένα μοντέλο γλώσσας θεωρείται σαν ένα θορυβώδες κανάλι ή noisy channel ή translation channel , το οποίο απεικονίζει τα έγγραφα στα ερωτήματα.")
28
Evaluation Measures Μέτρα Αποτίμησης των συστημάτων Επεξεργασίας Φυσικής Γλώσσας

29
Μέτρα Αποτίμησης Περιγράφουμε τα μέτρα Αποτίμησης που θα χρησιμοποιήσουμε στην Ανάκτηση Πληροφορίας και στα συστήματα Αποσαφήνισης Εννοιών. Τα μέτρα αυτά εφαρμόζονται και γενικότερα στα συστήματα Επεξεργασίας Φυσικής Γλώσσας

30
Μέτρα Αποτίμησης Συστημάτων ΕΦΓ Precision και Recall Ας εξηγήσουμε τις έννοιες με όρους από την σκοπιά του Information Retrieval και θα γενικεύσουμε. Έστω ότι στο σύστημα Αναζήτησης Πληροφορίας υποβάλλεται ένα ερώτημα q. Εάν R το σύνολο των σχετικών εγγράφων με αυτό το ερώτημα και A το σύνολο των εγγράφων πού επέστρεψε το σύστημα

31
Μέτρα Αποτίμησης Συστημάτων ΕΦΓ Επί πλέον έστω |Ra| ο αριθμός των εγγράφων στην τομή (Intersection) των R και A Recall = Precision =
 των R και A Recall = Precision =")
32
Μέτρα Αποτίμησης Συστημάτων ΕΦΓ Δηλαδή για ένα σύστημα Επεξεργασίας Precision είναι το ποσοστό των Επιτυχιών στο σύνολο των Απαντήσεων του συστήματος Recall είναι το ποσοστό των επιτυχιών στο σύνολο των σωστών Απαντήσεων που υπάρχει. Συνηθίζουμε να αναπαριστούμε την καμπύλη Precision versus Recall Μάλιστα σε συγκεκριμένα ποσοστά του Recall 0%, 10%, 20%,,100% Τότε μιλάμε για Precision Versus Recall at 11 Recall Points

33
Εφαρμογή των Στατιστικών Ελέγχων στην Ανάκτηση Πληροφορίας

34
Στα περισσότερα μοντέλα που χρησιμοποιούμε για την Αναζήτηση Πληροφορίας ενδιαφερόμαστε να εκτιμήσουμε πόσο “καλά” το μοντέλο του εγγράφου (document model) “ταιριάζει” στην πληροφοριακή ανάγκη του χρήστη (query model). Από την άλλη πλευρά στην στατιστική, υπάρχουν καλά θεμελιωμένες τεχνικές για την εκτίμηση του κατά πόσο ένα μοντέλο “ταιριάζει” με κάποιο άλλο μοντέλο Φράγγος Κων/νος – Στατιστικοί Έλεγχοι στην Επεξεργασία Φυσικής Γλώσσας Η Βασική Ιδέα.

35
Οι στατιστικοί έλεγχοι καλού “ταιριάσματος” (Goodness of fit statistical tests) είναι πολύ γνωστές μέθοδοι για την εκτίμηση της υπόθεσης του κατά πόσο ένα θεωρητικό μοντέλο «περιγράφει» καλά ένα σύνολο δεδομένων. Στη βασική θέση της διατριβής αναπτύσσουμε μια τεχνική για Αναζήτηση Πληροφορίας η οποία στηρίζεται στον Χ- τετράγωνο έλεγχο καλού “ταιριάσματος” για να εκτιμήσουμε πόσο “καλά” το μοντέλο του εγγράφου ταριάζει στην πληροφοριακή ανάγκη του χρήστη Η Βασική Ιδέα.

36
Η τεχνική αυτή εκτός του ότι αποδεικνύεται ιδιαίτερα αποδοτική, είναι και ευέλικτη. Μπορεί να προσαρμοσθεί και σε διαφορετικά προβλήματα, εκεί όπου υπεισέρχεται η έννοια της εκτίμησης του “ταιριάσματος”, όπως πχ στην αποσαφήνιση της έννοιας μιας λέξης. Εφαρμογή των Στατιστικών Ελέγχων στην Ανάκτηση Πληροφορίας

37
Φράγγος Κων/νος – Στατιστικοί Έλεγχοι στην Επεξεργασία Φυσικής Γλώσσας Η λογική είναι απλή. Διατυπώνουμε μια βασική υπόθεση για τα δεδομένα γνωστή και ως “μηδενική υπόθεση” Σύμφωνα με αυτή: Θεωρούμε ότι δεν υπάρχει καμία ιδιαίτερη σχέση ή δεσμός μεταξύ του ερωτήματος (query) και ενός συγκεκριμένου εγγράφου, εκτός από το ότι οι όροι του ερωτήματος μπορεί να εμφανισθούν σε αυτό το έγγραφο από “τύχη” και μόνο Υλοποίηση Για να εκτιμήσουμε την υπόθεση αυτή εκτελούμε ένα Χ-τετράγωνο στατιστικό έλεγχο (Goodness of Fit Statistical Test) και με την βοήθεια του ελέγχου αυτού εκτιμούμε την σχετικότητα του εγγράφου με το ερώτημα του Χρήστη.
 και ενός συγκεκριμένου εγγράφου, εκτός από το ότι οι όροι του ερωτήματος μπορεί να εμφανισθούν σε αυτό το έγγραφο από τύχη και μόνο Υλοποίηση Για να εκτιμήσουμε την υπόθεση αυτή εκτελούμε ένα Χ-τετράγωνο στατιστικό έλεγχο (Goodness of Fit Statistical Test) και με την βοήθεια του ελέγχου αυτού εκτιμούμε την σχετικότητα του εγγράφου με το ερώτημα του Χρήστη..")
38
Η μέθοδος αυτή εκτιμήθηκε πάνω στα επίσημα TREC δεδομένα για έλεγχο της αποδοτικότητας των Information Retrieval συστημάτων Η αποδοτικότητά της σταθερά πιο πάνω από τα κλασσικά tf-idf σχήματα και την OKAPI μέθοδο Πλεονεκτήματα Μη παραμετρική μέθοδος για Information Retrieval Προκύπτουν απλοί τύποι Αναζήτησης Πληροφορίας Εναλλακτικοί τρόποι μοντελοποίηση Εγγράφων και Ερωτημάτων

39
Εισαγωγή στα Στατιστικά μοντέλα Γλώσσας Διανυσματικά μοντέλα (vector Space models) Πιθανοτικά μοντέλα (Probabilistic models) Language Modeling Approach
 Πιθανοτικά μοντέλα (Probabilistic models) Language Modeling Approach")
40
Διανυσματικό μοντέλο. Προτάθηκε από τον Salton [2] το 1972. Μοντελοποιεί τα έγγραφα και τα ερωτήματα ως διανύσματα και χρησιμοποιεί διανυσματικές μετρικές για να εκτιμήσει την σχετικότητα. Ακόμα και σήμερα βρίσκεται σε χρήση. Πιθανοτικό μοντέλο. Προτάθηκε από τους Robertson και Sparck-Jones [3] το 1975. Χρησιμοποιεί την πιθανότητα εμφάνισης ενός όρου αντί της συχνότητας που χρησιμοποιείται στο Διανυσματικό μοντέλο, και εκτιμά την σχετικότητα του ερωτήματος με το έγγραφο χρησιμοποιώντας κατανομές Παραλλαγές Naïve Bayesian Networks [13] Inquery Retrieval System [14] OKAPI system
![Διανυσματικό μοντέλο. Προτάθηκε από τον Salton [2] το](http://images.slideplayer.gr/10/2849982/slides/slide_40.jpg "Μοντελοποιεί τα έγγραφα και τα ερωτήματα ως διανύσματα και χρησιμοποιεί διανυσματικές μετρικές για να εκτιμήσει την σχετικότητα. Ακόμα και σήμερα βρίσκεται σε χρήση. Πιθανοτικό μοντέλο. Προτάθηκε από τους Robertson και Sparck-Jones [3] το Χρησιμοποιεί την πιθανότητα εμφάνισης ενός όρου αντί της συχνότητας που χρησιμοποιείται στο Διανυσματικό μοντέλο, και εκτιμά την σχετικότητα του ερωτήματος με το έγγραφο χρησιμοποιώντας κατανομές Παραλλαγές Naïve Bayesian Networks [13] Inquery Retrieval System [14] OKAPI system.")
41
Language Modeling Approach Προτάθηκε to 1998 από τους Ponte και Croft [8] Χρησιμοποιεί τα στατιστικά μοντέλα γλώσσας με όμοιο τρόπο όπως αυτά χρησιμοποιούνται στο Speech Recognition και έχουν την καταγωγή τους από την εποχή του Shannon με το μοντέλο του θορυβώδες καναλιού (noisy channel) [12]. Τα συστήματα αυτά αποδίδουν καλά αλλά έχουν το μειονέκτημα ότι είναι παραμετρικά και χρειάζονται εκτίμηση παραμέτρων πάνω σε training data Παραλλαγές Hidden Markov Models [48],[11] Translation Models [10]
![Language Modeling Approach Προτάθηκε to 1998 από τους Ponte και Croft [8] Χρησιμοποιεί τα στατιστικά μοντέλα γλώσσας με όμοιο τρόπο όπως αυτά χρησιμοποιούνται στο Speech Recognition και έχουν την καταγωγή τους από την εποχή του Shannon με το μοντέλο του θορυβώδες καναλιού (noisy channel) [12].](http://images.slideplayer.gr/10/2849982/slides/slide_41.jpg "Τα συστήματα αυτά αποδίδουν καλά αλλά έχουν το μειονέκτημα ότι είναι παραμετρικά και χρειάζονται εκτίμηση παραμέτρων πάνω σε training data Παραλλαγές Hidden Markov Models [48],[11] Translation Models [10].")
42
Η δικιά μας Προσέγγιση Goodness of Fit (GOF) Αναζήτηση Για να βαθμολογήσουμε τα διάφορα έγγραφα βασιζόμαστε στον Χ-τετράγωνο στατιστικό έλεγχο Ο Χ-τετράγωνο έλεγχος περιγράφει το πόσο “καλά” μια υπόθεση (μηδενική υπόθεση), στην οποία θεωρούμε ότι υπόκεινται τα δεδομένα ταιριάζει με τα δεδομένα Πιο συγκεκριμένα διατυπώνουμε την μηδενική υπόθεση ότι όλοι οι όροι του ερωτήματος κατανέμονται “τυχαία” στα διάφορα έγγραφα Μετράμε την συχνότητα κάθε όρου στο έγγραφο (observed) και την συγκρίνουμε με την μηδενική υπόθεση (expected). Εάν η διαφορά είναι μεγάλη αυτό είναι ένδειξη “συσχέτισης” του ερωτήματος με το έγγραφο.

43
Στατιστικοί Έλεγχοι “Καλού” Ταιριάσματος Τα στατιστικά προβλήματα ανάγονται συνήθως στον Έλεγχο για την επιλογή μιας από δύο εναλλακτικές υποθέσεις: Την μηδενική (null Hypothesis) H 0, η οποία θεωρεί ότι το δείγμα ακολουθεί την υποκείμενη θεωρούμενη κατανομή, και την εναλλακτική H 1, η οποία θεωρεί ότι αυτό δεν συμβαίνει. Ένας στατιστικός Έλεγχος θεωρείται ισχυρός εάν η πιθανότητα αποδοχής της H 0 είναι μικρή όταν η H 0 είναι λάθος.

44
Χ-τετράγωνο Έλεγχος Ο πιο σημαντικός και ο πιο γνωστός στατιστικός Έλεγχος είναι ο Χ 2 και προτάθηκε από τον Pearson [33], (Pearson’s chi- squared test). Για τον υπολογισμό του η στατιστική που χρησιμοποιείται είναι η εξήs: Όπου O i η παρατηρηθείσα συχνότητα και E i η αναμενόμενη συχνότητα από την μηδενική υπόθεση. Η στατιστική Ελέγχου της εξίσωσης 2.1 ακολουθεί την Χ 2 κατανομή με k- c βαθμούς ελευθερίας, όπου k ο αριθμός των κλάσεων κατηγοριοποίησης των δεδομένων και c o αριθμός των εκτιμώμενων παραμέτρων για την κατανομή που θεωρούμε ότι διέπει τα δεδομένα.
![Χ-τετράγωνο Έλεγχος Ο πιο σημαντικός και ο πιο γνωστός στατιστικός Έλεγχος είναι ο Χ 2 και προτάθηκε από τον Pearson [33], (Pearson’s chi- squared test).](http://images.slideplayer.gr/10/2849982/slides/slide_44.jpg "Για τον υπολογισμό του η στατιστική που χρησιμοποιείται είναι η εξήs: Όπου O i η παρατηρηθείσα συχνότητα και E i η αναμενόμενη συχνότητα από την μηδενική υπόθεση. Η στατιστική Ελέγχου της εξίσωσης 2.1 ακολουθεί την Χ 2 κατανομή με k- c βαθμούς ελευθερίας, όπου k ο αριθμός των κλάσεων κατηγοριοποίησης των δεδομένων και c o αριθμός των εκτιμώμενων παραμέτρων για την κατανομή που θεωρούμε ότι διέπει τα δεδομένα..")
45
Χ-τετράγωνο Έλεγχος (συνέχεια) Χρησιμοποιώντας κάποιο στατιστικό πακέτο η πίνακες της Χ 2 κατανομής υπολογίζουμε την p τιμή (p-value) για την υπολογιζόμενη Χ 2 τιμή από την προηγούμενη εξίσωση. Εάν η τιμή p είναι πολύ μικρή (τυπικά κάτω από ένα επίπεδο σημαντικότητας) απορρίπτουμε την μηδενική υπόθεση, διαφορετικά την αποδεχόμαστε.
 απορρίπτουμε την μηδενική υπόθεση, διαφορετικά την αποδεχόμαστε..")
46
Μέθοδος Αναζήτησης Πληροφορίας με την χρήση του Χ 2 στατιστικού Ελέγχου Η ουσία της προτεινόμενης μεθόδου είναι να συγκρίνει τις παρατηρηθείσες συχνότητες των όρων του ερωτήματος στο έγγραφο με τις αναμενόμενες από την θεωρούμενη υπόθεση της “τυχαίας” κατανομής. Η σύγκριση αυτή με την βοήθεια του Χ2 στατιστικού Ελέγχου μπορεί να ποσοτικοποιήσει μια διαφορά (discrepancy), η οποία τελικά να χρησιμοποιηθεί σαν κριτήριο βαθμολόγησης της συνάφειας του ερωτήματος με το έγγραφο.
, η οποία τελικά να χρησιμοποιηθεί σαν κριτήριο βαθμολόγησης της συνάφειας του ερωτήματος με το έγγραφο..")
47
Μέθοδος Αναζήτησης Πληροφορίας με την χρήση του Χ 2 στατιστικού Ελέγχου (Συνέχεια) Η μηδενική υπόθεση απορρίπτεται όταν η υπολογιζόμενη Χ 2 τιμή από την εξίσωση 2.1 του Pearson είναι μεγαλύτερη από την τιμή που λαμβάνουμε από τους πίνακες της Χ 2 κατανομής για ένα επίπεδο σημαντικότητας α (συνήθως α=0.05, για βεβαιότητα 95%) Δηλαδή, όσο μεγαλύτερη είναι η υπολογιζόμενη Χ 2 τιμή τόσο ισχυρότερη είναι η ένδειξη να απορρίψουμε την μηδενική υπόθεση και επομένως να έχουμε μια συσχέτιση (relatedness) μεταξύ ερωτήματος και εγγράφου
 Η μηδενική υπόθεση απορρίπτεται όταν η υπολογιζόμενη Χ 2 τιμή από την εξίσωση 2.1 του Pearson είναι μεγαλύτερη από την τιμή που λαμβάνουμε από τους πίνακες της Χ 2 κατανομής για ένα επίπεδο σημαντικότητας α (συνήθως α=0.05, για βεβαιότητα 95%) Δηλαδή, όσο μεγαλύτερη είναι η υπολογιζόμενη Χ 2 τιμή τόσο ισχυρότερη είναι η ένδειξη να απορρίψουμε την μηδενική υπόθεση και επομένως να έχουμε μια συσχέτιση (relatedness) μεταξύ ερωτήματος και εγγράφου")
48
Μέθοδος Αναζήτησης Πληροφορίας με την χρήση του Χ 2 στατιστικού Ελέγχου (Συνέχεια) Επομένως όσον αφορά την τεχνική μας για την μέτρηση της συνάφειας μεταξύ ερωτήματος και εγγράφου θα μπορούσαμε να χρησιμοποιήσουμε αυτή καθ’ εαυτή την υπολογιζόμενη Χ 2 τιμή χωρίς να ενδιαφερόμαστε πραγματικά να απορρίψουμε την μηδενική υπόθεση Τα έγγραφα με την μεγαλύτερη αντίστοιχη Χ 2 τιμή θα τοποθετηθούν στην κορυφή της επιστρεφόμενης βαθμολογημένης λίστας με τα σχετικά έγγραφα
 Επομένως όσον αφορά την τεχνική μας για την μέτρηση της συνάφειας μεταξύ ερωτήματος και εγγράφου θα μπορούσαμε να χρησιμοποιήσουμε αυτή καθ’ εαυτή την υπολογιζόμενη Χ 2 τιμή χωρίς να ενδιαφερόμαστε πραγματικά να απορρίψουμε την μηδενική υπόθεση Τα έγγραφα με την μεγαλύτερη αντίστοιχη Χ 2 τιμή θα τοποθετηθούν στην κορυφή της επιστρεφόμενης βαθμολογημένης λίστας με τα σχετικά έγγραφα")
49
Μέθοδος Αναζήτησης Πληροφορίας με την χρήση του Χ 2 στατιστικού Ελέγχου (Συνέχεια)
")
50
Μέθοδος Αναζήτησης Πληροφορίας με την χρήση του Χ2 στατιστικού Ελέγχου (Συνέχεια)
")
51
Μέθοδος Αναζήτησης Πληροφορίας με την χρήση του Χ2 στατιστικού Ελέγχου (Συνέχεια)
")
52
Πλεονεκτήματα Το κύριο πλεονέκτημα είναι ότι η προτεινόμενη μέθοδος δεν είναι παραμετρική. Σε άλλες μεθόδους όπως η KL-Divergence το παραγόμενο μοντέλο χρειάζεται εκτίμηση των παραμέτρων της κατανομής πάνω σε δεδομένα εκπαίδευσης (training data) Προκύπτει απλός τύπος Αναζήτησης (Retrieval formula) Μπορούμε να δοκιμάσουμε πολλούς εναλλακτικούς τύπους Αναζήτησης απλά αλλάζοντας την βασική μας υπόθεση για τα δεδομένα (δηλαδή το μοντέλο της τυχαιότητας)
 Προκύπτει απλός τύπος Αναζήτησης (Retrieval formula) Μπορούμε να δοκιμάσουμε πολλούς εναλλακτικούς τύπους Αναζήτησης απλά αλλάζοντας την βασική μας υπόθεση για τα δεδομένα (δηλαδή το μοντέλο της τυχαιότητας).")
53
Τα μοντέλα Σύγκρισης Θα περιγράψουμε δύο δημοφιλή μοντέλα Αναζήτησης Πληροφορίας με τα οποία θα συγκρίνουμε την προτεινόμενη Χ 2 GOF μέθοδο, τις: Θα περιγράψουμε δύο δημοφιλή μοντέλα Αναζήτησης Πληροφορίας με τα οποία θα συγκρίνουμε την προτεινόμενη Χ 2 GOF μέθοδο, τις: –OKAPI μέθοδο, από τα γνωστά tf-idf σχήματα –KL-Divergence από την Language Modeling Προσέγγιση για Information Retrieval

54
Tf-idf σχήματα, OKAPI τύπος Αναζήτησης Τα tf-idf σχήματα είναι γνωστά και ως μοντέλα διανυσματικού χώρου και προτάθηκαν για πρώτη από τον Salton το 1971, [2]. Σύμφωνα με αυτό το μοντέλο, κάθε όρος k j σε ένα έγγραφο d j συνδέεται με ένα θετικό βάρος w ij το οποίο εκφράζει το πόσο σημαντικός είναι ο όρος για τον καθορισμό της σημασιολογίας του εγγράφου και επομένως της σπουδαιότητάς του στο σύστημα Αναζήτησης Επίσης και κάθε όρος του ερωτήματος συνδέεται με ένα αντίστοιχο βάρος
![Tf-idf σχήματα, OKAPI τύπος Αναζήτησης Τα tf-idf σχήματα είναι γνωστά και ως μοντέλα διανυσματικού χώρου και προτάθηκαν για πρώτη από τον Salton το 1971, [2].](http://images.slideplayer.gr/10/2849982/slides/slide_54.jpg "Σύμφωνα με αυτό το μοντέλο, κάθε όρος k j σε ένα έγγραφο d j συνδέεται με ένα θετικό βάρος w ij το οποίο εκφράζει το πόσο σημαντικός είναι ο όρος για τον καθορισμό της σημασιολογίας του εγγράφου και επομένως της σπουδαιότητάς του στο σύστημα Αναζήτησης Επίσης και κάθε όρος του ερωτήματος συνδέεται με ένα αντίστοιχο βάρος.")
55
Tf-idf, OKAPI τύπος Αναζήτησης (Συνέχεια)
")
57
Για να γίνει πιο ανταγωνιστικό το σχήμα χρησιμοποιούμε μια παραλλαγή του βάρους σχετικά με αυτό που δίνεται στον τύπο (2.8), τον OKAPI-TF τύπο γνωστό και ως BM25 τύπο για το βέλτιστο ταίριασμα (Best matching OKAPI retrieval formula [49]). Ενώ ο OKAPI TF τύπος σχεδιάστηκε για να χρησιμοποιηθεί με το ΟΚAPI πιθανοτικό μοντέλο, έχει αποδειχθεί ότι όταν χρησιμοποιείται με το διανυσματικό μοντέλο δίνει καλύτερα αποτελέσματα Αναζήτησης [66]
![Για να γίνει πιο ανταγωνιστικό το σχήμα χρησιμοποιούμε μια παραλλαγή του βάρους σχετικά με αυτό που δίνεται στον τύπο (2.8), τον OKAPI-TF τύπο γνωστό και ως BM25 τύπο για το βέλτιστο ταίριασμα (Best matching OKAPI retrieval formula [49]).](http://images.slideplayer.gr/10/2849982/slides/slide_57.jpg "Ενώ ο OKAPI TF τύπος σχεδιάστηκε για να χρησιμοποιηθεί με το ΟΚAPI πιθανοτικό μοντέλο, έχει αποδειχθεί ότι όταν χρησιμοποιείται με το διανυσματικό μοντέλο δίνει καλύτερα αποτελέσματα Αναζήτησης [66].")
58
Tf-idf, OKAPI τύπος Αναζήτησης (Συνέχεια)
")
59
KL-Divergence H KL-Divergence [40], είναι μια ιδιαίτερα αποδοτική μέθοδο η οποία επεκτείνει την προσέγγιση των μοντέλων γλώσσας (language modeling approach) στην περιοχή του Information Retrieval Είναι μια παραμετρική μέθοδο. Η βασική ιδέα έγκειται στην εκτίμηση ενός μοντέλου γλώσσας για το έγγραφο και ενός μοντέλου γλώσσας για το ερώτημα και να τα συγκρίνει με την Kullback-Leibler Divergence
![KL-Divergence H KL-Divergence [40], είναι μια ιδιαίτερα αποδοτική μέθοδο η οποία επεκτείνει την προσέγγιση των μοντέλων γλώσσας (language modeling approach) στην περιοχή του Information Retrieval Είναι μια παραμετρική μέθοδο.](http://images.slideplayer.gr/10/2849982/slides/slide_59.jpg "Η βασική ιδέα έγκειται στην εκτίμηση ενός μοντέλου γλώσσας για το έγγραφο και ενός μοντέλου γλώσσας για το ερώτημα και να τα συγκρίνει με την Kullback-Leibler Divergence.")
60
KL-Divergence (Συνέχεια) H KL-Divergence αν και δεν είναι πραγματική απόσταση (δεν είναι συμμετρική και δεν ισχύει η τριγωνική ανισότητα) είναι ένα πολύ καλό μέτρο μέτρησης της ομοιότητας μεταξύ δύο κατανομών.
 H KL-Divergence αν και δεν είναι πραγματική απόσταση (δεν είναι συμμετρική και δεν ισχύει η τριγωνική ανισότητα) είναι ένα πολύ καλό μέτρο μέτρησης της ομοιότητας μεταξύ δύο κατανομών.")
61
KL-Divergence (Συνέχεια) Ο δεύτερος από τα δεξιά όρος είναι μια σταθερά εξαρτώμενη από το ερώτημα, ή καλύτερα από την εντροπία του μοντέλου του ερωτήματος και δεν εξαρτάται από το έγγραφο, για αυτό μπορεί να παραληφθεί. Στον ίδιο τύπο, η σχετικότητα του εγγράφου d σε σχέση με το ερώτημα q εξαρτάται από την εκτίμηση του μοντέλου του ερωτήματος p(w|θq) και του μοντέλου γλώσσας του εγγράφου p(w|θd)
 και του μοντέλου γλώσσας του εγγράφου p(w|θd).")
62
KL-Divergence (Συνέχεια)
")
64
Εκτίμηση του Χ 2 Συστήματος Αναζήτησης Πληροφορίας Στα παραδοσιακά συστήματα Αναζήτησης Πληροφορίας τα έγγραφα παραμένουν σταθερά στην συλλογή, ενώ νέα ερωτήματα υποβάλλονται στο σύστημα από το οποίο ζητείται να επιστρέψει τα πιο σχετικά έγγραφα. Αυτό είναι γνωστό ως Ad-hoc Retrieval. Πάνω σε αυτό θα ελέγξουμε την αποδοτικότητα της προτεινόμενης Χ 2 -GOF μεθόδου και θα την συγκρίνουμε με την OKAPI και KL-Divergence μέθοδο για το ίδιο πρόβλημα

65
Περιγραφή των TREC Δεδομένων Αποτίμησης Μια συλλογή εγγράφων πού χρησιμοποιείται επί χρόνια για την αποτίμηση των συστημάτων Αναζήτησης Πληροφορίας είναι η TIPSTER/TREC collection [44] Μια συλλογή εγγράφων πού χρησιμοποιείται επί χρόνια για την αποτίμηση των συστημάτων Αναζήτησης Πληροφορίας είναι η TIPSTER/TREC collection [44] Λόγω του μεγάλου όγκου της θεωρείται σήμερα σαν standard reference test collection για την περιοχή του information Retrieval Λόγω του μεγάλου όγκου της θεωρείται σήμερα σαν standard reference test collection για την περιοχή του information Retrieval H δημιουργία της συλλογής ξεκίνησε από την Domna Harman, μια διευθύντρια στο National Institute of Standards and technology (NIST), πού είχε την ιδέα της διοργάνωσης ενός διαγωνισμού σε ετήσια βάσει για Information Retrieval συστήματα, υπό το όνομα TREC (Text Retrieval Conference) H δημιουργία της συλλογής ξεκίνησε από την Domna Harman, μια διευθύντρια στο National Institute of Standards and technology (NIST), πού είχε την ιδέα της διοργάνωσης ενός διαγωνισμού σε ετήσια βάσει για Information Retrieval συστήματα, υπό το όνομα TREC (Text Retrieval Conference)
![Περιγραφή των TREC Δεδομένων Αποτίμησης Μια συλλογή εγγράφων πού χρησιμοποιείται επί χρόνια για την αποτίμηση των συστημάτων Αναζήτησης Πληροφορίας είναι η TIPSTER/TREC collection [44] Μια συλλογή εγγράφων πού χρησιμοποιείται επί χρόνια για την αποτίμηση των συστημάτων Αναζήτησης Πληροφορίας είναι η TIPSTER/TREC collection [44] Λόγω του μεγάλου όγκου της θεωρείται σήμερα σαν standard reference test collection για την περιοχή του information Retrieval Λόγω του μεγάλου όγκου της θεωρείται σήμερα σαν standard reference test collection για την περιοχή του information Retrieval H δημιουργία της συλλογής ξεκίνησε από την Domna Harman, μια διευθύντρια στο National Institute of Standards and technology (NIST), πού είχε την ιδέα της διοργάνωσης ενός διαγωνισμού σε ετήσια βάσει για Information Retrieval συστήματα, υπό το όνομα TREC (Text Retrieval Conference) H δημιουργία της συλλογής ξεκίνησε από την Domna Harman, μια διευθύντρια στο National Institute of Standards and technology (NIST), πού είχε την ιδέα της διοργάνωσης ενός διαγωνισμού σε ετήσια βάσει για Information Retrieval συστήματα, υπό το όνομα TREC (Text Retrieval Conference)](http://images.slideplayer.gr/10/2849982/slides/slide_65.jpg "Περιγραφή των TREC Δεδομένων Αποτίμησης Μια συλλογή εγγράφων πού χρησιμοποιείται επί χρόνια για την αποτίμηση των συστημάτων Αναζήτησης Πληροφορίας είναι η TIPSTER/TREC collection [44] Μια συλλογή εγγράφων πού χρησιμοποιείται επί χρόνια για την αποτίμηση των συστημάτων Αναζήτησης Πληροφορίας είναι η TIPSTER/TREC collection [44] Λόγω του μεγάλου όγκου της θεωρείται σήμερα σαν standard reference test collection για την περιοχή του information Retrieval Λόγω του μεγάλου όγκου της θεωρείται σήμερα σαν standard reference test collection για την περιοχή του information Retrieval H δημιουργία της συλλογής ξεκίνησε από την Domna Harman, μια διευθύντρια στο National Institute of Standards and technology (NIST), πού είχε την ιδέα της διοργάνωσης ενός διαγωνισμού σε ετήσια βάσει για Information Retrieval συστήματα, υπό το όνομα TREC (Text Retrieval Conference) H δημιουργία της συλλογής ξεκίνησε από την Domna Harman, μια διευθύντρια στο National Institute of Standards and technology (NIST), πού είχε την ιδέα της διοργάνωσης ενός διαγωνισμού σε ετήσια βάσει για Information Retrieval συστήματα, υπό το όνομα TREC (Text Retrieval Conference)")
66
Περιγραφή των TREC Δεδομένων

67
Περιγραφή των TREC Δεδομένων (Συνέχεια) Επειδή οι συλλογές αυτές δημιουργήθηκαν υπό το χρηματοδοτούμενο από το DARPA πρόγραμμα TIPSTER αναφέρονται και σαν TIPSTER ή TIPSTER/TREC test Collection H TREC Collection αυξάνει σταθερά χρόνο με το χρόνο. Σήμερα διατίθεται επί αγορά σε 6 CD Rom Disks πού το καθένα χονδρικά περιέχει περίπου 1 gigabyte συμπιεσμένο κείμενο Πηγές Προέλευσης των κειμένων

68
Περιγραφή των TREC Δεδομένων (Συνέχεια) Όλα τα έγγραφα στην συλλογή έχουν ετικετοποιηθεί (tagged) με SGML για εύκολο Parsing Δείγμα Εγγράφου στην Συλλογή
 Όλα τα έγγραφα στην συλλογή έχουν ετικετοποιηθεί (tagged) με SGML για εύκολο Parsing Δείγμα Εγγράφου στην Συλλογή")
69
Περιγραφή των TREC Δεδομένων (Συνέχεια) Δείγμα Εγγράφου στην Συλλογή (Συνέχεια)
 Δείγμα Εγγράφου στην Συλλογή (Συνέχεια)")
70
Περιγραφή των TREC Δεδομένων (Συνέχεια) Η TREC συλλογή περιέχει και ένα σύνολο από ερωτήματα (queries) πού είναι αιτήματα που εκφράζουν κάποια πληροφοριακή ανάγκη και με αυτά μπορεί να ελεγχθεί ένας νέος αλγόριθμος ως προς την αποδοτικότητά του. Στην TREC ορολογία ένα τέτοιο ερώτημα ονομάζεται topic Παράδειγμα ενός topic είναι το επόμενο

71
Περιγραφή των TREC Δεδομένων (Συνέχεια) Δείγμα topic
 Δείγμα topic")
72
Σύγκριση Αποδοτικότητας με τα tf-idf σχήματα OKAPI μέθοδος Tην προτεινόμενη μέθοδο θα την συγκρίνουμε επίσης πάνω στην ίδια συλλογή με την OKAPI μέθοδο που θεωρείται κλασσική για Information Retrieval Tην προτεινόμενη μέθοδο θα την συγκρίνουμε επίσης πάνω στην ίδια συλλογή με την OKAPI μέθοδο που θεωρείται κλασσική για Information Retrieval Για να έχουμε μια καλύτερη εικόνα της δυνατότητας Αναζήτησης της προτεινόμενης X2-GOF μεθόδου, επιλέξαμε να γίνει ο έλεγχος της αποδοτικότητας σε 3 μεγάλες υποσυλλογές της TREC συλλογής, οι οποίες είναι: Για να έχουμε μια καλύτερη εικόνα της δυνατότητας Αναζήτησης της προτεινόμενης X2-GOF μεθόδου, επιλέξαμε να γίνει ο έλεγχος της αποδοτικότητας σε 3 μεγάλες υποσυλλογές της TREC συλλογής, οι οποίες είναι:

73
Σύγκριση Αποδοτικότητας με τα tf-idf σχήματα OKAPI μέθοδος (Συνέχεια) Στον πίνακα 2.1 φαίνονται τα στατιστικά στοιχεία των συλλογών αυτών Στον πίνακα 2.1 φαίνονται τα στατιστικά στοιχεία των συλλογών αυτών
 Στον πίνακα 2.1 φαίνονται τα στατιστικά στοιχεία των συλλογών αυτών Στον πίνακα 2.1 φαίνονται τα στατιστικά στοιχεία των συλλογών αυτών")
74
Σύγκριση Αποδοτικότητας με τα tf-idf σχήματα OKAPI μέθοδος (Συνέχεια) Ως ερωτήματα χρησιμοποιήσαμε τα θέματα 351-400 (topics 351-400), τα οποία χρησιμοποιήσαμε στο συνέδριο TREC-7 Ως ερωτήματα χρησιμοποιήσαμε τα θέματα 351-400 (topics 351-400), τα οποία χρησιμοποιήσαμε στο συνέδριο TREC-7 Εκτελέσαμε δύο πειράματα με αυτά τα θέματα. Στο ένα χρησιμοποιήσαμε μόνο τους τίτλους από το κείμενο του ερωτήματος και στο δεύτερο χρησιμοποιώντας μια μεγαλύτερη έκδοση των ερωτημάτων Εκτελέσαμε δύο πειράματα με αυτά τα θέματα. Στο ένα χρησιμοποιήσαμε μόνο τους τίτλους από το κείμενο του ερωτήματος και στο δεύτερο χρησιμοποιώντας μια μεγαλύτερη έκδοση των ερωτημάτων Για τα πειράματα αυτά δεν χρησιμοποιήσαμε καμία προεπεξεργασία στα κείμενα, όπως πχ, tokenization, stemming ούτε εφαρμόσαμε καμία λίστα αποκλεισμού συχνών λέξεων (stopword list), όπως άρθρων, συνδέσμων, επιρρημάτων, κλπ. Αντίθετα λάβαμε υπ’ όψιν όλες ανεξαιρέτως τις λέξεις όλων των εγγράφων στην συλλογή Για τα πειράματα αυτά δεν χρησιμοποιήσαμε καμία προεπεξεργασία στα κείμενα, όπως πχ, tokenization, stemming ούτε εφαρμόσαμε καμία λίστα αποκλεισμού συχνών λέξεων (stopword list), όπως άρθρων, συνδέσμων, επιρρημάτων, κλπ. Αντίθετα λάβαμε υπ’ όψιν όλες ανεξαιρέτως τις λέξεις όλων των εγγράφων στην συλλογή
, όπως άρθρων, συνδέσμων, επιρρημάτων, κλπ. Αντίθετα λάβαμε υπ’ όψιν όλες ανεξαιρέτως τις λέξεις όλων των εγγράφων στην συλλογή Για τα πειράματα αυτά δεν χρησιμοποιήσαμε καμία προεπεξεργασία στα κείμενα, όπως πχ, tokenization, stemming ούτε εφαρμόσαμε καμία λίστα αποκλεισμού συχνών λέξεων (stopword list), όπως άρθρων, συνδέσμων, επιρρημάτων, κλπ. Αντίθετα λάβαμε υπ’ όψιν όλες ανεξαιρέτως τις λέξεις όλων των εγγράφων στην συλλογή.")
75
Σύγκριση Αποδοτικότητας με τα tf-idf σχήματα OKAPI μέθοδος (Συνέχεια)
")
80
Σύγκριση Αποδοτικότητας με τα tf-idf σχήματα, OKAPI μέθοδος (Συνέχεια)
")
86
Σύγκριση με την KL-Divergence και OKAPI στην TREC συλλογή Για την καλύτερη αποτίμηση των δυνατοτήτων της προτεινόμενης X2- GOF μεθόδου εκτελέσαμε ένα μεγαλύτερο πείραμα πάνω σε όλη την TREC των CD’s 4,5 συγκρίνοντας αυτή την φορά και με την KL- Divergence μέθοδο Τα στατιστικά στοιχεία της συλλογής φαίνονται παρακάτω

89
Χαρακτηριστικά και πλεονεκτήματα της Προτεινόμενης Χ 2 -GOF μεθόδου Αν και η προτεινόμενη μέθοδος χρησιμοποιεί για την Αναζήτηση μόνο καθαρές συχνότητες, η μέθοδος ξεπερνά σταθερά την OKAPI BM25 μέθοδο Αναζήτησης Αν και η προτεινόμενη μέθοδος χρησιμοποιεί για την Αναζήτηση μόνο καθαρές συχνότητες, η μέθοδος ξεπερνά σταθερά την OKAPI BM25 μέθοδο Αναζήτησης Ωστόσο και στις δύο περιπτώσεις TREC-7 και TREC-8 η KL-Divergence έχει την καλύτερη αποδοτικότητα Ωστόσο και στις δύο περιπτώσεις TREC-7 και TREC-8 η KL-Divergence έχει την καλύτερη αποδοτικότητα Η μέθοδος όμως αυτή έχει το μειονέκτημα ότι είναι παραμετρική και χρειάζεται εκτίμηση των παραμέτρων πάνω σε ολόκληρη την συλλογή. Η μέθοδος όμως αυτή έχει το μειονέκτημα ότι είναι παραμετρική και χρειάζεται εκτίμηση των παραμέτρων πάνω σε ολόκληρη την συλλογή.

90
Χαρακτηριστικά και πλεονεκτήματα της Προτεινόμενης Χ2-GOF μεθόδου Η απλότητα είναι ένα από τα βασικά πλεονεκτήματα της προτεινόμενης μεθόδου. Η υπολογιζόμενη X 2 -GOF τιμή βελτιώνει την αποδοτικότητα και επιτρέπει την ανεύρεση εγγράφων που προσεγγίζουν τις συνθήκες του ερωτήματος Η απλότητα είναι ένα από τα βασικά πλεονεκτήματα της προτεινόμενης μεθόδου. Η υπολογιζόμενη X 2 -GOF τιμή βελτιώνει την αποδοτικότητα και επιτρέπει την ανεύρεση εγγράφων που προσεγγίζουν τις συνθήκες του ερωτήματος Η μέθοδος μας επιτρέπει να αποφασίσουμε εάν υπάρχει μια στατιστικά σημαντική σχέση μεταξύ ερωτήματος και εγγράφου Η μέθοδος μας επιτρέπει να αποφασίσουμε εάν υπάρχει μια στατιστικά σημαντική σχέση μεταξύ ερωτήματος και εγγράφου Επι πλέον, μας επιτρέπει μέσα στο πλαίσιο των στατιστικών ελέγχων να δοκιμάσουμε εναλλακτικούς τύπους Αναζήτησης, απλά αλλάζοντας την βασική υπόθεση για τα δεοδμένα Επι πλέον, μας επιτρέπει μέσα στο πλαίσιο των στατιστικών ελέγχων να δοκιμάσουμε εναλλακτικούς τύπους Αναζήτησης, απλά αλλάζοντας την βασική υπόθεση για τα δεοδμένα

91
Στατιστική Εκτίμηση της Αποδοτικότητας των Συγκρινόμενων Αλγορίθμων Οι αποδόσεις των συγκρινόμενων αλγορίθμων σε αυτά τα πειράματα φαίνεται να είναι διαφορετική Για να το εκτιμήσουμε και πιο τυπικά αυτό θα εκτελέσουμε ένα έλεγχο paired t-test O έλεγχος paired t-test χρησιμοποιείται για να ελέγξουμε εάν οι μέσες τιμές των πληθυσμών δύο δειγμάτων είναι ίσοι Στην περίπτωσή μας χρησιμοποιούμε σαν δείγματα τις λαμβανόμενες μέσες τιμές ακρίβειας στα 11-σημεία από τα πειράματα πού κάναμε

92
Στατιστική Εκτίμηση της Αποδοτικότητας των Συγκρινόμενων Αλγορίθμων Εκτελώντας τον έλεγχο paired t-test για τα μοντέλα X 2 -GOF και OKAPI, τότε η επιστρεφόμενη πιθανότητα (p-value) για τα θέματα 351-400 είναι 0.0326 και για τα θέματα 401-450 είναι 0.00010608 Επομένως συμπεραίνουμε ότι οι λαμβανόμενες μέσες ακρίβειες για τα μοντέλα X 2 -GOF και OKAPI, είναι διαφορετικές με βεβαιότητα 96.74% και 99.98% για τα για τα θέματα 351-400 και 401-450 αντίστοιχα Όμοια συγκρίνοντας τα μοντέλα X 2 -GOF και KL-Divergence βρίσκουμε επιστρεφόμενες πιθανότητες 0.0004 για τα θέματα 351-400 και 0.0018 για τα θέματα 401-450
 για τα θέματα είναι και για τα θέματα είναι Επομένως συμπεραίνουμε ότι οι λαμβανόμενες μέσες ακρίβειες για τα μοντέλα X 2 -GOF και OKAPI, είναι διαφορετικές με βεβαιότητα 96.74% και 99.98% για τα για τα θέματα και αντίστοιχα Όμοια συγκρίνοντας τα μοντέλα X 2 -GOF και KL-Divergence βρίσκουμε επιστρεφόμενες πιθανότητες για τα θέματα και για τα θέματα")
93
Αλλάζοντας την Βασική Υπόθεση για τα Δεδομένα Στην εργασία Divergence from Randomness, Amati [67], προτείνεται ένα βασικό μοντέλο τυχαιότητας της κατανομής των όρων στα διάφορα έγγραφα. Σύμφωνα με αυτό οι διαδικασίες κατανομής των όρων μπορούν να ορισθούν σαν τυχαίες εκλογές (Random Drawings) από ένα “δοχείο” (urn) που περιέχει τους διαθέσιμους όρους. Ακολουθώντας αυτή την πρόταση αλλάξαμε το μοντέλο τυχαιότητας από αυτό της ομοιόμορφης κατανομής στο διωνυμικό μοντέλο (Binomial model) Σύμφωνα με αυτό το μοντέλο η εμφάνιση ενός μοναδικού όρου i σε ένα έγγραφο d θεωρείται Bernoulli διαδικασία με πιθανότητα p=1/N, όπου Ν ο αριθμός των εγγράφων
![Αλλάζοντας την Βασική Υπόθεση για τα Δεδομένα Στην εργασία Divergence from Randomness, Amati [67], προτείνεται ένα βασικό μοντέλο τυχαιότητας της κατανομής των όρων στα διάφορα έγγραφα.](http://images.slideplayer.gr/10/2849982/slides/slide_93.jpg "Σύμφωνα με αυτό οι διαδικασίες κατανομής των όρων μπορούν να ορισθούν σαν τυχαίες εκλογές (Random Drawings) από ένα δοχείο (urn) που περιέχει τους διαθέσιμους όρους. Ακολουθώντας αυτή την πρόταση αλλάξαμε το μοντέλο τυχαιότητας από αυτό της ομοιόμορφης κατανομής στο διωνυμικό μοντέλο (Binomial model) Σύμφωνα με αυτό το μοντέλο η εμφάνιση ενός μοναδικού όρου i σε ένα έγγραφο d θεωρείται Bernoulli διαδικασία με πιθανότητα p=1/N, όπου Ν ο αριθμός των εγγράφων.")
94
Αλλάζοντας την Βασική Υπόθεση για τα Δεδομένα

95
Για να συγκρίνουμε την αποδοτικότητα των δύο διαφορετικών Υποθέσεων εκτελέσαμε ένα πείραμα Αναζήτησης πάνω στην συλλογή FBIS από το CD 5 της TREC συλλογής

97
Συμπεράσματα Παρουσιάσαμε μια μέθοδο για εφαρμογή του X 2 -GOF στατιστικού Ελέγχου στην Αναζήτηση Πληροφορίας H μέθοδος αποδεικνύεται εύρωστη (robust) και αποδοτική, αποδίδοντας καλά τόσα για “σύντομα” ερωτήματα όσο και για περισσότερα “φλύαρα” (Verbose) Έχει το πλεονέκτημα να μας επιτρέπει να μοντελοποιήσουμε τα έγγραφα και τα ερωτήματα με πολλές διαφορετικές Υποθέσεις. Κάποιες διαφορετικές υποθέσεις για τα δεδομένα όπως η Κανονικότητα (Normality), Weibull, κλπ, πιθανόν να είναι καλές εναλλακτικές Υποθέσεις. Επίσης και η δοκιμή άλλων στατιστικών Ελέγχων, όπως Kolmogorov-Smirnov και Anderson-Darling.
, Weibull, κλπ, πιθανόν να είναι καλές εναλλακτικές Υποθέσεις. Επίσης και η δοκιμή άλλων στατιστικών Ελέγχων, όπως Kolmogorov-Smirnov και Anderson-Darling..")
98
Στατιστικές Μέθοδοι στην Εύρεση Collocations

99
Collocations ► Λέξεις που συνεκφέρονται πολύ συχνά μαζί ► Είναι κοινό χαρακτηριστικό των φυσικών γλωσσών και μπορούν να εμφανισθούν τόσο σε απλό κείμενο φυσικής γλώσσας όσο και σε τεχνικό και επιστημονικό κείμενο ► Ένα Collocation μπορεί να είναι συνδυασμός λέξεων ή (φράσεων) πού εμφανίζεται πολύ συχνά στην γλώσσα με ένα τρόπο που να φαίνεται φυσικός νοηματικά από τα συμφραζόμενα, παρότι η απομονωμένη σύνθεση των επί μέρους νοημάτων που απαρτίζουν το collocation, οδηγεί σε νοηματικό περιεχόμενο άσχετο με τα συμφραζόμενα
 πού εμφανίζεται πολύ συχνά στην γλώσσα με ένα τρόπο που να φαίνεται φυσικός νοηματικά από τα συμφραζόμενα, παρότι η απομονωμένη σύνθεση των επί μέρους νοημάτων που απαρτίζουν το collocation, οδηγεί σε νοηματικό περιεχόμενο άσχετο με τα συμφραζόμενα")
100
Collocations Τα collocations σε γλώσσες με ένα πλούσιο κλιτικό σύστημα, όπως η Ελληνική, εμφανίζονται με 2 τρόπους: Άκαμπτος Οι λέξεις “χρηματιστήριο” και “αξία” σαν “Χρηματιστήριο Αξιών” Χαλαρός Οι λέξεις “Στρώνομαι” και “δουλειά” σαν “Στρώνομαι στην δουλειά” “Η δουλειά μου στρώνει”

101
Collocations Για τα Collocation υπάρχουν πολλοί ορισμοί, αφού οι διάφοροι ερευνητές έχουν εστιάσει πάνω σε διαφορετικά χαρακτηριστικά Firth [55] Firth [55] “Collocations of a given word are statements of the habitual or customary places of the word” Benson και Morton [50] Benson και Morton [50] “An arbitrary and recurrent word combination ” Το recurrent σημαίνει ότι αυτοί οι συνδυασμοί εμφανίζονται συχνά για ένα δεδομένο Context (συμφραζόμενα)
![Collocations Για τα Collocation υπάρχουν πολλοί ορισμοί, αφού οι διάφοροι ερευνητές έχουν εστιάσει πάνω σε διαφορετικά χαρακτηριστικά Firth [55] Firth [55] Collocations of a given word are statements of the habitual or customary places of the word Benson και Morton [50] Benson και Morton [50] An arbitrary and recurrent word combination Το recurrent σημαίνει ότι αυτοί οι συνδυασμοί εμφανίζονται συχνά για ένα δεδομένο Context (συμφραζόμενα)](http://images.slideplayer.gr/10/2849982/slides/slide_101.jpg "Collocations Για τα Collocation υπάρχουν πολλοί ορισμοί, αφού οι διάφοροι ερευνητές έχουν εστιάσει πάνω σε διαφορετικά χαρακτηριστικά Firth [55] Firth [55] Collocations of a given word are statements of the habitual or customary places of the word Benson και Morton [50] Benson και Morton [50] An arbitrary and recurrent word combination Το recurrent σημαίνει ότι αυτοί οι συνδυασμοί εμφανίζονται συχνά για ένα δεδομένο Context (συμφραζόμενα)")
102
Collocations Smadja [64] Smadja [64] Καθορίζει 4 χαρακτηριστικά για τα Collocations χρήσιμα για τις υπολογιστικές εφαρμογές Τα Collocations είναι αυθαίρετα, αυτό σημαίνει ότι δεν αντιστοιχούν σε κάποια συντακτική ή σημασιολογική παραλλαγή Τα Collocations είναι domain-dependent, επομένως ο χειρισμός κειμένου σε ένα πεδίο απαιτεί σαφή γνώση της ορολογίας και των domain-dependent Collocations Τα Collocations είναι recurrent, όπως ορίστηκε παραπάνω Τα Collocations είναι Cohesive lexical clusters, πού σημαίνει ότι η εμφάνιση μιας η περισσότερων λέξεων συχνά συνεπάγεται την εμφάνιση και των υπολοίπων λέξεων
![Collocations Smadja [64] Smadja [64] Καθορίζει 4 χαρακτηριστικά για τα Collocations χρήσιμα για τις υπολογιστικές εφαρμογές Τα Collocations είναι αυθαίρετα, αυτό σημαίνει ότι δεν αντιστοιχούν σε κάποια συντακτική ή σημασιολογική παραλλαγή Τα Collocations είναι domain-dependent, επομένως ο χειρισμός κειμένου σε ένα πεδίο απαιτεί σαφή γνώση της ορολογίας και των domain-dependent Collocations Τα Collocations είναι recurrent, όπως ορίστηκε παραπάνω Τα Collocations είναι Cohesive lexical clusters, πού σημαίνει ότι η εμφάνιση μιας η περισσότερων λέξεων συχνά συνεπάγεται την εμφάνιση και των υπολοίπων λέξεων](http://images.slideplayer.gr/10/2849982/slides/slide_102.jpg "Collocations Smadja [64] Smadja [64] Καθορίζει 4 χαρακτηριστικά για τα Collocations χρήσιμα για τις υπολογιστικές εφαρμογές Τα Collocations είναι αυθαίρετα, αυτό σημαίνει ότι δεν αντιστοιχούν σε κάποια συντακτική ή σημασιολογική παραλλαγή Τα Collocations είναι domain-dependent, επομένως ο χειρισμός κειμένου σε ένα πεδίο απαιτεί σαφή γνώση της ορολογίας και των domain-dependent Collocations Τα Collocations είναι recurrent, όπως ορίστηκε παραπάνω Τα Collocations είναι Cohesive lexical clusters, πού σημαίνει ότι η εμφάνιση μιας η περισσότερων λέξεων συχνά συνεπάγεται την εμφάνιση και των υπολοίπων λέξεων")
103
Collocations Σύμφωνα με τους Manning και Schutze [60] τα Collocations χαρακτηρίζονται από limited compositionality (περιορισμένη συνθετικότητα ) Μια έκφραση φυσικής γλώσσας είναι compositional, εάν η έννοια της έκφρασης μπορεί να προβλεφθεί από την σύνθεση των εννοιών που συνθέτου το collocation Παράδειγμα η έκφραση “Γερό ποτήρι” Τέλος Ένα άλλο χαρακτηριστικό των collocations είναι η απουσία έγκυρων συνωνύμων [59], [60] Παράδειγμα: Συνώνυμα Baggage και luggage Μόνο emotional, historical ή psychological baggage
![Collocations Σύμφωνα με τους Manning και Schutze [60] τα Collocations χαρακτηρίζονται από limited compositionality (περιορισμένη συνθετικότητα ) Μια έκφραση φυσικής γλώσσας είναι compositional, εάν η έννοια της έκφρασης μπορεί να προβλεφθεί από την σύνθεση των εννοιών που συνθέτου το collocation Παράδειγμα η έκφραση Γερό ποτήρι Τέλος Ένα άλλο χαρακτηριστικό των collocations είναι η απουσία έγκυρων συνωνύμων [59], [60] Παράδειγμα: Συνώνυμα Baggage και luggage Μόνο emotional, historical ή psychological baggage](http://images.slideplayer.gr/10/2849982/slides/slide_103.jpg "Collocations Σύμφωνα με τους Manning και Schutze [60] τα Collocations χαρακτηρίζονται από limited compositionality (περιορισμένη συνθετικότητα ) Μια έκφραση φυσικής γλώσσας είναι compositional, εάν η έννοια της έκφρασης μπορεί να προβλεφθεί από την σύνθεση των εννοιών που συνθέτου το collocation Παράδειγμα η έκφραση Γερό ποτήρι Τέλος Ένα άλλο χαρακτηριστικό των collocations είναι η απουσία έγκυρων συνωνύμων [59], [60] Παράδειγμα: Συνώνυμα Baggage και luggage Μόνο emotional, historical ή psychological baggage")
104
Η Χρησιμότητα των Collocations Είναι σημαντικά για ένα σημαντικό αριθμό εφαρμογών όπως Natural Language Generation: Χρειάζεται τον σωστό συνδυασμό λέξεων Natural Language Generation: Χρειάζεται τον σωστό συνδυασμό λέξεων Machine Translation : Είναι δύσκολο να μεταφράσουμε από την μια γλώσσα στην άλλη τα Collocations, π.χ. Clear road -> Ελεύθερος δρόμος Machine Translation : Είναι δύσκολο να μεταφράσουμε από την μια γλώσσα στην άλλη τα Collocations, π.χ. Clear road -> Ελεύθερος δρόμος Text Simplification: Αντικατάσταση δύσκολων λέξεων με απλές χρειάζεται γνώση Collocations Text Simplification: Αντικατάσταση δύσκολων λέξεων με απλές χρειάζεται γνώση Collocations Computational Lexicography: Τα Collocations είναι απαραίτητα για να χαρακτηρίσουν πλήρως τις λεξικές καταχωρήσεις Computational Lexicography: Τα Collocations είναι απαραίτητα για να χαρακτηρίσουν πλήρως τις λεξικές καταχωρήσεις

105
H λογική της Εξαγωγής Collocations Παρουσιάζουμε δύο μεθόδους παραγωγής Collocations. Στην πρώτη περίπτωση εφαρμόζουμε την δοκιμασμένη μέθοδο του μέσου και της διασποράς Στην δεύτερη μέθοδο θεμελιώνουμε την εφαρμογή του X 2 στατιστικού ελέγχου για την εξαγωγή Collocations

106
H λογική της Εξαγωγής Collocations Η παραδοσιακή προσέγγιση για την εξαγωγή Collocations είναι η λεξικογραφική προσέγγιση. Η παραδοσιακή προσέγγιση για την εξαγωγή Collocations είναι η λεξικογραφική προσέγγιση. Σύμφωνα με τους Benson και Morton [50] δεν μπορούμε να χειριστούμε ξεχωριστά τα συμμετέχοντα μέρη σε ένα Collocation (Collocates). Επομένως η εξαγωγή Collocations δεν είναι προβλέψιμη, πρέπει να γίνεται πρώτα χειρονακτικά και έπειτα να εισάγονται στα λεξικά Σύμφωνα με τους Benson και Morton [50] δεν μπορούμε να χειριστούμε ξεχωριστά τα συμμετέχοντα μέρη σε ένα Collocation (Collocates). Επομένως η εξαγωγή Collocations δεν είναι προβλέψιμη, πρέπει να γίνεται πρώτα χειρονακτικά και έπειτα να εισάγονται στα λεξικά
. Επομένως η εξαγωγή Collocations δεν είναι προβλέψιμη, πρέπει να γίνεται πρώτα χειρονακτικά και έπειτα να εισάγονται στα λεξικά Σύμφωνα με τους Benson και Morton [50] δεν μπορούμε να χειριστούμε ξεχωριστά τα συμμετέχοντα μέρη σε ένα Collocation (Collocates). Επομένως η εξαγωγή Collocations δεν είναι προβλέψιμη, πρέπει να γίνεται πρώτα χειρονακτικά και έπειτα να εισάγονται στα λεξικά.")
107
H λογική της Εξαγωγής Collocations Πρόσφατα η στατιστική έχει εφαρμοστεί στην εξαγωγή Collocations O Choueka [52], δοκίμασε να εξαγάγει Collocations χρησιμοποιώντας N-γράμματα (N-grams) συνδυασμούς από 2 έως 4 λέξης χρησιμοποιώντας ένα πολύ απλό κριτήριο την συχνότητα εμφάνισης Ατυχώς η επιλογή αυτή δεν οδηγεί πάντοτε στα καλύτερα αποτελέσματα, π.χ. στην Αγγλική γλώσσα τα συχνότερα bigrams: Of the, in the, to the
![H λογική της Εξαγωγής Collocations Πρόσφατα η στατιστική έχει εφαρμοστεί στην εξαγωγή Collocations O Choueka [52], δοκίμασε να εξαγάγει Collocations χρησιμοποιώντας N-γράμματα (N-grams) συνδυασμούς από 2 έως 4 λέξης χρησιμοποιώντας ένα πολύ απλό κριτήριο την συχνότητα εμφάνισης Ατυχώς η επιλογή αυτή δεν οδηγεί πάντοτε στα καλύτερα αποτελέσματα, π.χ.](http://images.slideplayer.gr/10/2849982/slides/slide_107.jpg "στην Αγγλική γλώσσα τα συχνότερα bigrams: Of the, in the, to the.")
108
H λογική της Εξαγωγής Collocations Για να ξεπεράσουν το προηγούμενο πρόβλημα οι Justenson και Katz [58] πρότειναν να επιλέγονται μόνο εκείνα τα bigrams πού αποτελούν φράσεις. Χρησιμοποίησαν part-of-speech φίλτρα AN, NN, AAN, ANN, όπου A σημαίνει επίθετο και Ν ουσιαστικό AN, NN, AAN, ANN, όπου A σημαίνει επίθετο και Ν ουσιαστικό Αν και ευριστική απλή μέθοδος οι συγγραφείς ανέφεραν σημαντική βελτιωση στα αποτελέσματα Αν και ευριστική απλή μέθοδος οι συγγραφείς ανέφεραν σημαντική βελτιωση στα αποτελέσματα
![H λογική της Εξαγωγής Collocations Για να ξεπεράσουν το προηγούμενο πρόβλημα οι Justenson και Katz [58] πρότειναν να επιλέγονται μόνο εκείνα τα bigrams πού αποτελούν φράσεις.](http://images.slideplayer.gr/10/2849982/slides/slide_108.jpg "Χρησιμοποίησαν part-of-speech φίλτρα AN, NN, AAN, ANN, όπου A σημαίνει επίθετο και Ν ουσιαστικό AN, NN, AAN, ANN, όπου A σημαίνει επίθετο και Ν ουσιαστικό Αν και ευριστική απλή μέθοδος οι συγγραφείς ανέφεραν σημαντική βελτιωση στα αποτελέσματα Αν και ευριστική απλή μέθοδος οι συγγραφείς ανέφεραν σημαντική βελτιωση στα αποτελέσματα.")
109
H λογική της Εξαγωγής Collocations Η βασιζόμενη στην συχνότητα εμφάνισης μέθοδος δουλεύει πολύ καλά με φράσεις ουσιαστικών. Ωστόσο πολλά Collocations περιέχουν λέξεις με πολύ πιο ευέλικτες συσχετίσεις μεταξύ των Η βασιζόμενη στην συχνότητα εμφάνισης μέθοδος δουλεύει πολύ καλά με φράσεις ουσιαστικών. Ωστόσο πολλά Collocations περιέχουν λέξεις με πολύ πιο ευέλικτες συσχετίσεις μεταξύ των Η μέθοδος του μέσου και της διασποράς (mean and Variance method [64]) ξεπερνάει το πρόβλημα υπολογίζοντας τις προσημασμένες αποστάσεις μεταξύ των Collocates και βρίσκοντας την διασπορά (spread) αυτών των προσημασμένων αποστάσεων Η μέθοδος του μέσου και της διασποράς (mean and Variance method [64]) ξεπερνάει το πρόβλημα υπολογίζοντας τις προσημασμένες αποστάσεις μεταξύ των Collocates και βρίσκοντας την διασπορά (spread) αυτών των προσημασμένων αποστάσεων
 ξεπερνάει το πρόβλημα υπολογίζοντας τις προσημασμένες αποστάσεις μεταξύ των Collocates και βρίσκοντας την διασπορά (spread) αυτών των προσημασμένων αποστάσεων Η μέθοδος του μέσου και της διασποράς (mean and Variance method [64]) ξεπερνάει το πρόβλημα υπολογίζοντας τις προσημασμένες αποστάσεις μεταξύ των Collocates και βρίσκοντας την διασπορά (spread) αυτών των προσημασμένων αποστάσεων.")
110
H λογική της Εξαγωγής Collocations Η προσέγγιση του μέσου και της διασποράς φαίνεται λογική είναι απλή. Αναζητούμε κατανομές με μικρή διασπορά Η προσέγγιση του μέσου και της διασποράς φαίνεται λογική είναι απλή. Αναζητούμε κατανομές με μικρή διασπορά Μια εναλλακτική μέθοδος βασιζόμενη στην συχνότητα εμφάνισης είναι αμοιβαία πληροφορία (mutual information [53]). Μια εναλλακτική μέθοδος βασιζόμενη στην συχνότητα εμφάνισης είναι αμοιβαία πληροφορία (mutual information [53]). O όρος έχει mutual information την καταγωγή του από την Θεωρία της Πληροφορίας και είναι χονδρικά ένα μέτρο του πόσο πολύ μια λέξη μας πληροφορεί για μια άλλη O όρος έχει mutual information την καταγωγή του από την Θεωρία της Πληροφορίας και είναι χονδρικά ένα μέτρο του πόσο πολύ μια λέξη μας πληροφορεί για μια άλλη
. Μια εναλλακτική μέθοδος βασιζόμενη στην συχνότητα εμφάνισης είναι αμοιβαία πληροφορία (mutual information [53]). O όρος έχει mutual information την καταγωγή του από την Θεωρία της Πληροφορίας και είναι χονδρικά ένα μέτρο του πόσο πολύ μια λέξη μας πληροφορεί για μια άλλη O όρος έχει mutual information την καταγωγή του από την Θεωρία της Πληροφορίας και είναι χονδρικά ένα μέτρο του πόσο πολύ μια λέξη μας πληροφορεί για μια άλλη.")
111
Η προτεινόμενη μέθοδος του X 2 στατιστικού ελέγχου Η βασιζόμενη στην συχνότητα εμφάνισης μέθοδο έχει μια αδυναμία. Αποτυγχάνει στην περίπτωση που έχουμε ακραίες τιμές Outliers (Bigrams με πολύ υψηλή συχνότητα) Η βασιζόμενη στην συχνότητα εμφάνισης μέθοδο έχει μια αδυναμία. Αποτυγχάνει στην περίπτωση που έχουμε ακραίες τιμές Outliers (Bigrams με πολύ υψηλή συχνότητα) Εμείς θα παρουσιάσουμε μια εναλλακτική προσέγγιση πού βασίζεται στον X 2 στατιστικό έλεγχο. Εμείς θα παρουσιάσουμε μια εναλλακτική προσέγγιση πού βασίζεται στον X 2 στατιστικό έλεγχο. Θα δώσουμε επίσης ένα εναλλακτικό τύπο για τον υπολογισμό της X 2 στατιστικής για την περίπτωση της εξαγωγής bigrams από το corpus Θα δώσουμε επίσης ένα εναλλακτικό τύπο για τον υπολογισμό της X 2 στατιστικής για την περίπτωση της εξαγωγής bigrams από το corpus
 Η βασιζόμενη στην συχνότητα εμφάνισης μέθοδο έχει μια αδυναμία. Αποτυγχάνει στην περίπτωση που έχουμε ακραίες τιμές Outliers (Bigrams με πολύ υψηλή συχνότητα) Εμείς θα παρουσιάσουμε μια εναλλακτική προσέγγιση πού βασίζεται στον X 2 στατιστικό έλεγχο. Εμείς θα παρουσιάσουμε μια εναλλακτική προσέγγιση πού βασίζεται στον X 2 στατιστικό έλεγχο. Θα δώσουμε επίσης ένα εναλλακτικό τύπο για τον υπολογισμό της X 2 στατιστικής για την περίπτωση της εξαγωγής bigrams από το corpus Θα δώσουμε επίσης ένα εναλλακτικό τύπο για τον υπολογισμό της X 2 στατιστικής για την περίπτωση της εξαγωγής bigrams από το corpus.")
112
Η προτεινόμενη μέθοδος του X 2 στατιστικού ελέγχου To X2 είναι μια πολύ καλά ορισμένη στατιστική προσέγγιση που εκτιμά κατά πόσο ένα συμβάν είναι αποτέλεσμα της τύχης To X2 είναι μια πολύ καλά ορισμένη στατιστική προσέγγιση που εκτιμά κατά πόσο ένα συμβάν είναι αποτέλεσμα της τύχης Αυτό είναι ένα από τα γενικότερα προβλήματα στην στατιστική και συνήθως διατυπώνεται από την άποψη του Hypothesis testing Αυτό είναι ένα από τα γενικότερα προβλήματα στην στατιστική και συνήθως διατυπώνεται από την άποψη του Hypothesis testing Στην περίπτωσή μας θέλουμε να ξέρουμε κατά πόσο δύο λέξεις εμφανίζονται περισσότερο συχνά μαζί απ’ ότι στην τύχη Στην περίπτωσή μας θέλουμε να ξέρουμε κατά πόσο δύο λέξεις εμφανίζονται περισσότερο συχνά μαζί απ’ ότι στην τύχη

113
Η προτεινόμενη μέθοδος του X 2 στατιστικού ελέγχου Διατυπώνουμε την μηδενική υπόθεση (null Hypothesis H 0 ) ότι δεν υπάρχει διασύνδεση μεταξύ των δύο λέξεων πέραν από αυτήν της εμφάνισης μαζί από τύχη. Διατυπώνουμε την μηδενική υπόθεση (null Hypothesis H 0 ) ότι δεν υπάρχει διασύνδεση μεταξύ των δύο λέξεων πέραν από αυτήν της εμφάνισης μαζί από τύχη. Υπολογίζουμε την πιθανότητα (p 0 ) πού θα είχε το συμβάν εάν η H 0 ήταν αληθινή. Υπολογίζουμε την πιθανότητα (p 0 ) πού θα είχε το συμβάν εάν η H 0 ήταν αληθινή. Εάν η p 0 είναι μικρή, τυπικά κάτω από ένα προκαθορισμένο επίπεδο σημαντικότητας p 0 <0.005 ή p 0 <0.001 απορρίπτουμε την Η 0 διαφορετικά την δεχόμαστε ως αληθινή Εάν η p 0 είναι μικρή, τυπικά κάτω από ένα προκαθορισμένο επίπεδο σημαντικότητας p 0 <0.005 ή p 0 <0.001 απορρίπτουμε την Η 0 διαφορετικά την δεχόμαστε ως αληθινή
 ότι δεν υπάρχει διασύνδεση μεταξύ των δύο λέξεων πέραν από αυτήν της εμφάνισης μαζί από τύχη. Υπολογίζουμε την πιθανότητα (p 0 ) πού θα είχε το συμβάν εάν η H 0 ήταν αληθινή. Υπολογίζουμε την πιθανότητα (p 0 ) πού θα είχε το συμβάν εάν η H 0 ήταν αληθινή. Εάν η p 0 είναι μικρή, τυπικά κάτω από ένα προκαθορισμένο επίπεδο σημαντικότητας p 0 <0.005 ή p 0 <0.001 απορρίπτουμε την Η 0 διαφορετικά την δεχόμαστε ως αληθινή Εάν η p 0 είναι μικρή, τυπικά κάτω από ένα προκαθορισμένο επίπεδο σημαντικότητας p 0 <0.005 ή p 0 <0.001 απορρίπτουμε την Η 0 διαφορετικά την δεχόμαστε ως αληθινή.")
114
Η προτεινόμενη μέθοδος του X 2 στατιστικού ελέγχου Στην στατιστική γενικότερα για τον υπολογισμό τέτοιων πιθανοτήτων για την απόρριψη ή μη της μηδενικής υπόθεσης χρησιμοποιούμε τον student στατιστικό έλεγχο (t-statistic), που υποθέτει κανονικά κατανεμημένα στατιστικά δείγματα Στην στατιστική γενικότερα για τον υπολογισμό τέτοιων πιθανοτήτων για την απόρριψη ή μη της μηδενικής υπόθεσης χρησιμοποιούμε τον student στατιστικό έλεγχο (t-statistic), που υποθέτει κανονικά κατανεμημένα στατιστικά δείγματα O λόγος που επιλέξαμε τον Χ2 στατιστικό έλεγχο είναι ότι δεν υποθέτει ότι τα δεδομένα ακολουθούν την κανονική κατανομή (free distribution), κάτι που είναι πολύ σωστό στην περίπτωση λέξεων κειμένων O λόγος που επιλέξαμε τον Χ2 στατιστικό έλεγχο είναι ότι δεν υποθέτει ότι τα δεδομένα ακολουθούν την κανονική κατανομή (free distribution), κάτι που είναι πολύ σωστό στην περίπτωση λέξεων κειμένων
, που υποθέτει κανονικά κατανεμημένα στατιστικά δείγματα Στην στατιστική γενικότερα για τον υπολογισμό τέτοιων πιθανοτήτων για την απόρριψη ή μη της μηδενικής υπόθεσης χρησιμοποιούμε τον student στατιστικό έλεγχο (t-statistic), που υποθέτει κανονικά κατανεμημένα στατιστικά δείγματα O λόγος που επιλέξαμε τον Χ2 στατιστικό έλεγχο είναι ότι δεν υποθέτει ότι τα δεδομένα ακολουθούν την κανονική κατανομή (free distribution), κάτι που είναι πολύ σωστό στην περίπτωση λέξεων κειμένων O λόγος που επιλέξαμε τον Χ2 στατιστικό έλεγχο είναι ότι δεν υποθέτει ότι τα δεδομένα ακολουθούν την κανονική κατανομή (free distribution), κάτι που είναι πολύ σωστό στην περίπτωση λέξεων κειμένων")
115
Η εφαρμογή της μεθόδου και σύγκριση με την μέθοδο Mean and Variance Σε ότι ακολουθεί σε αυτή την ενότητα Περιγράφουμε πιο αναλυτικά τις δύο μεθόδους Δίνουμε πειραματικά αποτελέσματα από την εφαρμογή τους πάνω σε ένα σώμα (corpus) Ελληνικών κειμένων
 Ελληνικών κειμένων")
116
Η μέθοδος Mean and Variance

117
Η εφαρμογή της μεθόδου και σύγκριση με την μέθοδο Mean and Variance Ας δούμε ένα παράδειγμα υπολογισμού του μέσου και της Απόκλισης. Έστω οι προτάσεις από την Ελληνική γλώσσα για τις λέξεις “κτύπησε” και “πόρτα”.

118
Η μέθοδος Mean and Variance Μπορούμε να υπολογίσουμε το μέσο (mean) και την διακύμανση των αποστάσεων της λέξης “κτύπησε” σε σχέση με την λέξη “πόρτα”
 και την διακύμανση των αποστάσεων της λέξης κτύπησε σε σχέση με την λέξη πόρτα")
119
Η μέθοδος Mean and Variance Ο μέσος και η διασπορά μας βοηθά να βρούμε Collocations ψάχνοντας για ζευγάρια με την πιο χαμηλή διασπορά (spread) Όσο πιο χαμηλή είναι η διακύμανση μεταξύ των αποστάσεων σε ένα ζευγάρι λέξεων τόσο πιο ισχυρή είναι η ένδειξη ότι αυτό το ζευγάρι αποτελεί Collocation Μια οξεία κορυφούμενη κατανομή των αποστάσεων είναι ισχυρή ένδειξη. Ας το εξηγήσουμε αυτό με δύο κατανομές με πραγματικά δεδομένα από το σώμα αποτίμησης των μεθόδων (Evaluation Corpus)
.")
120
Η μέθοδος Mean and Variance

122
Το 1900 ο Karl Pearson πρότεινε μια στατιστική, την Χ 2 στατιστική, η οποία συγκρίνει τους παρατηρηθέντες με τους αναμενόμενους αριθμούς όταν οι δυνατές εκβάσεις ενός πειράματος υποδιαιρούνται σε αμοιβαία αποκλειόμενες κατηγορίες Η μέθοδος Χ-τετράγωνο Το Σ παριστάνει το άθροισμα και υπολογίζεται για όλες τις δυνατές εκβάσεις του πειράματος

123
Οι αναμενόμενες και οι παρατηρηθείσες συχνότητες μπορούν να εξηγηθούν στο πλαίσιο του Hypothesis testing Εάν τα δεδομένα διαιρούνται σε αμοιβαία αποκλειόμενες κατηγορίες και διατυπώσουμε μια μηδενική υπόθεση για τα δεδομένα Τότε Η αναμενόμενη τιμή είναι η τιμή για την κάθε κατηγορία εάν η μηδενική υπόθεση είναι αληθινή Η παρατηρηθείσα τιμή για κάθε κατηγορία προκύπτει από τα δεδομένα του δείγματος Η μέθοδος Χ-τετράγωνο

124
Για να γίνει πιο κατανοητή η εφαρμογή της παραπάνω μεθόδου δίνουμε ένα παράδειγμα Έστω ότι έχουμε ένα γλωσσολογικό corpus και ενδιαφερόμαστε να εξαγάγουμε Collocations Ορίζουμε ένα collocational window 10 λέξεων και μετράμε την συχνότητα εμφάνισης του ζευγαριού των λέξεων “ισχυρός” και “άνδρας” Η μέθοδος Χ-τετράγωνο

125
Προκύπτουν τα ακόλουθα. 10 εμφανίσεις του ζευγαριού (ισχυρός, άνδρας) μέσα στο corpus 1000 bigrams όπου η δεύτερη λέξη είναι “άνδρας” και η πρώτη όχι “ισχυρός” 500 bigrams όπου η πρώτη λέξη είναι “ισχυρός” και η δεύτερη όχι “άνδρας” 1,500,000 bigrams που δεν περιέχουν καμμία από τις δύο λέξεις δεδομένου του Collocational window Η μέθοδος Χ-τετράγωνο
 μέσα στο corpus 1000 bigrams όπου η δεύτερη λέξη είναι άνδρας και η πρώτη όχι ισχυρός 500 bigrams όπου η πρώτη λέξη είναι ισχυρός και η δεύτερη όχι άνδρας 1,500,000 bigrams που δεν περιέχουν καμμία από τις δύο λέξεις δεδομένου του Collocational window Η μέθοδος Χ-τετράγωνο.")
126
Στην περίπτωση αυτή θα ήταν χρήσιμο να χρησιμοποιήσουμε τον πίνακα συνάφειας (Contingency table)
")
127
Χρησιμοποιώντας maximum likelihood estimates μπορούμε να υπολογίσουμε την πιθανότητα εμφάνισης του ζευγαριού που απορρέει από την μηδενική υπόθεση Η μέθοδος Χ-τετράγωνο Η μηδενική υπόθεση είναι ότι οι εμφανίσεις του “ισχυρός” και “άνδρας” είναι ανεξάρτητες

128
Έπειτα υπολογίζουμε την Χ 2 τιμή από την εξίσωση 3.7 Από τους πίνακες της Χ 2 κατανομής βρίσκουμε την κρίσιμη τιμή για ένα επίπεδο σημαντικότητας (συνήθως α=0.05) Εάν η υπολογιζόμενη Χ 2 τιμή είναι μεγαλύτερη από την κρίσιμη τιμή μπορούμε να απορρίψουμε την μηδενική υπόθεση ότι οι λέξεις “ισχυρός” και “άνδρας” εμφανίζονται ανεξάρτητα Επομένως για μεγάλες τιμές του Χ 2 στατιστικού ελέγχου έχουμε ισχυρή ένδειξη για τον σχηματισμό Collocation Η μέθοδος Χ-τετράγωνο
 Εάν η υπολογιζόμενη Χ 2 τιμή είναι μεγαλύτερη από την κρίσιμη τιμή μπορούμε να απορρίψουμε την μηδενική υπόθεση ότι οι λέξεις ισχυρός και άνδρας εμφανίζονται ανεξάρτητα Επομένως για μεγάλες τιμές του Χ 2 στατιστικού ελέγχου έχουμε ισχυρή ένδειξη για τον σχηματισμό Collocation Η μέθοδος Χ-τετράγωνο")
129
Για ένα 2x2 πίνακα συνάφειας για τον υπολογισμό της Χ2 στατιστικής μπορούμε να χρησιμοποιήσουμε τον παρακάτω τύπο Η μέθοδος Χ-τετράγωνο Όπου α ij οι καταχωρήσεις του 2x2 πίνακα συνάφειας και Ν το άθροισμα αυτών των καταχωρήσεων

130
Πειραματικά αποτελέσματα Αρκετά αρχεία κειμένων της Νεοελληνικής γλώσσας ήταν διαθέσιμα σε εμάς σε ηλεκτρονική μορφή από διάφορες πηγές Μια πρωταρχική μορφολογική διαδικασία part-of- speech tagging σημείωσε το μέρος του λόγου και το λήμμα για κάθε λέξη του σώματος (corpus) Ατυχώς η προεπεξεργασία μας δεν ήταν ικανή να μας παράσχει τα λήμματα για ρήματα και επιρρήματα.
 Ατυχώς η προεπεξεργασία μας δεν ήταν ικανή να μας παράσχει τα λήμματα για ρήματα και επιρρήματα.")
131
Πειραματικά αποτελέσματα Η κατανομή των λημμάτων στο corpus φαίνεται στον παρακάτω πίνακα

132
O μόνος συνδυασμός διγραμμάτων (bigrams) που μπορούμε να δοκιμάσουμε είναι (Επίθετο, Ουσιαστικό), καθώς δεν περιέχονται τα άλλα μέρη του λόγου Ορίζουμε ένα collocational window μήκους 10 λέξεων συμπεριλαμβανομένων και των σημείων στίξης Πειραματικά αποτελέσματα Ανάλυση διασποράς Υπολογίζουμε από το Corpus τις αποστάσεις και την τυπική απόκλιση για όλους τους συνδυασμούς των διγραμμάτων (Επίθετο, Ουσιαστικό)
 που μπορούμε να δοκιμάσουμε είναι (Επίθετο, Ουσιαστικό), καθώς δεν περιέχονται τα άλλα μέρη του λόγου Ορίζουμε ένα collocational window μήκους 10 λέξεων συμπεριλαμβανομένων και των σημείων στίξης Πειραματικά αποτελέσματα Ανάλυση διασποράς Υπολογίζουμε από το Corpus τις αποστάσεις και την τυπική απόκλιση για όλους τους συνδυασμούς των διγραμμάτων (Επίθετο, Ουσιαστικό)")
133
Ανάλυση διασποράς

138
Ανάλυση του Ελέγχου Χ 2 Διατυπώνουμε την μηδενική υπόθεση της στατιστικής ανεξαρτησίας μεταξύ των δύο λέξεων που απαρτίζουν το δείγμα Αυτό σημαίνει ότι οι δύο λέξεις εμφανίζονται ανεξάρτητες η μία από την άλλη μέσα στο δείγμα στο οποίο και κατανέμονται τυχαία Υπολογίζουμε την X 2 στατιστική με τον τρόπο πού περιγράψαμε παραπάνω. Όσο μεγαλύτερη είναι η τιμή τόσο πιο ισχυρή είναι η ένδειξη για να απορρίψουμε την μηδενική υπόθεση

139
Ανάλυση του Ελέγχου Χ 2

141
Συμπεράσματα Στο κεφάλαιο αυτό εφαρμόσαμε τον έλεγχο Χ 2 για την ανάδειξη ζευγαριών λέξεων πού ενδεχόμενα να σχηματίζουν Collocations. H μέθοδος αυτή υπερτερεί της κλασσικής ανάλυσης της διασποράς η οποία αποτυγχάνει στην περίπτωση ακραίων τιμών “Outliers”. Επίσης υπερτερεί και άλλων μεθόδων που έχουν εφαρμοσθεί κατά καιρούς, όπως του t-test, likelihood (LL) ratio test, mutual Information γιατί αυτές οι μέθοδοι έχουν το μειονέκτημα ότι υποθέτουν παραμετρική κατανομή δεδομένων.
 ratio test, mutual Information γιατί αυτές οι μέθοδοι έχουν το μειονέκτημα ότι υποθέτουν παραμετρική κατανομή δεδομένων..")
142
Συμπεράσματα Επιπλέον η μέθοδος mutual information (MI), συγκρίνει την συνδεδεμένη πιθανότητα p(w 1,w 2 ) και απαιτεί οι ανεξάρτητες πιθανότητες p(w 1 ) και p(w 2 ) να συμβαίνουν με οποιονδήποτε τρόπο στο δείγμα, το οποίο δεν δίνει μια ρεαλιστική εικόνα στην περίπτωση χαμηλών συχνοτήτων Πολλά κοινά bigrams βρέθηκαν στις πρώτες θέσης βαθμολογίας των μεθόδων της διασποράς και του X2 ελέγχου, σε κάθε περίπτωση όμως εναπόκειται στους ειδικούς γλωσσολόγους να αξιολογήσουν αυτά τα ευρήματα.
, συγκρίνει την συνδεδεμένη πιθανότητα p(w 1,w 2 ) και απαιτεί οι ανεξάρτητες πιθανότητες p(w 1 ) και p(w 2 ) να συμβαίνουν με οποιονδήποτε τρόπο στο δείγμα, το οποίο δεν δίνει μια ρεαλιστική εικόνα στην περίπτωση χαμηλών συχνοτήτων Πολλά κοινά bigrams βρέθηκαν στις πρώτες θέσης βαθμολογίας των μεθόδων της διασποράς και του X2 ελέγχου, σε κάθε περίπτωση όμως εναπόκειται στους ειδικούς γλωσσολόγους να αξιολογήσουν αυτά τα ευρήματα.")
143
O X2 Στατιστικός Έλεγχος στην Αποσαφήνιση Εννοιών Λέξεων Word Sense Disambiguation

144
Αποσαφήνιση Εννοιών Η συντριπτική πλειονότητα των λέξεων που εμφανίζονται σε κείμενα φυσικής γλώσσας είναι πολύσημες, δηλαδή εμφανίζονται με διαφορετικές σημασίες σε διαφορετικά linguistic contexts (πλαίσια κειμένου). Πχ, η Αγγλική λέξη “bank”, μπορεί να έχει σε κάποιο context την έννοια της “τράπεζας” και σε άλλο την έννοια της “όχθης ποταμού”. Μέσα στο ίδιο πλαίσιο των X2 στατιστικών ελέγχων, με την βοήθεια του ηλεκτρονικού λεξικού WordNet, θα αναπτύξουμε μια μέθοδο για την αποσαφήνιση της έννοιας μιας λέξης πού εμφανίζεται σε ένα context.

145
Αποσαφήνιση Εννοιών Σύμφωνα με την μέθοδο αυτή εργαζόμαστε ως εξής. Επαυξάνουμε το πλαίσιο (context) στο οποίο εμφανίζεται η προς αποσαφήνιση λέξη με συσχετιζόμενες έννοιες (Related Synsets) από το ηλεκτρονικό λεξικό WordNet. Το επαυξημένο πλαίσιο το θεωρούμε σαν ένα στατιστικό δείγμα Μελετάμε την κατανομή των συσχετιζόμενων εννοιών της κάθε μια έννοιας της προς αποσαφήνιση λέξης στο στατιστικό αυτό δείγμα
 στο οποίο εμφανίζεται η προς αποσαφήνιση λέξη με συσχετιζόμενες έννοιες (Related Synsets) από το ηλεκτρονικό λεξικό WordNet. Το επαυξημένο πλαίσιο το θεωρούμε σαν ένα στατιστικό δείγμα Μελετάμε την κατανομή των συσχετιζόμενων εννοιών της κάθε μια έννοιας της προς αποσαφήνιση λέξης στο στατιστικό αυτό δείγμα.")
146
Αποσαφήνιση Εννοιών Διατυπώνουμε την μηδενική υπόθεση ότι όλες οι συσχετιζόμενες έννοιες, δηλαδή τα Related Synsets από το WordNet κατανέμονται κανονικά (Normally) στο δείγμα. Με την βοήθεια του Χ 2 στατιστικού ελέγχου καλού ταιριάσματος (X 2 Goodness of fit statistical test), προσπαθούμε να εντοπίσουμε την έννοια της οποίας τα related Synsets αποκλίνουν από αυτή την υπόθεση. Την έννοια αυτή την επιλέγουμε σαν την σωστή έννοια της προς αποσαφήνιση λέξης
, προσπαθούμε να εντοπίσουμε την έννοια της οποίας τα related Synsets αποκλίνουν από αυτή την υπόθεση. Την έννοια αυτή την επιλέγουμε σαν την σωστή έννοια της προς αποσαφήνιση λέξης.")
147
Αποσαφήνιση λέξης και WordNet To πρόβλημα της απόδοσης της σωστής έννοιας μια λέξης (target word) μέσα στο πλαίσιο (context) που αποτελείται από τις περιβάλλουσες λέξεις είναι η αποστολή των συστημάτων αποσαφήνισης λέξης Αναγνωρίζεται σαν ένα από τα πιο δύσκολα προβλήματα στην επεξεργασία φυσικής γλώσσας. Πολλά συστήματα έχουν προταθεί κατά καιρούς η πλειονότητα των οποίων στηρίζεται σε στατιστικές μεθόδους επεξεργασίας

148
Αποσαφήνιση λέξης και WordNet Τα πρώτα συστήματα εβασίζοντο σε εμπειρικούς κανόνες και χρησιμοποιώντας μικρά λεξικά (καταλόγους εννοιών) αποσαφήνιζαν μικρό αριθμό περιπτώσεων [16],[17],[18] Σήμερα με την διαθεσιμότητα μεγάλων ηλεκτρονικών λεξικών όπως το WordNet, δίνει μεγάλη ώθηση για την ανάπτυξη απαιτητικών εφαρμογών στην αποσαφήνιση λέξης [20],[21],[22]. Επί πλέον το γεγονός ότι οι διάφορες έννοιες συνδέονται μεταξύ τους με ένα μεγάλο αριθμό από σημασιολογικές (semantic) και λεξικολογικές (lexical) σχέσεις κάνει το WordNet πολύτιμη πηγή για την αναπαράσταση των δικτύων γνώσης
![Αποσαφήνιση λέξης και WordNet Τα πρώτα συστήματα εβασίζοντο σε εμπειρικούς κανόνες και χρησιμοποιώντας μικρά λεξικά (καταλόγους εννοιών) αποσαφήνιζαν μικρό αριθμό περιπτώσεων [16],[17],[18] Σήμερα με την διαθεσιμότητα μεγάλων ηλεκτρονικών λεξικών όπως το WordNet, δίνει μεγάλη ώθηση για την ανάπτυξη απαιτητικών εφαρμογών στην αποσαφήνιση λέξης [20],[21],[22].](http://images.slideplayer.gr/10/2849982/slides/slide_148.jpg "Επί πλέον το γεγονός ότι οι διάφορες έννοιες συνδέονται μεταξύ τους με ένα μεγάλο αριθμό από σημασιολογικές (semantic) και λεξικολογικές (lexical) σχέσεις κάνει το WordNet πολύτιμη πηγή για την αναπαράσταση των δικτύων γνώσης.")
149
Αποσαφήνιση λέξης και WordNet Χρησιμοποιώντας ορισμούς από το WordNet και κείμενα από το Internet οι Mihalcea και Moldovan [23], συγκέντρωσαν λεξικολογική πληροφορία για την αποσαφήνιση πολύσημων λέξεων Οι Montoyo και Palomar [24] παρουσίασαν μέθοδο για την αποσαφήνιση λέξεων στηριζόμενοι στις σημασιολογικές τάξεις (semantic classes) του Wordnet καθώς και στους ορισμούς του λεξικού. Η εργασία των Banerjee και Pederson [25] παρουσιάζει μια προσαρμογή του αλγορίθμου Lesk [16] πού βασίζεται στους ορισμούς του Wordnet.
![Αποσαφήνιση λέξης και WordNet Χρησιμοποιώντας ορισμούς από το WordNet και κείμενα από το Internet οι Mihalcea και Moldovan [23], συγκέντρωσαν λεξικολογική πληροφορία για την αποσαφήνιση πολύσημων λέξεων Οι Montoyo και Palomar [24] παρουσίασαν μέθοδο για την αποσαφήνιση λέξεων στηριζόμενοι στις σημασιολογικές τάξεις (semantic classes) του Wordnet καθώς και στους ορισμούς του λεξικού.](http://images.slideplayer.gr/10/2849982/slides/slide_149.jpg "Η εργασία των Banerjee και Pederson [25] παρουσιάζει μια προσαρμογή του αλγορίθμου Lesk [16] πού βασίζεται στους ορισμούς του Wordnet..")
150
Αποσαφήνιση λέξης και WordNet Εκτός από τους ορισμούς πολύ δουλειά έχει πραγματοποιηθεί χρησιμοποιώντας και την σχέση ιεραρχίας του Wordnet (Hypernymy/Hyponymy relation) O Resnic [21] αποσαφήνισε λεξικά χρησιμοποιώντας την σημασιολογική ομοιότητα (semantic similarity) μεταξύ δύο λέξεων διαλέγοντας τον κοινό πρόγονο με το μεγαλύτερο πληροφοριακό περιεχόμενο (the most informative “subsumer”), όπου το πληροφοριακό περιεχόμενο το όρισε σαν συνάρτηση του πλήθους των υπαγόμενων όρων Leacock και Chodorow [26], πρότειναν ένα μέτρο για τον υπολογισμό της σημασιολογικής ομοιότητας μετρώντας το μήκος της διαδρομήςμεταξύ των δύο κόμβων της ιεραρχίας
![Αποσαφήνιση λέξης και WordNet Εκτός από τους ορισμούς πολύ δουλειά έχει πραγματοποιηθεί χρησιμοποιώντας και την σχέση ιεραρχίας του Wordnet (Hypernymy/Hyponymy relation) O Resnic [21] αποσαφήνισε λεξικά χρησιμοποιώντας την σημασιολογική ομοιότητα (semantic similarity) μεταξύ δύο λέξεων διαλέγοντας τον κοινό πρόγονο με το μεγαλύτερο πληροφοριακό περιεχόμενο (the most informative subsumer ), όπου το πληροφοριακό περιεχόμενο το όρισε σαν συνάρτηση του πλήθους των υπαγόμενων όρων Leacock και Chodorow [26], πρότειναν ένα μέτρο για τον υπολογισμό της σημασιολογικής ομοιότητας μετρώντας το μήκος της διαδρομήςμεταξύ των δύο κόμβων της ιεραρχίας](http://images.slideplayer.gr/10/2849982/slides/slide_150.jpg "Αποσαφήνιση λέξης και WordNet Εκτός από τους ορισμούς πολύ δουλειά έχει πραγματοποιηθεί χρησιμοποιώντας και την σχέση ιεραρχίας του Wordnet (Hypernymy/Hyponymy relation) O Resnic [21] αποσαφήνισε λεξικά χρησιμοποιώντας την σημασιολογική ομοιότητα (semantic similarity) μεταξύ δύο λέξεων διαλέγοντας τον κοινό πρόγονο με το μεγαλύτερο πληροφοριακό περιεχόμενο (the most informative subsumer ), όπου το πληροφοριακό περιεχόμενο το όρισε σαν συνάρτηση του πλήθους των υπαγόμενων όρων Leacock και Chodorow [26], πρότειναν ένα μέτρο για τον υπολογισμό της σημασιολογικής ομοιότητας μετρώντας το μήκος της διαδρομήςμεταξύ των δύο κόμβων της ιεραρχίας")
151
Προσέγγιση των στατιστικών ελέγχων Στο προηγούμενο πνεύμα της εφαρμογής στατιστικών ελέγχων παρουσιάζουμε μια προσέγγιση για συστήματα αποσαφήνισης λέξης βασιζόμενοι σε μια διαφορετική αντίληψη για την εκτίμηση του μέτρου της σχετικότητας (relatedness) μεταξύ του context μιας λέξης και της κάθε μιας έννοιας ξεχωριστά Στο WordNet κάθε λεξική καταχώριση αναπαριστά μια έννοια και αποδίδεται με ένα σύνολο από συνώνυμες λέξεις που λέγεται Synset.
 μεταξύ του context μιας λέξης και της κάθε μιας έννοιας ξεχωριστά Στο WordNet κάθε λεξική καταχώριση αναπαριστά μια έννοια και αποδίδεται με ένα σύνολο από συνώνυμες λέξεις που λέγεται Synset.")
152
Προσέγγιση των στατιστικών ελέγχων Το σχήμα δείχνει πως είναι οι καταχωρήσεις στο Wordnet (τυχαία σειρά, ο αριθμός στην αρχή στην παρένθεση είναι ο αύξων αριθμός καταχώρησης στο WordNet ). WordNet Εννοια (Sense ή Synset) Επεξήγηση (gloss) (320) city, metropolis, urban center a large and densely populated urban area (1437) man, adult male an adult male person (4) walk, walking the act of travelling by foot
 Επεξήγηση (gloss) (320) city, metropolis, urban center a large and densely populated urban area (1437) man, adult male an adult male person (4) walk, walking the act of travelling by foot.")
153
Προσέγγιση των στατιστικών ελέγχων Ετσι λοιπόν οι καταχωρήσεις στο WordNet αποκαλούνται synsets. Κάθε synset είναι μοναδικό και συνηθίζουμε να το συμβολίζουμε με άγκιστρα. Π.χ. { city, metropolis, urban center }, { man, adult male } κλπ. Η μεγάλη διαφορά του WordNet με τα συμαβατικά λεξικά είναι οι συσχετίσεις μεταξύ των Synsets. Κάθε Synset συσχετίζεται με άλλα Synsets με διάφορες σχέσεις. Tο παρακάτω σχήμα δίνει μια εικόνα της κατάστασης στο WordNet.

154
Προσέγγιση των στατιστικών ελέγχων

155
Αυτά τα συσχετιζόμενα Synsets τα λέμε Related Synsets. Τέτοιες συσχετίσεις συναντάμε αρκετές στο WordNet. Τέτοιες συσχετίσεις συναντάμε αρκετές στο WordNet. Υπάρχουν 32 τέτοιες συσχετίσεις και κατανέμονται στa κύρια μέρη του λόγου (ένα μεγάλο ποσοστό είναι για ουσιαστικά και ρήματα αλλά υπάρχουν βέβαια και για επίθετα και επιρρήματα Υπάρχουν 32 τέτοιες συσχετίσεις και κατανέμονται στa κύρια μέρη του λόγου (ένα μεγάλο ποσοστό είναι για ουσιαστικά και ρήματα αλλά υπάρχουν βέβαια και για επίθετα και επιρρήματα (βλέπε διατριβή για αναλυτική παρουσίαση) (βλέπε διατριβή για αναλυτική παρουσίαση)
 (βλέπε διατριβή για αναλυτική παρουσίαση).")
156
Οι Εννοιες (Senses): Κάθε λεξική μορφή σε μια γλώσσα εμφανίζεται με πολλές έννοιες σε διάφορες προτάσεις (context). Πχ η λέξη bank μπορεί να έχει μεταξύ των άλλων σε ένα context την έννοια του Financial Institute, ενώ σε ένα άλλο την έννοια της όχθης του ποταμού (bank river). Κάθε λεξική μορφή σε μια γλώσσα εμφανίζεται με πολλές έννοιες σε διάφορες προτάσεις (context). Πχ η λέξη bank μπορεί να έχει μεταξύ των άλλων σε ένα context την έννοια του Financial Institute, ενώ σε ένα άλλο την έννοια της όχθης του ποταμού (bank river). Αφού οι έννοιες στο WordNet αποδίδονται με Synsets, απλά η λέξη bank εμφανίζεται σε περισσότερα του ενός Synsets. Αφού οι έννοιες στο WordNet αποδίδονται με Synsets, απλά η λέξη bank εμφανίζεται σε περισσότερα του ενός Synsets. Να παρακάτω τα 10 Sysnsets sta οποία εμφανίζεται η λέξη bank. Ένα για κάθε μια από τις 10 έννοιες της πού έχει στο Wordnet. Να παρακάτω τα 10 Sysnsets sta οποία εμφανίζεται η λέξη bank. Ένα για κάθε μια από τις 10 έννοιες της πού έχει στο Wordnet. Χρηση των Related Synsets για Word Sense Disambiguation
. Κάθε λεξική μορφή σε μια γλώσσα εμφανίζεται με πολλές έννοιες σε διάφορες προτάσεις (context). Πχ η λέξη bank μπορεί να έχει μεταξύ των άλλων σε ένα context την έννοια του Financial Institute, ενώ σε ένα άλλο την έννοια της όχθης του ποταμού (bank river). Αφού οι έννοιες στο WordNet αποδίδονται με Synsets, απλά η λέξη bank εμφανίζεται σε περισσότερα του ενός Synsets. Αφού οι έννοιες στο WordNet αποδίδονται με Synsets, απλά η λέξη bank εμφανίζεται σε περισσότερα του ενός Synsets. Να παρακάτω τα 10 Sysnsets sta οποία εμφανίζεται η λέξη bank. Ένα για κάθε μια από τις 10 έννοιες της πού έχει στο Wordnet. Να παρακάτω τα 10 Sysnsets sta οποία εμφανίζεται η λέξη bank. Ένα για κάθε μια από τις 10 έννοιες της πού έχει στο Wordnet. Χρηση των Related Synsets για Word Sense Disambiguation.")
157
1. (883) depository financial institution, bank, banking concern, banking company -- (a financial institution that accepts deposits and channels the money into lending activities; "he cashed a check at the bank"; "that bank holds the mortgage on my home") 2. (99) bank -- (sloping land (especially the slope beside a body of water); "they pulled the canoe up on the bank"; "he sat on the bank of the river and watched the currents") 3. (76) bank -- (a supply or stock held in reserve for future use (especially in emergencies)) 4. (54) bank, bank building -- (a building in which commercial banking is transacted; "the bank is on the corner of Nassau and Witherspoon") 5. (7) bank -- (an arrangement of similar objects in a row or in tiers; "he operated a bank of switches") 6. (6) savings bank, coin bank, money box, bank -- (a container (usually with a slot in the top) for keeping money at home; "the coin bank was empty") 7. (3) bank -- (a long ridge or pile; "a huge bank of earth") 8. (1) bank -- (the funds held by a gambling house or the dealer in some gambling games; "he tried to break the bank at Monte Carlo") 9. (1) bank, cant, camber -- (a slope in the turn of a road or track; the outside is higher than the inside in order to reduce the effects of centrifugal force) 10. bank -- (a flight maneuver; aircraft tips laterally about its longitudinal axis (especially in turning); "the plane went into a steep bank")
 depository financial institution, bank, banking concern, banking company -- (a financial institution that accepts deposits and channels the money into lending activities; he cashed a check at the bank ; that bank holds the mortgage on my home ) 2. (99) bank -- (sloping land (especially the slope beside a body of water); they pulled the canoe up on the bank ; he sat on the bank of the river and watched the currents ) 3. (76) bank -- (a supply or stock held in reserve for future use (especially in emergencies)) 4. (54) bank, bank building -- (a building in which commercial banking is transacted; the bank is on the corner of Nassau and Witherspoon ) 5. (7) bank -- (an arrangement of similar objects in a row or in tiers; he operated a bank of switches ) 6. (6) savings bank, coin bank, money box, bank -- (a container (usually with a slot in the top) for keeping money at home; the coin bank was empty ) 7. (3) bank -- (a long ridge or pile; a huge bank of earth ) 8. (1) bank -- (the funds held by a gambling house or the dealer in some gambling games; he tried to break the bank at Monte Carlo ) 9. (1) bank, cant, camber -- (a slope in the turn of a road or track; the outside is higher than the inside in order to reduce the effects of centrifugal force) 10. bank -- (a flight maneuver; aircraft tips laterally about its longitudinal axis (especially in turning); the plane went into a steep bank ).")
158
Χρηση των Related Synsets για Word Sense Disambiguation To WordNet είναι ένας άρτιος και ολοκληρωμένος κατάλογος εννοιών για την Αγγλική που χρησιμοποιείται επίσημα σε διαγωνισμούς για testing Word Sense Disambiguation συστημάτων, όπως πχ ο Senseval Στο Senseval διαγωνισμό δίνονται διάφορα contexts και ζητάμε από τον αλγόριθμο να βρεί την σωστή έννοια της λέξης σύμφωνα με τον επίσημο κατάλογο του WordNet.

159
Χρηση των Related Synsets για Word Sense Disambiguation Τα contexts είναι προτάσεις μέσα στις οποίες εμφανίζεται η target λέξη που θέλουμε να αποσαφηνίσουμε. Να παρακάτω ένα παράδειγμα ενός context όπως δίνεται από το Senseval για την λέξη art Readers need also to be wary of the existence of special markets. The explosive prices for Teddy Bears in the last few years indicate how a market can be created, in this case by a mix of merit and nostalgia. What is clearly a dealers' market is often signalled by the invention of a brand name to group together a variety of material, perhaps rather disparate. Pop Art is an example.

160
Χρηση των Related Synsets για Word Sense Disambiguation Σε αυτό το context δίνεται ένα instance id="art.40003" και η λέξη που θέλουμε να αποσαφηνίσουμε εμφανίζεται μέσα στο tag Art. Πρέπει λοιπόν ο αλγόριθμός μας να βρεί την σωστή έννοια της λέξης art σε αυτό το context. Πρέπει να διαλέξει μια από 4 παρακάτω έννοιες του WordNet

161
1. (49) art, fine art -- (the products of human creativity; works of art collectively; "an art exhibition"; "a fine collection of art") 1. (49) art, fine art -- (the products of human creativity; works of art collectively; "an art exhibition"; "a fine collection of art") 2. (15) art, artistic creation, artistic production -- (the creation of beautiful or significant things; "art does not need to be innovative to be good"; "I was never any good at art"; "he said that architecture is the art of wasting space beautifully") 2. (15) art, artistic creation, artistic production -- (the creation of beautiful or significant things; "art does not need to be innovative to be good"; "I was never any good at art"; "he said that architecture is the art of wasting space beautifully") 3. (7) art, artistry, prowess -- (a superior skill that you can learn by study and practice and observation; "the art of conversation"; "it's quite an art") 3. (7) art, artistry, prowess -- (a superior skill that you can learn by study and practice and observation; "the art of conversation"; "it's quite an art") 4. (3) artwork, art, graphics, nontextual matter - - (photographs or other visual representations in a printed publication; "the publisher was responsible for all the artwork in the book") 4. (3) artwork, art, graphics, nontextual matter - - (photographs or other visual representations in a printed publication; "the publisher was responsible for all the artwork in the book")
 art, fine art -- (the products of human creativity; works of art collectively; an art exhibition ; a fine collection of art ) 1. (49) art, fine art -- (the products of human creativity; works of art collectively; an art exhibition ; a fine collection of art ) 2. (15) art, artistic creation, artistic production -- (the creation of beautiful or significant things; art does not need to be innovative to be good ; I was never any good at art ; he said that architecture is the art of wasting space beautifully ) 2. (15) art, artistic creation, artistic production -- (the creation of beautiful or significant things; art does not need to be innovative to be good ; I was never any good at art ; he said that architecture is the art of wasting space beautifully ) 3. (7) art, artistry, prowess -- (a superior skill that you can learn by study and practice and observation; the art of conversation ; it s quite an art ) 3. (7) art, artistry, prowess -- (a superior skill that you can learn by study and practice and observation; the art of conversation ; it s quite an art ) 4. (3) artwork, art, graphics, nontextual matter - - (photographs or other visual representations in a printed publication; the publisher was responsible for all the artwork in the book ) 4. (3) artwork, art, graphics, nontextual matter - - (photographs or other visual representations in a printed publication; the publisher was responsible for all the artwork in the book ).")
162
Χρηση των Related Synsets για Word Sense Disambiguation Όταν ο αλγόριθμός μας αποφασίσει για μια από τις 4 έννοιες πως θα ξέρουμε ότι τα πήγε καλά? Ο Senseval μας έχει δώσει εκ των προτέρων τις απαντήσεις σε ένα αρχείο το ckey όπου σε κάθε instance id μας αντιστοιχίζει την σωστή απάντηση, τον αριθμό της έννοιας στο WordNet (1,2,3 η 4) και έτσι εμείς χρησιμοποιώντας αυτό το αρχείο των σωστών απαντήσεων μπορούμε να βαθμολογήσουμε την απόδοση του αλγορίθμου μας.
 και έτσι εμείς χρησιμοποιώντας αυτό το αρχείο των σωστών απαντήσεων μπορούμε να βαθμολογήσουμε την απόδοση του αλγορίθμου μας..")
163
Ο προτεινόμενος Αλγόριθμος Αποσαφήνισης Ο αλγόριθμός μας είναι πάρα πολύ απλός στην σύλληψη του. Χρησιμοποιεί όπως είπαμε αρχικά τα Related Synsets του WordNet και μάλιστα την κατανομή αυτών και με την βοήθεια του στατιστικού ελέγχου αποφασίζει για την σωστή έννοια. Αυτό γίνεται ως εξής. Εξήγηση με δεδομένα ενός συγκεκριμένου παραδείγματος.

164
Ο προτεινόμενος Αλγόριθμος Αποσαφήνισης 1) Έχουμε το context για την λέξη art (το παραπάνω παράδειγμα) Readers need also to be wary of the existence of special markets. The explosive prices for Teddy Bears in the last few years indicate how a market can be created, in this case by a mix of merit and nostalgia. What is clearly a dealers' market is often signalled by the invention of a brand name to group together a variety of material, perhaps rather disparate. Pop Art is an example 2) Εχουμε και τις 4 έννοιες της λέξης art (4 Synsets toy WordNet)
 Εχουμε και τις 4 έννοιες της λέξης art (4 Synsets toy WordNet).")
165
Ο προτεινόμενος Αλγόριθμος Αποσαφήνισης Ενθυμούμαστε την δομική μονάδα του WordNet, το Synset, δηλαδή αυτές τις συνώνυμες λέξεις μέσα σε άγκιστρα. Μπορούμε να σχηματίσουμε ένα σύνολο από Related Synsets για το context και από ένα σύνολο Related synsets για κάθε μια από τις 4 έννοιες. O τρόπος περιγράφεται καλύτερα με το παρακάτω σχήμα παρά με λέξεις

167
Ο προτεινόμενος Αλγόριθμος Αποσαφήνισης Για κάθε λέξη του context, συμπεριλαμβανομένης και της προς αποσαφήνιση (και για όλα ανεξάρτητα τα senses της κάθε λέξης) μαζεύουμε τα Related Synsets από το WordNet. Επίσης για κάθε Sense της προς αποσαφήνιση λέξης art πάλι συγκεντρώνουμε τα Related Synsets από το WordNet.

168
Ο προτεινόμενος Αλγόριθμος Αποσαφήνισης Μελετώντας την κατανομή των Synsets της κάθε έννοιας της προς αποσαφήνιση λέξης μέσα στο context, προσδοκάμε η σωστή έννοια για κάποια συγκεκριμένα χαρακτηριστικά να επιδείξει μια διαφορετική συμπεριφορά Αυτό προσπαθούμε να συλλάβουμε με την βοήθεια του Χ 2 στατιστικού ελέγχου

169
Ο προτεινόμενος Αλγόριθμος Αποσαφήνισης H εφαρμογή του ελέγχου Έστω X i η τυχαία μεταβλητή που μετράει το αριθμό των εμφανίσεων του i-οστού συσχετιζόμενου synset μέσα στο context Διατυπώνουμε την μηδενική υπόθεση: Ότι τα συσχετιζόμενα synsets κατανέμονται κανονικά μέσα στο context, ότι δηλαδή ακολουθούν την κανονική κατανομή (normal distribution) Για τον υπολογισμό των p-τιμών του X 2 στατιστικού ελέγχου εργαζόμαστε ως εξής:
 Για τον υπολογισμό των p-τιμών του X 2 στατιστικού ελέγχου εργαζόμαστε ως εξής:")
170
Ο προτεινόμενος Αλγόριθμος Αποσαφήνισης H εφαρμογή του ελέγχου Προχωράμε σε κανονικοποίηση των παρατηρηθησών τιμών της τυχαίας μεταβλητής Χ Για να δημιουργήσουμε πινακοποιημένα δεδομένα (binned data) για τη θεωρούμενη κανονική κατανομή, επιλέγουμε τα διαστήματα X b (bins) με ίσο μήκος (-∞ -1.6 -1.2 -0.8 -0.4 0.4 0.8 1.2 1.6 +∞) Οι αναμενόμενες τιμές υπολογίζονται από την κανονική κατανομή για την κανονικοποιημένη μεταβλητή Z στα ανωτέρω διαστήματα X b Yπολογίζουμε τις τιμές της X 2 στατιστικής από την εξίσωση του Pearson
 για τη θεωρούμενη κανονική κατανομή, επιλέγουμε τα διαστήματα X b (bins) με ίσο μήκος (-∞ ∞) Οι αναμενόμενες τιμές υπολογίζονται από την κανονική κατανομή για την κανονικοποιημένη μεταβλητή Z στα ανωτέρω διαστήματα X b Yπολογίζουμε τις τιμές της X 2 στατιστικής από την εξίσωση του Pearson")
171
Ο προτεινόμενος Αλγόριθμος Αποσαφήνισης H εφαρμογή του ελέγχου Τέλος υπολογίζουμε τις p-τιμές Χ 2 συνάρτηση κατανομής για ένα επίπεδο σημαντικότητας 0.05 και «αριθμό διαστημάτων – 3» βαθμούς ελευθερίας (αφαιρούμε 3 γιατί αποκλείουμε τα άκρα από τα binned data

172
Αποτίμηση της προτεινόμενης μεθόδου Για την εκτίμηση της αποδοτικότητας της προτεινόμενης μεθόδου χρησιμοποιήσαμε όπως αναφέραμε παραπάνω τα δεδομένα που χρησιμοποιήθηκαν στον SenEval-2 διαγωνισμό Στον διαγωνισμό αυτό σαν μέτρο της αποδοτικότητας χρησιμοποιήθηκε το F-measure, το οποίο είναι ένας συνδυασμός του Precision και Recall

177
Συμπεράσματα Το σύστημά μας κάνοντας χρήση μόνο της λεξικολογικής πηγής του Wordnet επιτυγχάνει αποδοτικότητα 0.333 για Recall και F- measure. Η αποδοτικότητα αυτή είναι συγκρίσιμη με την αποδοτικότητα των δύο πρώτων συστημάτων του διαγωνισμού. Τα δύο αυτά συστήματα κάνουν χρήση ενός σημαντικού αριθμού από γλωσσολογικά δεδομένα (corpora) κατά την διαδικασία αποσαφήνισης
 κατά την διαδικασία αποσαφήνισης.")
178
ΕΠΙΛΟΓΟΣ Οι στατιστικές μέθοδοι θεωρούνται ως οι κατεξοχήν μέθοδοι για συστήματα Επεξεργασίας Φυσικής Γλώσσας, όπως: Information Retrieval, Word Sense Disambiguation, Text Classification, Collocations, κλπ. Στην παρούσα διατριβή παρουσιάσαμε μια μεθοδολογία εφαρμογής των στατιστικών ελέγχων «καλού ταιριάσματος» (Goodness of Fit Statistical Tests) για τις ανωτέρω περιοχές της Επεξεργασίας Φυσικής Γλώσσας
 για τις ανωτέρω περιοχές της Επεξεργασίας Φυσικής Γλώσσας.")
179
ΕΠΙΛΟΓΟΣ Τα περισσότερα προβλήματα επεξεργασίας φυσικής γλώσσας εμφανίζουν ένα κοινό χαρακτηριστικό, αυτό της επιλογής μεταξύ ανταγωνιζόμενων οντοτήτων για κάποιο συγκεκριμένο στόχο. Για παράδειγμα, ανταγωνιζόμενα έγγραφα στην ανάκτηση πληροφορίας, ανταγωνίζονται ως προς τον στόχο πού μπορεί να είναι η συνάφεια με το ερώτημα (query) ενός χρήστη, ανταγωνιζόμενες έννοιες στην αποσαφήνιση της έννοιας μιας λέξης, ή ανταγωνιζόμενα ζευγάρια λέξεων για τον σχηματισμό collocations.
 ενός χρήστη, ανταγωνιζόμενες έννοιες στην αποσαφήνιση της έννοιας μιας λέξης, ή ανταγωνιζόμενα ζευγάρια λέξεων για τον σχηματισμό collocations..")
180
ΕΠΙΛΟΓΟΣ Στη διατριβή χρησιμοποιήσαμε τον ‘Χ- τετράγωνον’ στατιστικό έλεγχο «καλού ταιριάσματος» για την αποτίμηση της σχετικότητας με το στόχο της κάθε ανταγωνιζόμενης οντότητας. Πιο συγκεκριμένα, διατυπώνεται μια μηδενική υπόθεση (null hypothesis) ότι οι διάφορες ανταγωνιζόμενες οντότητες δεν επιδεικνύουν καμία ιδιαίτερη συμπεριφορά έναντι του στόχου πέραν της τυχαίας. Αυτή είναι η θεωρητική υπόθεση που γίνεται για τα δεδομένα.
 ότι οι διάφορες ανταγωνιζόμενες οντότητες δεν επιδεικνύουν καμία ιδιαίτερη συμπεριφορά έναντι του στόχου πέραν της τυχαίας. Αυτή είναι η θεωρητική υπόθεση που γίνεται για τα δεδομένα..")
181
ΕΠΙΛΟΓΟΣ Από τα πραγματικά δεδομένα καταγράφεται η πραγματική συμπεριφορά της κάθε ανταγωνιζόμενης οντότητας και πιστοποιείται έτσι μια διαφορά (discrepancy) μεταξύ της πραγματικής συμπεριφοράς και αυτής πού απορρέει από την θεωρητική υπόθεση Η διαφορά αυτή ποσοτικοποιείται με την βοήθεια της ‘X2 κατανομής’ και αυτή η ποσοτικοποίηση είναι ικανή να χρησιμοποιηθεί ως μέτρο της αποτίμησης της σχετικότητας της ανταγωνιζόμενης οντότητας με το στόχο (ranking criterion).
 μεταξύ της πραγματικής συμπεριφοράς και αυτής πού απορρέει από την θεωρητική υπόθεση Η διαφορά αυτή ποσοτικοποιείται με την βοήθεια της ‘X2 κατανομής’ και αυτή η ποσοτικοποίηση είναι ικανή να χρησιμοποιηθεί ως μέτρο της αποτίμησης της σχετικότητας της ανταγωνιζόμενης οντότητας με το στόχο (ranking criterion).")
182
ΕΠΙΛΟΓΟΣ Πετύχαμε τον στόχο μας αναπτύσσοντας συστήματα που επιδεικνύουν καλή συμπεριφορά και αποδόσεις σε πολλές περιπτώσεις πολύ καλύτερες από αυτές των κλασσικών μεθόδων Δημιουργείται ένας ενιαίος τρόπος στατιστικής μεθοδολογίας για την επίλυση των δύσκολων προβλημάτων Επεξεργασίας Φυσικής Γλώσσας.

183
ΕΠΙΛΟΓΟΣ Δίνεται η δυνατότητα για παραμετροποίηση των συστημάτων Επεξεργασίας Φυσικής Γλώσσας αφού μέσα στο ίδιο πλαίσιο (framework) μπορούν να εξεταστούν πολλές εναλλακτικές θεωρητικές κατανομές για τα δεδομένα, αλλά και διαφορετικοί στατιστικοί έλεγχοι. Η συγκεκριμένη στατιστική μεθοδολογία οδηγεί σε απλά και εύκολα στον σχεδιασμό υπολογιστικά συστήματα, έναντι άλλων μεθόδων που κατά κανόνα χρησιμοποιούν σύνθετα και υπολογιστικά πολύπλοκα συστήματα Επεξεργασίας Φυσικής Γλώσσας.

184
ΕΠΙΛΟΓΟΣ Νομίζουμε ότι για την βελτίωση αυτών των συστημάτων όσο και η εφαρμογή της μεθοδολογίας και σε άλλες περιοχές της Επεξεργασίας Φυσικής Γλώσσας θα άξιζε να ασχοληθούμε συστηματικότερα στο μέλλον Νομίζουμε ότι για την βελτίωση αυτών των συστημάτων όσο και η εφαρμογή της μεθοδολογίας και σε άλλες περιοχές της Επεξεργασίας Φυσικής Γλώσσας θα άξιζε να ασχοληθούμε συστηματικότερα στο μέλλον ΤΕΛΟΣ ΤΕΛΟΣ

Παρόμοιες παρουσιάσεις




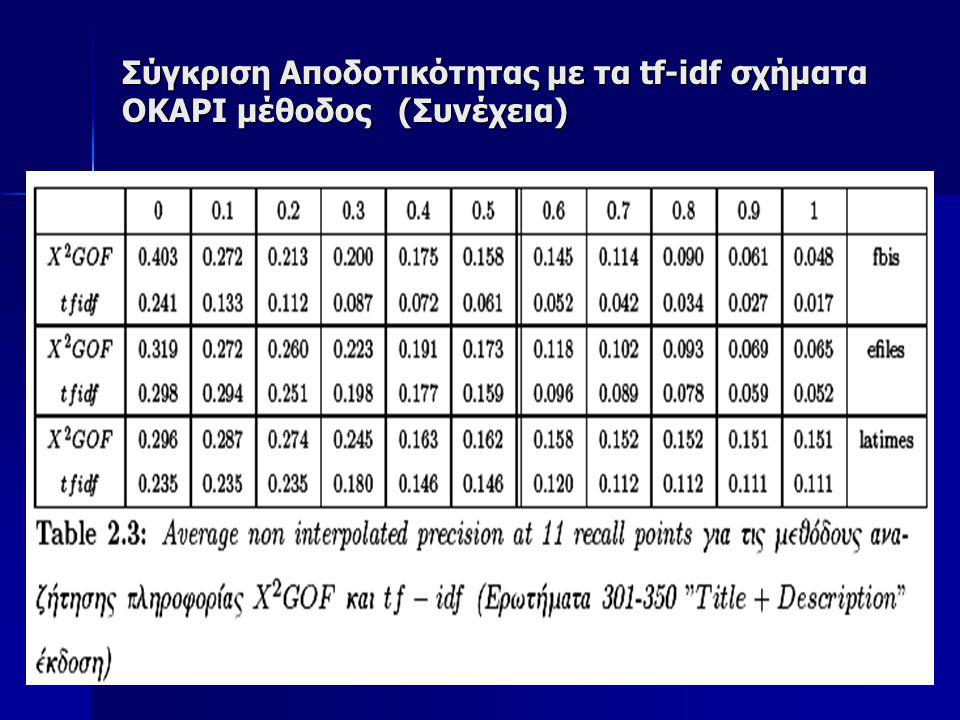
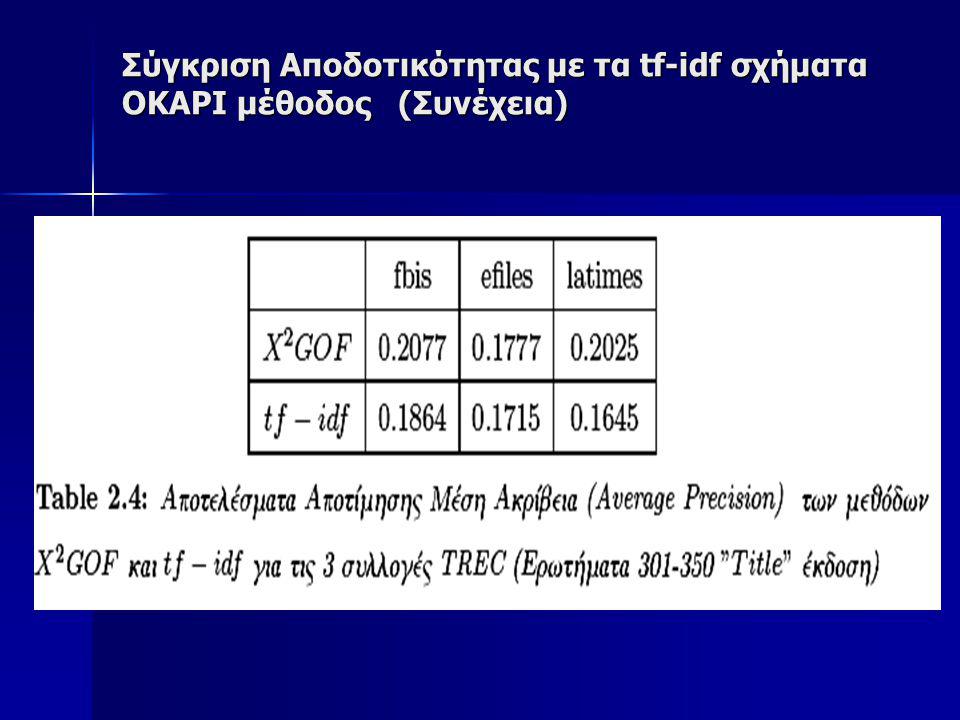
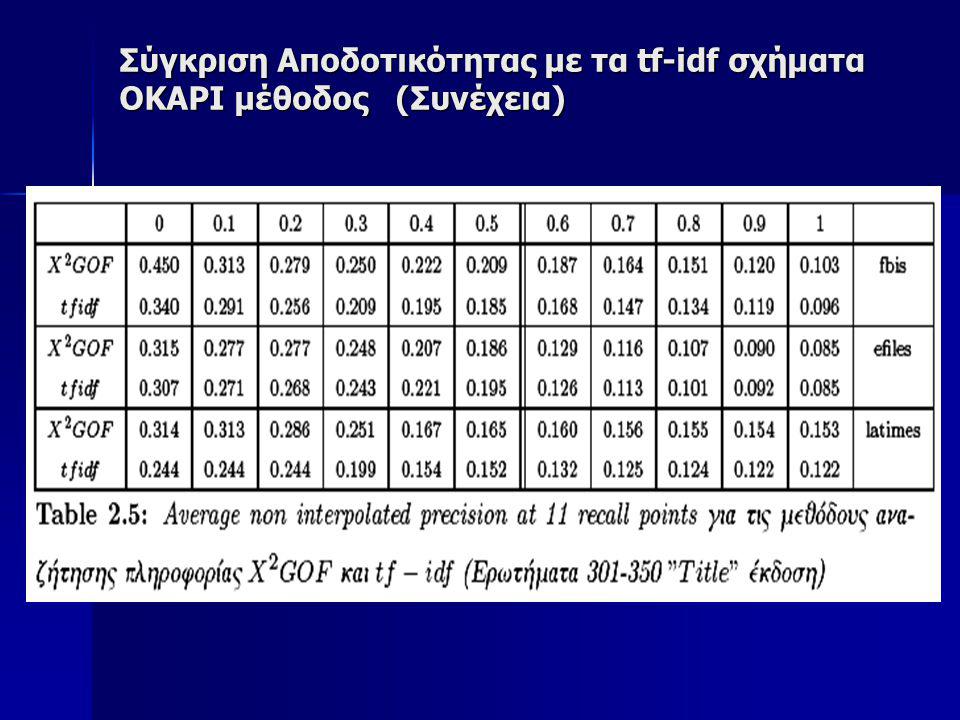
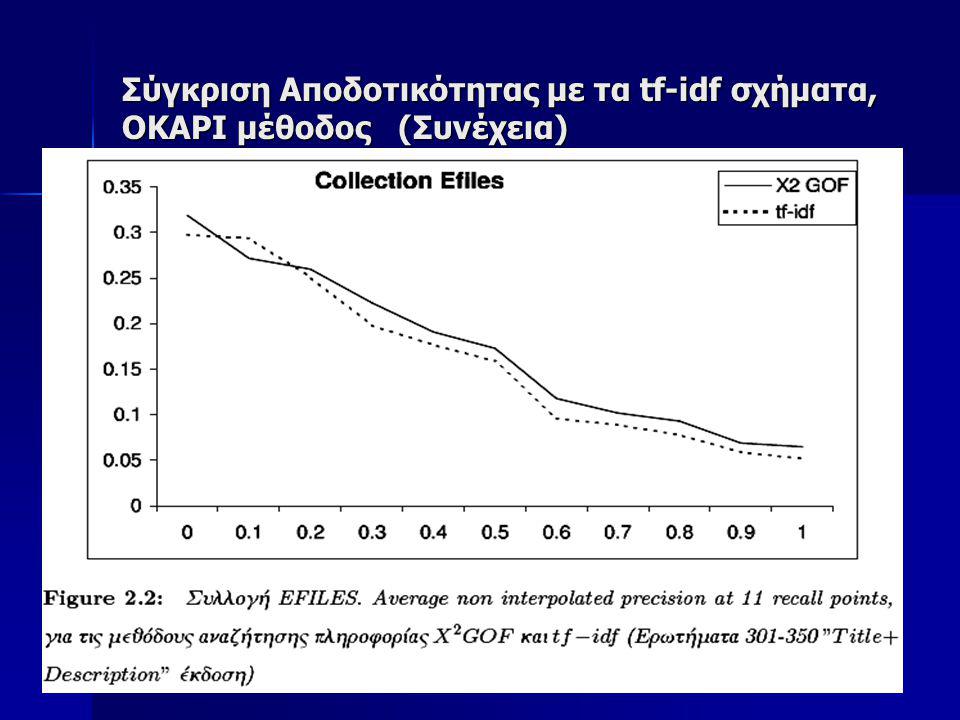
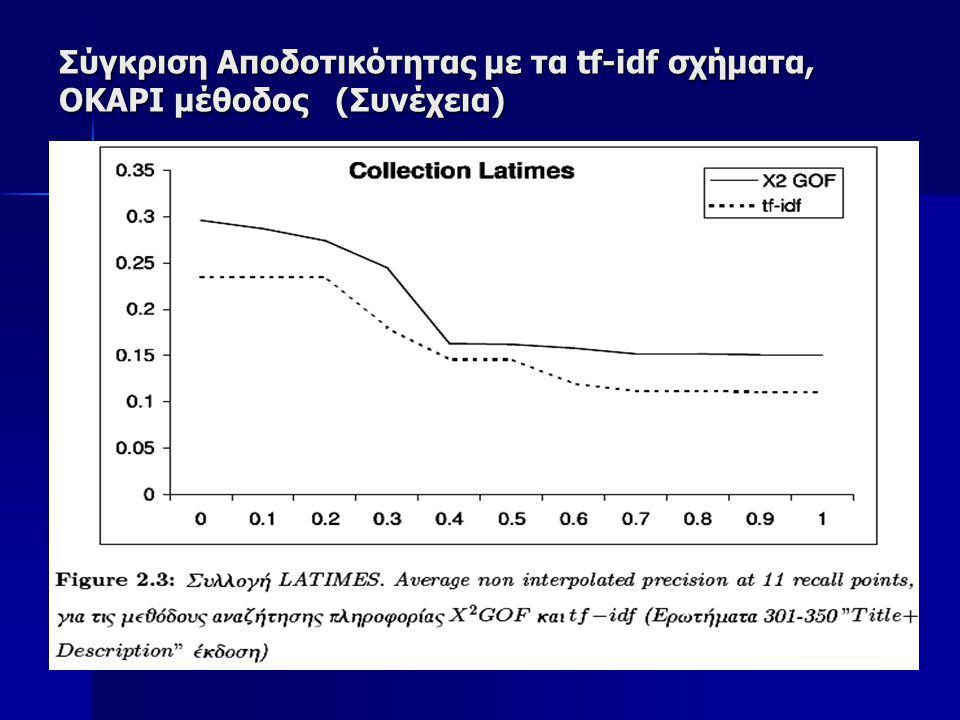
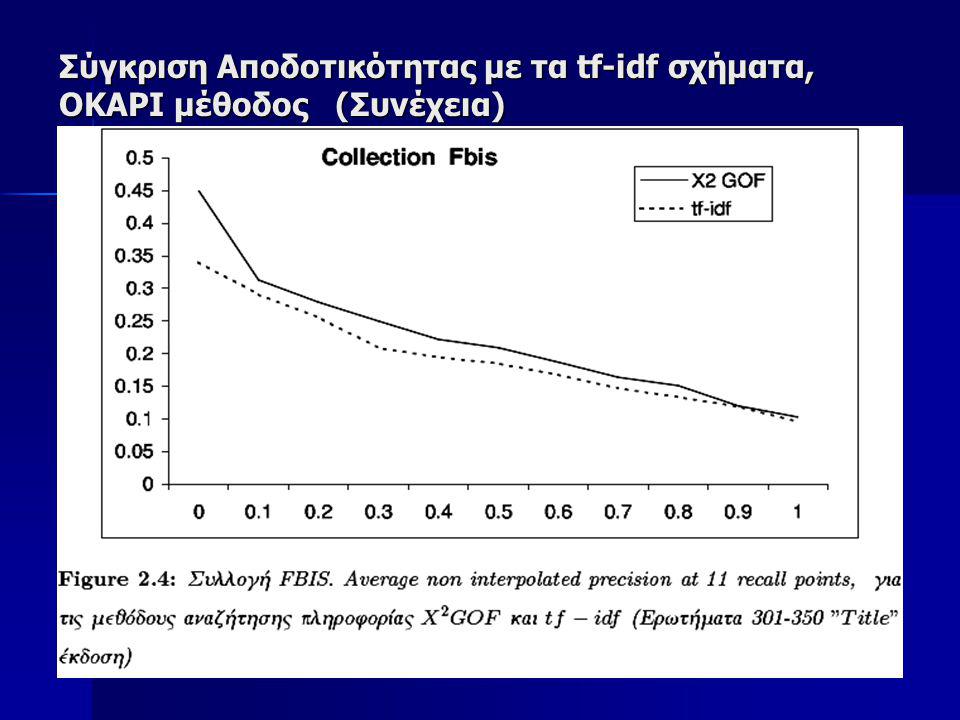
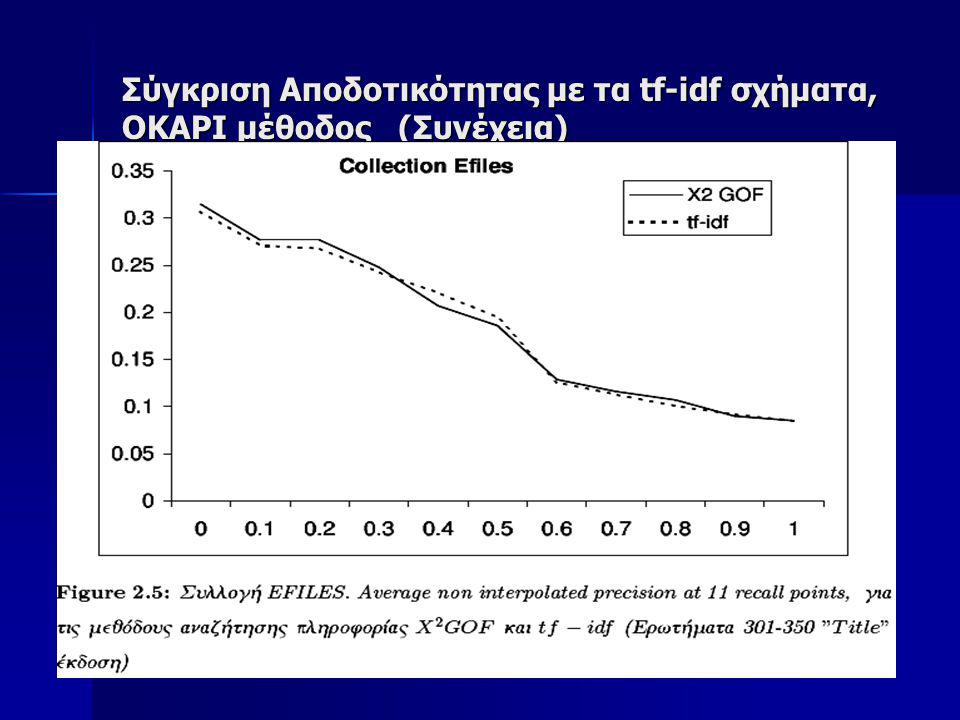
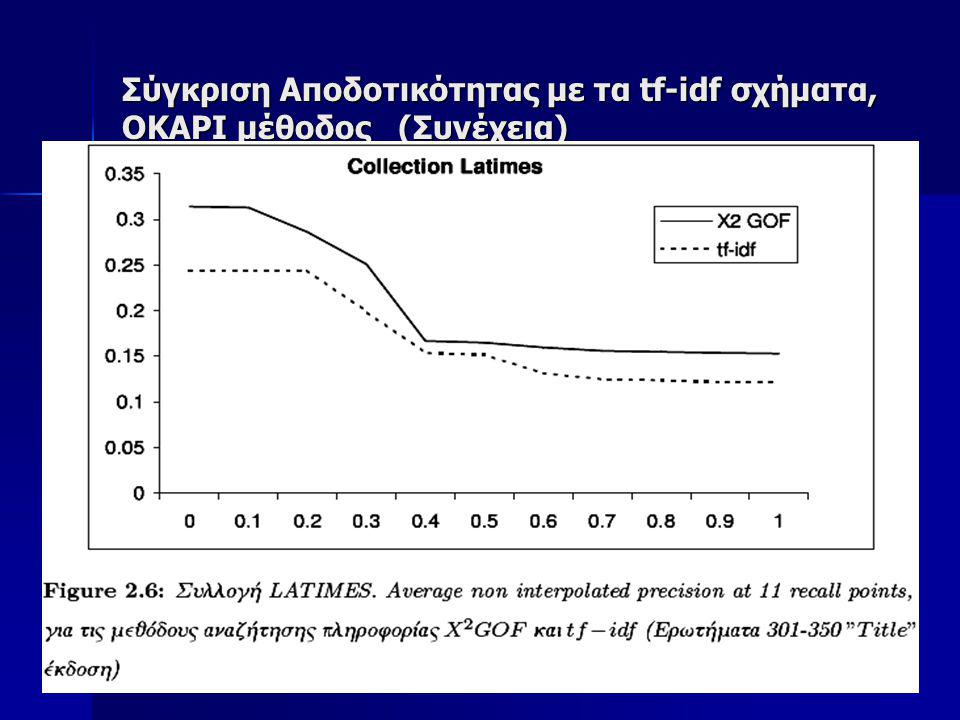
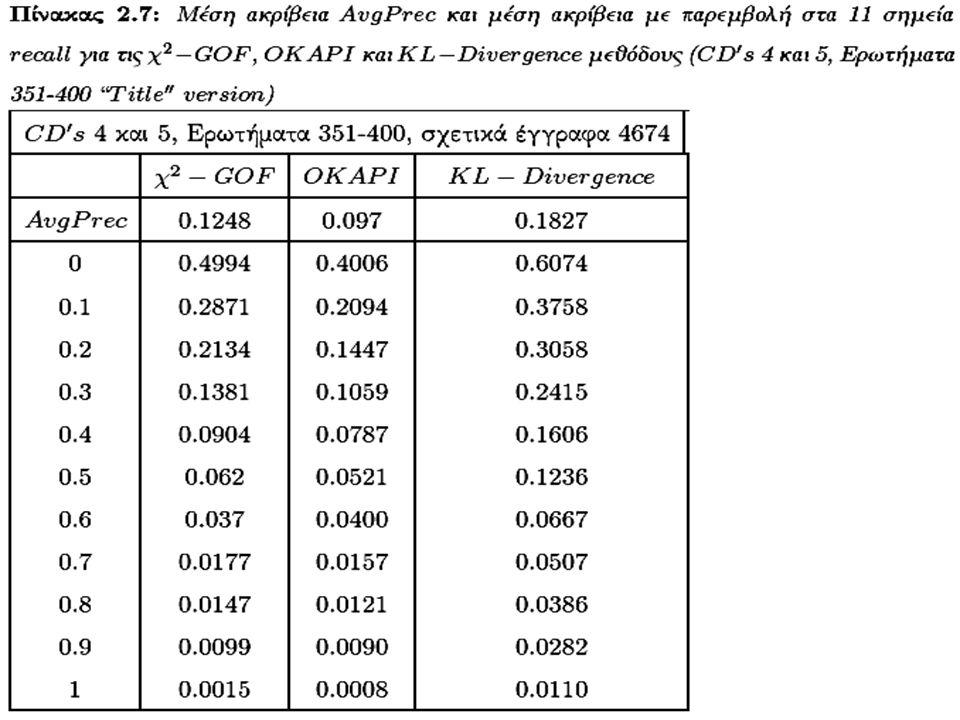
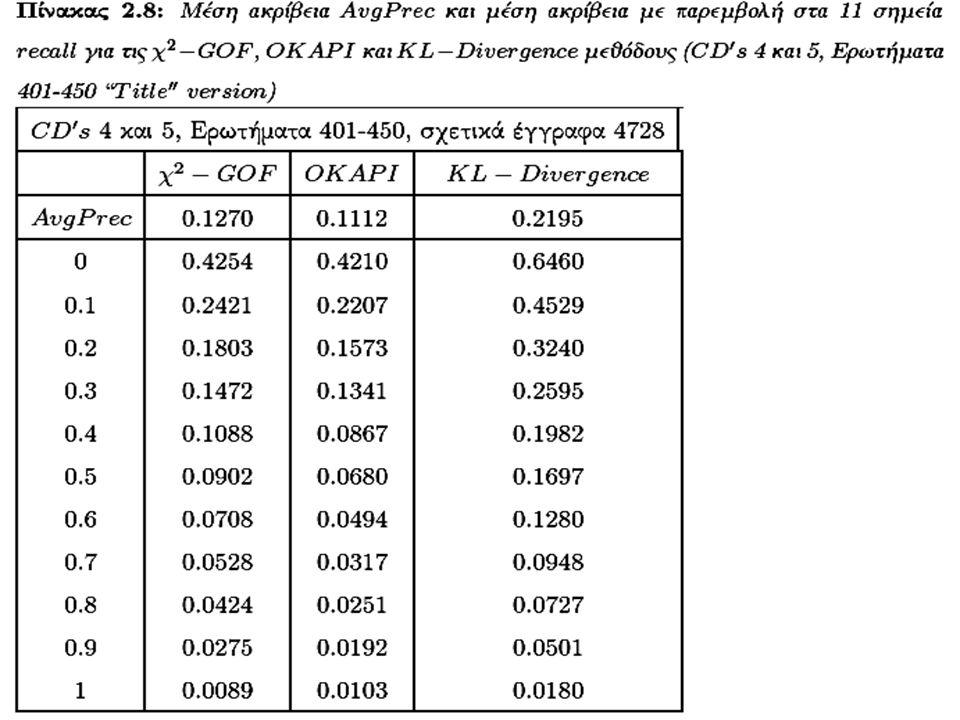

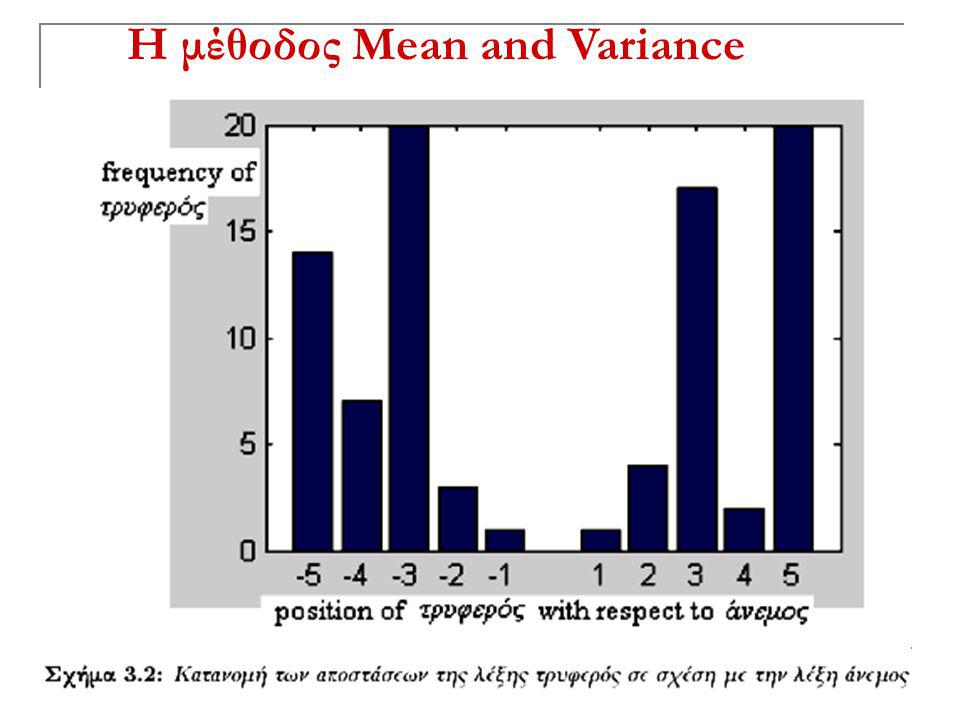
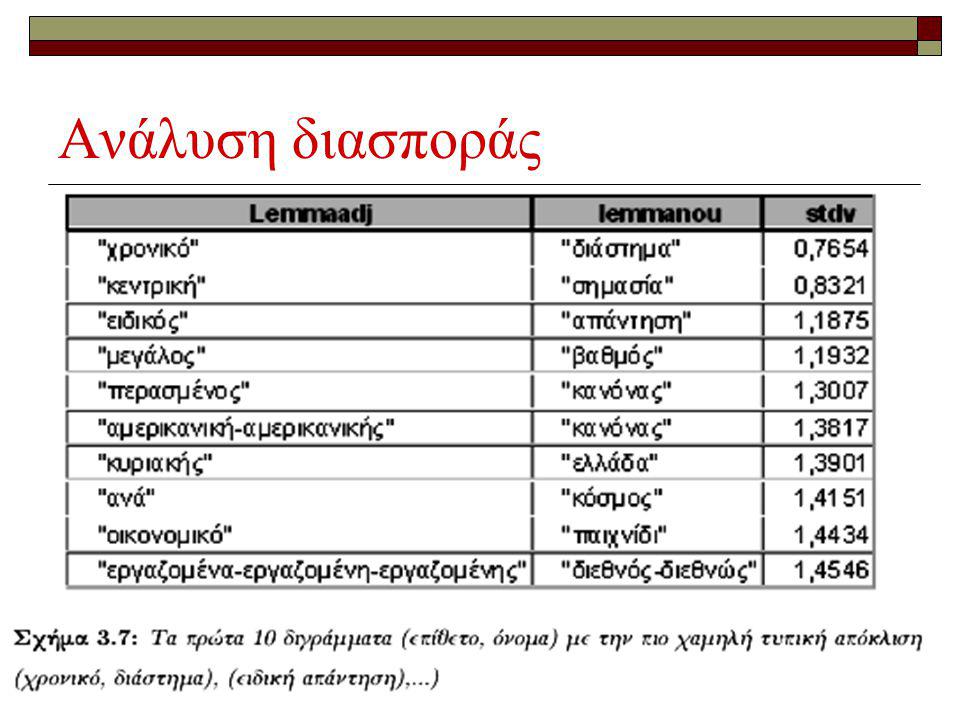
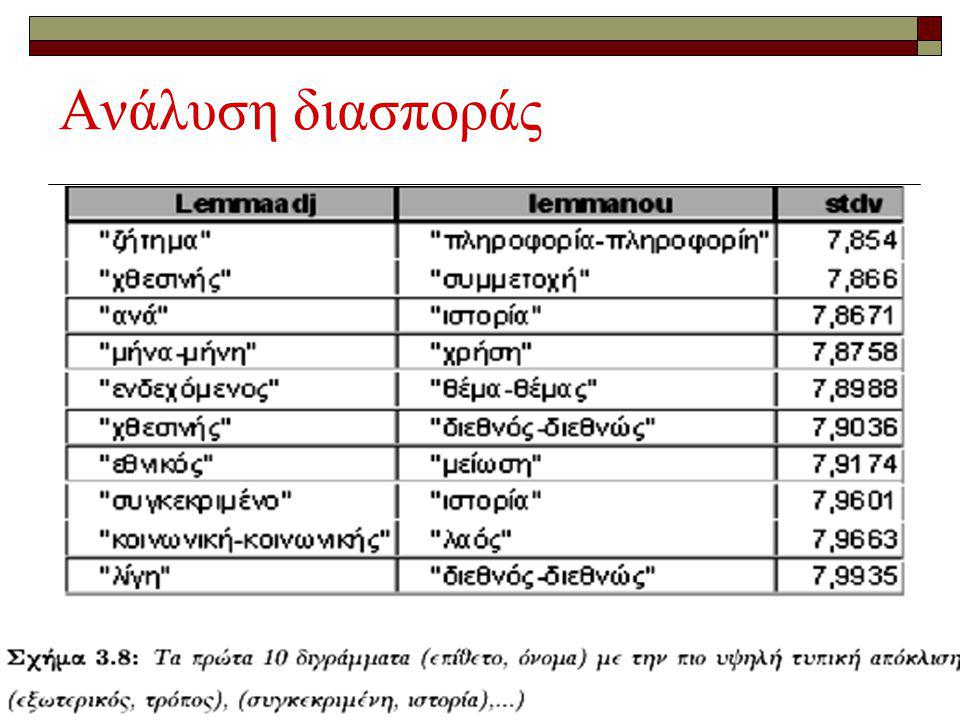


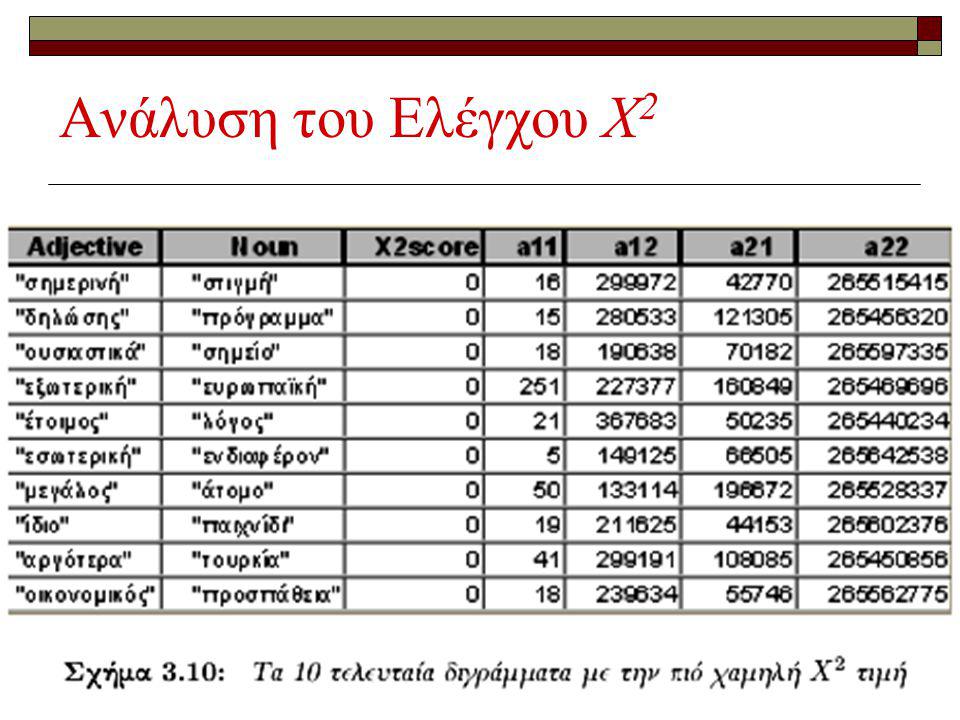
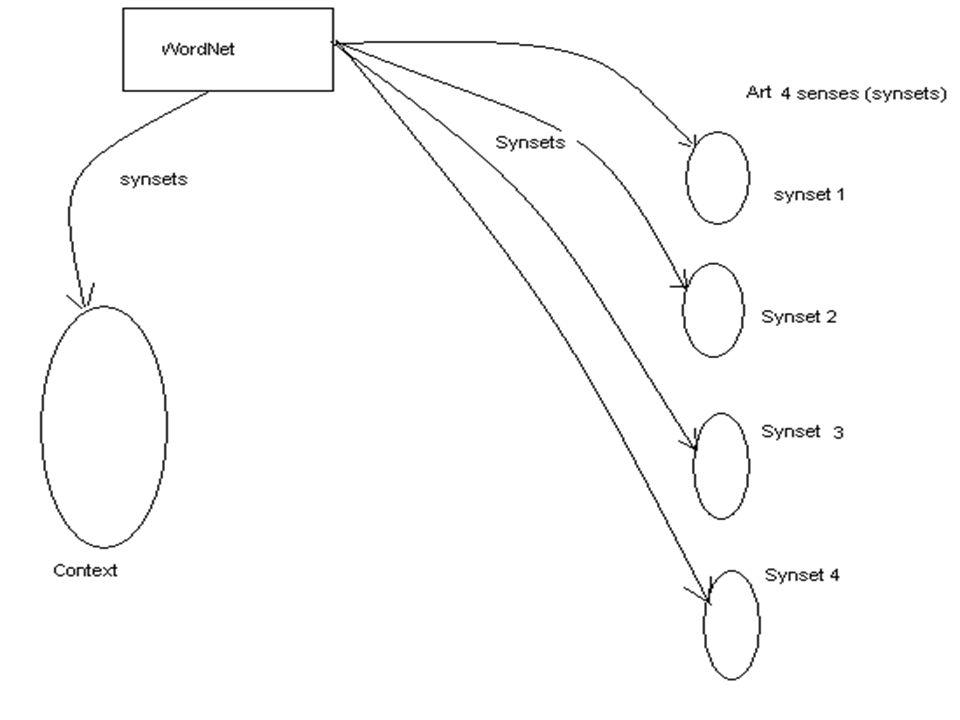


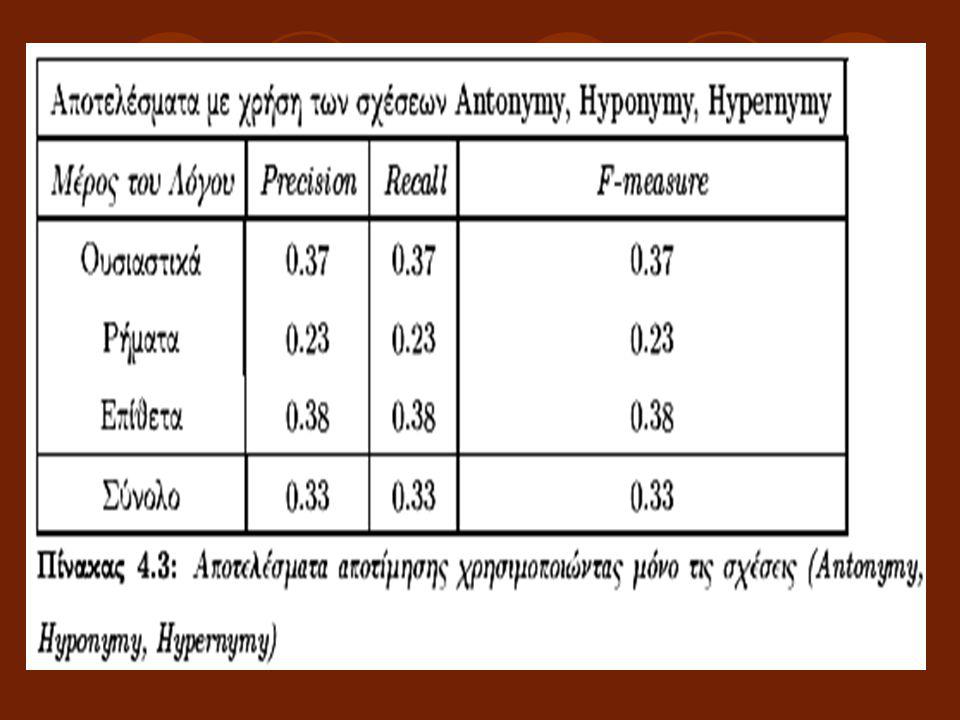
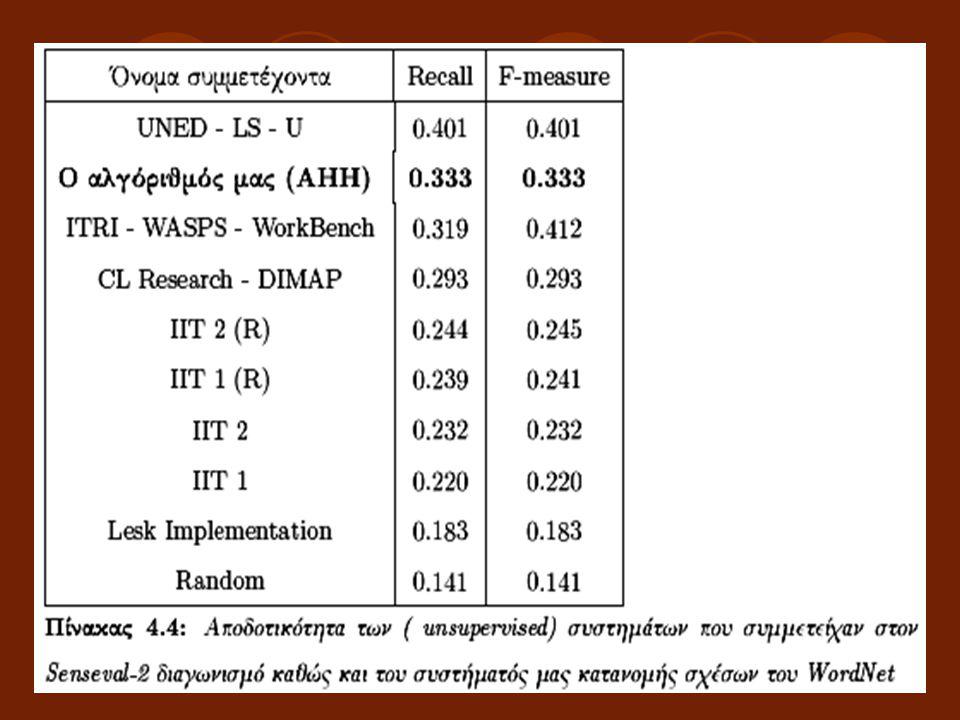






 Γιαννάκης Παναγιώτης (Α.Μ. 181)>")









 1 Τυχαία συνάρτηση Μία τυχαία συνάρτηση (ΤΣ) είναι ένας κανόνας με τον οποίο σε κάθε αποτέλεσμα ζ.>")


 Πανεπιστήμιο Θεσσαλίας Πολυτεχνική Σχολή Τμήμα Μηχ. Η/Υ, Τηλ/νιών & Δικτύων Ακαδημαϊκό Έτος 2005-2006.>")