Κατέβασμα παρουσίασης
1
Ανάκτηση Πληροφορίας Φροντιστήριο 8 Καφέζα Ευανθία Δεκέμβριος 2011

2
Περιεχόμενα Εξατομίκευση Μηχανών Αναζήτησης

3
Εναλλακτικά Πιθανοτικά Μοντέλα

4
Πιθανοτικά Μοντέλα Δυο μοντέλα Bayesian Network Inference Network
Belief Network Inference network: παρέχει μια θεωρητική βάση για την μηχανή ανάκτησης σε ένα σύστημα (inquery system). Έτσι οδηγηθήκαμε στη χρήση των bayesian networks με συστήματα ανάκτησης δεδομένων Belief network: γενικεύει το πρώτο
. Έτσι οδηγηθήκαμε στη χρήση των bayesian networks με συστήματα ανάκτησης δεδομένων. Belief network: γενικεύει το πρώτο.")
5
Bayesian Networks Χρησιμοποιούν διαφορετικές πηγές πληροφορίας για να αποδείξουν κάτι: Παλιές ερωτήσεις Διαφορετικές μορφές δεικτοδότησης Ένα Bayesian Network είναι ένας κατευθυνόμενος γράφος χωρίς κύκλους (DAG) όπου οι κόμβοι είναι τυχαίες μεταβλητές , οι ακμές δηλώνουν συσχέτιση μεταξύ των μεταβλητών, και η ισχύς μίας συσχέτισης δηλώνεται με υπό συνθήκη πιθανότητες. Τα bayesian networks (DAG) είναι κατευθυνόμενοι άκυκλοι γράφοι όπου οι κόμβοι αναπαριστούν τυχαίες μεταβλητές. Οι ακμές απεικονίζουν τη σχέση μεταξύ μεταβλητών και η ισχύς των σχέσεων αυτών εκφράζεται με υπο συνθήκη πιθανότητες
 όπου οι κόμβοι είναι τυχαίες μεταβλητές , οι ακμές δηλώνουν συσχέτιση μεταξύ των μεταβλητών, και η ισχύς μίας συσχέτισης δηλώνεται με υπό συνθήκη πιθανότητες. Τα bayesian networks (DAG) είναι κατευθυνόμενοι άκυκλοι γράφοι όπου οι κόμβοι αναπαριστούν τυχαίες μεταβλητές. Οι ακμές απεικονίζουν τη σχέση μεταξύ μεταβλητών και η ισχύς των σχέσεων αυτών εκφράζεται με υπο συνθήκη πιθανότητες.")
6
Bayesian Networks Βασικά αξιώματα: 0 < P(A) < 1 ; P(sure)=1;
P(A V B)=P(A)+P(B) αν τα A και B είναι αμοιβαία αποκλειόμενα Οι γονείς ενός κόμβου είναι αυτοί που κρίνεται πως το έχουν άμεσα προκαλέσει. Αυτή η σχέση φαίνεται στο δίκτυο από ένα Link από το γονέα στο παιδί.
=P(A)+P(B) αν τα A και B είναι αμοιβαία αποκλειόμενα. Οι γονείς ενός κόμβου είναι αυτοί που κρίνεται πως το έχουν άμεσα προκαλέσει. Αυτή η σχέση φαίνεται στο δίκτυο από ένα Link από το γονέα στο παιδί.")
7
Bayesian Networks • yi : parent nodes • x : child node
• To yi προκαλεί το x • Y σύνολο γονέων του x • Η επίδραση του Y στο x εκφράζεται με τη σχέση F(x,Y) έτσι ώστε Σ F(x,Y) = 1 0 < F(x,Y) < 1 για κάθε χ • Για παράδειγμα, F(x,Y)=P(x|Y) Έστω Xi ο κόμβος του δικτύου G και Γxi το σύνολο των γονέων του xi. Η επιρροή του Γxi στο xi δίνεται από κάθε σύνολο συναρτήσεων Fi(xi, Γxi) που ικανοποιούν το Σ Fi(xi, Γxi) = 1 για κάθε xi Και 0<=Fi(xi,Γxi)<=1
 έτσι ώστε Σ F(x,Y) = 1. 0 < F(x,Y) < 1 για κάθε χ. • Για παράδειγμα, F(x,Y)=P(x|Y) Έστω Xi ο κόμβος του δικτύου G και Γxi το σύνολο των γονέων του xi. Η επιρροή του Γxi στο xi δίνεται από κάθε σύνολο συναρτήσεων Fi(xi, Γxi) που ικανοποιούν το. Σ Fi(xi, Γxi) = 1 για κάθε xi. Και. 0<=Fi(xi,Γxi)<=1.")
8
Bayesian Networks P(X1, X2, X3, X4, X5) = P(X1)P(X2|X1)P(X3|X1)P(X4|X2,X3)P(X5|X3), Όπου Ρ(Χ1) η αρχική πιθανότητα του αρχικού κόμβου του δικτύου και μπορεί να χρησιμοποιηθεί για την διαμόρφωση της γνώσης πάνω στη σημασιολογία της εφαρμογής. Από τις εξαρτήσεις του Bayesian Network, η κοινή πιθανότητα μπορεί να υπολογιστεί ως γινόμενο τοπικών υπό συνθήκη πιθανοτήτων. Όπου Ρ(Χ1) η αρχική πιθανότητα του αρχικού κόμβου του δικτύου και μπορει να χρησιμοποιηθεί για την διαμόρφωση τησ γνώσης πάνω στη σημασιολογία της εφαρμογής. P(A|K) πιθανότητα του A αν ισχύει το K
 η αρχική πιθανότητα του αρχικού κόμβου του δικτύου και μπορεί να χρησιμοποιηθεί για την διαμόρφωση της γνώσης πάνω στη σημασιολογία της εφαρμογής. Από τις εξαρτήσεις του. Bayesian Network, η κοινή. πιθανότητα μπορεί να υπολογιστεί. ως γινόμενο τοπικών υπό συνθήκη. πιθανοτήτων. Όπου Ρ(Χ1) η αρχική πιθανότητα του αρχικού κόμβου του δικτύου και μπορει να χρησιμοποιηθεί για την διαμόρφωση τησ γνώσης πάνω στη σημασιολογία της εφαρμογής. P(A|K) πιθανότητα του A αν ισχύει το K.")
9
Bayesian Networks Σε ένα Bayesian Network κάθε
τυχαία μεταβλητή x είναι υπό συνθήκη ανεξάρτητη από τους μη απογόνους Για παράδειγμα: P(Χ4, Χ5| Χ2 , Χ3)= P(Χ4| Χ2 , Χ3)P( Χ5| Χ3)
= P(Χ4| Χ2 , Χ3)P( Χ5| Χ3)")
10
Παράδειγμα Bayesian Network

11
Inference Network Model
Επιστημολογική αντιμετώπιση του προβλήματος ανάκτησης πληροφορίας Τυχαίες μεταβλητές που σχετίζονται με κείμενα, index terms και ερωτήματα των χρηστών Μία τυχαία μεταβλητή που σχετίζεται με το κείμενο dj δηλώνει το γεγονός να παρατηρήσουμε αυτό το κείμενο Έτσι η παρατήρηση ενός κειμένου είναι η αιτία για την αύξηση της πίστης στις μεταβλητές που σχετίζονται με τους index terms του

12
Inference Network Model
dj k 2 ki 1 kt ……… . q I or and Κόμβοι documents (dj) index terms (ki) queries (q, q1, και q2) ανάγκη πληροφορίας (I) Ακμές από dj σε index term nodes ki δηλώνουν ότι η παρατήρηση του dj αυξάνει την πίστη μας για τις μεταβλητές ki Οι index term και document μεταβλητές αναπαρίστανται σαν κόμβοι στο δίκτυο. Οι ακμές είναι κατευθυνόμενες από το κείμενο προς τους Index terms του ώστε να δηλώνουν πως η παρατήρηση του κειμένου αποφέρει βελτιωμένη πίστη στους Index terms του.
 index terms (ki) queries (q, q1, και q2) ανάγκη πληροφορίας (I) Ακμές. από dj σε index term nodes ki. δηλώνουν ότι η παρατήρηση του dj αυξάνει την πίστη μας για τις μεταβλητές ki. Οι index term και document μεταβλητές αναπαρίστανται σαν κόμβοι στο δίκτυο. Οι ακμές είναι κατευθυνόμενες από το κείμενο προς τους Index terms του ώστε να δηλώνουν πως η παρατήρηση του κειμένου αποφέρει βελτιωμένη πίστη στους Index terms του.")
13
Inference Network Model
dj έχει k2, ki, και kt • q έχει k1, k2, και ki • q1=((k1 ^ k2) v ki) • I = (q v q1) Η τυχαία μεταβλητή σχετίζεται με το ερώτημα ενός χρήστη καθορίζει πως η αιτούμενη πληροφορία έχει παρουσιαστεί. είναι κόμβος και η πίστη σε αυτή είναι μια συνάρτηση για την πίστη στους κόμβους που σχετίζονται με τους όρους του ερωτήματος. Η τυχαία μεταβλητή που σχετίζεται με το ερώτημα ενός χρήστη καθορίζει πως η αιτούμενη πληροφορία έχει παρουσιαστεί. Έτσι η τυχαία αυτή μεταβλητή είναι επίσης κόμβος και η πίστη σε αυτή είναι μια συνάρτηση για την πίστη στους κόμβους που σχετίζονται με τους όρους του ερωτήματος.
 v ki) • I = (q v q1) Η τυχαία μεταβλητή. σχετίζεται με το ερώτημα ενός χρήστη καθορίζει πως η αιτούμενη πληροφορία έχει παρουσιαστεί. είναι κόμβος και η πίστη σε αυτή είναι μια συνάρτηση για την πίστη στους κόμβους που σχετίζονται με τους όρους του ερωτήματος. Η τυχαία μεταβλητή που σχετίζεται με το ερώτημα ενός χρήστη καθορίζει πως η αιτούμενη πληροφορία έχει παρουσιαστεί. Έτσι η τυχαία αυτή μεταβλητή είναι επίσης κόμβος και η πίστη σε αυτή είναι μια συνάρτηση για την πίστη στους κόμβους που σχετίζονται με τους όρους του ερωτήματος.")
14
Inference Network Model
k1, dj,, και q τυχαίες μεταβλητές. k=(k1, k2, ...,kt) διάνυσμα με t διαστάσεις ki,i{0, 1}, τότε k έχει 2t δυνατές καταστάσεις dj,j{0, 1}; q{0, 1} Ο βαθμός ενός κειμένου dj υπολογίζεται ως P(q dj) Ο βαθμός ενός κειμένου σύμφωνα με το ερώτημα είναι ένα μέτρο του κατά πόσο παρέχει υποστήριξη η παρατήρηση του κειμένου στο ερώτημα αυτό.
 διάνυσμα με t διαστάσεις. ki,i{0, 1}, τότε k έχει 2t δυνατές καταστάσεις. dj,j{0, 1}; q{0, 1} Ο βαθμός ενός κειμένου dj υπολογίζεται ως P(q dj) Ο βαθμός ενός κειμένου σύμφωνα με το ερώτημα είναι ένα μέτρο του κατά πόσο παρέχει υποστήριξη η παρατήρηση του κειμένου στο ερώτημα αυτό.")
15
Inference Network Model
P(q dj)= k P(q dj| k) P(k) = k P(q dj k) = k P(q | dj k) P(dj k) = k P(q | k) P(k | dj ) P( dj ) P(¬(q dj)) = 1 - P(q dj) Η αμεσότητα ενός κόμβου dj χωρίζει τα παιδιά του (Index terms) ki κάνοντας τα ανεξάρτητα. Έτσι η πίστη σε κάθε κόμβο ενός index term μπορεί να υπολογιστεί μεμονωμένα για ένα συγκεκριμένο dj. Η αμεσότητα ενός κόμβου dj χωρίζει τα παιδιά του (Index terms) ki κάνοντας τα ανεξάρτητα. η πίστη σε κάθε κόμβο ενός index term μπορεί να υπολογιστεί μεμονωμένα για ένα συγκεκριμένο dj.
= k P(q dj| k) P(k) = k P(q dj k) = k P(q | dj k) P(dj k) = k P(q | k) P(k | dj ) P( dj ) P(¬(q dj)) = 1 - P(q dj) Η αμεσότητα ενός κόμβου dj χωρίζει τα παιδιά του (Index terms) ki κάνοντας τα ανεξάρτητα. Έτσι η πίστη σε κάθε κόμβο ενός index term μπορεί να υπολογιστεί μεμονωμένα για ένα συγκεκριμένο dj. Η αμεσότητα ενός κόμβου dj χωρίζει τα παιδιά του (Index terms) ki κάνοντας τα ανεξάρτητα. η πίστη σε κάθε κόμβο ενός index term μπορεί να υπολογιστεί μεμονωμένα για ένα συγκεκριμένο dj.")
16
Inference Network Model
Η εκ των προτέρων πιθανότητα P(dj) δείχνει πόσο πιθανό είναι να παρατηρήσουμε ένα κείμενο dj Υπολογισμός: Ενιαία για N κείμενα P(dj) = 1/N P(¬dj) = 1 - 1/N Βάσει της νόρμας του διανύσματος dj P(dj)= 1/|dj| P(¬dj) = 1 - 1/|dj|
 δείχνει πόσο πιθανό είναι να παρατηρήσουμε ένα κείμενο dj. Υπολογισμός: Ενιαία για N κείμενα. P(dj) = 1/N. P(¬dj) = 1 - 1/N. Βάσει της νόρμας του διανύσματος dj. P(dj)= 1/|dj| P(¬dj) = 1 - 1/|dj|")
17
Inference Network Model
Για το Boolean Model P(dj) = 1/N P(ki | dj) = 1 αν gi(dj)=1 ή P(ki | dj) = 0 αλλιώς P(¬ki | dj) = 1 - P(ki | dj) μόνο οι κόμβοι που συνδέονται με τα index terms του κειμένου dj ενεργοποιούνται
 = 1/N. P(ki | dj) = 1 αν gi(dj)=1. ή. P(ki | dj) = 0 αλλιώς. P(¬ki | dj) = 1 - P(ki | dj) μόνο οι κόμβοι που συνδέονται με τα index terms του κειμένου dj ενεργοποιούνται.")
18
Belief Network Model Όπως και στο Inference Network Model
Επιστημολογική προσέγγιση Τυχαίες μεταβλητές αντιστοιχούν σε κείμενα, index terms και ερωτήματα Αντίθετα με το Inference Network Model Καλά ορισμένος δειγματοχώρος Συνολοθεωρητική άποψη Διαφορετική τοπολογία δικτύου

19
Belief Network Model Ο Χώρος Πιθανοτήτων Ορισμός:
K={k1, k2, ...,kt} ο δειγματοχώρος (χώρος εννοιών) u ένα υποσύνολο του K (μία έννοια) ki ένας index term (μία στοιχειώδης έννοια) k=(k1, k2, ...,kt) ένα διάνυσμα που συνδέεται με κάθε u ki μία δυαδική τυχαία μεταβλητή που συνδέεται με ένα index term ki
 u ένα υποσύνολο του K (μία έννοια) ki ένας index term (μία στοιχειώδης έννοια) k=(k1, k2, ...,kt) ένα διάνυσμα που συνδέεται με κάθε u. ki μία δυαδική τυχαία μεταβλητή που συνδέεται με ένα index term ki.")
20
Belief Network Model Συνολοθεωρητική Προσέγγιση Ορισμοί:
ένα κείμενο dj και μία ερώτηση q ως έννοιες στο K μία γενική έννοια c στο K μία κατανομή πιθανότητας P στο K P(c)= uP(c|u) P(u) P(u)=(1/2)t Το P(c) είναι ο βαθμός κάλυψης του χώρου K από το c
= uP(c|u) P(u) P(u)=(1/2)t. Το P(c) είναι ο βαθμός κάλυψης του χώρου K από το c.")
21
Belief Network Model query side document side

22
Belief Network Model Υπόθεση
P(dj|q) είναι ο βαθμός σχετικότητας του κειμένου dj ως προς το ερώτημα q. Δείχνει το βαθμό κάλυψης στην έννοια dj από την έννοια q.
 είναι ο βαθμός σχετικότητας του κειμένου dj ως προς το ερώτημα q. Δείχνει το βαθμό κάλυψης στην έννοια dj από την έννοια q.")
23
Belief Network Model Σύγκριση
Inference Network Model το πρώτο που εμφανίστηκε Belief Network συνολοθεωρητική άποψη Belief Network καθορισμένος δειγματοχώρος Belief Network διαχωρισμός στοιχείων ερωτήματος και στοιχείων κειμένου Belief Network αναπαράγει κάθε βαθμολόγηση που παράγει το Inference Network ενώ το αντίθετο δεν ισχύει

24
Belief Network Model Υπολογιστικό Κόστος
Το Inference Network Model επεξεργάζεται ένα κείμενο τη φορά, και το κόστος επεξεργασίας είναι γραμμικό ως προς τον αριθμό των κειμένων Στο Belief Network, επεξεργάζονται μόνο οι καταστάσεις που ενεργοποιούν τα query terms Επειδή στα δίκτυα αυτά δεν υπάρχουν κύκλοι δεν έχουμε άλλο υπολογιστικό κόστος

25
Εξατομίκευση Μηχανών Αναζήτησης

26
Εισαγωγή Εξατομίκευση : Προσαρμογή της σελίδας ή των αποτελεσμάτων που μας εμφανίζει μια μηχανή αναζήτησης με βάση την προηγούμενη συμπεριφορά του χρήστη. Καταγράφονται οι προηγούμενες ενέργειες του χρήστη και στη συνέχεια χρησιμοποιούνται για να προσαρμοστούν τα δεδομένα που του εμφανίζονται.

27
Εισαγωγή Εξατομίκευση Μηχανών Αναζήτησης : Καταγράφουμε τα ερωτήματα που κάνει ο χρήστης και τα αποτελέσματα που επιλέγει και με βάση αυτά προσαρμόζουμε τα αποτελέσματα που του εμφανίζουμε στα επόμενα ερωτήματα. Η διαδικασία αυτή περιλαμβάνει μια σειρά από βήματα στα οποία ξεχωρίζουν η καταγραφή της συμπεριφοράς του χρήστη και ο αλγόριθμος εξατομίκευσης.

28
Καταγραφή Συμπεριφοράς
Καταγραφή συμπεριφοράς του χρήστη : Σημαίνει ότι ο χρήστης καθώς πλοηγείται και βλέπει αποτελέσματα υπάρχει ένα σύστημα προσαρμοσμένο που καταγράφει όλες τις λειτουργίες που έχει κάνει. Λειτουργίες Που έχει κάνει ? 1. Ποια ερωτήματα έκανε. 2. Ποια αποτελέσματα διάλεξε. 3. Με ποια σειρά τα διάλεξε και τι σειρά είχαν στην μηχανή αναζήτησης. 4. Κτλ.

29
Καταγραφή Συμπεριφοράς
Πως μπορεί να καταγραφεί η συμπεριφορά του χρήστη? Με ένα πρόσθετο στον Internet Explorer ή στο Firefox. Με τον τρόπο αυτό μπορούμε καθώς πλοηγούμαστε να καταγράφεται συμπεριφορά μας χωρίς να χρειάζεται να αλλάξουμε κάτι στον τρόπο που λειτουργούμε. 2. Κατασκευάζοντας εφαρμογή που χρησιμοποιεί το Google API και υλοποιώντας από πίσω ένα σύστημα που καταγράφει τι έκανε ο χρήστης.

30
Πρόσθετο στον Internet Explorer ή Firefox
Κατασκευή συστήματος εξατομίκευσης που αποτελείται από δυο βασικές εφαρμογές, την εφαρμογή του χρήστη και την εφαρμογή του εξυπηρετητή. Η εφαρμογή του χρήστη είναι αρμόδια για την καταγραφή της συμπεριφοράς του χρήστη και την εμφάνιση της νέας κατάταξης των αποτελεσμάτων για ένα ερώτημα. Η εφαρμογή του εξυπηρετητή αποθηκεύει την συμπεριφορά κάθε χρήστη, κατασκευάζει το εξατομικευμένο δένδρο της συμπεριφοράς (υλοποιώντας τους αλγορίθμους εξατομίκευσης) και υπολογίζει την καινούργια κατάταξη των αποτελεσμάτων μιας ερώτησης.
 και υπολογίζει την καινούργια κατάταξη των αποτελεσμάτων μιας ερώτησης.")
31
Πρόσθετο στον Internet Explorer ή Firefox
Κάθε φορά που ο χρήστης επιθυμεί να κάνει εξατομίκευση σε μια ερώτηση, δηλαδή να δει τα εξατομικευμένα αποτελέσματα της ερώτησης που βρίσκεται, η εφαρμογή του χρήστη επικοινωνεί με την εφαρμογή του εξυπηρετητή και ζητάει την νέα εξατομικευμένη κατάταξη των αποτελεσμάτων της ερώτησης. Στην συνέχεια η εφαρμογή του χρήστη αλλάζει την σειρά των αποτελεσμάτων και την εμφανίζει σύμφωνα με τη σειρά που στάλθηκε από τον εξυπηρετητή.

32
Πρόσθετο στον Internet Explorer ή Firefox
Η εφαρμογή του εξυπηρετητή υλοποιείται από ένα Web Service που καλείται από την εφαρμογή του χρήστη και υλοποιεί τις λειτουργίες που περιγράψαμε παραπάνω.

33
Κατασκευάζοντας εφαρμογή που χρησιμοποιεί το Google API
Κατασκευή εφαρμογής που συνδέεται στο Google API και κάνει ερωτήματα σε αυτό. Το Google API μας επιστρέφει τα αποτελέσματα για το ερώτημα που κάναμε και εμείς τα εμφανίζουμε. Καθώς ο χρήστης πλοηγείται στην εφαρμογή μας καταγράφουμε τα αποτελέσματα που επιλέγει και στην συνέχεια τα αποθηκεύουμε. Δίνουμε στον χρήστη την δυνατότητα να εξατομικεύσει τα αποτελέσματά του χρησιμοποιώντας κάποιον από τους αλγόριθμους εξατομίκευσης.

34
Αλγόριθμοι Εξατομίκευσης
Οι αλγόριθμοι εξατομίκευσης προσπαθούν να εκμεταλλευθούν τα χαρακτηριστικά της πληροφορίας που έχουμε ασχοληθεί σε προηγούμενες ερωτήσεις για να προβλέψουν κατά κάποιο τρόπο τι θα μας ενδιαφέρει στις επόμενες ερωτήσεις. Ένα πολύ σημαντικό στοιχείο που μπορούμε να εξάγουμε από προηγούμενες ερωτήσεις είναι η κατηγορία της σελίδας που διάλεξε πιο πριν ο χρήστης. Πως γίνεται αυτό? Χρησιμοποιώντας το Open Directory Project(ODP).
.")
35
Αλγόριθμοι Εξατομίκευσης - ODP
Ένα κομμάτι των σελίδων έχουν κατηγοριοποιηθεί σε κατηγορίες που προσδιορίζουν το περιεχόμενό τους. Το ODP είναι ένα γράφος θεματικών κατηγοριών στον οποίο κατατάσσονται οι σελίδες του Ιστού. Οι σελίδες που ανήκουν σε μια κατηγορία χαρακτηρίζονται από την κατηγορία που ανήκουν. Εφόσον ένας χρήστης επιλέξει μια σελίδα από μια κατηγορία, σημαίνει ότι ενδιαφέρεται για το θέμα της σελίδας, συνεπώς πολύ πιθανόν να τον ενδιαφέρουν και οι υπόλοιπες σελίδες της ίδιας κατηγορίας. Μέσω των κατηγοριών που επιλέγει ένας χρήστης μπορούμε να καταλάβουμε σε μεγάλο βαθμό ποιες σελίδες θα τον ενδιαφέρουν και μετά.

36
Αλγόριθμοι Εξατομίκευσης
Η αλγόριθμοι που θα παρουσιάσουμε θα βασίζονται στο ODP. Θεωρούμε ότι για κάθε χρήστη κατασκευάζουμε ένα γράφημα κατηγοριών G(V,E) το οποίο προκύπτει από το γράφο του ODP, στο οποίο με vεV συμβολίζουμε τους κόμβους του γραφήματος, οι οποίοι είναι οι κατηγορίες του ODP που χρησιμοποιούμε, και με (vi, vj)εΕ συμβολίζουμε τις ακμές του γράφου, οι οποίες συμβολίζουν την σχέση που έχουν μεταξύ τους οι κατηγορίες. Σε κάθε ακμή αντιστοιχούμε ένα βάρος d(vi, vj) που δείχνει την σημασιολογική σχέση των κατηγοριών.
 το οποίο προκύπτει από το γράφο του ODP, στο οποίο με vεV συμβολίζουμε τους κόμβους του γραφήματος, οι οποίοι είναι οι κατηγορίες του ODP που χρησιμοποιούμε, και με (vi, vj)εΕ συμβολίζουμε τις ακμές του γράφου, οι οποίες συμβολίζουν την σχέση που έχουν μεταξύ τους οι κατηγορίες. Σε κάθε ακμή αντιστοιχούμε ένα βάρος d(vi, vj) που δείχνει την σημασιολογική σχέση των κατηγοριών.")
37
Αλγόριθμοι Εξατομίκευσης
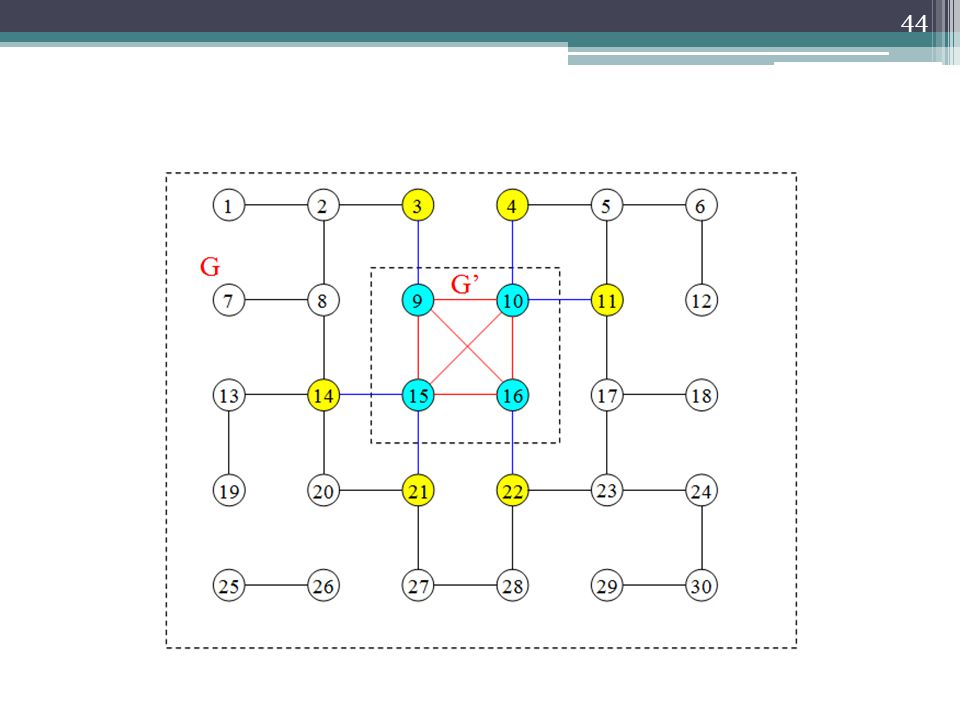
Γενικά, παρουσιάζουμε την ιδέα της δημιουργίας, στην μεριά του χρήστη, ενός γραφήματος που είναι η επέκταση ενός κατάλληλα διαλεγμένου υπό- γραφήματος Guser του G. Ανάλογα με τις προτιμήσεις του χρήστη κάθε κατηγορία v του Guser θα πάρει ένα σχετικό βάρος β(v) > 0. Αυτά τα βάρη θα χρησιμοποιηθούν για την κατηγοριοποίηση των σελίδων που θα επιστραφούν στον χρήστη, όταν αυτός κάνει μια ερώτηση. Επίσης συμβολίζουμε με G’ το τοπικό γράφημα της ερώτησης. Συγκεκριμένα, η θέση μιας σελίδας p στο σύνολο των αποτελεσμάτων μιας ερώτησης θα δίνεται από μια συνάρτηση της μορφής : φ(β(γ(p)),σ(p))
 > 0. Αυτά τα βάρη θα χρησιμοποιηθούν για την κατηγοριοποίηση των σελίδων που θα επιστραφούν στον χρήστη, όταν αυτός κάνει μια ερώτηση. Επίσης συμβολίζουμε με G’ το τοπικό γράφημα της ερώτησης. Συγκεκριμένα, η θέση μιας σελίδας p στο σύνολο των αποτελεσμάτων μιας ερώτησης θα δίνεται από μια συνάρτηση της μορφής : φ(β(γ(p)),σ(p))")
38
Αλγόριθμοι Εξατομίκευσης
Στην παραπάνω συνάρτηση, γ(p) είναι η κατηγορία που ανήκει η σελίδα p, σ(p) είναι η σχετικότητά της σύμφωνα με τον αλγόριθμο βαθμολόγησης της μηχανής, και η συνάρτηση φ() δηλώνει πως η τελική βαθμολόγηση θα διαφοροποιηθεί σε σχέση με την βαθμολόγηση της μηχανής (π.χ. φ(α, β) = (α + β)/2 ). Ουσιαστικά, παρουσιάζουμε την συνάρτηση φ() που συνδυάζει την βαθμολόγηση της μηχανής αναζήτησης και την προτεινόμενη από εμάς βαθμολόγηση με σκοπό να παρέχει καλύτερη κλιμάκωση των αποτελεσμάτων μας.
 είναι η κατηγορία που ανήκει η σελίδα p, σ(p) είναι η σχετικότητά της σύμφωνα με τον αλγόριθμο βαθμολόγησης της μηχανής, και η συνάρτηση φ() δηλώνει πως η τελική βαθμολόγηση θα διαφοροποιηθεί σε σχέση με την βαθμολόγηση της μηχανής (π.χ. φ(α, β) = (α + β)/2 ). Ουσιαστικά, παρουσιάζουμε την συνάρτηση φ() που συνδυάζει την βαθμολόγηση της μηχανής αναζήτησης και την προτεινόμενη από εμάς βαθμολόγηση με σκοπό να παρέχει καλύτερη κλιμάκωση των αποτελεσμάτων μας.")
39
Αλγόριθμοι Εξατομίκευσης
Η μεθοδολογία μας βασίζεται στην ακόλουθη παρατήρηση : σε κάθε διαδικασία, άσχετα με την ερώτηση, οι χρήστες επιλέγουν να επισκέπτονται μόνο κάποια από τα αποτελέσματα που συνήθως δεν ανήκουν στις ίδιες κατηγορίες. Αυτό σημαίνει ότι οι κατηγορίες αυτές έχουν κάποια σχέση για τον συγκεκριμένο χρήστη. O χρήστης θα ήθελε αυτές οι κατηγορίες να σχετίζονται έτσι ώστε να πάρει καλύτερα εξατομικευμένα αποτελέσματα (σε σχέση με το προφίλ του) σε επόμενες ερωτήσεις του.
 σε επόμενες ερωτήσεις του.")
40
Αλγόριθμοι Εξατομίκευσης
Επιπλέον ένας χρήστης μπορεί να θέλει να συσχετίσει μια κατηγορία v, που έχει σταθερή προτίμηση και έχει βάρος β(v), με μια κατηγορία w που έχει μόλις τραβήξει το ενδιαφέρον του. Η παραπάνω συζήτηση δείχνει την ανάγκη για δυο πράγματα : την συσχέτιση μη συσχετισμένων κατηγοριών και την ανάθεση τιμής που να δηλώνει το βαθμό συσχέτισής τους.
, με μια κατηγορία w που έχει μόλις τραβήξει το ενδιαφέρον του. Η παραπάνω συζήτηση δείχνει την ανάγκη για δυο πράγματα : την συσχέτιση μη συσχετισμένων κατηγοριών και την ανάθεση τιμής που να δηλώνει το βαθμό συσχέτισής τους.")
41
Αλγόριθμος βασισμένος στις ακμές του γράφου
Θεωρούμε την εκτέλεση κ πειραμάτων, που είναι περίοδοι πλοήγησης του χρήστη που περιέχουν την εισαγωγή μιας ερώτησης και την πλοήγηση στα ανακτημένα αποτελέσματα. Κατά τη διάρκεια αυτών των πειραμάτων το ιστορικό πλοήγησης του χρήστη ανανεώνεται αυτόματα χωρίς κάποια ενέργεια από τους χρήστες.

42
Αλγόριθμος βασισμένος στις ακμές του γράφου
Για να υπολογίσουμε την εξατομικευμένη κατάταξη των αποτελεσμάτων σε ένα ερώτημα με βάση αυτόν τον αλγόριθμο, υπολογίζουμε το γi(pi), όπου pi είναι το αποτέλεσμα, και γi(pi) είναι η τελική σειρά του αποτελέσματος που εμφανίζεται στο χρήστη. Θεωρούμε ότι το Si είναι το σύνολο των σελίδων του αποτελέσματος και αi(pi) είναι η τιμή της σημαντικότητας που «ανατίθεται» από τον χρήστη στην σελίδα pi της ερώτησης αi.
, όπου pi είναι το αποτέλεσμα, και γi(pi) είναι η τελική σειρά του αποτελέσματος που εμφανίζεται στο χρήστη. Θεωρούμε ότι το Si είναι το σύνολο των σελίδων του αποτελέσματος και αi(pi) είναι η τιμή της σημαντικότητας που «ανατίθεται» από τον χρήστη στην σελίδα pi της ερώτησης αi.")
43
Αλγόριθμος βασισμένος στις ακμές του γράφου
Το αi(pi) θα είναι η σειρά προτίμησης της σελίδας pi από τον χρήστη στην ερώτηση αi. Δηλαδή αν η σελίδα p1 επιλεχθεί πρώτη τότε αi(p1) = 1, αν επιλεγεί δεύτερη τότε αi(p1) = 2, κοκ. Επίσης η τιμή αυτή ανατίθεται αυτόματα κατά την πλοήγηση των σελίδων χωρίς να χρειάζεται να κάνει κάποια ενέργεια ο χρήστης
 θα είναι η σειρά προτίμησης της σελίδας pi από τον χρήστη στην ερώτηση αi. Δηλαδή αν η σελίδα p1 επιλεχθεί πρώτη τότε αi(p1) = 1, αν επιλεγεί δεύτερη τότε αi(p1) = 2, κοκ. Επίσης η τιμή αυτή ανατίθεται αυτόματα κατά την πλοήγηση των σελίδων χωρίς να χρειάζεται να κάνει κάποια ενέργεια ο χρήστης.")
45
Αλγόριθμος βασισμένος στις ακμές του γράφου
Βήμα 1. Εισαγωγή μιας ερώτησης, συλλέγουμε το Si και αφήνουμε τους χρήστες να «καθορίσουν» το αi(pi). Βήμα 2. Για κάθε σελίδα pi των αποτελεσμάτων υπολογίζουμε με βάση την κατηγορία της στο γράφημα, το συντελεστή κατάταξης γi(pi) για αυτήν την σελίδα. Συγκεκριμένα
. Βήμα 2. Για κάθε σελίδα pi των αποτελεσμάτων υπολογίζουμε με βάση την κατηγορία της στο γράφημα, το συντελεστή κατάταξης γi(pi) για αυτήν την σελίδα. Συγκεκριμένα.")
46
Αλγόριθμος βασισμένος στις ακμές του γράφου
results είναι ο αριθμός των αποτελεσμάτων σε κάθε ερώτηση και α(pi) είναι η θέση της σελίδας pi στα αποτελέσματα του Google για την ερώτηση αi. Βήμα 3. Υποθέτουμε ότι v1, v2, …, vl(G’) είναι όλες οι κατηγορίες που σελίδες τους εμφανίζονται στα αποτελέσματα της ερώτησης. Ενώνουμε όλους τους κόμβους αυτούς με ακμές και θέτουμε σε αυτές τις ακμές ένα βάρος w(vi, vj). Το βάρος αυτό προσδιορίζει το πόσο σχετικές είναι οι κατηγορίες αυτές μεταξύ τους.
 είναι η θέση της σελίδας pi στα αποτελέσματα του Google για την ερώτηση αi. Βήμα 3. Υποθέτουμε ότι v1, v2, …, vl(G’) είναι όλες οι κατηγορίες που σελίδες τους εμφανίζονται στα αποτελέσματα της ερώτησης. Ενώνουμε όλους τους κόμβους αυτούς με ακμές και θέτουμε σε αυτές τις ακμές ένα βάρος w(vi, vj). Το βάρος αυτό προσδιορίζει το πόσο σχετικές είναι οι κατηγορίες αυτές μεταξύ τους.")
47
Αλγόριθμος βασισμένος στις ακμές του γράφου
Την παράσταση την λέμε συντελεστή σχετικότητας γιατί προσδιορίζει την σχετικότητα της κατηγορίας του αποτελέσματος με τον χρήστη. Υπολογίζοντας τα γi(pi) βρίσκουμε έναν συντελεστή για κάθε αποτέλεσμα της ερώτησης ταξινομούμε τα αποτελέσματα με βάση αυτούς τους νέους συντελεστές και εμφανίζουμε τα αποτελέσματα με την νέα σειρά.
 βρίσκουμε έναν συντελεστή για κάθε αποτέλεσμα της ερώτησης ταξινομούμε τα αποτελέσματα με βάση αυτούς τους νέους συντελεστές και εμφανίζουμε τα αποτελέσματα με την νέα σειρά.")
48
Αλγόριθμος βασισμένος στις ακμές του γράφου
Ο συντελεστής vother(v(pi)) προκύπτει από τις κατηγορίες που έχει επιλέξει ο χρήστης σε προηγούμενες ερωτήσεις και σχετίζονται άμεσα με τις κατηγορίες(μέσω ακμών) που επιστρέφουν τα αποτελέσματα(δηλ. η κατηγορίες που συνδέουν το G’ με το υπόλοιπο γράφημα). Η πρακτική σημασία των vother(v(pi)) έγκειται στο γεγονός ότι μας δίνουν ένα μέτρο για το πόσο σχετικές είναι οι κατηγορίες της ερώτησης με άλλες κατηγορίες που έχει επιλέξει ο ίδιος χρήστης.
) προκύπτει από τις κατηγορίες που έχει επιλέξει ο χρήστης σε προηγούμενες ερωτήσεις και σχετίζονται άμεσα με τις κατηγορίες(μέσω ακμών) που επιστρέφουν τα αποτελέσματα(δηλ. η κατηγορίες που συνδέουν το G’ με το υπόλοιπο γράφημα). Η πρακτική σημασία των vother(v(pi)) έγκειται στο γεγονός ότι μας δίνουν ένα μέτρο για το πόσο σχετικές είναι οι κατηγορίες της ερώτησης με άλλες κατηγορίες που έχει επιλέξει ο ίδιος χρήστης.")
49
Αλγόριθμος βασισμένος στις ακμές του γράφου
Ο συντελεστής vgraph(v(pi)) προκύπτει με βάση τη σχετικότητα των κατηγοριών των αποτελεσμάτων πριν γίνει η ερώτηση. Το είναι ο συντελεστής που λαμβάνει υπόψη την σειρά κατάταξης των αποτελεσμάτων στο Google. Π.χ. το πρώτο αποτέλεσμα παίρνει συντελεστή 10, το δεύτερο 9, κοκ.
) προκύπτει με βάση τη σχετικότητα των κατηγοριών των αποτελεσμάτων πριν γίνει η ερώτηση. Το είναι ο συντελεστής που λαμβάνει υπόψη την σειρά κατάταξης των αποτελεσμάτων στο Google. Π.χ. το πρώτο αποτέλεσμα παίρνει συντελεστή 10, το δεύτερο 9, κοκ.")
50
Υπολογισμός των βαρών των ακμών
Οι νέες κατηγορίες(κόμβοι) που προστίθενται είναι οι κατηγορίες της ερώτησης που κάνουμε και δεν υπάρχουν ήδη και οι νέες ακμές που θα προστίθενται θα είναι αυτές μεταξύ των κατηγοριών της ερώτησης που δεν υπάρχουν. Τα βάρη των ακμών στο γράφημα θα είναι μεταβλητές που θα μετράνε το πόσες φορές έχουν συσχετιστεί οι δυο κατηγορίες και πόσο, δηλαδή πόσες φορές έχουν βρεθεί οι δυο κατηγορίες στα ίδια αποτελέσματα και πόσο σχετικές ήταν.
 που προστίθενται είναι οι κατηγορίες της ερώτησης που κάνουμε και δεν υπάρχουν ήδη και οι νέες ακμές που θα προστίθενται θα είναι αυτές μεταξύ των κατηγοριών της ερώτησης που δεν υπάρχουν. Τα βάρη των ακμών στο γράφημα θα είναι μεταβλητές που θα μετράνε το πόσες φορές έχουν συσχετιστεί οι δυο κατηγορίες και πόσο, δηλαδή πόσες φορές έχουν βρεθεί οι δυο κατηγορίες στα ίδια αποτελέσματα και πόσο σχετικές ήταν.")
51
Υπολογισμός των βαρών των ακμών
Κάθε φορά που πρέπει να σχετιστούν δυο κατηγορίες είτε δημιουργείται ακμή (περίπτωση για αν έχουν συσχετιστεί) και παίρνει το παρακάτω βάρος (όταν δεν υπάρχει) είτε αυξάνεται η τιμή της (για να λαμβάνουμε υπόψη το πόσες φορές έχει συσχετιστεί) κατά
 και παίρνει το παρακάτω βάρος (όταν δεν υπάρχει) είτε αυξάνεται η τιμή της (για να λαμβάνουμε υπόψη το πόσες φορές έχει συσχετιστεί) κατά.")
52
Υπολογισμός των βαρών των ακμών
Τα αθροίσματα υπάρχουν γιατί σε μια κατηγορία μπορεί να ανήκουν περισσότερα από 1 αποτελέσματα, συνεπώς η κατηγορία αυτή είναι πολύ σχετική με την ερώτηση και συνεπώς και με τις άλλες κατηγορίες. Δηλαδή όσο πιο μεγάλη είναι το βάρος ανάμεσα σε δυο κατηγορίες, σημαίνει ότι για τον χρήστη αυτές οι δυο κατηγορίες είναι πολύ σχετικές.

53
Υπολογισμός των βαρών των ακμών
Η σχέση επιλέχθηκε γιατί προσδιορίζει την σχετικότητα των αποτελεσμάτων με βάση την σημαντικότητα(σειρά) που τους δίνει ο χρήστης. Η σχέση αυτή για n = 4 παίρνει τις τιμές : 1 2 3 4 - 1/2 1/3 1/4
 που τους δίνει ο χρήστης. Η σχέση αυτή για n = 4 παίρνει τις τιμές : /2. 1/3. 1/4.")
54
Υπολογισμός των βαρών των ακμών
Μέσω της σχέσης αυτής πετυχαίνουμε να λαμβάνουμε υπόψη και τη θέση των αποτελεσμάτων και πόσο σημαντικά είναι τα αποτελέσματα (πόσο ψηλά βρίσκονται στην κατάταξη των αποτελεσμάτων). Π.χ. Οι κόμβοι των αποτελεσμάτων 1,2 είναι οι πιο σχετικοί, όμως η σχέση των κόμβων 1,3 είναι ίδια με αυτή των 2,3 επειδή ο κόμβος 1 είναι πολύ σημαντικός.
. Π.χ. Οι κόμβοι των αποτελεσμάτων 1,2 είναι οι πιο σχετικοί, όμως η σχέση των κόμβων 1,3 είναι ίδια με αυτή των 2,3 επειδή ο κόμβος 1 είναι πολύ σημαντικός.")
55
Υπολογισμός των βαρών των ακμών
Τώρα μπορούμε να υπολογίσουμε και τα vother(v(pi)) και vgraph(v(pi)) που δίνονται από τους ακόλουθους τύπους. vother(v(pi)) = /max( ), (vi = v(pi)). Το max(vother) είναι το μέγιστο vother ανάμεσα στις κατηγορίες του αποτελέσματος.
) και vgraph(v(pi)) που δίνονται από τους ακόλουθους τύπους. vother(v(pi)) = /max( ), (vi = v(pi)). Το max(vother) είναι το μέγιστο vother ανάμεσα στις κατηγορίες του αποτελέσματος.")
56
Υπολογισμός των βαρών των ακμών
Τώρα μπορούμε να υπολογίσουμε και τα vother(v(pi)) και vgraph(v(pi)) που δίνονται από τους ακόλουθους τύπους. vgraph(v(pi)) = /max( ), (vi = v(pi)). Το max(vgraph) είναι το μέγιστο vgraph ανάμεσα στις κατηγορίες του αποτελέσματος.
) και vgraph(v(pi)) που δίνονται από τους ακόλουθους τύπους. vgraph(v(pi)) = /max( ), (vi = v(pi)). Το max(vgraph) είναι το μέγιστο vgraph ανάμεσα στις κατηγορίες του αποτελέσματος.")
57
Παράδειγμα Θεωρίας

59
Παράδειγμα Λειτουργίας
Βήμα 1ο . Εκτελούμε την 1η ερώτηση «upatras». Τα αποτελέσματα τις ερώτησης εμφανίζονται παρακάτω μαζί με την αντίστοιχη κατηγορία που ανήκουν και την σειρά επιλογής τους από τον χρήστη(αν δεν έχουν επιλεγεί έχει παύλα). Σειρά Google Link Κατηγορία Σειρά επιλογής p1 University of Patras - p2 Πανεπιστήμιο_Πατρών 1 p3 Academic Departments p4 Greece p5 Research_Institutes 2 p6 p7 Education p8 Medical Schools p9 2002 p10 3
. Σειρά Google. Link. Κατηγορία. Σειρά επιλογής. p1. University of Patras. - p2. Πανεπιστήμιο_Πατρών. 1. p3. Academic Departments. p4. Greece. p5. Research_Institutes. 2. p6. p7. Education. p8. Medical Schools. p p")
60
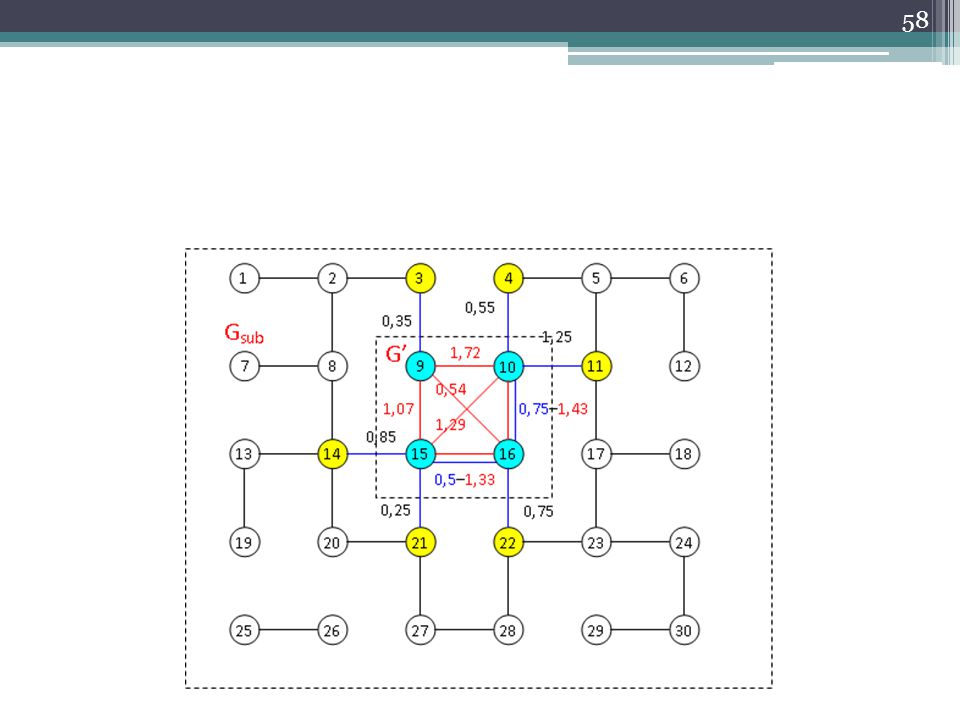
Βήμα 1ο Μετά την επιλογή αυτή που κάναμε παραπάνω, ο αλγόριθμος μας αναγνωρίζει τις διαφορετικές κατηγορίες των αποτελεσμάτων που διαλέξαμε(Πανεπιστήμιο_Πατρών[ΠΠ] και Research_Institutes[RI]). Στην συνέχεια υπολογίζει το βάρος της ακμής που θα της ενώνει(πόσο σχετικές είναι) το οποίο είναι 1,5. Τέλος ξεκινάει την κατασκευή του δένδρου, προσθέτοντας αυτές τις δυο κορυφές και την ακμή.
. Στην συνέχεια υπολογίζει το βάρος της ακμής που θα της ενώνει(πόσο σχετικές είναι) το οποίο είναι 1,5. Τέλος. ξεκινάει την κατασκευή. του δένδρου, προσθέτοντας. αυτές τις δυο κορυφές και. την ακμή.")
61
Βήμα 2ο Εκτελούμε την 2η ερώτηση «ceid». Σειρά Google Link Κατηγορία
Σειρά επιλογής p1 Πανεπιστήμιο_Πατρών 2 p2 Greece - p3 Research_Institutes 1 p4 Research Centres p5 arcadia.ceid.upatras.gr/arkadia/ Guides and Directories p6 arcadia.ceid.upatras.gr/thomtrip/ 3 p7 Universitat de vic p8 Past Conferences p9 Scientia p10 ceid=11 Tools

62
Βήμα 3ο Εκτελούμε την 3η ερώτηση «βιβλιοθήκες Πάτρας». Σειρά Google
Εκτελούμε την 3η ερώτηση «βιβλιοθήκες Πάτρας». Σειρά Google Link Κατηγορία Σειρά επιλογής p1 Ακαδημαϊκές 2 p2 University of Patras - p3 openarchives.gr/ Ψηφιακές p4 Τηλεόραση p5 Φιλοσοφία p6 Γερμανία p7 Πανεπιστήμιο_Πατρών 1 p8 Υπολογιστές, Μηχανογράφηση p9 Εικαστικές τέχνες p10 athens.indymedia.org/ Περιοδικά On Line

63
Βήμα 4ο Εκτελούμε την 4η ερώτηση «ελληνικά Πανεπιστήμια». Σειρά Google
Εκτελούμε την 4η ερώτηση «ελληνικά Πανεπιστήμια». Σειρά Google Link Κατηγορία Σειρά επιλογής p1 Πανεπιστήμια - p2 Ακαδημαϊκές 4 p3 3 p4 Εργασία p5 openarchives.gr/ Ψηφιακές p6 library.aua.gr/ 1 p7 Δευτεροβάθμια p8 Greece 2 p9 library.panteion.gr/ p10 Cyprus

64
Γράφημα του χρήστη




>")
















