Κατέβασμα παρουσίασης
1
Eλέγχουμε αν η διαφορά μεταξύ δύο μέσων τιμών (Τ και P) είναι σημαντική (δηλ. αν διαφέρει από το 0 ή ότι δεν είναι τυχαία) χρησιμοποιώντας το t-test: Recall t-test
 χρησιμοποιώντας το t-test: Recall t-test.")
2
H τιμή του t-τεστ είναι σημαντική (και επομένως διαφορά των μέσων τιμών) αν είναι μεγαλύτερη από το 5% σημείο της t-κατανομής για (n T -1)+(n P -1)df (δες πίνακα της t-κατανομής).
 αν είναι μεγαλύτερη από το 5% σημείο της t-κατανομής για (n T -1)+(n P -1)df (δες πίνακα της t-κατανομής).")
3
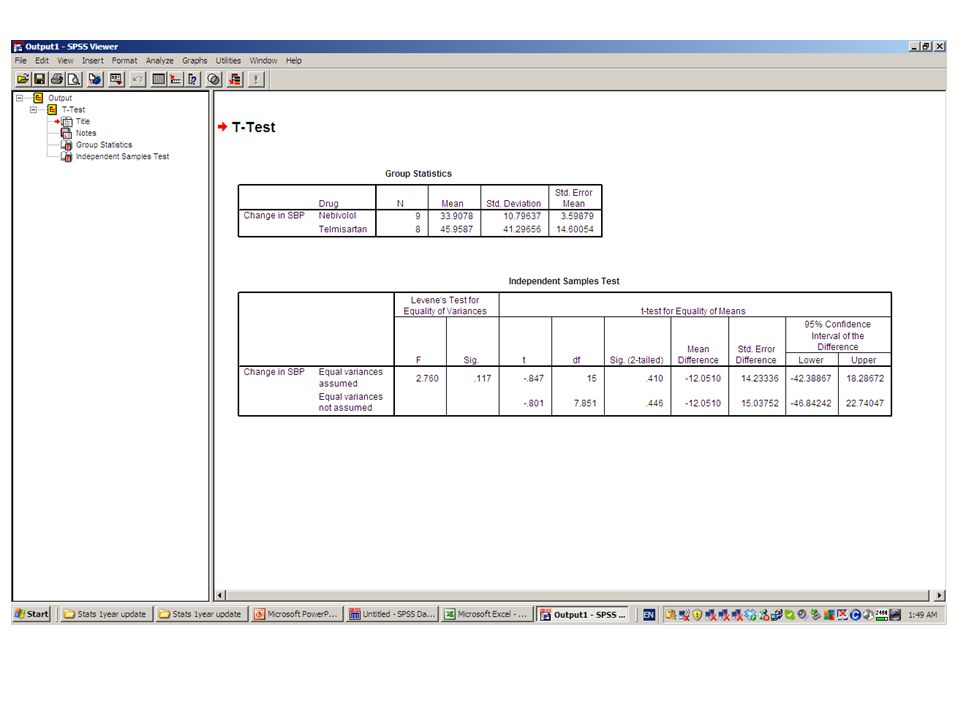
2. Nα συγκριθεί η αποτελεσματικότητα δύο φαρμάκων (Nebivolol vs Telmisartan), το Nebivolol χορηγήθηκε σε 9 ασθενείς και το Telmisartan σε 8 ασθενείς. Η αποτελεσματικότητα αξιολογήθηκε με βάση την συστολική πίεση (SBP) πριν την χορήγηση θεραπείας και μετά από τρεις μήνες: NebivololTelmisartan patientbaseline3rd monthpatientbaseline3rd month 11501201158.33130 2157.5126.672160133.33 3153.33120316012.33 4165.17113.334151.67120 51651205154.17123.33 61601206155126.67 7165136.677155.83116.67 8150118.338151.67116.67 9147.5133.33
, το Nebivolol χορηγήθηκε σε 9 ασθενείς και το Telmisartan σε 8 ασθενείς. Η αποτελεσματικότητα αξιολογήθηκε με βάση την συστολική πίεση (SBP) πριν την χορήγηση θεραπείας και μετά από τρεις μήνες: NebivololTelmisartan patientbaseline3rd monthpatientbaseline3rd month")
5
Σύγκριση δύο ή περισσότερων θεραπειών (One-way ANOVA)
")
6
Η ανάλυση διασποράς με ένα παράγοντα χρησιμοποιείται όταν θέλουμε να συγκρίνουμε τις μέσες τιμές πολλών ομάδων (περισσότερες από δύο). Η ανάλυση καλείται με ένα παράγοντα επειδή τα δεδομένα ταξινομούνται σύμφωνα με ένα παράγοντα ή ομάδα.

7
Παράδειγμα: Σε μία μελέτη, έχει καταγραφεί το βάρος του ήπατος (x) (εκφρασμένο ως ποσοστό του βάρους του σώματος) ποντικιών που ανήκουν σε k=4 ομάδες που τράφηκαν με 4 διαφορετικές δίαιτες. Θέλουμε να ερευνήσουμε αν υπάρχουν συστηματικές διαφορές μεταξύ των 4 ομάδων, δηλ. να θέλουμε να συγκρίνουμε τις μέσες τιμές των 4 ομάδων.

8
Ο έλεγχος για τις διαφορές μεταξύ των ομάδων βασίζεται στον εντοπισμό όλων των πηγών που διαμορφώνουν την μεταβλητότητα των δεδομένων (δηλ. τι κάνει τα 24 νούμερα να είναι διαφορετικά). Οπότε, η συνολική μεταβλητότητα (ή διακύμανση) αναλύεται στις πηγές διακύμανσης που την συνθέτουν (analysis of variance, ANOVA)
. Οπότε, η συνολική μεταβλητότητα (ή διακύμανση) αναλύεται στις πηγές διακύμανσης που την συνθέτουν (analysis of variance, ANOVA).")
9
Προφανώς, μία πηγή μεταβλητότητας (ή διακύμανσης) είναι η επίδραση των 4 διαίτων. Μία άλλη πηγή διακύμανσης είναι η ενδογενή διακύμανση μέσα στην κάθε ομάδα αφού το κάθε ποντίκι αντιδρά διαφορετικά στην ίδια δίαιτα; αυτή η μεταβλητότητα δεν μπορεί να ελεγχθεί και συνεπώς θεωρείται ως τυχαίο σφάλμα ή τυχαία διακύμανση (error).
..")
10
Ο έλεγχος για τις διαφορές μεταξύ των ομάδων βασίζεται στη σύγκριση μεταξύ της διακύμανσης μεταξύ των 4 ομάδων με την τυχαία διακύμανση, δηλ. την ενδογενή διακύμανση της κάθε ομάδας Αν η διακύμανση μεταξύ των 4 ομάδων είναι ίση με την τυχαία διακύμανση τότε συμπεραίνουμε ότι η διακύμανση μεταξύ των 4 ομάδων είναι τυχαία, δηλ. δεν υπάρχουν πραγματικές διαφορές μεταξύ των ομάδων Διαφορετικά, διακύμανση μεταξύ των 4 ομάδων δεν είναι τυχαία, δηλ. υπάρχουν πραγματικές διαφορές μεταξύ των ομάδων

11
Η σύγκριση μεταξύ της διακύμανσης μεταξύ των 4 ομάδων με την τυχαία διακύμανση γίνεται με το F-test που προκύπτει από το πίνακα της ANOVA: Source of variation df SS ------------------------------------------------------------------ Between groups 4-1=3 0.954 Within groups (error/random) 23-3=20 0.876 ------------------------------------------------------------------ Total 24-1=23 1.83 H ANOVA διαιρεί το συνολικό SS=1.83 σε δύο μέρη: i)Το SS που οφείλεται στις διαφορές μεταξύ των μέσων τιμών ομάδων (Between groups SS) που είναι η διακύμανση μεταξύ των 4 μέσων τιμών ii) Το SS του σφάλματος (ή Within groups SS) που είναι (Total SS)-(Between groups SS) Με όμοιο τρόπο διαιρείται το σύνολο (n-1) των df
 23-3= Total 24-1= H ANOVA διαιρεί το συνολικό SS=1.83 σε δύο μέρη: i)Το SS που οφείλεται στις διαφορές μεταξύ των μέσων τιμών ομάδων (Between groups SS) που είναι η διακύμανση μεταξύ των 4 μέσων τιμών ii) Το SS του σφάλματος (ή Within groups SS) που είναι (Total SS)-(Between groups SS) Με όμοιο τρόπο διαιρείται το σύνολο (n-1) των df")
12
Μετά υπολογίζεται, η μέση διακύμανση (Mean Square, MS), δηλ. MS=SS/df, της κάθε πηγής διακύμανσης Source of variation dfSSMS=SS/df --------------------------------------------------------------------------------- Between groups 30.9540.318 Within groups (error/random) 200.8760.044=s 2 ---------------------------------------------------------------------------------- Total 231.83
 =s Total")
13
Κατόπιν, η μέση διακύμανση μεταξύ των 4 ομάδων συγκρίνεται με την μέση τυχαία διακύμανση χρησιμοποιώντας το F-test: Αν η μέση διακύμανση μεταξύ των 4 ομάδων είναι μεγαλύτερη από την μέση τυχαία διακύμανση, τότε οι διαφορές μεταξύ των 4 ομάδων δεν είναι τυχαίες (είναι πραγματικές) Σε αυτή την περίπτωση, η τιμή του F-test γίνεται πολύ μεγαλύτερη του 1
 Σε αυτή την περίπτωση, η τιμή του F-test γίνεται πολύ μεγαλύτερη του 1")
14
Η σημαντικότητα της τιμής F=7.23 προσδιορίζεται με παρόμοιο τρόπο με το t-test (δηλ. προσομοιώνουμε τυχαία 10000 φορές την μελέτη υποθέτοντας ότι οι δίαιτες δεν διαφέρουν και υπολογίζουμε τα 10000 F-tests, τα οποία σχηματίζουν τη F-κατανομή, και βρίσκουμε το ποσοστό των F- tests που είναι μεγαλύτερα από το F=7.23) Τότε, P=0.002 Συνεπώς, οι 4 δίαιτες διαφέρουν μεταξύ τους σημαντικά (με μία μικρή πιθανότητα λάθους P<0.05 ή P=0.002)
 Τότε, P=0.002 Συνεπώς, οι 4 δίαιτες διαφέρουν μεταξύ τους σημαντικά (με μία μικρή πιθανότητα λάθους P<0.05 ή P=0.002).")
15
Εναλλακτικά, η τιμή F=7.23 συγκρίνεται με 5% σημείο της F- κατανομής με 3 και 20 df που είναι 3.1 (δες Πίνακα F-κατανομής). Eπειδή το F=7.23 είναι μεγαλύτερο από το 3.2 συμπεραίνουμε ότι υπάρχει ένδειξη (P<0.05) οι ομάδες (δίαιτες) διαφέρουν μεταξύ τους
 οι ομάδες (δίαιτες) διαφέρουν μεταξύ τους.")
16
5% points of the F-distribution

17
Post-hoc tests Αν η ANOVA δείξει ότι υπάρχουν σημαντικές διαφορές μεταξύ των ομάδων τότε μπορούμε να κάνουμε επιμέρους συγκρίσεις μεταξύ των ομάδων, π.χ. να συγκρίνουμε την ομάδα a με την ομάδα b, χρησιμοποιώντας το t-test. Όμως, αυτό το t-test διαφέρει από το προηγούμενο στο SE (εδώ υπολογίζεται χρησιμοποιώντας την τυχαία διακύμανση, το error). To t-test είναι: H τιμή του t-test (t=3.25) είναι μεγαλύτερη από το 5% σημείο της t- κατανομής για 20 df (οι df του error) που είναι 2.09 Συνεπώς, υπάρχει σημαντική διαφορά μεταξύ των ομάδων a και b (P<0.05 ή πιο συγκεκριμένα P=0.004)
. To t-test είναι: H τιμή του t-test (t=3.25) είναι μεγαλύτερη από το 5% σημείο της t- κατανομής για 20 df (οι df του error) που είναι 2.09 Συνεπώς, υπάρχει σημαντική διαφορά μεταξύ των ομάδων a και b (P<0.05 ή πιο συγκεκριμένα P=0.004).")
18
Διάστημα εμπιστοσύνης (δε) μέσης τιμής των διαφορών Το 95% δ.ε. για την μέση τιμή των διαφορών των ομάδων a και b είναι: Οπότε, με 95% βεβαιότητα η ομάδα a έχει υψηλότερο βάρος μεταξύ 0.14 και 0.64 από ότι η ομάδα b Επειδή το 0 δεν συμπεριλαμβάνεται μέσα στο 95% δε, σημαίνει ότι η διαφορά είναι σημαντική

19
Πολλαπλές συγκρίσεις - Διόρθωση Bonferroni Όλες οι πιθανές συγκρίσεις μεταξύ των ομάδων δεν είναι ανεξάρτητες. Για το λόγο αυτό όταν γίνονται πολλαπλές συγκρίσεις (k) η στάθμη σημαντικότητας (P) πρέπει να διορθώνεται σε P’=kP Συνεπώς, αν εκτελέσουμε 6 συγκρίσεις μεταξύ ομάδων, η σύγκριση μεταξύ της δίαιτας a και b θα είναι σημαντική αν το P-value είναι P>6*0.004=0.024
 η στάθμη σημαντικότητας (P) πρέπει να διορθώνεται σε P’=kP Συνεπώς, αν εκτελέσουμε 6 συγκρίσεις μεταξύ ομάδων, η σύγκριση μεταξύ της δίαιτας a και b θα είναι σημαντική αν το P-value είναι P>6*0.004=")
20
Ασκήσεις Θέλουμε να συγκρίνουμε τα επίπεδα αιμοσφαιρίνης τριών ομάδων ασθενών με τρεις διαφορετικούς τύπους δρεπανοκυτταρικής αναιμίας. Η κάθε ομάδα αποτελείται από 15 ασθενείς. Πώς θα συγκρίνουμε τις τρείς ομάδες? Αν το Sum of Squares μεταξύ των ομάδων είναι 100 και το Error Sum of Squares είναι 30 είναι στατιστικά σημαντική η διαφορά μεταξύ των ομάδων? Πώς θα συγκρίνουμε την πρώτη με την τρίτη ομάδα? Μετρήθηκε η ποσότητα πρωτεϊνης (gr/100ml) στο αίμα ατόμων που ζουν σε διαφορετικές συνθήκες στις γεωγραφικές περιοχές Α, Β, Γ και βρέθηκε ότι Α: 7.6, 7.0, 7.5, 7.9Β: 7.6, 7.2, 7.5, 7.1 Γ: 8.0, 8.2, 8.3, 8.4 1. Πως θα δείξουμε αν η ποσότητα πρωτεϊνης στο αίμα είναι η ίδια και στις τρεις περιοχές? 2. Αν το Sum of Squares μεταξύ των ομάδων είναι 1.75 και το Error Sum of Squares είναι 0.68 είναι στατιστικά σημαντική η διαφορά μεταξύ των ομάδων? 3. Διαφέρει η περιοχή Β από τη Γ?
 στο αίμα ατόμων που ζουν σε διαφορετικές συνθήκες στις γεωγραφικές περιοχές Α, Β, Γ και βρέθηκε ότι Α: 7.6, 7.0, 7.5, 7.9Β: 7.6, 7.2, 7.5, 7.1 Γ: 8.0, 8.2, 8.3, Πως θα δείξουμε αν η ποσότητα πρωτεϊνης στο αίμα είναι η ίδια και στις τρεις περιοχές. 2. Αν το Sum of Squares μεταξύ των ομάδων είναι 1.75 και το Error Sum of Squares είναι 0.68 είναι στατιστικά σημαντική η διαφορά μεταξύ των ομάδων. 3. Διαφέρει η περιοχή Β από τη Γ .")
21
Ανάλυση διασποράς με δύο παράγοντες (two-way ANOVA) χωρίς αλληλεπίδραση
 χωρίς αλληλεπίδραση")
22
Όταν υπάρχουν δύο πιθανοί γνωστοί παράγοντες που συνεισφέρουν στη μεταβλητότητα (διακύμανση) των δεδομένων τότε ο έλεγχος της επίδρασης του κάθε παράγοντα γίνεται με την ανάλυση διασποράς με δύο παράγοντες (two-way ANOVA). Η ανάλυση γίνεται συνήθως με τη χρήση στατιστικού προγράμματος.

23
Παράδειγμα: Σε ένα πείραμα για να συγκρίνουμε την επίδραση k=3 φαρμάκων στον αριθμό λεμφοκυττάρων σε ποντίκια, χρησιμοποιήθηκε ένας σχεδιασμός με 3 ποντίκια από b=4 διαφορετικά κλουβιά. Ο αριθμός λεμφοκυττάρων ήταν: Υπάρχουν δύο πιθανοί παράγοντες διακύμανσης: το κλουβί και το φάρμακο

24
Η διαίρεση της συνολικής διακύμανσης ακολουθεί την ίδια φιλοσοφία με την One-way ANOVA. H ANOVA παρουσιάζεται με τον εξής πίνακα: Ελέγχουμε αν τα φάρμακα διαφέρουν μεταξύ τους συγκρίνοντας την τιμή F=(Between drugs MS)/(Residual MS)=14.89 με το 5% σημείο της F-κατανομής με 2 και 6 df (Between drugs df και Residual df) Error SS = Total SS – (Between litters SS + Between Drugs SS)
/(Residual MS)=14.89 με το 5% σημείο της F-κατανομής με 2 και 6 df (Between drugs df και Residual df) Error SS = Total SS – (Between litters SS + Between Drugs SS).")
25
Επειδή η τιμή του F=14.89 είναι μεγαλύτερη από τη τιμή της F- κατανομής που είναι 5.14 (δες Πίνακα της F-κατανομής) τότε υπάρχει σημαντική διαφορά μεταξύ των φαρμάκων με (πιθανότητα λάθους) P<0.05 Η σύγκριση μεταξύ δύο φαρμάκων γίνεται με t-test όπως ακριβώς στον one-way ANOVA
 τότε υπάρχει σημαντική διαφορά μεταξύ των φαρμάκων με (πιθανότητα λάθους) P<0.05 Η σύγκριση μεταξύ δύο φαρμάκων γίνεται με t-test όπως ακριβώς στον one-way ANOVA")
26
5% points of the F-distribution

27
Άσκηση

28
Με ποια στατιστική τεχνική θα συγκρίνουμε τα δύο φάρμακα?

29
Πρώτα υπολογίζουμε την βελτίωση της πίεσης σε κάθε ασθενή και μετά συγκρίνουμε τα φάρμακα σε σχέση με τη βελτίωση με 2-way ANOVA.

30
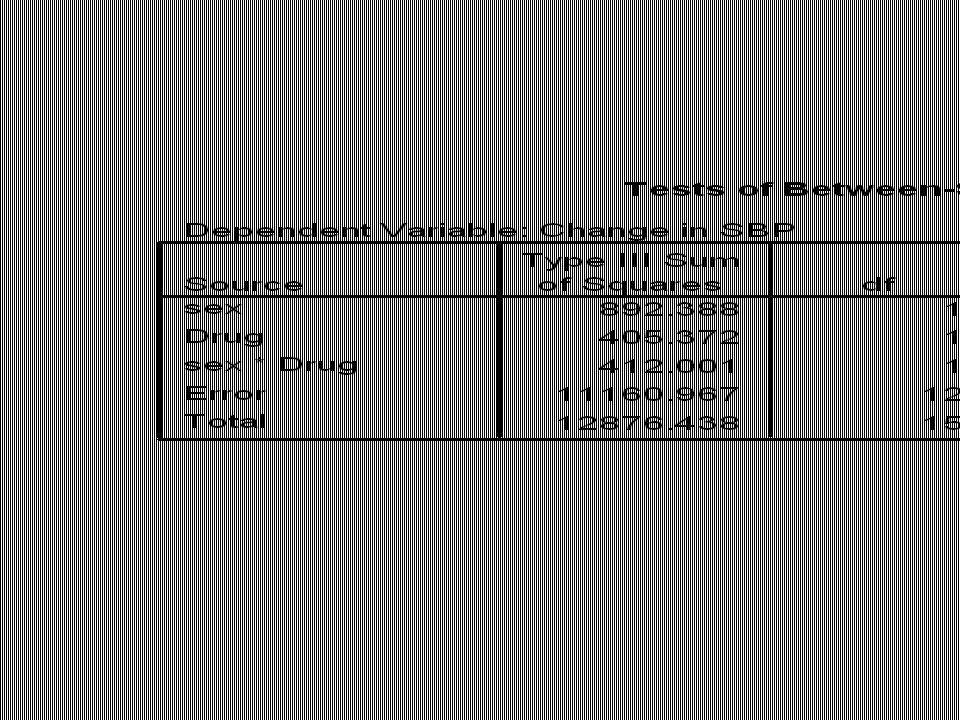
Αν το Total SS is 12876, το Sex SS is 933 και το Drug SS is 527, 1) ελέγξτε αν υπάρχει σημαντική διαφορά μεταξύ των φαρμάκων και 2) βρείτε το 95% CI της διαφορά τους. Ερμηνεύστε τα αποτέλεσματα.

31
Δεν υπάρχει σημαντική διαφορά μεταξύ των φαρμάκων με P<0.05 ή P=0.456.

32
Το 95% CI της μέσης τιμής του Nebivolol επικαλύπτεται με το 95 CI της μέσης τιμής του Telmisartan. Δηλ. επιβεβαιώνονται περιγραφικά το αποτέλεσμα της ANOVA.

33
Το 95 CI της διαφοράς των δύο μέσων τιμών περιέχει το μηδέν, δηλαδή δεν υπάρχει σημαντική διαφορά μεταξύ των φαρμάκων.

34
Ανάλυση διασποράς με δύο παράγοντες με αλληλεπίδραση (two-way ANOVA with interaction)
")
35
Ανάλυση διασποράς με δύο παράγοντες (Two-way ANOVA) με αλληλεπίδραση Όταν τα δεδομένα ταξινομούνται σε δύο παράγοντες και υπάρχουν πολλαπλές παρατηρήσεις για κάθε συνδυασμό των δύο παραγόντων τότε ο έλεγχος της επίδρασης του κάθε παράγοντα (δηλ της διαφοράς μεταξύ των επιπέδων του παράγοντα) ή της αλληλεπίδρασης μεταξύ των παραγόντων γίνεται με την ανάλυση διασποράς με δύο παράγοντες (two- way ANOVA) και αλληλεπίδραση.
 με αλληλεπίδραση Όταν τα δεδομένα ταξινομούνται σε δύο παράγοντες και υπάρχουν πολλαπλές παρατηρήσεις για κάθε συνδυασμό των δύο παραγόντων τότε ο έλεγχος της επίδρασης του κάθε παράγοντα (δηλ της διαφοράς μεταξύ των επιπέδων του παράγοντα) ή της αλληλεπίδρασης μεταξύ των παραγόντων γίνεται με την ανάλυση διασποράς με δύο παράγοντες (two- way ANOVA) και αλληλεπίδραση.")
36
Παράδειγμα: Για να ερευνήσουμε την επίδραση του σορβικού οξέος (sa) και του pH του νερού στην επιβίωση της σαλμονέλας, χρησιμοποιήσαμε w=3 επίπεδα pH (5.0, 5.5, 6.0) και s=2 επίπεδα σορβικού οξέος (0, 100 p.p.m.). Για τον κάθε συνδυασμό sa και pH υπάρχουν k=3 παρατηρήσεις. Μία εβδομάδα μετά μετρήθηκε η ποσότητα σαλμονέλας που επιβίωσε (log(πυκνότητα/ml)). Τα δεδομένα ήταν:
). Τα δεδομένα ήταν:.")
37
Η ANOVA παρουσιάζεται με τον εξής πίνακα: Ελέγχουμε αν τα επίπεδα pH διαφέρουν συγκρίνοντας την τιμή F=(pH MS)/(Residual MS)=590 με το 5% σημείο της F-κατανομής με 2 και 12 df (pH df και Residual df) που είναι 3.89 (δες Πίνακα F- κατανομής) Επειδή η τιμή της F=590 είναι μεγαλύτερη από το 3.89, υπάρχει σημαντική διαφορά μεταξύ των επιπέδων pH (P<0.05)
/(Residual MS)=590 με το 5% σημείο της F-κατανομής με 2 και 12 df (pH df και Residual df) που είναι 3.89 (δες Πίνακα F- κατανομής) Επειδή η τιμή της F=590 είναι μεγαλύτερη από το 3.89, υπάρχει σημαντική διαφορά μεταξύ των επιπέδων pH (P<0.05)")
38
5% points of the F-distribution

39
Ελέγχουμε αν τα επίπεδα sa διαφέρουν συγκρίνοντας την τιμή F=(sa MS)/(Residual MS)=23.89 με το 5% σημείο της F-κατανομής με 1 και 12 df (sa df και Residual df) που είναι 4.75 (δες Πίνακα F- κατανομής) Επειδή η τιμή της F=23.89 είναι μεγαλύτερη από το 4.75, υπάρχει διαφορά μεταξύ των επιπέδων pH (P<0.05)
/(Residual MS)=23.89 με το 5% σημείο της F-κατανομής με 1 και 12 df (sa df και Residual df) που είναι 4.75 (δες Πίνακα F- κατανομής) Επειδή η τιμή της F=23.89 είναι μεγαλύτερη από το 4.75, υπάρχει διαφορά μεταξύ των επιπέδων pH (P<0.05)")
40
Ελέγχουμε αν υπάρχει αλληλεπίδραση μεταξύ pH και sa συγκρίνοντας την τιμή F=(Interaction MS)/(Residual MS)=4.72 με το 5% σημείο της F-κατανομής με 2 και 12 df (Interaction df και Residual df) που είναι 3.89 (δες Πίνακα F-κατανομής) Επειδή η τιμή της F=4.72 είναι μεγαλύτερη από το 3.89, υπάρχει αλληλεπίδραση μεταξύ pH και sa (P<0.05)
/(Residual MS)=4.72 με το 5% σημείο της F-κατανομής με 2 και 12 df (Interaction df και Residual df) που είναι 3.89 (δες Πίνακα F-κατανομής) Επειδή η τιμή της F=4.72 είναι μεγαλύτερη από το 3.89, υπάρχει αλληλεπίδραση μεταξύ pH και sa (P<0.05)")
41
Αλληλοεπίδραση Η ύπαρξη της αλληλεπίδρασης σημαίνει ότι η διαφορά (D) sa0- sa100 δεν είναι σταθερή για τα διαφορετικά επίπεδα pH. Οι μέσες τιμές για τον κάθε συνδυασμό sa και pH είναι: Οι διαφορές (D) sa0-sa100 για κάθε επίπεδο pH είναι: Αλληλεπίδραση σημαίνει ότι οι διαφορές (D) διαφέρουν μεταξύ τους
 sa0-sa100 για κάθε επίπεδο pH είναι: Αλληλεπίδραση σημαίνει ότι οι διαφορές (D) διαφέρουν μεταξύ τους.")
42
Μπορούμε να κάνουμε σύγκριση των μέσων τιμών δύο επιπέδων pH ή δύο επιπέδων sa χρησιμοποιώντας το t-test (όπως και στην one- way ANOVA) Επίσης, μπορούμε να κάνουμε σύγκριση των μέσων τιμών δύο επιπέδων pH για ένα επίπεδο του sa χρησιμοποιώντας πάλι το t-test (όπως και στην one-way ANOVA)
 Επίσης, μπορούμε να κάνουμε σύγκριση των μέσων τιμών δύο επιπέδων pH για ένα επίπεδο του sa χρησιμοποιώντας πάλι το t-test (όπως και στην one-way ANOVA)")
43
Άσκηση

44
Αν το Total SS is 12876, το Sex SS is 892 και το Drug SS is 405, 1) ελέγξτε αν υπάρχει αλληλεπίδραση μεταξύ Sex και φαρμάκων? Ερμηνεύστε τα αποτελέσματα.

46
Μετατροπή των δεδομένων

47
Για να είναι έγκυρος ένας στατιστικός έλεγχος όπως t-test ή ANOVA πρέπει να υποθέσουμε ότι: 1) οι παρατηρήσεις έχουν κανονική κατανομή και 2) οι διακυμάνσεις των ομάδων που συγκρίνονται είναι ίσες. Αν δεν πληρούνται οι παραπάνω υποθέσεις και τα δείγματα είναι μικρά σε μέγεθος τότε τα δεδομένα χρειάζεται να μετασχηματισθούν στους λογαρίθμους τους. Η ανάλυση τότε θα βασίζεται στα λογαριθμοποιημένα δεδομένα. Αν τα δεδομένα είναι συχνότητες τότε ίσως χρειάζεται να μετασχηματισθούν στις τετραγωνικές τους ρίζες. Ο λογάριθμος (log) μίας ποσότητας x είναι η ποσότητα y, y=log(x), έτσι ώστε x=e y, όπου e=2.718. Ο λογάριθμος του 1 είναι 0 και του 0 είναι άπειρο. Μπορούμε να βρούμε τον λογάριθμο μόνο θετικών τιμών.
 μίας ποσότητας x είναι η ποσότητα y, y=log(x), έτσι ώστε x=e y, όπου e= Ο λογάριθμος του 1 είναι 0 και του 0 είναι άπειρο. Μπορούμε να βρούμε τον λογάριθμο μόνο θετικών τιμών..")
48
Παράδειγμα: Η κατανομή των τιμών χολερυθρίνης ορού μίας ομάδας ατόμων δεν ακολουθεί την κανονική κατανομή. Τότε με έναν λογαριθμικό μετασχηματισμό τα δεδομένα ακολουθούν κανονική κατανομή.







>")










>")
 από το οποίο το δείγμα λαμβάνεται. Δείγμα.>")
>")
