Κατέβασμα παρουσίασης
1
Προεπεξεργασία Δεδομένων
Εξόρυξη Δεδομένων και Αλγόριθμοι Μάθησης Επαναληπτικο Φροντιστήριο Τσιράκης Νίκος Σκούρα Αγγελική

2
Σκοπός της προεπεξεργασίας
Τα δεδομένα γενικά χαρακτηρίζονται ως dirty Δεν είναι ολοκληρωμένα: λείπουν τιμές χαρακτηριστικών, λείπουν σημαντικά χαρακτηριστικά ή περιέχουν συναθροιστικά δεδομένα Περιέχουν «θόρυβο»: περιέχουν σφάλματα ή outliers Είναι αντιφατικά: περιέχουν ασυμφωνίες σε κώδικες ή ονόματα Τα δεδομένα είναι κακής ποιότητας Για να έχουμε ποιοτικά αποτελέσματα από την εξόρυξη γνώσης χρειαζόμαστε ποιοτικά δεδομένα Οι αποθήκες δεδομένων έχουν ανάγκη από συνεπή ενοποίηση ποιοτικών δεδομένων

3
Βήματα προεπεξεργασίας
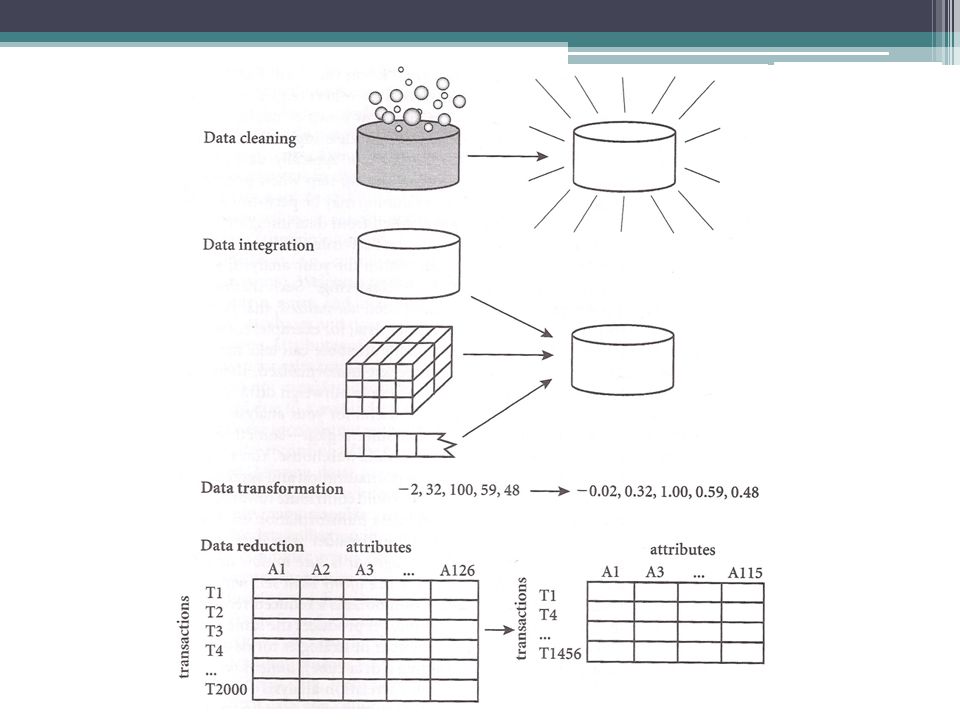
Καθαρισμός δεδομένων (Data cleaning) Συμπλήρωση των missing data, εξομάλυνση δεδομένων με θόρυβο, αναγνώριση ή απομάκρυνση από outliers, και επίλυση ασυνεπειών στα δεδομένα Ενοποίηση δεδομένων (Data integration) Ενοποίηση πολλαπλών βάσεων δεδομένων Μετασχηματισμός δεδομένων (Data transformation) Κανονικοποίηση και συνάθροιση δεδομένων Μείωση δεδομένων (Data reduction) Διατηρούνται μειωμένες αναπαραστάσεις δεδομένων σε χωρητικότητα αλλά δημιουργούνται ίδια ή παρόμοια αποτελέσματα ανάλυσης Περικοπή δεδομένων (Data discretization) Μέρος της μείωσης δεδομένων αλλά με ιδιαίτερη σημαντικότητα, ειδικά για numerical data
 Συμπλήρωση των missing data, εξομάλυνση δεδομένων με θόρυβο, αναγνώριση ή απομάκρυνση από outliers, και επίλυση ασυνεπειών στα δεδομένα. Ενοποίηση δεδομένων (Data integration) Ενοποίηση πολλαπλών βάσεων δεδομένων. Μετασχηματισμός δεδομένων (Data transformation) Κανονικοποίηση και συνάθροιση δεδομένων. Μείωση δεδομένων (Data reduction) Διατηρούνται μειωμένες αναπαραστάσεις δεδομένων σε χωρητικότητα αλλά δημιουργούνται ίδια ή παρόμοια αποτελέσματα ανάλυσης. Περικοπή δεδομένων (Data discretization) Μέρος της μείωσης δεδομένων αλλά με ιδιαίτερη σημαντικότητα, ειδικά για numerical data.")
5
Βήματα προεπεξεργασίας
Καθαρισμός δεδομένων (Data cleaning) Συμπλήρωση των missing data, εξομάλυνση δεδομένων με θόρυβο, αναγνώριση ή απομάκρυνση από outliers, και επίλυση ασυνεπειών στα δεδομένα Ενοποίηση δεδομένων (Data integration) Ενοποίηση πολλαπλών βάσεων δεδομένων Μετασχηματισμός δεδομένων (Data transformation) Κανονικοποίηση και συνάθροιση δεδομένων Μείωση δεδομένων (Data reduction) Διατηρούνται μειωμένες αναπαραστάσεις δεδομένων σε χωρητικότητα αλλά δημιουργούνται ίδια ή παρόμοια αποτελέσματα ανάλυσης Περικοπή δεδομένων (Data discretization) Μέρος της μείωσης δεδομένων αλλά με ιδιαίτερη σημαντικότητα, ειδικά για numerical data
 Συμπλήρωση των missing data, εξομάλυνση δεδομένων με θόρυβο, αναγνώριση ή απομάκρυνση από outliers, και επίλυση ασυνεπειών στα δεδομένα. Ενοποίηση δεδομένων (Data integration) Ενοποίηση πολλαπλών βάσεων δεδομένων. Μετασχηματισμός δεδομένων (Data transformation) Κανονικοποίηση και συνάθροιση δεδομένων. Μείωση δεδομένων (Data reduction) Διατηρούνται μειωμένες αναπαραστάσεις δεδομένων σε χωρητικότητα αλλά δημιουργούνται ίδια ή παρόμοια αποτελέσματα ανάλυσης. Περικοπή δεδομένων (Data discretization) Μέρος της μείωσης δεδομένων αλλά με ιδιαίτερη σημαντικότητα, ειδικά για numerical data.")
6
Καθαρισμός δεδομένων (Data cleaning)
Εργασίες στο καθαρισμό δεδομένων Άμεση κτήση δεδομένων (data acquisition) και μετα- δεδομένων Συμπλήρωση των missing data Μετατροπή των nominal τιμών σε numerical Αναγνώριση των outliers και εξομάλυνση δεδομένων με θόρυβο Διόρθωση ασυνεπειών στα δεδομένα
 και μετα- δεδομένων. Συμπλήρωση των missing data. Μετατροπή των nominal τιμών σε numerical. Αναγνώριση των outliers και εξομάλυνση δεδομένων με θόρυβο. Διόρθωση ασυνεπειών στα δεδομένα.")
7
Acquisition (απόκτηση)
Τα δεδομένα μπορούν να είναι σε DBMS OpenDBConnectivity ODBC (Ο στόχος της είναι η πρόσβαση σε οποιαδήποτε δεδομένα από κάθε εφαρμογή, ανεξάρτητα από ποια database management system (DBMS) αποκτούμε τα δεδομένα) . Η ODBC το επιτυγχάνει εισάγοντας ένα ενδιάμεσο layer, το οποίο ονομάζεται database driver, μεταξύ της εφαρμογής και των DBMS). JavaDBC JDBC (Είναι ένα Java API το οποίο επιτρέπει στoυς προγραμματιστές JAVA να αποκτούν πρόσβαση σε σχεσιακές DBs) Δεδομένα σε ένα flat file Fixed-column μορφή Delimited format: tab, comma “,”, other π.χ. το Weka χρησιμοποιεί comma-delimited δεδομένα Μετατροπή των χαρακτήρων αρχής/τέλους μέσα στις συμβολοσειρές Εξακρίβωση του αριθμού των πεδίων πριν και μετά
 αποκτούμε τα δεδομένα) . Η ODBC το επιτυγχάνει εισάγοντας ένα ενδιάμεσο layer, το οποίο ονομάζεται database driver, μεταξύ της εφαρμογής και των DBMS). JavaDBC JDBC (Είναι ένα Java API το οποίο επιτρέπει στoυς προγραμματιστές JAVA να αποκτούν πρόσβαση σε σχεσιακές DBs) Δεδομένα σε ένα flat file. Fixed-column μορφή. Delimited format: tab, comma , , other. π.χ. το Weka χρησιμοποιεί comma-delimited δεδομένα. Μετατροπή των χαρακτήρων αρχής/τέλους μέσα στις συμβολοσειρές. Εξακρίβωση του αριθμού των πεδίων πριν και μετά.")
8
Μετα-δεδομένα (Metadata)
Τύποι πεδίων: binary, nominal (categorical),ordinal, numeric, … Ρόλοι πεδίων: input : inputs for modeling target : output id/auxiliary : keep, but not use for modeling ignore : don’t use for modeling weight : instance weight Περιγραφή πεδίων
,ordinal, numeric, … Ρόλοι πεδίων: input : inputs for modeling. target : output. id/auxiliary : keep, but not use for modeling. ignore : don’t use for modeling. weight : instance weight. Περιγραφή πεδίων.")
9
Missing Data Τα δεδομένα δεν είναι πάντα διαθέσιμα π.χ. πολλές πλειάδες δεν έχουν τιμές για κάποια χαρακτηριστικά, όπως το εισόδημα του πελάτη στα δεδομένα πωλήσεων Τα missing data μπορούν να οφείλονται: Βλάβη εξοπλισμού Ασυμβατότητα με άλλα δεδομένα οπότε και διαγράφονται Δεδομένα που δεν συμπληρώθηκαν ποτέ λόγω κακής συνεννόησης Δεδομένα που δεν ήταν σημαντικό να αποθηκευθούν Δεν υπάρχει ιστορικό των δεδομένων Τα missing data μπορεί να πρέπει να εξαχθούν από συμπεράσματα

10
Πως χειριζόμαστε τα missing data
Παραβλέπουμε πλειάδες: συνήθως όταν λείπει το class label (π.χ. το classification δεν είναι αποτελεσματικό όταν το ποσοστό των missing values ανά χαρακτηριστικό διαφοροποιείται σημαντικά) Συμπλήρωση των missing data manually Χρησιμοποίηση γενικών σταθερών για τη συμπλήρωση των missing data: π.χ., “unknown”
 Συμπλήρωση των missing data manually. Χρησιμοποίηση γενικών σταθερών για τη συμπλήρωση των missing data: π.χ., unknown")
11
Δεδομένα με θόρυβο (Noisy Data)
Θόρυβος: τυχαίο σφάλμα ή ασυμφωνία σε μετρημένες μεταβλητές Λάθος τιμές χαρακτηριστικών μπορεί να οφείλονται σε: λάθη στον τρόπο συλλογής δεδομένων λάθη στην εισαγωγή δεδομένων προβλήματα στη μετάδοση δεδομένων περιορισμούς στην τεχνολογία inconsistency in naming convention Άλλα προβλήματα για τα οποία χρειάζεται καθαρισμός των δεδομένων: διπλές εγγραφές ημιτελή δεδομένα ασυνεπή δεδομένα

12
Πως χειριζόμαστε τα δεδομένα με θόρυβο
Συνδυασμός υπολογιστικής και ανθρώπινης παρατήρησης Αναγνώριση ύποπτων τιμών και έλεγχος τους Binning method: Αρχικά ταξινόμηση δεδομένων και διαχωρισμός τους σε (equi-depth) bins Smooth by bin means, smooth by bin median, smooth by bin boundaries, etc. Clustering(Συσταδοποίηση ) Βρίσκει και απομακρύνει τα outliers Regression (Απόκλιση) Εξομάλυνση των δεδομένων με χρήση των regression functions
 bins. Smooth by bin means, smooth by bin median, smooth by bin boundaries, etc. Clustering(Συσταδοποίηση ) Βρίσκει και απομακρύνει τα outliers. Regression (Απόκλιση) Εξομάλυνση των δεδομένων με χρήση των regression functions.")
13
Binning method Sorted data for price (in dollars): 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34 Partition into (equi-depth) bins: - Bin 1: 4, 8, 9, 15 - Bin 2: 21, 21, 24, 25 - Bin 3: 26, 28, 29, 34 Smoothing by bin means: - Bin 1: 9, 9, 9, 9 - Bin 2: 23, 23, 23, 23 - Bin 3: 29, 29, 29, 29 Smoothing by bin boundaries: - Bin 1: 4, 4, 4, 15 - Bin 2: 21, 21, 25, 25 - Bin 3: 26, 26, 26, 34

14
Clustering

15
Linear Regression

16
Βήματα προεπεξεργασίας
Καθαρισμός δεδομένων (Data cleaning) Συμπλήρωση των missing data, εξομάλυνση δεδομένων με θόρυβο, αναγνώριση ή απομάκρυνση από outliers, και επίλυση ασυνεπειών στα δεδομένα Ενοποίηση δεδομένων (Data integration) Ενοποίηση πολλαπλών βάσεων δεδομένων Μετασχηματισμός δεδομένων (Data transformation) Κανονικοποίηση και συνάθροιση δεδομένων Μείωση δεδομένων (Data reduction) Διατηρούνται μειωμένες αναπαραστάσεις δεδομένων σε χωρητικότητα αλλά δημιουργούνται ίδια ή παρόμοια αποτελέσματα ανάλυσης Περικοπή δεδομένων (Data discretization) Μέρος της μείωσης δεδομένων αλλά με ιδιαίτερη σημαντικότητα, ειδικά για numerical data
 Συμπλήρωση των missing data, εξομάλυνση δεδομένων με θόρυβο, αναγνώριση ή απομάκρυνση από outliers, και επίλυση ασυνεπειών στα δεδομένα. Ενοποίηση δεδομένων (Data integration) Ενοποίηση πολλαπλών βάσεων δεδομένων. Μετασχηματισμός δεδομένων (Data transformation) Κανονικοποίηση και συνάθροιση δεδομένων. Μείωση δεδομένων (Data reduction) Διατηρούνται μειωμένες αναπαραστάσεις δεδομένων σε χωρητικότητα αλλά δημιουργούνται ίδια ή παρόμοια αποτελέσματα ανάλυσης. Περικοπή δεδομένων (Data discretization) Μέρος της μείωσης δεδομένων αλλά με ιδιαίτερη σημαντικότητα, ειδικά για numerical data.")
17
Ενοποίηση δεδομένων (Data integration)
Ενώνει δεδομένα από πολλαπλές πηγές Ενοποίηση σχήματος (Schema integration) Ενοποίηση μετα-δεδομένων από διαφορετικές πηγές Ανίχνευση και επίλυση συγκρούσεων σε τιμές δεδομένων Για την ίδια οντότητα οι τιμές από διαφορετικές πηγές είναι διαφορετικές
 Ενοποίηση μετα-δεδομένων από διαφορετικές πηγές. Ανίχνευση και επίλυση συγκρούσεων σε τιμές δεδομένων. Για την ίδια οντότητα οι τιμές από διαφορετικές πηγές είναι διαφορετικές.")
18
Χρήση των Redundant Data
Το ίδιο χαρακτηριστικό μπορεί να έχει διαφορετικό όνομα σε διαφορετικές βάσεις δεδομένων Ένα χαρακτηριστικό μπορεί να συνεπάγεται από ένα άλλο Πλεονάζοντα δεδομένα μπορούν να βρεθούν με προσεκτική ανάλυση συσχετίσεων Προσεκτική ενοποίηση δεδομένων από πολλαπλές πηγές μπορεί να βοηθήσει στη μείωση των πλεοναζόντων δεδομένων

19
Βήματα προεπεξεργασίας
Καθαρισμός δεδομένων (Data cleaning) Συμπλήρωση των missing data, εξομάλυνση δεδομένων με θόρυβο, αναγνώριση ή απομάκρυνση από outliers, και επίλυση ασυνεπειών στα δεδομένα Ενοποίηση δεδομένων (Data integration) Ενοποίηση πολλαπλών βάσεων δεδομένων Μετασχηματισμός δεδομένων (Data transformation) Κανονικοποίηση και συνάθροιση δεδομένων Μείωση δεδομένων (Data reduction) Διατηρούνται μειωμένες αναπαραστάσεις δεδομένων σε χωρητικότητα αλλά δημιουργούνται ίδια ή παρόμοια αποτελέσματα ανάλυσης Περικοπή δεδομένων (Data discretization) Μέρος της μείωσης δεδομένων αλλά με ιδιαίτερη σημαντικότητα, ειδικά για numerical data
 Συμπλήρωση των missing data, εξομάλυνση δεδομένων με θόρυβο, αναγνώριση ή απομάκρυνση από outliers, και επίλυση ασυνεπειών στα δεδομένα. Ενοποίηση δεδομένων (Data integration) Ενοποίηση πολλαπλών βάσεων δεδομένων. Μετασχηματισμός δεδομένων (Data transformation) Κανονικοποίηση και συνάθροιση δεδομένων. Μείωση δεδομένων (Data reduction) Διατηρούνται μειωμένες αναπαραστάσεις δεδομένων σε χωρητικότητα αλλά δημιουργούνται ίδια ή παρόμοια αποτελέσματα ανάλυσης. Περικοπή δεδομένων (Data discretization) Μέρος της μείωσης δεδομένων αλλά με ιδιαίτερη σημαντικότητα, ειδικά για numerical data.")
20
Μετασχηματισμός δεδομένων (Data transformation)
Smoothing απομάκρυνση θορύβου από τα δεδομένα Aggregation συνάθροιση, data cube construction Generalization concept hierarchy climbing Normalization scaled to fall within a small, specified range min-max normalization z-score normalization normalization by decimal scaling Δημιουργία νέων χαρακτηριστικών Χρησιμοποιούνται για να βελτιώσουν τη διαδικασία εξόρυξης γνώσης

21
Normalization Techniques
Σκοπός της κανονικοποίησης: η αντιστοίχιση των τιμών των δεδομένων από το διάστημα [minA, maxA] [new_minA, new_maxA] Min-max normalization: Επίσης, υπάρχουν παραλλαγές της min max κανονικοποίησης ώστε το διάστημα [new_min, new_max] να μην είναι κατ’ ανάγκη το [0,1] Decimal scaling: (όταν τα δεδομένα προέρχονται από πηγές που διαφέρουν με λογαριθμικό παράγοντα). Παράδειγμα μια πηγή έχει εύρος τιμών [0,1] και μια άλλη πηγή έχει εύρος τιμών [0, 1000]. Σε αυτήν χρησιμοποιείται η τεχνική Decimal scaling.
. Παράδειγμα μια πηγή έχει εύρος τιμών [0,1] και μια άλλη πηγή έχει εύρος τιμών [0, 1000]. Σε αυτήν χρησιμοποιείται η τεχνική Decimal scaling.")
22
Normalization: Παράδειγμα
Θεωρούμε τα δεδομένα από και έστω ότι θέλουμε να τα μετασχηματίσουμε ώστε να κυμαίνονται από 0-1. Θα χρησιμοποιήσουμε Min-max normalization Το στοιχείο 30 αντιστοιχίζεται ως εξής: s’ = (30-30)/(50-30) = 0 Το στοιχείο 50 αντιστοιχίζεται ως εξής: s’ = (50-30)/(50-30) = 1 Το ενδιάμεσο στοιχείο 35 αντιστοιχίζεται ως εξής: s’ = (35-30)/(50-30) = 5/20 = 0.25
/(50-30) = 0. Το στοιχείο 50 αντιστοιχίζεται ως εξής: s’ = (50-30)/(50-30) = 1. Το ενδιάμεσο στοιχείο 35 αντιστοιχίζεται ως εξής: s’ = (35-30)/(50-30) = 5/20 =")
23
Normalization Techniques
Z-score: Median and Median Absolute Deviation (MAD):
:")
24
Βήματα προεπεξεργασίας
Καθαρισμός δεδομένων (Data cleaning) Συμπλήρωση των missing data, εξομάλυνση δεδομένων με θόρυβο, αναγνώριση ή απομάκρυνση από outliers, και επίλυση ασυνεπειών στα δεδομένα Ενοποίηση δεδομένων (Data integration) Ενοποίηση πολλαπλών βάσεων δεδομένων Μετασχηματισμός δεδομένων (Data transformation) Κανονικοποίηση και συνάθροιση δεδομένων Μείωση δεδομένων (Data reduction) Διατηρούνται μειωμένες αναπαραστάσεις δεδομένων σε χωρητικότητα αλλά δημιουργούνται ίδια ή παρόμοια αποτελέσματα ανάλυσης Περικοπή δεδομένων (Data discretization) Μέρος της μείωσης δεδομένων αλλά με ιδιαίτερη σημαντικότητα, ειδικά για numerical data
 Συμπλήρωση των missing data, εξομάλυνση δεδομένων με θόρυβο, αναγνώριση ή απομάκρυνση από outliers, και επίλυση ασυνεπειών στα δεδομένα. Ενοποίηση δεδομένων (Data integration) Ενοποίηση πολλαπλών βάσεων δεδομένων. Μετασχηματισμός δεδομένων (Data transformation) Κανονικοποίηση και συνάθροιση δεδομένων. Μείωση δεδομένων (Data reduction) Διατηρούνται μειωμένες αναπαραστάσεις δεδομένων σε χωρητικότητα αλλά δημιουργούνται ίδια ή παρόμοια αποτελέσματα ανάλυσης. Περικοπή δεδομένων (Data discretization) Μέρος της μείωσης δεδομένων αλλά με ιδιαίτερη σημαντικότητα, ειδικά για numerical data.")
25
Μείωση δεδομένων (Data reduction)
Πρόβλημα: Μεγάλες αποθήκες δεδομένων μπορούν να έχουν terabytes δεδομένων, Πολύπλοκη ανάλυση δεδομένων και εξόρυξη γνώσης μπορεί να απαιτήσει πολύ χρόνο Λύση: Μείωση δεδομένων (Διατηρούνται μειωμένες αναπαραστάσεις δεδομένων σε χωρητικότητα αλλά δημιουργούνται ίδια ή παρόμοια αποτελέσματα ανάλυσης) Στρατηγικές: Data cube aggregation Dimension Reduction Instance Selection Value Discretization Συμπίεση δεδομένων Numerosity reduction
 Στρατηγικές: Data cube aggregation. Dimension Reduction. Instance Selection. Value Discretization. Συμπίεση δεδομένων. Numerosity reduction.")
26
Data Cube Aggregation Το χαμηλότερο επίπεδο ενός data cube Τα συναθροισμένα δεδομένα για μια ξεχωριστή οντότητα ενδιαφέροντος π.χ., ένας πελάτης σε μια εταιρία αυτοκινήτων. Πολλαπλά επίπεδα συνάθροισης σε data cubes Επιπλέον μείωση του μεγέθους των δεδομένων που θα χρησιμοποιηθούν Αναφορά σε κατάλληλα επίπεδα Χρησιμοποιούμε την λιγότερη δυνατή πληροφορία για την επίλυση του προβλήματος μας

27
Μείωση διαστάσεων Μπορεί να επιτευχθεί με δύο μεθόδους:
Επιλογή χαρακτηριστικών: Επιλογή ενός ελάχιστου πλήθους χαρακτηριστικών με τα οποία είναι δυνατή η εξαγωγή ισοδύναμων ή κοντινών αποτελεσμάτων με αυτά που θα είχαμε αν είχαμε κρατήσει όλα τα χαρακτηριστικά για ανάλυση. Ιδανικά m <<< n. Μετασχηματισμός χαρακτηριστικών: Είναι γνωστός ως Principle Component Analysis. Ο μετασχηματισμός των χαρκτηριστικών δημιουργεί ένα νέο σύνολο χαρακτηριστικών, λιγότερων διαστάσεων από το αρχικό, αλλά χωρίς μείωση των βασικών διαστάσεων. Επίσης, συχνά χρησιμοποιείται για την οπτικοποίηση των δεδομένων.

28
Instance Selection Η επιλογή περιπτώσεων (instance selection) μπορεί να επιτευχθεί με δύο τύπους μεθόδων: Sampling methods : Random Sampling - randomly select "m" instances from the "n" initial instances. Stratified Sampling - randomly select "m" instances from the "n" initial instances, such that the distribution of classes is maintain in the selected sample. Search-based methods : Search for representative instances in the data, based on some criterion and remove the remaining instances. Use Statistical measures (number of instances, mean or standard deviations) to replace redundant instances with their representative pseudo-instances.
 to replace redundant instances with their representative pseudo-instances.")
29
Συμπίεση δεδομένων Wavelet Transforms
Τεχνική που εφαρμόζεται σε ένα διάνυσμα D και το μετασχηματίζει σε ένα αριθμητικά διαφορετικό διάνυσμα D’ ίδιου μήκους Κυρίως χρησιμοποιείται για συμπίεση χρονοσειρών Παράδειγμα 2 τύπων wavelet μετασχηματισμών Daubechies μετασχηματισμός Haar μετασχηματισμός

30
Numerosity reduction Παραμετροποιήσιμες μέθοδοι
Χρησιμοποιείται ένα μοντέλο(ή μια συνάρτηση) για την εκτίμηση των δεδομένων και έτσι αποθηκεύονται μόνο οι παράμετροι του αντί των δεδομένων Log-linear μοντέλα τα οποία διατηρούν διακριτά πολυδιάστατες πιθανοτικές κατανομές Μη-παραμετροποιήσιμες μέθοδοι Ιστογράμματα Συσταδοποίηση Δειγματοληψία
 για την εκτίμηση των δεδομένων και έτσι αποθηκεύονται μόνο οι παράμετροι του αντί των δεδομένων. Log-linear μοντέλα τα οποία διατηρούν διακριτά πολυδιάστατες πιθανοτικές κατανομές. Μη-παραμετροποιήσιμες μέθοδοι. Ιστογράμματα. Συσταδοποίηση. Δειγματοληψία.")
31
Βήματα προεπεξεργασίας
Καθαρισμός δεδομένων (Data cleaning) Συμπλήρωση των missing data, εξομάλυνση δεδομένων με θόρυβο, αναγνώριση ή απομάκρυνση από outliers, και επίλυση ασυνεπειών στα δεδομένα Ενοποίηση δεδομένων (Data integration) Ενοποίηση πολλαπλών βάσεων δεδομένων Μετασχηματισμός δεδομένων (Data transformation) Κανονικοποίηση και συνάθροιση δεδομένων Μείωση δεδομένων (Data reduction) Διατηρούνται μειωμένες αναπαραστάσεις δεδομένων σε χωρητικότητα αλλά δημιουργούνται ίδια ή παρόμοια αποτελέσματα ανάλυσης Περικοπή δεδομένων (Data discretization) Μέρος της μείωσης δεδομένων αλλά με ιδιαίτερη σημαντικότητα, ειδικά για numerical data
 Συμπλήρωση των missing data, εξομάλυνση δεδομένων με θόρυβο, αναγνώριση ή απομάκρυνση από outliers, και επίλυση ασυνεπειών στα δεδομένα. Ενοποίηση δεδομένων (Data integration) Ενοποίηση πολλαπλών βάσεων δεδομένων. Μετασχηματισμός δεδομένων (Data transformation) Κανονικοποίηση και συνάθροιση δεδομένων. Μείωση δεδομένων (Data reduction) Διατηρούνται μειωμένες αναπαραστάσεις δεδομένων σε χωρητικότητα αλλά δημιουργούνται ίδια ή παρόμοια αποτελέσματα ανάλυσης. Περικοπή δεδομένων (Data discretization) Μέρος της μείωσης δεδομένων αλλά με ιδιαίτερη σημαντικότητα, ειδικά για numerical data.")
32
Περικοπή δεδομένων (Data discretization)
Τρείς τύποι χαρακτηριστικών: Nominal — values from an unordered set Ordinal — values from an ordered set Continuous — real numbers Discretization: Διαχωρισμός του πεδίου των χαρακτηριστικών σε intervals. Οι ετικέτες των intervals χρησιμοποιούνται μετά για την αντικατάσταση των δεδομένων Classification αλγόριθμοι

33
Αλγόριθμος κατηγοριοποίησης
2. Κατηγοριοποίηση Αποτελεί μια από τις βασικές εργασίες στην εξόρυξη δεδομένων Βασίζεται στην εξέταση των χαρακτηριστικών ενός αντικειμένου το όποιο βάση τα χαρακτηριστικά αυτά αντιστοιχίζεται σε ένα προκαθορισμένο σύνολο κλάσεων Αλγόριθμος κατηγοριοποίησης Μετρική ομοιότητας Αναπαράσταση δένδρων

34
Κατηγοριοποίηση Η εργασία της κατηγοριοποίησης χαρακτηρίζεται από έναν καλά καθορισμένο ορισμό των κατηγοριών(κλάσεων) και το σύνολο που χρησιμοποιείται για την εκπαίδευση του μοντέλου αποτελείται από προκατηγοριοποιημένα παραδείγματα Η βασική εργασία είναι να δημιουργηθεί ένα μοντέλο το οποίο θα μπορούσε να εφαρμοστεί για να κατηγοριοποιήσει δεδομένα που δεν έχουν ακόμα κατηγοριοποιηθεί
 και το σύνολο που χρησιμοποιείται για την εκπαίδευση του μοντέλου αποτελείται από προκατηγοριοποιημένα παραδείγματα. Η βασική εργασία είναι να δημιουργηθεί ένα μοντέλο το οποίο θα μπορούσε να εφαρμοστεί για να κατηγοριοποιήσει δεδομένα που δεν έχουν ακόμα κατηγοριοποιηθεί.")
35
Κατηγοριοποίηση Υπάρχει συνήθως περιορισμένος αριθμός κατηγοριών
Συνήθεις τεχνικές: Δέντρα Αποφάσεων (Decision Trees) Νευρωνικά Δίκτυα (Neural Networks) K-πλησιέστερων γειτόνων (k-Nearest Neighbors, k-NN) k-means Μηχανές Υποστήριξης Διανυσμάτων (Support Vector Machines, SVM) Bayesian μέθοδοι Στηρίζονται στην ιδέα της «εκπαίδευσης» με τη βοήθεια ενός υποσυνόλου δεδομένων (σύνολο εκπαίδευσης)
 Νευρωνικά Δίκτυα (Neural Networks) K-πλησιέστερων γειτόνων (k-Nearest Neighbors, k-NN) k-means. Μηχανές Υποστήριξης Διανυσμάτων (Support Vector Machines, SVM) Bayesian μέθοδοι. Στηρίζονται στην ιδέα της «εκπαίδευσης» με τη βοήθεια ενός υποσυνόλου δεδομένων (σύνολο εκπαίδευσης)")
36
Εκμάθηση Χτίζεται το μοντέλο περιγράφοντας ένα προκαθορισμένο σύνολο από κατηγορίες δεδομένων Τα δεδομένα εκπαίδευσης αναλύονται από έναν αλγόριθμο κατηγοριοποίησης για να κατασκευάσουν στη συνέχεια το μοντέλο Τα στοιχεία αυτά επιλέγονται τυχαία από ένα πληθυσμό δεδομένων και ανήκουν σε μια από τις προκαθορισμένες κατηγορίες Η κατηγορία των δειγμάτων εκπαίδευσης είναι γνωστή και το βήμα αυτό λέγεται «εποπτευόμενη μάθηση»

37
Κατηγοριοποίηση Χρησιμοποιούνται τα δοκιμαστικά δεδομένα για να υπολογίσουν την ακρίβεια του μοντέλου Αν η ακρίβεια είναι αποδεκτή το μοντέλο χρησιμοποιείται για κατηγοριοποίηση μελλοντικών δεδομένων των οποίων η κατηγοριοποίηση είναι άγνωστη

38
Δένδρα Απόφασης Χρήση της τεχνικής «διαίρει και βασίλευε» για διαίρεση του χώρου αναζήτησης σε υποσύνολα (ορθογώνιες περιοχές) Κάθε εσωτερικός κόμβος ονοματίζεται με το όνομα ενός χαρακτηριστικού Xi . Κάθε κλαδί/σύνδεση ονοματίζεται με ένα κατηγόρημα που μπορεί να εφαρμοστεί στο χαρακτηριστικό που αποτελεί το όνομα του κόμβου- πατέρα. Κάθε φύλλο ονοματίζεται με το όνομα μιας κλάσης

39
Νευρωνικά Δίκτυα Συνάρτηση Μεταφοράς, η οποία μπορεί να είναι:
Οι νευρώνες είναι το δομικό στοιχείο του δικτύου. Υπάρχουν δύο είδη νευρώνων, οι νευρώνες εισόδου και οι υπολογιστικοί νευρώνες. Οι νευρώνες εισόδου δεν υπολογίζουν τίποτα, μεσολαβούν ανάμεσα στις εισόδους του δικτύου και τους υπολογιστικούς νευρώνες. Οι υπολογιστικοί νευρώνες πολλαπλασιάζουν τις εισόδους τους με τα συναπτικά βάρη και υπολογίζουν το άθροισμα του γινομένου. Το άθροισμα που προκύπτει είναι το όρισμα της συνάρτησης μεταφοράς. Συνάρτηση Μεταφοράς, η οποία μπορεί να είναι: βηματική (step), γραμμική (linear), μη γραμμική (non-linear), στοχαστική (stochastic).
, γραμμική (linear), μη γραμμική (non-linear), στοχαστική (stochastic).")
40
K-nn Η τεχνική των κοντινότερων γειτόνων (Nearest Neighbor (NN)) είναι μια απλή προσέγγιση του προβλήματος της κατηγοριοποίησης. ένα νέο στοιχείο κατηγοριοποιείται χρησιμοποιώντας την πλειοψηφία μεταξύ των κατηγοριών από k παραδείγματα που είναι τα πιο κοντινά σε αυτό που δίνεται για να κατηγοριοποιηθεί Μια τέτοια μέθοδος παράγει συνεχείς και επικαλυπτόμενες, παρά σταθερές γειτονιές.

41
Κατηγοριοποίηση k-nn Bucketing Kd tree Περιορισμός με προβολή
Εύρεση ΝΝ Bucketing Kd tree Περιορισμός με προβολή Περιορισμός με τριγωνική ανισότητα ΝΝ σε κείμενα

42
Εφαρμογές αναζήτησης ΝΝ
Αναγνώριση προτύπων computer aided diagnosis δηλ. υποστηρίζει τους γιατρούς στην αναγνώριση ευρημάτων οπτική αναγνώριση χαρακτήρων Θεωρεία κωδικοποίησης αποκωδικοποίηση ληφθέντων σημάτων Βάσεις δεδομένων που είναι context based ανάκτηση δεδομένων Ηλεκτρονικό εμπόριο contextual advertising Στη βιοπληροφορική ταξινόμηση βιολογικών ακολουθιών σε ομάδες Spell checking εφαρμογές όπως Microsoft Word Plagiarism detection ανίχνευση αντιγραφής, ομοιότητας κειμένων

43
Μηχανές Υποστήριξης Διανυσμάτων (SVM)
Χρησιμοποιούν μια συνάρτηση πυρήνα Π.χ. συνάρτηση πυρήνα ακτινωτής βάσης όπου s είναι τα διανύσματα υποστήριξης, z είναι τα διανύσματα γνωρισμάτων των pixel ελέγχου και γ παράμετρος που καθορίζει το μέγεθος του πυρήνα το όριο απόφασης της κατηγοριοποίησης Π.χ ως όπου ns είναι το πλήθος των διανυσμάτων υποστήριξης si, li είναι οι ετικέτες των αντίστοιχων διανυσμάτων υποστήριξης, a, b παράμετροι που υπολογίζονται κατά τη διαδικασία εκμάθησης και Δ η τιμή κατωφλίου για την εξισορρόπηση των ρυθμών των ψευδώς θετικών και ψευδών αρνητικών.

44
Μηχανές Υποστήριξης Διανυσμάτων (SVM)
Οι Μηχανές Διανυσμάτων Υποστήριξης είναι μια μέθοδος μηχανικής μάθησης για δυαδικά προβλήματα ταξινόμησης. Προβάλλουν τα σημεία του συνόλου εκπαίδευσης σε έναν χώρο περισσοτέρων διαστάσεων και βρίσκουν το υπερεπίπεδο το οποίο διαχωρίζει βέλτιστα τα σημεία των δύο τάξεων. Τα άγνωστα σημεία ταξινομούνται σύμφωνα με την πλευρά του υπερεπίπεδου στην οποία βρίσκονται. Τα διανύσματα τα οποία ορίζουν το υπερεπίπεδο το οποίο χωρίζει τις δύο τάξεις ονομάζονται διανύσματα υποστήριξης (support vectors). Χαμηλό υπολογιστικό κόστος, ακόμη και στην περίπτωση μη γραμμικότητας
. Χαμηλό υπολογιστικό κόστος, ακόμη και στην περίπτωση μη γραμμικότητας.")
45
Εμφάνιση μεγάλου όγκου δεδομένων
Παραδείγματα: Image processing Spam detection Text mining DNA micro-array data Protein data …

46
Εμφάνιση μεγάλου όγκου δεδομένων
Η πολυπλοκότητα προκύπτει από: Πολλά instances (examples) Instances με πολλαπλά features (properties / characteristics) Εξαρτήσεις μεταξύ των features (correlations)
 Instances με πολλαπλά features (properties / characteristics) Εξαρτήσεις μεταξύ των features (correlations)")
47
Προεπεξεργασία δεδομένων
Επιλογή των instances: Remove identical / inconsistent / incomplete instances (e.g. reduction of homologous genes, removal of wrongly annotated genes) Μετασχηματισμός/επιλογή των features: Feature selection techniques Projection techniques (e.g. principal components analysis) Compression techniques (e.g. minimum description length)
 Μετασχηματισμός/επιλογή των features: Feature selection techniques. Projection techniques (e.g. principal components analysis) Compression techniques (e.g. minimum description length)")
48
Πλεονεκτήματα από την επιλογή των features
Πετυχαίνουμε καλύτερα αποτελέσματα κατηγοριοποίησης χρησιμοποιώντας μικρά set από features Λιγότερος θόρυβος στα δεδομένα Παρέχουμε πιο αποδοτικούς σε κόστος classifiers Λιγότερα features να λάβουμε υπόψη smaller datasets faster classifiers Αναγνώριση σχετικών (biologically) features για ένα δοθέν πρόβλημα
 features για ένα δοθέν πρόβλημα.")
49
Βήματα του Data Analysis στον Explorer του WEKA
Επιλογή αλγόριθμου Ρυθμίσεις αλγορίθμου Ρυθμίσεις sampling Ρυθμίσεις output Επιλογή class variable Ανάλυση του output

50
Μέθοδοι Κατηγοριοποίησης στο WEKA
Decision trees Hidden Markov Models (HMMs) Support vector machines Artificial Neural Networks Bayesian methods …
 Support vector machines. Artificial Neural Networks. Bayesian methods. …")
51
Δέντρα απόφασης Δοθέντος ενός συνόλου από instances (with a set of features), δημιουργείται ένα δέντρο με εσωτερικούς κόμβους τα features και με φύλλα τις classes.
, δημιουργείται ένα δέντρο με εσωτερικούς κόμβους τα features και με φύλλα τις classes.")
52
Παράδειγμα Instance Attributes / Features Class day outlook
Class day outlook temperature humidity windy Play Golf ? 1 sunny hot high FALSE no 2 TRUE 3 overcast yes 4 rainy mild 5 cool normal 6 7 8 9 10 11 12 13 14 today ?

53
Παράδειγμα: δεδομένα Independent features (attributes) Class
Instance Independent features (attributes) Class Day Outlook Temperature Humidity Windy Play Golf? 1 sunny hot high FALSE no 2 TRUE 3 overcast yes 4 rainy mild 5 cool normal 6 7 8 9 10 11 12 13 14 WEKA data file (arff format) : @relation weather.symbolic @attribute outlook {sunny, overcast, rainy} @attribute temperature {hot, mild, cool} @attribute humidity {high, normal} @attribute windy {TRUE, FALSE} @attribute play {yes, no} @data sunny,hot,high,FALSE,no sunny,hot,high,TRUE,no overcast,hot,high,FALSE,yes rainy,mild,high,FALSE,yes rainy,cool,normal,FALSE,yes rainy,cool,normal,TRUE,no overcast,cool,normal,TRUE,yes sunny,mild,high,FALSE,no sunny,cool,normal,FALSE,yes rainy,mild,normal,FALSE,yes sunny,mild,normal,TRUE,yes overcast,mild,high,TRUE,yes overcast,hot,normal,FALSE,yes rainy,mild,high,TRUE,no
 Class. Day. Outlook. Temperature. Humidity. Windy. Play Golf 1. sunny. hot. high. FALSE. no. 2. TRUE. 3. overcast. yes. 4. rainy. mild. 5. cool. normal WEKA data file (arff format) outlook {sunny, overcast, temperature {hot, mild, humidity {high, windy {TRUE, play {yes, sunny,hot,high,FALSE,no. sunny,hot,high,TRUE,no. overcast,hot,high,FALSE,yes. rainy,mild,high,FALSE,yes. rainy,cool,normal,FALSE,yes. rainy,cool,normal,TRUE,no. overcast,cool,normal,TRUE,yes. sunny,mild,high,FALSE,no. sunny,cool,normal,FALSE,yes. rainy,mild,normal,FALSE,yes. sunny,mild,normal,TRUE,yes. overcast,mild,high,TRUE,yes. overcast,hot,normal,FALSE,yes. rainy,mild,high,TRUE,no.")
54
Παράδειγμα: σύνθεση χαρακτηριστικών

55
Δέντρο απόφασης Attributes / Features Attribute Values Classes
J48 pruned tree outlook = sunny | humidity = high: no (3.0) | humidity = normal: yes (2.0) outlook = overcast: yes (4.0) outlook = rainy | windy = TRUE: no (2.0) | windy = FALSE: yes (3.0) Number of Leaves : 5 Size of the tree : 8 Attributes / Features Attribute Values Classes
 | humidity = normal: yes (2.0) outlook = overcast: yes (4.0) outlook = rainy. | windy = TRUE: no (2.0) | windy = FALSE: yes (3.0) Number of Leaves : 5. Size of the tree : 8. Attributes / Features. Attribute Values. Classes.")
56
Πειράματα Αξιολόγησης Απόδοσης
Πειράματα Αξιολόγησης Απόδοσης Data (9/10) Training Set Test Set (1/10) 10x Σταυρωτή Επικύρωση (Cross-Validation ), 10 fold ML Classifier Performance Evaluation
 Training Set. Test Set. (1/10) 10x. Σταυρωτή Επικύρωση. (Cross-Validation ), 10 fold. ML. Classifier. Performance Evaluation.")
57
Αξιολόγηση και Μετρικές

58
Μετρικές Αξιολόγησης Αccuracy Precision Recall Roc καμπύλη (Roc Curve)
The number of correctly classified instances/number of instances Precision The number of correctly classified instances of class X/number of instances classified as belonging to class X Recall The number of correctly classified instances of class X/number of instances in class X Roc καμπύλη (Roc Curve)
")
59
Μετρικές Αξιολόγησης

60
3. Συσταδοποιηση

61
Συσταδοποιηση Complete Linkage Clustering Single Linkage Clustering
Συσταδοποίηση Εύρεση ΝΝ Bucketing Kd tree Περιορισμός με προβολή Περιορισμός με τριγωνική ανισότητα ΝΝ σε κείμενα Complete Linkage Clustering Single Linkage Clustering Average Linkage Clustering Graph clustering K-means Model-based clustering Kohonen map

62
Πλησιέστερος γείτονας (Nearest Neighbor) - NN
 - NN")
63
Αλγόριθμοι συσταδοποίησης
Ιεραρχικοί (bottom-up) Συσσωρευτικοί (top-down) Διαιρετικοί Διαχωριστικοί
 Συσσωρευτικοί. (top-down) Διαιρετικοί. Διαχωριστικοί.")
64
Αλγόριθμοι συσταδοποίησης
Ιεραρχικοί (bottom-up) Συσσωρευτικοί (top-down) Διαιρετικοί Διαχωριστικοί
 Συσσωρευτικοί. (top-down) Διαιρετικοί. Διαχωριστικοί.")
65
Ιεραρχικοί συσσωρευτικοί αλγόριθμοι
Πώς θα υπολογίσουμε την απόσταση μεταξύ a και της συστάδας bc? Υπάρχουν 3 τρόποι

66
Υπολογισμός απόστασης μεταξύ a και συστάδας bc
Complete linkage clustering Μέγιστη απόσταση μεταξύ των στοιχείων κάθε συστάδας Single linkage clustering Ελάχιστη απόσταση μεταξύ των στοιχείων κάθε συστάδας Average linkage clustering Μέση απόσταση μεταξύ των στοιχείων κάθε συστάδας

67
Πότε σταματά η συσταδοποίηση?
Κριτήρια Τερματισμού Κριτήριο της Απόστασης Όταν δύο συστάδες είναι αρκετά μακριά για να συσταδοποιηθούν μεταξύ τους Κριτήριο του Αριθμού των συστάδων Όταν υπάρχει ικανοποιητικός αριθμός συστάδων

68
Graph clustering Ιεραρχικές μέθοδοι συσταδοποίησης στενά συνδεδεμένες με συσταδοποίηση βασισμένη σε γράφους Κατασκευή γράφου ομοιότητας Χρήση Minimum Spanning Tree

69
Αλγόριθμος συσταδοποίησης K-means
ξεκινά με μια τυχαία διαμέριση σε clusters και συνεχώς τοποθετεί στοιχεία στα clusters με βάση την απόσταση των στοιχείων από το κεντροειδές του cluster Κριτήριο τερματισμού: η ελαχιστοποίηση της συνάρτησης τετραγωνικού λάθους ή η μη διαφοροποίηση των clusters από κάποια επανάληψη και μετά Πολυπλοκότητα Ο(n)
")
70
Αλγόριθμος K-means Επιλογή k κεντοειδών cluster τα οποία αποτελούν και τα μόνα στοιχεία των k επιλεγμένων clusters Τοποθέτησε κάθε στοιχείο στο πιο κοντινό cluster μετά από υπολογισμό της απόστασης του σημείου από το κεντροειδές του cluster Υπολόγισε το νέο κεντροειδές Aν το κριτήριο τερματισμού δεν ικανοποιείται πήγαινε στο βήμα 2

71
Παράδειγμα υλοποίησης K-means
Βήμα 1: Έστω τα τρία χρωματισμένα στοιχεία να είναι τα αρχικά τυχαία κεντροειδή και έστω γκρι τα υπόλοιπα στοιχεία προς συσταδοποίηση Βήμα 2: Τα στοιχεία σχετίζονται με τον κοντινότερο κεντροειδές

72
Παράδειγμα υλοποίησης K-means
Βήμα 3: Τώρα τα κεντροειδή μετακινούνται στο κέντρο των αντίστοιχων συστάδων Βήμα 4: Τα βήματα 2 και 3 επαναλαμβάνονται μέχρι να ικανοποιηθεί το κριτήριο του τερματισμού