Κατέβασμα παρουσίασης
Η παρουσίαση φορτώνεται. Παρακαλείστε να περιμένετε

1
Ανάκτηση Πληροφορίας Φροντιστήριο 1 Οκτώβριος 2013

2
Περιεχόμενα Ανάκτηση Πληροφορίας Ανεστραμμένα Αρχεία Β-Δέντρα
Perfect Hashing Structures

3
Ανάκτηση Πληροφορίας

4
Ανάκτηση Πληροφορίας ΠΩΣ εκφράζουμε ανάγκες πληροφόρησης (queries)
ΠΩΣ εντοπίζουμε και ανακτούμε πληροφορίες που ικανοποιούν τις ανάγκες ΠΩΣ αξιολογούμε τα αποτελέσματα της αναζήτησης

5
Information Retrieval System
Input Document classification Processor Search strategy Documents Output queries feedback

6
Information retrieval process
ranked docs User Interface user feedback user need Text Operations (tokenization, stopwords, stemming, etc.) text DB manager Indexing Query operations query Searching Docs database Retrieved docs Index Ranking
 text. DB manager. Indexing. Query operations. query. Searching. Docs database. Retrieved docs. Index. Ranking.")
7
IR = < D, Q, F, R(qi, dj)>
Ανακεφαλαίωση IR = < D, Q, F, R(qi, dj)> D: documents Q: queries F: πλαίσιο αναπαράστασης κειμένων R: συνάφεια query qi με κείμενο dj αριθμός 0-1
> D: documents. Q: queries. F: πλαίσιο αναπαράστασης κειμένων. R: συνάφεια query qi με κείμενο dj αριθμός 0-1.")
8
Κατηγορίες Documents Δομημένα (structured) Πλήρως αδόμητα
εγγραφές, πεδία (Βάσεις Δεδομένων) Πλήρως αδόμητα ελεύθερο κείμενο Προεπεξεργασία (pre-processing) Metadata Stemming
 Πλήρως αδόμητα. ελεύθερο κείμενο. Προεπεξεργασία (pre-processing) Metadata. Stemming.")
9
Τυπικός ορισμός document
Λεξιλόγιο V, ελεγχόμενο (controlled) ή όχι όροι wi, document α συχνότητα όρου wi στο α
 ή όχι. όροι wi, document α. συχνότητα όρου wi στο α.")
10
Ανεστραμμένα Αρχεία

11
Ανεστραμμένα Αρχεία Τα ανεστραμμένα αρχεία (inverted files) αποτελούν μια διαφορετική λύση για δεικτοδότηση πεδίων τύπου συνόλου (σύνολα κειμένων). Παίρνουν το όνομά τους από το γεγονός ότι για κάθε αντικείμενο του λεξιλογίου δημιουργείται μια λίστα (ανεστραμμένη λίστα) στην οποία περιέχεται πληροφορία για τις θέσεις όπου εμφανίζεται το αντικείμενο (όρος) αυτός στη βάση (κείμενο ή έγγραφο).
 στην οποία περιέχεται πληροφορία για τις θέσεις όπου εμφανίζεται το αντικείμενο (όρος) αυτός στη βάση (κείμενο ή έγγραφο).")
12
Ανεστραμμένα Αρχεία – Παραδείγματα Χρήσης
Σε μια βάση δεδομένων εμπορικών συναλλαγών, η πληροφορία αυτή μπορεί να είναι τα αναγνωριστικά των συναλλαγών που περιέχουν το αντικείμενο. Σε βάσεις που διαχειρίζονται κείμενο, η πληροφορία μπορεί να πάρει τη μορφή του αριθμού γραμμής στους οποίους εμφανίζεται η λέξη ή τον αριθμό του κειμένου που εμφανίζεται η λέξη.

13
Δημιουργία Ανεστραμμένων Αρχείων
Αρχεία κειμένων σαρώνονται και εξάγονται διακριτικά (tokens). Τα tokens καταχωρούνται με ένα κωδικό κειμένου (Document ID) Κείμενο Α Κείμενο Β Now is the time for all good men to come to the aid of their country It was a dark and stormy night in the country manor. The time was past midnight Φάση 1
. Τα tokens καταχωρούνται με ένα κωδικό κειμένου (Document ID) Κείμενο Α. Κείμενο Β. Now is the time. for all good men. to come to the aid. of their country. It was a dark and. stormy night in. the country. manor. The time. was past midnight. Φάση 1.")
14
Δημιουργία Ανεστραμμένων Αρχείων
Φάση 2 Όταν όλα τα κείμενα σαρωθούν τότε το ανεστραμμένο αρχείο ταξινομείται.

15
Δημιουργία Ανεστραμμένων Αρχείων
Φάση 3 Οι πολλαπλοί όροι για κάθε κείμενο συνενώνονται και προστίθεται η συχνότητα εμφάνισης

16
Δημιουργία Ανεστραμμένων Αρχείων
Το αρχείο χωρίζεται σε: λεξικό (για διευκόλυνση του ψαξίματος) και εμφανίσεις. Φάση 4 Εμφανίσεις Το αρχείο χωρίζεται Λεξικό
 και. εμφανίσεις. Φάση 4. Εμφανίσεις. Το αρχείο χωρίζεται. Λεξικό.")
17
Ανεστραμμένα Αρχεία Η ακρίβεια με την οποία προσδιορίζεται η θέση αναφέρεται σαν υφή (grain) του ευρετηρίου. Για ευρετήρια ανεστραμμένου αρχείου, μπορούμε να διακρίνουμε δύο κατηγορίες σχετικές με την υφή τους: Ευρετήριο αδρής υφής (coarse grain index) Ευρετήριο λεπτής υφής (fine grain index)
 Ευρετήριο λεπτής υφής (fine grain index)")
18
Ανεστραμμένα Αρχεία Ευρετήριο αδρής υφής (coarse grain index): Σε ευρετήρια αδρής υφής, κρατείται πληροφορία μικρής λεπτομέρειας. Κάθε ανεστραμμένη λίστα κρατά μόνο τους αύξοντες αριθμούς των κειμένων στις οποίες εμφανίζεται ο αντίστοιχος όρος.
: Σε ευρετήρια αδρής υφής, κρατείται πληροφορία μικρής λεπτομέρειας. Κάθε ανεστραμμένη λίστα κρατά μόνο τους αύξοντες αριθμούς των κειμένων στις οποίες εμφανίζεται ο αντίστοιχος όρος.")
19
Ανεστραμμένα Αρχεία Ευρετήριο λεπτής υφής (fine grain index): Σε τέτοια ευρετήρια, η θέση του κάθε όρου προσδιορίζεται με μεγαλύτερη ακρίβεια. Στο προηγούμενο παράδειγμα, ένα ευρετήριο λεπτής υφής θα μπορούσε να περιλαμβάνει, εκτός από το αναγνωριστικό του κειμένου, ένα δεύτερο αριθμό που να προσδιορίζει σε ποια θέση μέσα στο κείμενο υπάρχει ο όρος.
: Σε τέτοια ευρετήρια, η θέση του κάθε όρου προσδιορίζεται με μεγαλύτερη ακρίβεια. Στο προηγούμενο παράδειγμα, ένα ευρετήριο λεπτής υφής θα μπορούσε να περιλαμβάνει, εκτός από το αναγνωριστικό του κειμένου, ένα δεύτερο αριθμό που να προσδιορίζει σε ποια θέση μέσα στο κείμενο υπάρχει ο όρος.")
20
Ανεστραμμένα Αρχεία – Λεπτή υφή
Ανεστραμμένα Αρχεία – Λεπτή υφή Μεγαλύτερο το μέγεθός του ανεστραμμένου αρχείου μεγαλύτερη ακρίβεια στον προσδιορισμό της θέσης κάθε όρου ΑΡΑ κρατείται περισσότερη πληροφορία Οι πολλαπλές εμφανίσεις ενός όρου σε ένα κείμενο Δυνατότητα άμεσης απόρριψης λανθασμένων υποψήφιων απαντήσεων (π.χ. όταν ψάχνουμε φράσεις) χωρίς να είναι απαραίτητη η πρόσβαση στο περιεχόμενο των απαντήσεων αυτών (να ανακτήσουμε το κείμενο).
 χωρίς να είναι απαραίτητη η πρόσβαση στο περιεχόμενο των απαντήσεων αυτών (να ανακτήσουμε το κείμενο).")
21
Queries Ερώτημα(Query) με ένα όρο Ερώτημα(Query) με ένα 2 όρους
Επιστρέφεται η ανεστραμμένη λίστα του όρου που ψάχνουμε. Ερώτημα(Query) με ένα 2 όρους Επιστρέφεται η τομή ανάμεσα στις δυο ανεστραμμένες λίστες των όρων που ψάχνουμε.
 με ένα 2 όρους. Επιστρέφεται η τομή ανάμεσα στις δυο ανεστραμμένες λίστες των όρων που ψάχνουμε.")
22
Ερώτημα(Query) με δυο όρους
1ος όρος some <2; 4, 5> 2ος όρος hot <2; 1, 4> Τομή some AND hot → <4> Παραδείγματα: 1ος όρος: the 2ος όρος: country 1ος όρος: a 1ος όρος: now 2ος όρος: dark

23
Β-Δέντρα (B-trees)
")
24
Κίνητρα για B-Trees Μέχρι τώρα έχουμε υποθέσει ότι μπορούμε να αποθηκεύσουμε μια ολόκληρη δομή δεδομένων στην κύρια μνήμη. Τι κάνουμε σε περίπτωση που τα δεδομένα δε χωράνε στη μνήμη; Χρησιμοποιούμε το δίσκο αλλά σε αυτή την περίπτωση η πολυπλοκότητα αποτυγχάνει.

25
Κίνητρα για B-Trees Υποθέτουμε ότι όλες οι διαδικασίες παίρνουν κατά προσέγγιση ίσο χρόνο. Αυτό δε συμβαίνει όταν παρεμβάλλεται πρόσβαση στο δίσκο. Με άλλα λόγια, μια πρόσβαση στο δίσκο παίρνει σχεδόν ίδιο χρόνο με εντολές. Αξίζει να εκτελούμε πολλές εντολές για να αποφύγουμε μία πρόσβαση στο δίσκο.

26
Κίνητρα για B-Trees Σε περιπτώσεις μεγάλου όγκου δεδομένων, καταλήγουμε σε ένα πολύ βαθύ δέντρο με πολλές διαφορετικές προσβάσεις στο δίσκο. Γνωρίζουμε πως δεν μπορούμε να βελτιώσουμε το log n για ένα binary tree Μια λύση είναι να χρησιμοποιηθούν περισσότεροι κλάδοι και έτσι λιγότερο ύψος! Όσο αυξάνονται οι διακλαδώσεις το βάθος μειώνεται

27
Ορισμός B-tree Ένα B-tree τάξης m είναι ένα m- tree (ένα δέντρο όπου κάθε κόμβος μπορεί να έχει μέχρι m παιδιά ) όπου: 1. Ο αριθμός κλειδιών στα μη φύλλα είναι ένα λιγότερο από τον αριθμό των παιδιών τους και αυτά τα κλειδιά ορίζουν τη διαμέριση των κλειδιών των παιδιών όπως σε ένα κλασσικό search tree 2. όλα τα φύλλα είναι στο ίδιο επίπεδο. 3. όλα τα μη φύλλα εκτός της ρίζας έχουν τουλάχιστον m / 2 παιδιά ( m / 2 στοιχεία). 4. Η ρίζα είναι φύλλο, ή έχει από 2 έως m παιδιά 5. Ένα φύλλο περιέχει μέχρι m – 1 κλειδιά m πάντα περιττός
. 4. Η ρίζα είναι φύλλο, ή έχει από 2 έως m παιδιά. 5. Ένα φύλλο περιέχει μέχρι m – 1 κλειδιά. m πάντα περιττός.")
28
Ένα B-Tree Ένα B-tree τάξης 5 με 26 στοιχεία 26 6 12 42 51 62 1 2 4 7
Η ρίζα έχει από 2 έως m παιδιά Ένα B-tree τάξης 5 με 26 στοιχεία 3 κλειδιά οπότε απαραίτητα το ελάχιστο 4 παιδιά 26 Τουλάχιστον m / 2 (3) παιδιά 6 12 42 51 62 1 2 4 7 8 13 15 18 25 Όλα τα φύλλα στο ίδιο επίπεδο και τα φύλλα περιέχουν μέχρι m-1(4) κλειδιά 27 29 45 46 48 53 55 60 64 70 90
 παιδιά Όλα τα φύλλα στο ίδιο επίπεδο και τα φύλλα περιέχουν μέχρι m-1(4) κλειδιά")
29
Insert σε ένα B-Tree Προσπάθεια να προστεθεί το νέο κλειδί σε ένα φύλλο Εάν υπερφορτωθεί το φύλλο, σπάμε το φύλλο στα δύο, και ανεβάζουμε το μεσαίο κλειδί στον πατέρα του. Εάν υπερφορτωθεί ο πατέρας επαναλαμβάνουμε την ίδια διαδικασία. Αυτή η στρατηγική να πρέπει να επαναληφθεί μέχρι την κορυφή. Εάν κριθεί απαραίτητο, η ρίζα σπάει στα δύο και το μεσαίο κλειδί ανεβαίνει στη νέα ρίζα.

30
Κατασκευάζοντας ένα B-tree
τα κλειδιά φθάνουν στην ακόλουθη σειρά : Θέλουμε να κατασκευάσουμε ένα B-tree τάξης 5 Τα 4 πρώτα στοιχεία πάνε στη ρίζα: Εάν βάλουμε το 5ο στοιχείο στη ρίζα παραβιάζουμε τη συνθήκη 5 Επομένως, όταν το 25 έρχεται, επιλέγουμε το μεσαίο κλειδί και φτιάχνουμε μία νέα ρίζα 1 2 8 12

31
Κατασκευάζοντας ένα B-tree
8 1 2 12 25 6, 14, 28 προστίθενται στα φύλλα : 1 2 8 12 14 6 25 28

32
Κατασκευάζοντας ένα B-tree
Προσθέτοντας το 17 στο δεξί φύλλο το υπερφορτώνουμε, και έτσι παίρνουμε το μεσαίο κλειδί , το ανεβάζουμε στη ρίζα και σπάμε το φύλλο. 8 17 1 2 6 12 14 25 28 7, 52, 16, 48 προστίθενται στα φύλλα 8 17 12 14 25 28 1 2 6 16 48 52 7

33
Κατασκευάζοντας ένα B-tree
Προσθέτοντας το 68 σπάμε το δεξιότερο φύλλο, ανεβάζουμε το 48 στη ρίζα, και προσθέτοντας το 3 σπάμε το αριστερότερο φύλλο, ανεβάζοντας το 3 στη ρίζα; 26, 29, 53, 55 πάνε στα φύλλα. 3 8 17 48 1 2 6 7 12 14 16 25 26 28 29 52 53 55 68 Η πρόσθεση του 45 σπάει το 25 26 28 29 Και ανεβάζοντας το 28 στη ρίζα , σπάμε τη ρίζα

34
Κατασκευάζοντας ένα B-tree
17 3 8 28 48 1 2 6 7 12 14 16 25 26 29 45 52 53 55 68
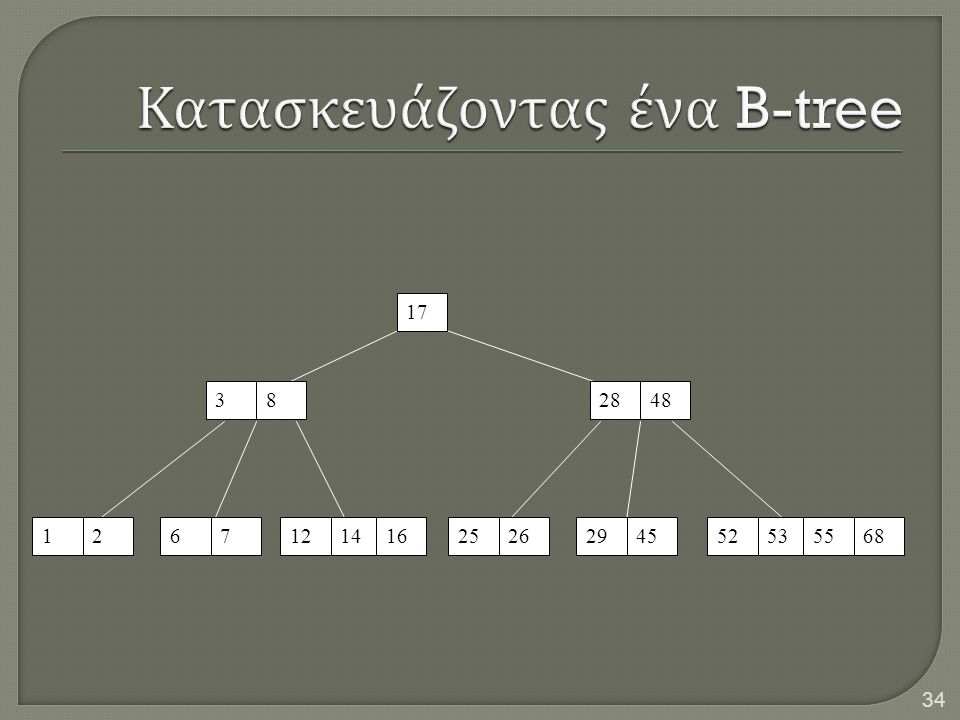
35
Διαγραφή σε ένα B-tree Κατά τη διάρκεια της εισαγωγής, το κλειδί πηγαίνει πάντα σε ένα φύλλο . Για τη διαγραφή επιθυμούμε να αφαιρέσουμε από ένα φύλλο . Οι πιθανοί τρόποι που μπορούμε να κάνουμε αυτό είναι: Εάν το κλειδί είναι σε φύλλο, και η αφαίρεσή του δεν οδηγεί σε πολύ λίγα παιδιά, τότε απλά το διαγράφουμε. Εάν το κλειδί δεν είναι σε φύλλο και ο πρόγονος ή απόγονός του είναι σε φύλλο. Τότε διαγράφουμε το κλειδί και μεταφέρουμε το κλειδί του απόγονου/πρόγονου στη θέση του διαγραμμένου κλειδιού.

36
#1: Απλή διαγραφή φύλλου
12 29 52 2 7 9 15 22 56 69 72 31 43 Delete 2:Δεδομένου ότι υπάρχουν αρκετά κλειδιά στον κόμβο, το διαγράφουμε

37
#2: Απλή διαγραφή μη-φύλλου
12 29 52 7 9 15 22 56 69 72 31 43 56 Delete 52

38
Διαγραφή σε ένα B-tree Εάν οι 1 και 2 οδηγήσουν σε έναν κόμβο φύλλων που περιέχει λιγότερο από τον ελάχιστο αριθμό κλειδιών, έπειτα πρέπει να εξετάσουμε τα γειτονικά αδέρφια του εν λόγω φύλλου : εάν ένας από αυτούς έχει περισσότερα από τον ελάχιστο αριθμό κλειδιών τότε ανεβάζουμε ένα κλειδί στον πατέρα και παίρνουμε το κλειδί του πατέρα στο φύλλο που το χρειάζεται. εάν κανένας από αυτούς δεν έχει περισσότερα από τον ελάχιστο αριθμό κλειδιών, τότε το φύλλο και ένας από τους γείτονες μπορούν να συνδυαστούν με τον κοινό πατέρα τους και το νέο φύλλο θα έχει το σωστό αριθμό φύλλων; εάν αυτό το βήμα αφήνει το γονέα με πολύ λίγα κλειδιά έπειτα επαναλαμβάνουμε τη διαδικασία μέχρι τη ρίζα, αν είναι απαραίτητο

39
#3: Αρκετά αδέρφια 12 29 7 9 15 22 69 56 31 43 Delete 22

40
#3: Αρκετά αδέρφια 12 31 69 56 43 7 9 15 29

41
#4:Πολύ λίγα κλειδιά στον κόμβο και τα αδέρφια του
Τα συνενώνουμε 12 29 56 7 9 15 22 69 72 31 43 Πολύ λίγα κλειδιά! Delete 72

42
#4:Πολύ λίγα κλειδιά στον κόμβο και τα αδέρφια του
12 29 7 9 15 22 69 56 31 43

43
Ανάλυση B-Tree Ο μέγιστος αριθμός στοιχείων σε ένα B-tree τάξης m και ύψους h: root m – 1 level 1 m(m – 1) level 2 m2(m – 1) level h mh(m – 1) Έτσι, ο συνολικός αριθμός στοιχείων είναι (1 + m + m2 + m3 + … + mh)(m – 1) = [(mh+1 – 1)/ (m – 1)] (m – 1) = mh+1 – 1
 level h mh(m – 1) Έτσι, ο συνολικός αριθμός στοιχείων είναι (1 + m + m2 + m3 + … + mh)(m – 1) = [(mh+1 – 1)/ (m – 1)] (m – 1) = mh+1 – 1.")
44
Πολυπλοκότητα πράξεων
Search/Insert/Delete παίρνουν όσο ο αριθμός των στοιχείων στο μονοπάτι από τον κόμβο στη ρίζα. Ο συνολικός αριθμός πράξεων είναι λιγότερος από το ύψος του δέντρου. Το ύψος ενός δέντρου είναι λιγότερο από log(n) όπου n είναι ο αριθμός στοιχείων σε ένα B-δέντρο.
 όπου n είναι ο αριθμός στοιχείων σε ένα B-δέντρο.")
45
Perfect Hashing Structures

46
Εισαγωγή Μία από τις βασικότερες δομές ευρετηριοποίησης σε συλλογές εγγράφων είναι τα ανεστραμμένα αρχεία (inverted files). Υπάρχουν πολλοί τρόποι για να αποθηκεύσει κανείς το λεξικό, ένας από αυτούς είναι το Perfect hashing: Οι όροι αποθηκεύονται με χρησιμοποίηση μίας συνάρτησης τέλειου κατακερματισμού (perfect hashing), αυτή η επιλογή προτιμάται για λεξικά σταθερού μεγέθους που δεν ανανεώνονται
, αυτή η επιλογή προτιμάται για λεξικά σταθερού μεγέθους που δεν ανανεώνονται.")
47
Hashing Μηχανισμός ταιριάσματος ενός συνόλου L με n στοιχεία Xj με ένα σύνολο από ακεραίους αριθμούς h(xj) που ικανοποιούν τη σχέση 0≤h(xj)≤m-1, με διπλά ταιριάσματα να επιτρέπονται. Καθιερωμένος τρόπος για την υλοποίηση ενός πίνακα αναζήτησης με καλά αποτελέσματα.
 που ικανοποιούν τη σχέση 0≤h(xj)≤m-1, με διπλά ταιριάσματα να επιτρέπονται. Καθιερωμένος τρόπος για την υλοποίηση ενός πίνακα αναζήτησης με καλά αποτελέσματα.")
48
Perfect hashing Χρησιμοποιούνται στην πράξη σε μικρούς πίνακες της κύριας μνήμης για ειδικές εφαρμογές όπως για παράδειγμα, σε μεταφραστές για αποθήκευση δεσμευμένων λέξεων, σε επεξεργασία φυσικής γλώσσας για φιλτράρισμα λέξεων υψηλής συχνότητας κτλ. Αυτού του είδους ο κατακερματισμός είναι εφικτός μόνο όταν ξέρουμε εκ των προτέρων τα κλειδιά πού θα μετασχηματίσουμε. Αν μια τέλεια συνάρτηση δεσμεύει τον ελάχιστο δυνατό χώρο, τότε λέγεται ελάχιστη(minimal).
.")
49
Minimal Perfect Hashing
Παράδειγμα: Έχουμε n κλειδιά Μια κοινή hash function είναι η εξής: H(x) = x*modm, m > n/a, a ένα βάρος (αναλογία εγγραφών σε διαθέσιμες διευθύνσεις) και m ένας αρχικά καθορισμένος αριθμός διαθέσιμων θέσεων
 = x*modm, m > n/a, a ένα βάρος (αναλογία εγγραφών σε διαθέσιμες διευθύνσεις) και m ένας αρχικά καθορισμένος αριθμός διαθέσιμων θέσεων.")
50
Minimal Perfect Hashing
Παράδειγμα: Έχουμε 1000 κλειδιά Προτείνεται η συνάρτηση h(x) = x*mod (τοποθεσίες) Δίνει βάρος a=0.7 αφού
 = x*mod1.399 (τοποθεσίες) Δίνει βάρος a=0.7 αφού.")
51
Σχεδιασμός αλγορίθμου
Πρέπει να κάνουμε map n στοιχεία σε m slots Η πιθανότητα να εισάγουμε τα n στοιχεία χωρίς επικαλύψεις είναι:

52
Minimal Perfect Hashing
Παράδειγμα: Έχουμε για κλειδιά τις 365 ημέρες Πόσοι άνθρωποι μπορούν να συλλεχθούν μαζί πριν να συμβεί 2 από αυτούς να έχουν την ίδια μέρα γενέθλια με πιθανότητα 0.5; Η απάντηση είναι 23 άνθρωποι Όταν m=365 και n=22, Π=0.524 Όταν m=365 και n=23, Π=0.493

53
Minimal Perfect Hashing
Όσο πιο μικρό είναι το a τόσο απίθανο είναι 2 κλειδιά να δείχνουν στην ίδια hash τιμή. Η αποφυγή επικαλύψεων είναι σχεδόν αδύνατη στην πραγματικότητα.

54
Minimal Perfect Hashing
Όταν η hash function έχει την επιπλέον ιδιότητα για xi και xj στο L, h(xi)=h(xj) αν και μόνο αν i=j τότε η συνάρτηση λέγεται perfect hash function Εδώ δεν υπάρχουν συγκρούσεις Όταν η hash function είναι και perfect και ταιριάζει το m με το n (m=n) καθένα από τα n κλειδιά ταιριάζει σε ένα μοναδικό ακέραιο μεταξύ 1 και n και a=1. Τότε η συνάρτηση λέγεται minimal perfect function (MPHF) Επιτυγχάνει μια πρόσβαση Δεν υπάρχουν κενά slots Όταν η hash function έχει ιδιότητα όταν xi<xj τότε h(xi)<h(xj) τότε λέγεται πως είναι order preserving
=h(xj) αν και μόνο αν i=j τότε η συνάρτηση λέγεται perfect hash function. Εδώ δεν υπάρχουν συγκρούσεις. Όταν η hash function είναι και perfect και ταιριάζει το m με το n (m=n) καθένα από τα n κλειδιά ταιριάζει σε ένα μοναδικό ακέραιο μεταξύ 1 και n και a=1. Τότε η συνάρτηση λέγεται minimal perfect function (MPHF) Επιτυγχάνει μια πρόσβαση. Δεν υπάρχουν κενά slots. Όταν η hash function έχει ιδιότητα όταν xi<xj τότε h(xi)<h(xj) τότε λέγεται πως είναι order preserving.")
55
Minimal Perfect Hashing
Έχουμε 2 hash functions h1(t), h2(t) Κάνουν map σε ακέραιους στο διάστημα 0....m-1 για κάποιες τιμές m≥n με επικαλύψεις επιτρεπτές.
, h2(t) Κάνουν map σε ακέραιους στο διάστημα 0....m-1 για κάποιες τιμές m≥n με επικαλύψεις επιτρεπτές.")
56
Minimal Perfect Hashing
1ος τρόπος: να λάβουμε κάθε χαρακτήρα σαν συμβολοσειρά radix-36 και να υπολογίσουμε τα βάρη wj, t[i] είναι το radix-36 του i χαρακτήρα του όρου t |t| είναι το μήκος σε χαρακτήρες του όρου t

57
Minimal Perfect Hashing
Έχοντας δυο διαφορετικά σύνολα από βάρη w1[i] και w2[i] για 1≤i ≤|t| έχουμε και δυο διαφορετικές hash functions h1(t), h2(t) Χρειαζόμαστε ένα πίνακα g που να κάνει map τους αριθμούς 0...m-1 στα κλειδιά 0…..n-1 (πίνακας b) h(t) = g(h1(t))+ ng(h2(t)) για ένα string t (το h(t) δείχνει την τελική θέση στη λίστα)
, h2(t) Χρειαζόμαστε ένα πίνακα g που να κάνει map τους αριθμούς 0...m-1 στα κλειδιά 0…..n-1 (πίνακας b) h(t) = g(h1(t))+ ng(h2(t)) για ένα string t (το h(t) δείχνει την τελική θέση στη λίστα)")
58
Minimal Perfect Hashing
Έχοντας ένα σύνολο από όρους Δεν χρειάζεται να αποθηκεύουμε το αλφαριθμητικό (όρο t) Χρειαζόμαστε να αποθηκεύουμε στην h(t) θέση του πίνακα Το ft Την διεύθυνση του όρου στο ανεστραμμένο αρχείο Χώρος 1.44n bits (~ or 4-20 bits per key) για MPHF nlogn bits για OPMPHF Ολοκληρωμένο παράδειγμα
 Χρειαζόμαστε να αποθηκεύουμε στην h(t) θέση του πίνακα. Το ft. Την διεύθυνση του όρου στο ανεστραμμένο αρχείο. Χώρος. 1.44n bits (~ or 4-20 bits per key) για MPHF. nlogn bits για OPMPHF. Ολοκληρωμένο παράδειγμα.")
59
Σχεδιασμός αλγορίθμου
Το μυστικό του σχεδιασμού είναι ο ορθός σχεδιασμός του πίνακα g. Δημιουργούμε τις h1(t) και h2(t) βάζοντας τυχαίες τιμές στους πίνακες w1 και w2. Δημιουργούμε γράφημα με m κόμβους και ακμές με ετικέτες την hash function (h(t)) για κάθε όρο t. Κάθε όρος t του λεξικού ανταποκρίνεται σε μια ακμή του γραφήματος και οι δυο hash functions ορίζουν σε ποιους κόμβους συνδέεται η κάθε ακμή. Ξεκινάμε έχοντας μόνο τους όρους και την h(t).
 και h2(t) βάζοντας τυχαίες τιμές στους πίνακες w1 και w2. Δημιουργούμε γράφημα με m κόμβους και ακμές με ετικέτες την hash function (h(t)) για κάθε όρο t. Κάθε όρος t του λεξικού ανταποκρίνεται σε μια ακμή του γραφήματος και οι δυο hash functions ορίζουν σε ποιους κόμβους συνδέεται η κάθε ακμή. Ξεκινάμε έχοντας μόνο τους όρους και την h(t).")
60
Σχεδιασμός αλγορίθμου

61
Τέλος 1ου Φροντιστηρίου
Αναφορές Managing Gigabytes, Compressing and Indexing Documents and Images, Witten, Moffat, Bell Χρήστος Παπαθεοδώρου,Τμήμα Αρχειονομίας – Βιβλιοθηκονομίας,Ιόνιο Πανεπιστήμιο

Παρόμοιες παρουσιάσεις














>")




