Κατέβασμα παρουσίασης
Η παρουσίαση φορτώνεται. Παρακαλείστε να περιμένετε

1
TIPURI DE MULTICALCULATOARE
PROCESOARE MASIV PARALELE SISTEME CU TRANSPUTERE CLUSTERE DE STATII DE LUCRU

2
PROCESOARE MASIV PARALELE (MPP)
Procesoarele masiv paralele MPP (Massively Parallel Processors) : -cost foarte mare (de ordinul milioanelor de dolari); -utilizari speciale (cercetari ştiinţifice, industrie pentru calcul intensiv, prelucrare a unor baze de date imense); -procesoare standard (Intel Pentium, Sun UltraSparc, DEC Alpha); -reţeaua de interconectare: de firma, foarte performanta, foarte scumpa; -capacitate enorma de I/E; -tolerante la erori (defecte): hardware şi software speciale pentru monitorizarea sistemului, detectând şi recuperând erorile.
 : -cost foarte mare (de ordinul milioanelor de dolari); -utilizari speciale (cercetari ştiinţifice, industrie pentru calcul intensiv, prelucrare a unor baze de date imense); -procesoare standard (Intel Pentium, Sun UltraSparc, DEC Alpha); -reţeaua de interconectare: de firma, foarte performanta, foarte scumpa; -capacitate enorma de I/E; -tolerante la erori (defecte): hardware şi software speciale pentru monitorizarea sistemului, detectând şi recuperând erorile.")
3
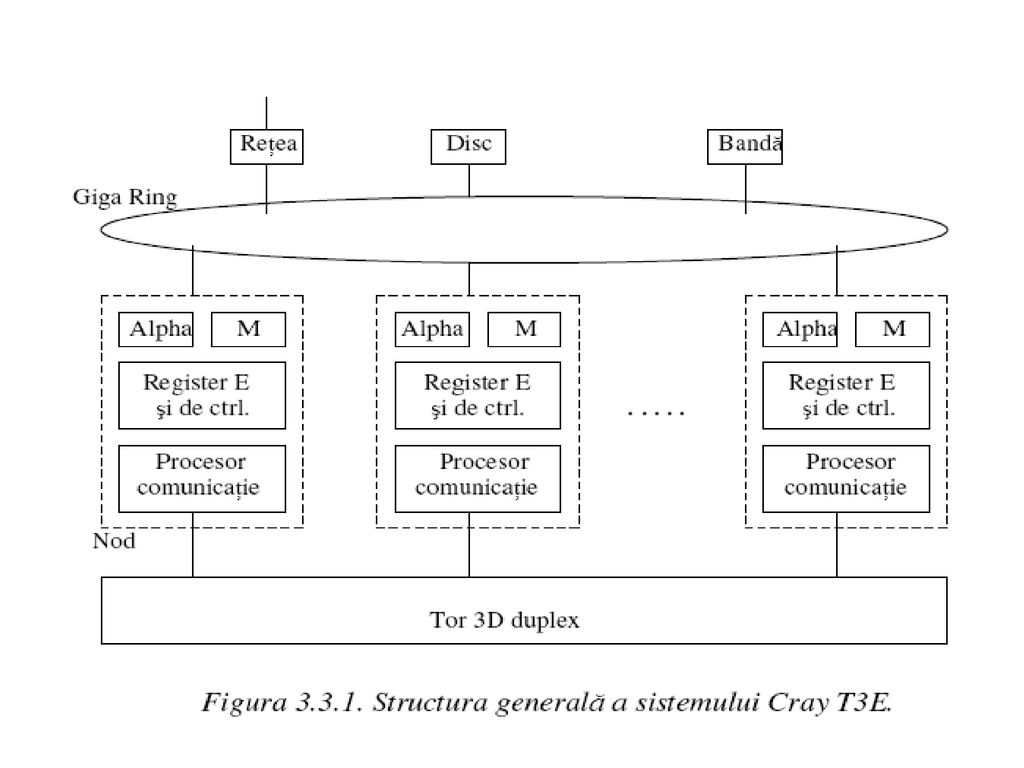
Cray T3E -continua linia de supercalculatoare începuta la mijlocul anilor ’60; -max de procesoare; -DEC Alpha 21164: -RISC superscalar (4 instrucţiuni / ciclu de ceas); -frecvenţe de 300, 450, 600 MHz; -64 de biţi; -adresele virtuale pe 43 de biţi; -adresele fizice pe 40 de biţi -> 1 TB memorie fizica; -doua niveluri de memorie cache: -nivelul 1: 8 kB pentru date şi 8 kB pentru cod; -nivelul 2: 96 kB de memorie cache date şi cod; -memoria locala RAM maxim 2 GB / procesor => 4 TB de memorie; -procesorul + circuit special “shell” (memoria, procesorul de comunicaţie şi 512 registre E speciale); -reg E: se încarca cu adrese de memorie la distanţa -> citire/scriere cuvinte sau blocuri de memorie la distanţa - nu cu instrucţiuni “load” şi “store”); -coerenţa memoriei: datele citite din memoria la distanţa nu sunt pastrate în cache.
; -frecvenţe de 300, 450, 600 MHz; -64 de biţi; -adresele virtuale pe 43 de biţi; -adresele fizice pe 40 de biţi -> 1 TB memorie fizica; -doua niveluri de memorie cache: -nivelul 1: 8 kB pentru date şi 8 kB pentru cod; -nivelul 2: 96 kB de memorie cache date şi cod; -memoria locala RAM maxim 2 GB / procesor => 4 TB de memorie; -procesorul + circuit special shell (memoria, procesorul de comunicaţie şi 512 registre E speciale); -reg E: se încarca cu adrese de memorie la distanţa -> citire/scriere cuvinte sau blocuri de memorie la distanţa - nu cu instrucţiuni load şi store ); -coerenţa memoriei: datele citite din memoria la distanţa nu sunt pastrate în cache.")
5
Conectarea nodurilor:
-tor 3D duplex (exemplu: sistem cu 512 noduri -> cub de 8x8x8 => fiecare nod având sase legaturi cu alte noduri vecine, rata de transfer 480 MB/s ); -subsistem de I/E de banda foarte larga, bazat pe comutarea de pachete, cu unul sau mai multe inele Giga Ring: pentru comunicaţia între noduri şi cu echipamentele periferice. Tipuri de noduri: -noduri utilizator (nu executa întregul S.O., ci numai un nucleu simplificat); -noduri dedicate S.O. (Unix); -noduri de rezerva: la fiecare 128 de noduri -> un nod de rezerva.
; -subsistem de I/E de banda foarte larga, bazat pe comutarea de pachete, cu unul sau mai multe inele Giga Ring: pentru comunicaţia între noduri şi cu echipamentele periferice. Tipuri de noduri: -noduri utilizator (nu executa întregul S.O., ci numai un nucleu simplificat); -noduri dedicate S.O. (Unix); -noduri de rezerva: la fiecare 128 de noduri -> un nod de rezerva.")
6
Intel/Sandia Option Red
Departamentele de Apărare şi Energie ale SUA -> program supercalculatoare MPP de TFLOPS. Intel: primul contract la Sandia National Laboratories Option Red (1TFLOPS)! (următoarele două contracte: IBM - Option Blue şi Option White). Sistemul Option Red: -4608 noduri - reţea plasă 3D; -două tipuri de plăci: -plăci Kestrel (noduri de calcul); -plăci Eagle (servicii, disc, reţea şi ca noduri de pornire). => 4536 de noduri de calcul, 32 de noduri de servicii, 32 de noduri disc, 6 noduri reţea şi 2 noduri de pornire.
! (următoarele două contracte: IBM - Option Blue şi Option White). Sistemul Option Red: noduri - reţea plasă 3D; -două tipuri de plăci: -plăci Kestrel (noduri de calcul); -plăci Eagle (servicii, disc, reţea şi ca noduri de pornire). => 4536 de noduri de calcul, 32 de noduri de servicii, 32 de noduri disc, 6 noduri reţea şi 2 noduri de pornire.")
7
Placa Kestrel: -două noduri, fiecare cu două procesoare Pentium Pro la 200 MHz; -memorie partajată de 64 MB; -magistrală locală de 64 de biţi; -interfaţă de reţea (NIC) -> modulele NIC legate între ele, dar numai unul este conectat la reţea. Placa Eagle: -două procesoare Pentium Pro şi I/E.
 -> modulele NIC legate între ele, dar numai unul este conectat la reţea. Placa Eagle: -două procesoare Pentium Pro şi I/E.")
8
-plăcile interconectate în reţea de tip grilă cu 32x38x2 noduri;
-în fiecare: cip pentru dirijare cu şase legături (est, vest nord, sud, celălalt plan şi la o placă Kestrel sau Eagle conectată la punct); -fiecare legătură: 400 MB/s în fiecare sens.
; -fiecare legătură: 400 MB/s în fiecare sens.")
9
Partiţii (din punct de vedere logic):
-nodurile de servicii: maşini universale Unix; -nodurile de calcul: aplicaţiile numerice complexe; -nodurile de I/E: 640 de discuri (>1 TB): -set de noduri de I/E pentru aplicaţii secrete; -set pentru aplicaţii civile (la un moment dat ataşat un singur set); -nodurile sistem: pornirea sistemului.
: -set de noduri de I/E pentru aplicaţii secrete; -set pentru aplicaţii civile (la un moment dat ataşat un singur set); -nodurile sistem: pornirea sistemului.")
10
Sistemele IBM SP Arhitectura IBM Power
1990: statiile de lucru superscalare si serverele din familia RISC System/6000 (RS/6000): -RISC = Reduced Instruction Set Computer; -Superscalar = unitati multiple in cip (unitati de v.m, v.f., load/store, etc.) care executa simultan instructiuni in fiecare ciclu de ceas; -POWER = Performance Optimized With Enhanced RISC. Initial Power1: 25 MHZ, cate o unitate de v.m. si de v.f., performante de 50 MFLOPS.
: -RISC = Reduced Instruction Set Computer; -Superscalar = unitati multiple in cip (unitati de v.m, v.f., load/store, etc.) care executa simultan instructiuni in fiecare ciclu de ceas; -POWER = Performance Optimized With Enhanced RISC. Initial Power1: 25 MHZ, cate o unitate de v.m. si de v.f., performante de 50 MFLOPS.")
11
SP1 =>primul sistem SP (Scalable POWER parallel). Inovatii: -suprafata ocupata redusa: masinile POWER1 puse intr-un singur dulap (rack); -mentenanta redusa: intregul sistem gestionat de administrator de la o singura consola; -comunicatie performanta interprocesor printr-o retea interna de comutatoare; -software Parallel Environment pentru dezvoltarea si rularea de aplicatii paralele (cu memorie distribuita); -SP1 POWER1: 62.5 MHz, 125 MFLOPS.
; -SP1 POWER1: 62.5 MHz, 125 MFLOPS.")
12
SP2 => 1993 cu procesoare POWER2. Caracteristici: - cate doua unitati de v.m. si v.f.; -marirea cache-ului de date; -cresterea ratei de transfer memorie – cache; -66.5 MHz, 254 MFLOPS; -set imbunatatit de instructiuni. Imbunatatirile SP2 (pentru o mai buna scalabilitate): -software performant de sistem si de gestiune a sistemului; -imbunatatirea Parallel Environment; -rata crescuta in reteaua de comutatoare.
: -software performant de sistem si de gestiune a sistemului; -imbunatatirea Parallel Environment; -rata crescuta in reteaua de comutatoare.")
13
P2SC => 1996, POWER2 SuperChip (~POWER2), dar cu 160 MHz si dublul performantelor POWER2. PowerPC => 1993, parteneriat IBM, Apple, Motorola. Include majoritatea instructiunilor POWER, in plus instructiuni pentru SMP. Varianta finala 604e. Avantaje: -CPU-uri multiple; -frecventa mai mare de ceas; -cache L2; -memorie marita, discuri, I/E. PowerPC 604e: SMP cu 4 procesoare, 332 MHz => realizarea sistemului ASC Blue-Pacific (cel mai puternic sistem la vremea respectiva).
.")
14
POWER3 => 1999, fuziune intre POWER2 uniprocesor si PowerPC multiprocesor. Avantaje: -arhitectura pe 64 biti; -frecventa mai mare de ceas; -memorie, cache, disc, I/E marite; -numar mai mare de procesoare. => ASC White (bazat pe POWER3 Nighthawk-2). POWER4 => 2001, blocul de baza: cip cu doua procesoare SMP, 4 cipuri = 1 modul cu 8 procesoare. Se pot combina module pentru masini SMP cu 16, 24, 32 procesoare. Imbunatatiri: -cresterea numarului de procesoare: maxim 32 de procesoare / nod; -frecventa de ceas peste 1 GHz; -cache L2, disc, I/E crescute; -cache L3 partajata intre module.
. POWER4. => 2001, blocul de baza: cip cu doua procesoare SMP, 4 cipuri = 1 modul cu 8 procesoare. Se pot combina module pentru masini SMP cu 16, 24, 32 procesoare. Imbunatatiri: -cresterea numarului de procesoare: maxim 32 de procesoare / nod; -frecventa de ceas peste 1 GHz; -cache L2, disc, I/E crescute; -cache L3 partajata intre module.")
15
POWER5 => introdus in 2004; asemanator POWER4, dar cateva imbunatatiri: -maxim 64 procesoare / nod; -ceas 2.5 GHz; -cache L3 mai mare, mai rapid si pe cip; -largime de banda cip-memorie 16 GB/s (4x POWER4); -multithreading (2 thread-uri simultane per procesor); -gestiune de putere dinamica (cipurile neutilizate consuma mai putin si degaja mai putina caldura). Exemplu: ASC Purple.
; -multithreading (2 thread-uri simultane per procesor); -gestiune de putere dinamica (cipurile neutilizate consuma mai putin si degaja mai putina caldura). Exemplu: ASC Purple.")
16
POWER6 => introdus in 2007

17
Dezvoltari : -POWERx evolutie in continuare: -2008 POWER7 (in dezvoltare, din aprilie 2006); -2010 POWERn... -BlueGene: arhitectura noua, peste 106 procesoare, fiecare cu 1 GFLOPS => 1 PFLOPS (BlueGene/L de la Lawrence Livermore National Laboratory a atins pentru benchmark Linpack performanta de TFLOPS).
.")
18
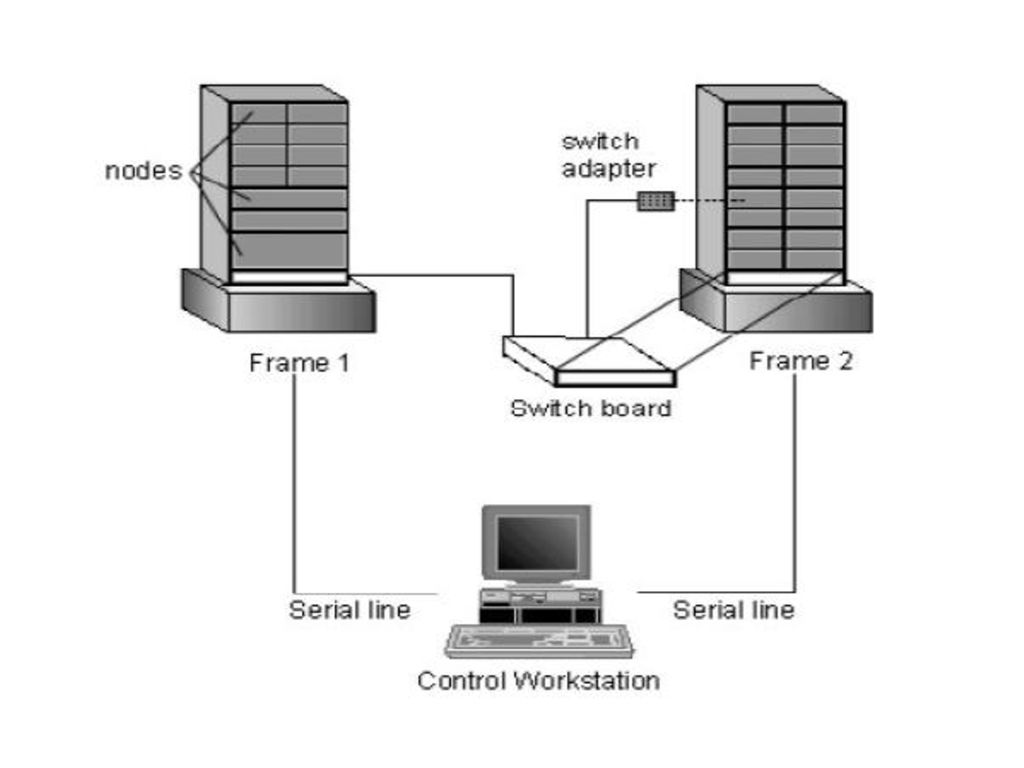
Hardware SP Componentele unui sistem SP: -„frames”: o unitate constand dintr-un rack pentru plasarea calculatoarelor, surse, echipamente de racire, comunicatii; -„nodes”: statii de lucru AIX RS/6000 impachetate pentru a fi plasate intr-un frame SP. Nu dispun de display, tastatura; -„switch”: mediul retea interna pentru comunicatie de viteza mare intre noduri. Fiecare frame are o placa de switch-uri pentru interconectarea nodurilor proprii, dar si pentru conectarea la placi de switch-uri ale altor frame-uri; -„switch adapter”: conecteaza fizic fiecare nod la reteaua de switch-uri; -„control workstation” (CWS): este o statie de lucru AIX independenta cu display si tastatura care controleaza intregul sistem.
: este o statie de lucru AIX independenta cu display si tastatura care controleaza intregul sistem.")
20
Frame-urile Un sistem SP compus din unul sau mai multe frame-uri, racire cu aer: -1-16 noduri / frame; Tipuri de noduri: -„thin”: ocupa un slot in frame; -„wide”: ocupa 2 sloturi adiacente orizontale; -„high”: ocupa 2x2 sloturi; -„mixed”.

21
Nodurile SP Un nod = masina independenta, plasata intr-o cutie, pusa in frame. Fiecare nod are hardware propriu: -I/E, inclusiv discuri; -adaptoare de retea; -memorii (placi si memorii cache); -alimentare si echipament de racire. Exista o copie a S.O. AIX pentru fiecare nod, chiar si pentru nodurile SMP.
; -alimentare si echipament de racire. Exista o copie a S.O. AIX pentru fiecare nod, chiar si pentru nodurile SMP.")
22
-nod = SMP cu 2-16 procesoare; -64 biti;
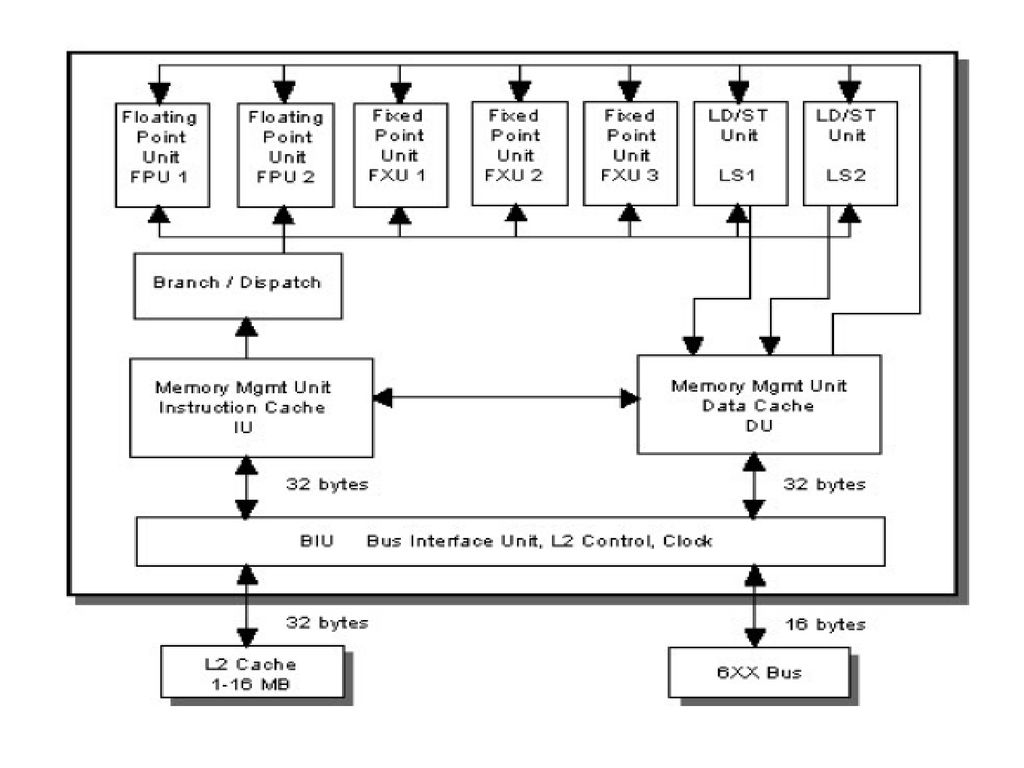
Noduri POWER3 -nod = SMP cu 2-16 procesoare; -64 biti; -4 tipuri de noduri POWER3: Winterhawk-1, Winterhawk-2, Nighthawk-1, Nighthawk-2; -frecventa MHz; -cache L1: 64 kB date, 32 kB cod; -cache L2: 4 sau 8 MB, cu magistrala proprie; -maxim 64 GB memorie partajata; -magistrale separate de date si adrese; -structura superscalara: 8 unitati de executie: -2 unitati v.m. (FPU); -3 unitati v.f. (FXU); -2 unitati load/store (LS); -unitate de ramificatie; -unitate registru de conditie.
; -3 unitati v.f. (FXU); -2 unitati load/store (LS); -unitate de ramificatie; -unitate registru de conditie.")
25
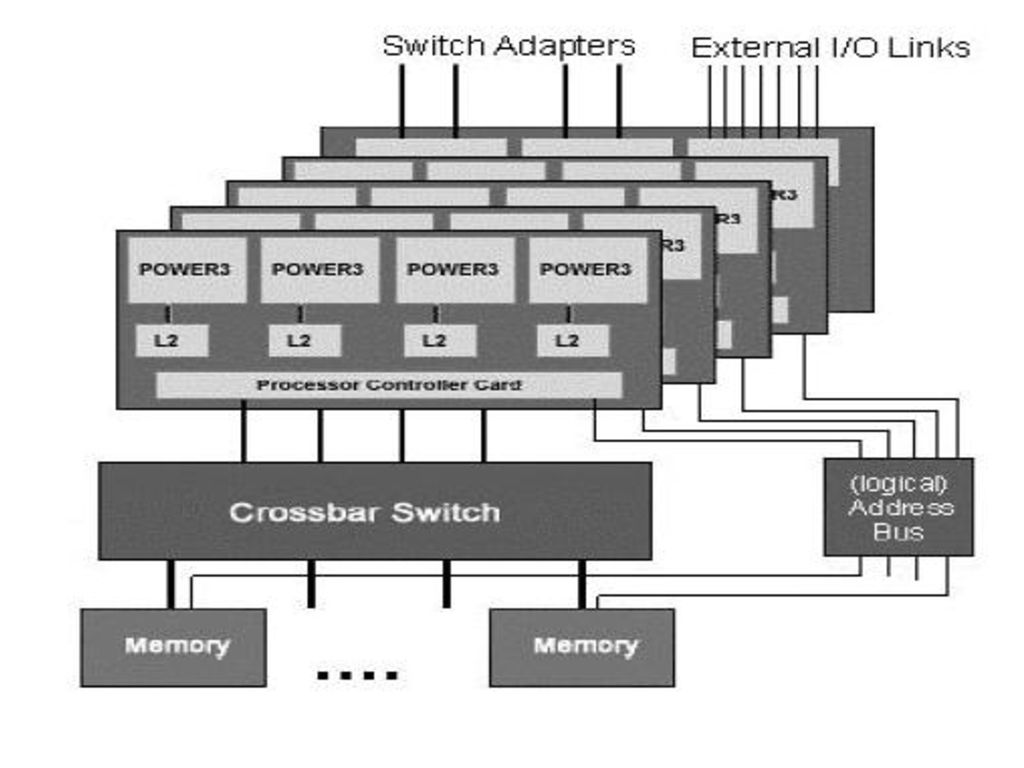
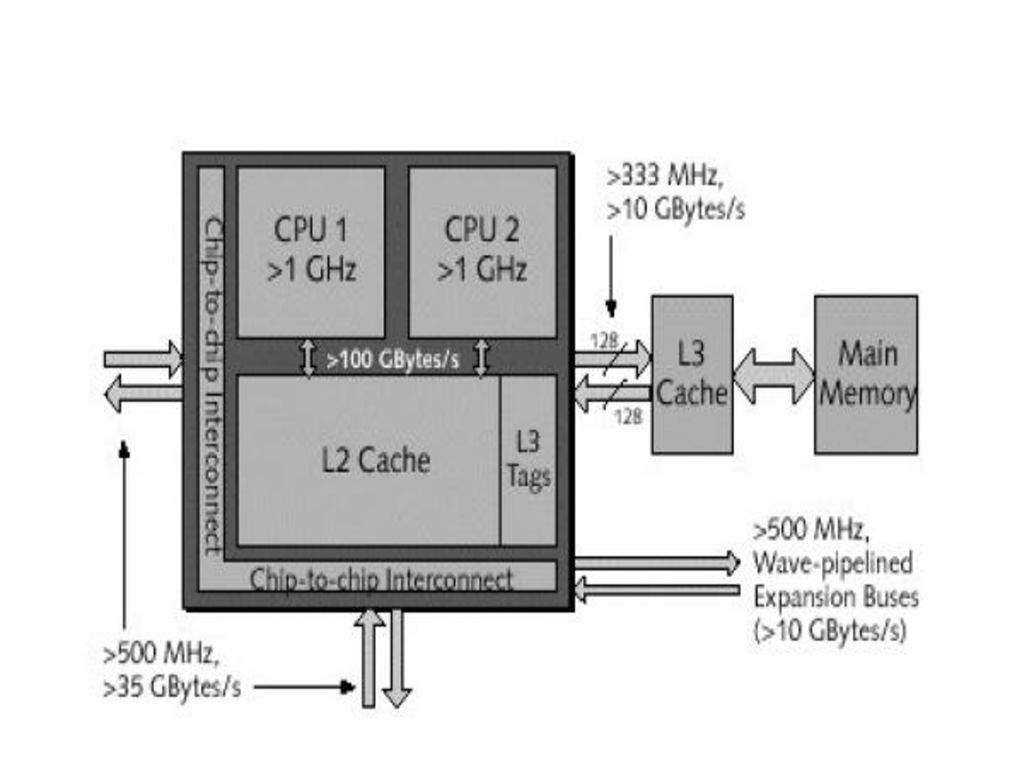
Noduri POWER4 -nod = SMP cu 8-32 procesoare; -64 biti; -frecventa ceas GHz; -blocul de baza: modul = 4 cipuri cu cate 2 procesoare (8 procesoare) => 4 module formeaza un SMP cu 32 procesoare; - cache L1: 64 kB date, 32 kB instructiuni/procesor; -L2: 1.5 MB/cip; -L3: 32 MB/cip => L2 si L3 partajate de toate cipurile din modul; -rata cip-cip: 35 GB/s; -memorie partajata de maxim 1024 GB/nod; -interfata rapida I/E (magistrala rapida Gxx) de 1.7 TB/s; -superscalar: 2 FPU, 2 FXU, 2 LS, „Branch Resolution Unit”, „Condition Register Unit”.
 => 4 module formeaza un SMP cu 32 procesoare; - cache L1: 64 kB date, 32 kB instructiuni/procesor; -L2: 1.5 MB/cip; -L3: 32 MB/cip => L2 si L3 partajate de toate cipurile din modul; -rata cip-cip: 35 GB/s; -memorie partajata de maxim 1024 GB/nod; -interfata rapida I/E (magistrala rapida Gxx) de 1.7 TB/s; -superscalar: 2 FPU, 2 FXU, 2 LS, „Branch Resolution Unit , „Condition Register Unit .")
28
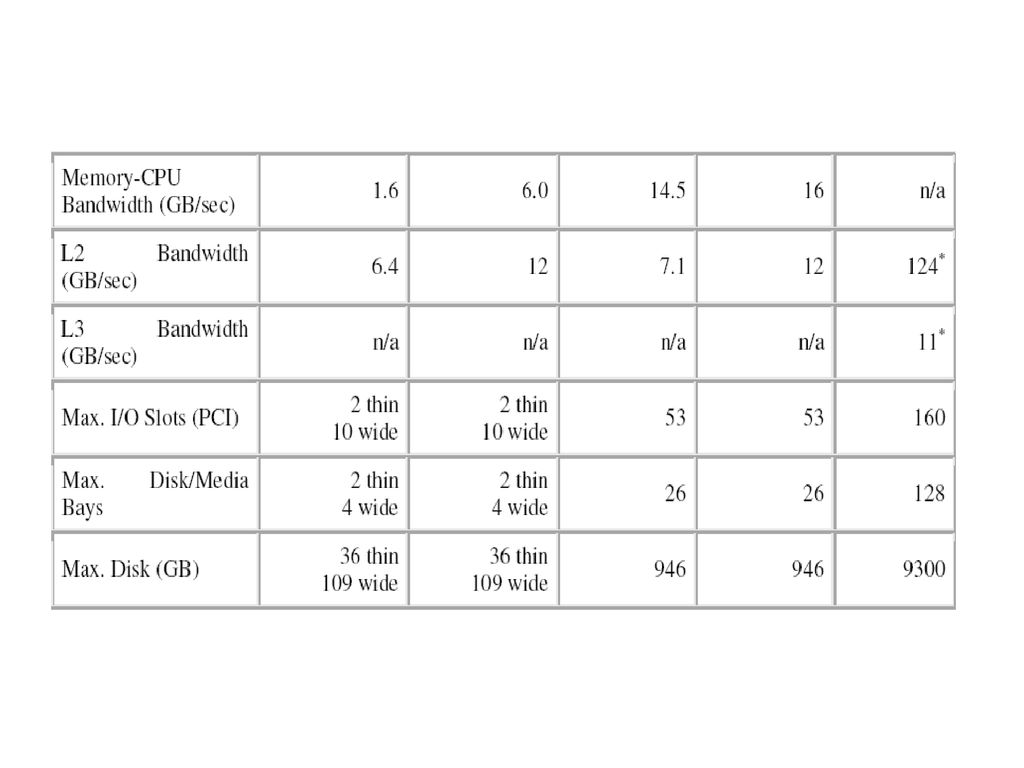
Comparatie POWER3 – POWER4

30
Noduri POWER5 -dual-core; -maxim 64 procesoare / nod; -arhitectura 64 biti; -superscalar, executie out-of-order, cu unitati functionale multiple (inclusiv doua unitati v.f. si doua unitati v.m.); -ceas 2.5 GHz; -cache: -controller cache si director L3 pe cip; -L1 date 32 KB/procesor, bloc (linie) 128 octeti, set asociativ dim. 4; -L1 cod 64 KB/procesor; -L2 1.9 MB/cip (partajata intre procesoarele duale); -L3 36 MB/cip (partajata intre procesoarele duale); -memorie GB; -largime de banda cip-memorie 16 GB/s (4x POWER4); -multithreading (2 thread-uri simultane per procesor) => aceeasi idee la Intel IA32 „hyperthreading”; -gestiune de putere dinamica (cipurile neutilizate consuma mai putin si degaja mai putina caldura).
; -ceas 2.5 GHz; -cache: -controller cache si director L3 pe cip; -L1 date 32 KB/procesor, bloc (linie) 128 octeti, set asociativ dim. 4; -L1 cod 64 KB/procesor; -L2 1.9 MB/cip (partajata intre procesoarele duale); -L3 36 MB/cip (partajata intre procesoarele duale); -memorie GB; -largime de banda cip-memorie 16 GB/s (4x POWER4); -multithreading (2 thread-uri simultane per procesor) => aceeasi idee la Intel IA32 „hyperthreading ; -gestiune de putere dinamica (cipurile neutilizate consuma mai putin si degaja mai putina caldura).")
31
Comparatie privind organizarea memoriei la POWER4 si POWER5:

32
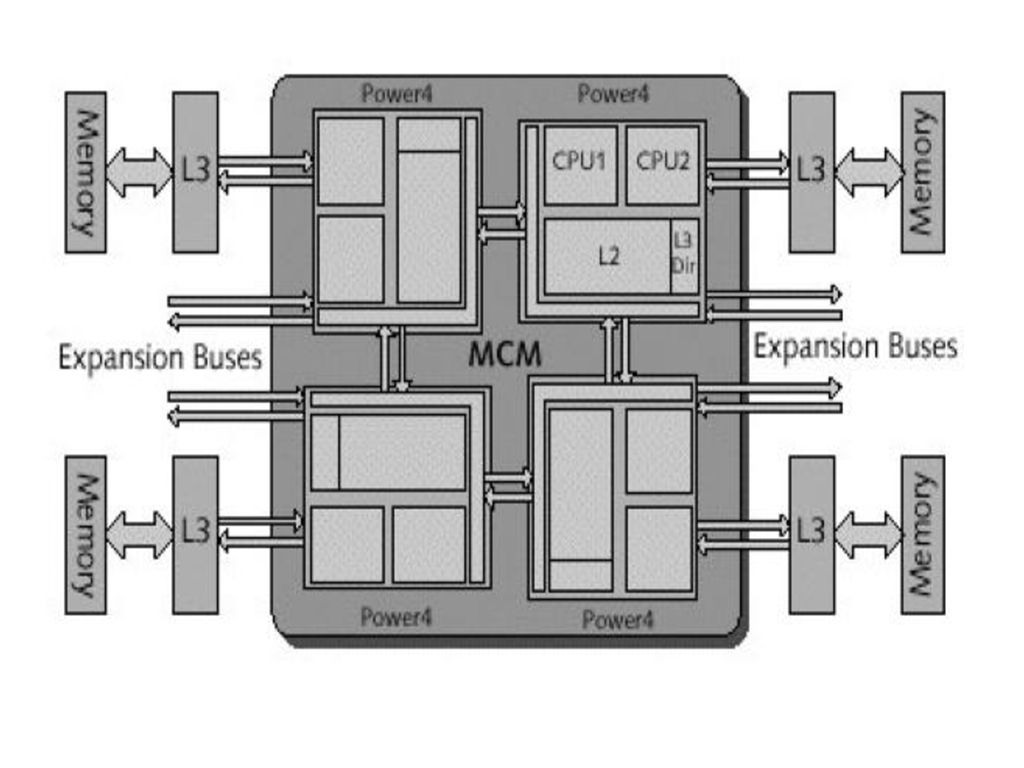
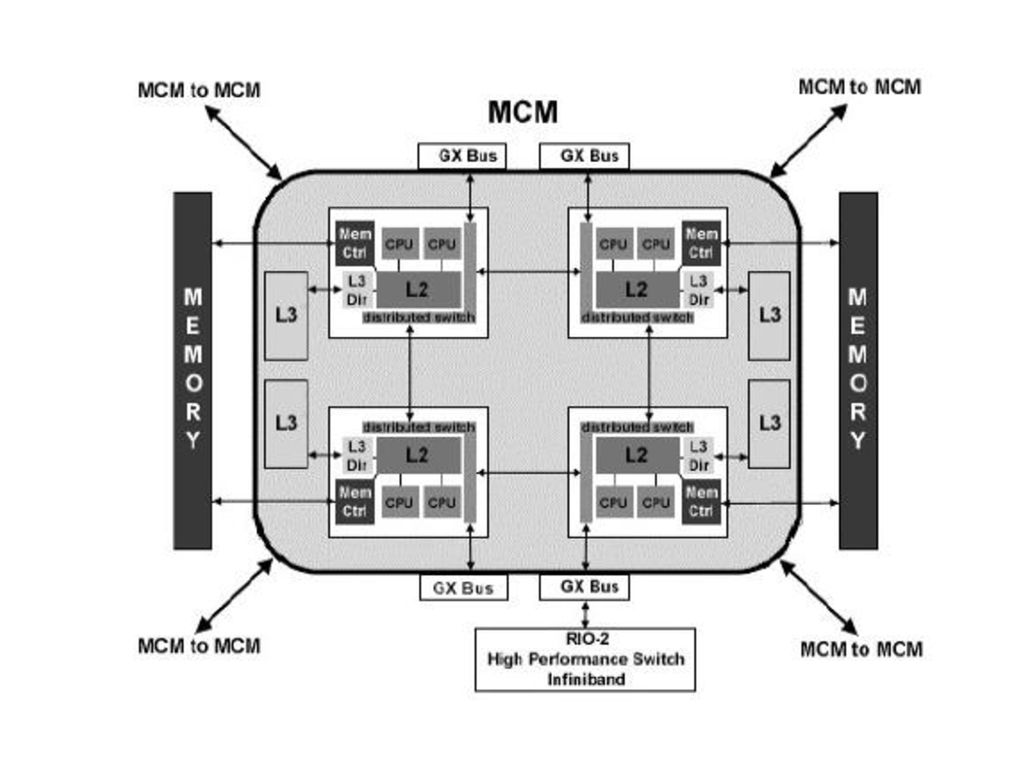
-module: -DCM („Dual-chip Module”): un cip dual core si cache L3; -QCM („Quad-chip Module”): 2 cipuri dual core si 2 cache-uri L3; -MCM („Multi-chip Module”): 4 cipuri dual core si 4 cipuri cache L3;
: 4 cipuri dual core si 4 cipuri cache L3;")
34
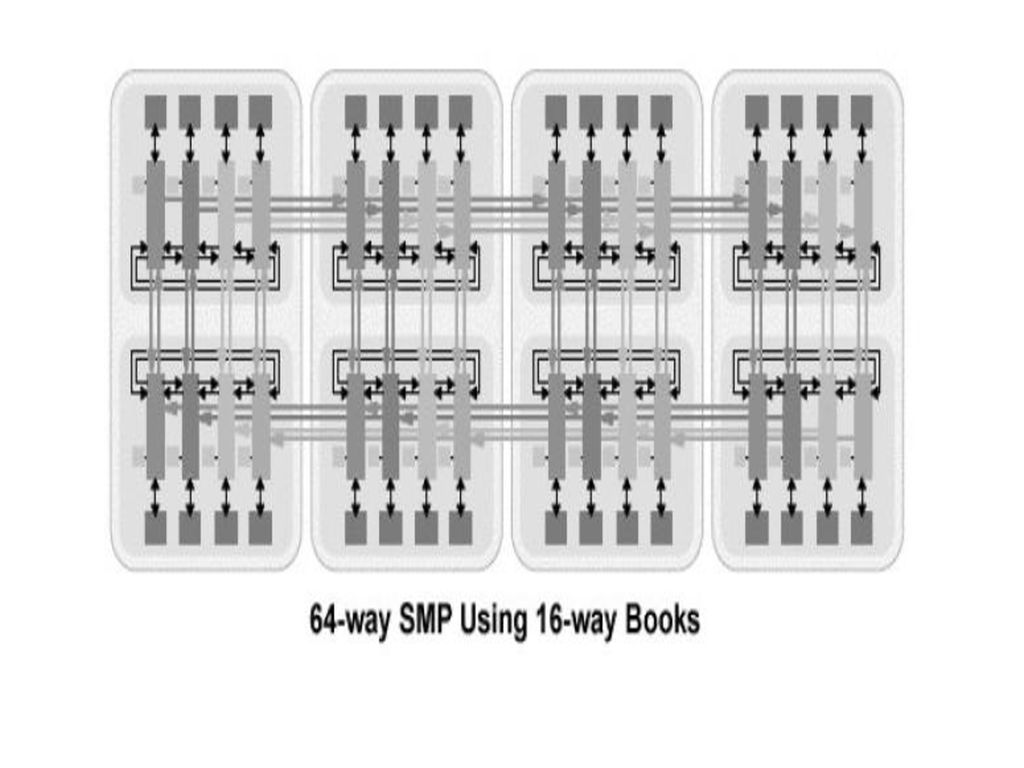
-modulele se pot combina pentru a forma SMP-uri mai mari:
-2xMCM => bloc „book” cu 16 SMP-uri; -4x”book” => 64 SMP-uri;

36
Reteaua de comutatoare
-este bidirectionala: oricare conexiune intermediara contine doua canale full-duplex; -interconectare multinivel: pentru sistemele mari (>80 noduri) se adauga switch-uri intermediare; -componentele principale: -placa de comutatoare (o placa / frame) contine 8 cipuri de switch-uri logice, cu 16 cipuri fizice (pentru toleranta la defecte) => formeaza un crossbar 4x4; -adaptorul de comunicatii: pentru fiecare nod un adaptor ocupand un slot de extensie de I/E al nodului, adaptorul cablat la placa de comutatoare in portul corespunzator.
 se adauga switch-uri intermediare; -componentele principale: -placa de comutatoare (o placa / frame) contine 8 cipuri de switch-uri logice, cu 16 cipuri fizice (pentru toleranta la defecte) => formeaza un crossbar 4x4; -adaptorul de comunicatii: pentru fiecare nod un adaptor ocupand un slot de extensie de I/E al nodului, adaptorul cablat la placa de comutatoare in portul corespunzator.")
37
Exemplu: configuratie de switch-uri pentru 64 de noduri.

38
-in functie de utilizare placa de comutatoare:
-NSB (“Node Switch Board”): 16 porturi pentru conectarea nodurilor si 16 porturi pentru conectarea la switch-uri din alte frame-uri; -ISB (“Intermediate Switch Board”): toate porturile utilizate pentru conectarea la alte placi de comutatoare Sistem cu 96/128 de noduri
: 16 porturi pentru conectarea nodurilor si 16 porturi pentru conectarea la switch-uri din alte frame-uri; -ISB ( Intermediate Switch Board ): toate porturile utilizate pentru conectarea la alte placi de comutatoare. Sistem cu 96/128 de noduri.")
39
Performantele comunicatiei:
Protocoale de comuncatie la switch-uri -US („User Space Protocol”): performante mai bune; -IP („Internet Protocol”): mai lent, utilizat pentru comunicatii de job-uri care implica sisteme IBM SP multiple. Performantele comunicatiei:
: performante mai bune; -IP („Internet Protocol ): mai lent, utilizat pentru comunicatii de job-uri care implica sisteme IBM SP multiple. Performantele comunicatiei:")
40
CWS -utilizat de administratorul sistemului pentru monitorizare, intretinere si control; -nu face parte din sistemul SP; -este un RISC System / 6000; -se conecteaza la fiecare frame prin: -linie seriala RS232C; -LAN Ethernet extern; CWS: punct singular de cadere pentru intregul sistem SP => HACWS („High Availibility CWS”), cu doua CWS (primar si backup) !
, cu doua CWS (primar si backup) !")
41
Software -S.O. AIX (Unix System V); -fiecare nod SP -> copia sa AIX (o singura copie partajata de toate procesoarele SMP ale nodului); -Parallel Environment (IBM) => mediul de dezvoltare pentru sistemele IBM SP (C/C++ si Fortran); -biblioteci matematice: -ESSL („Engineering Scientific Subroutine Library”); -PESSL („Parallel ESSL”, subset cu partea paralela a bibliotecii); -MASS („Math Acceleration Subsystem”, continand versiunile de mare performanta ale celor mai multe functii intrinseci, cu versiune scalara si versiune vectoriala).
 => mediul de dezvoltare pentru sistemele IBM SP (C/C++ si Fortran); -biblioteci matematice: -ESSL („Engineering Scientific Subroutine Library ); -PESSL („Parallel ESSL , subset cu partea paralela a bibliotecii); -MASS („Math Acceleration Subsystem , continand versiunile de mare performanta ale celor mai multe functii intrinseci, cu versiune scalara si versiune vectoriala).")
42
Blue Gene/L Blue Gene = supercalculator masiv paralel bazat pe tehnologia IBM sistem-pe-un-cip (SoC: system-on–a-chip). -configuratie maxima : noduri biprocesor, performanta de 360 TFLOPS. -tehnologie de integrare de nivel foarte inalt; -experienta altor sisteme de scop special (exemplu: QCDSP – „quantum chromodynamics on digital signal processors”): foarte bun raport performanta/cost pentru un domeniu restrans de probleme.
: foarte bun raport performanta/cost pentru un domeniu restrans de probleme.")
43
=> Consum scazut de putere!
Eficienta pe unitatea de putere consumata: (albastru=IBM, negru=alte masini SUA, rosu=masini Japonia) Un supercalculator cu procesoare conventionale de 360 Tflops => consuma aproximativ MW.
 Un supercalculator cu procesoare conventionale de 360 Tflops => consuma aproximativ MW.")
44
Alt criteriu la proiectare: reteaua de interconectare => scalare eficienta (din p.d.v. al performantei si impachetarii). Reteaua: -mesaje foarte mici (pana la 32 de octeti); -suport hardware pentru operatii colective (broadcast, reducere, etc.) Alt element: sistemul software si monitorizarea => modelul de programare transfer de mesaje, cu memorie distribuita (biblioteca MPI., disponibila in limbajele C, C++ si Fortran). Sistemul destinat in mod special unor aplicatii: -simularea fenomenelor fizice; -prelucrarea datelor in timp real; -analiza offline de date.
; -suport hardware pentru operatii colective (broadcast, reducere, etc.) Alt element: sistemul software si monitorizarea => modelul de programare transfer de mesaje, cu memorie distribuita (biblioteca MPI., disponibila in limbajele C, C++ si Fortran). Sistemul destinat in mod special unor aplicatii: -simularea fenomenelor fizice; -prelucrarea datelor in timp real; -analiza offline de date.")
45
Componentele sistemului
-maxim de noduri, fiecare nod = ASIC cu doua procesoare si 9 DDR-SDRAM-uri (maxim 18); -nodurile interconectate prin cinci retele (c. m. importanta: retea tor tridimensionala 64x32x32); -interconectarea este virtual simetrica (un nod poate comunica cu nodurile vecine de pe aceeasi placa sau intr-un alt dulap cu aceeasi rata si aproape aceeasi latenta). -impachetarea sistemului: 512 noduri de prelucrare cu o rata de varf de 5.6 Gflops pe o placa de 20x25 in („midplane”). Cele doua procesoare dintr-un nod pot opera intr-unul din doua moduri: -„virtual node mode”: fiecare procesor isi gestioneaza comunicatiile proprii; -„communication coprocessor mode”: un procesor este dedicat pentru comunicatii si celalalt pentru calcule.
; -nodurile interconectate prin cinci retele (c. m. importanta: retea tor tridimensionala 64x32x32); -interconectarea este virtual simetrica (un nod poate comunica cu nodurile vecine de pe aceeasi placa sau intr-un alt dulap cu aceeasi rata si aproape aceeasi latenta). -impachetarea sistemului: 512 noduri de prelucrare cu o rata de varf de 5.6 Gflops pe o placa de 20x25 in („midplane ). Cele doua procesoare dintr-un nod pot opera intr-unul din doua moduri: -„virtual node mode : fiecare procesor isi gestioneaza comunicatiile proprii; -„communication coprocessor mode : un procesor este dedicat pentru comunicatii si celalalt pentru calcule.")
46
-noduri de I/E pentru comunicatia cu sistemul de fisiere;
-calculator host extern (sau chiar doua): pentru sistemul de fisiere, compilare, diagnostic, analiza si service. -gestionarea de utilizatori multipli simultan: partitionarea spatiului masinii astfel incat fiecare utilizator sa dispuna de un set dedicat de noduri pentru aplicatia sa, inclusiv resurse dedicate de retea. Partitionarea: prin cipuri de legatura („link chips”). Cip de legatura = ASIC cu doua functii: -comanda semnalele prin cabluri intre placi, refacand forma semnalelor distorsionate de cablurile lungi; -redirectioneaza semnalele intre diferite porturi => partitionarea sistemului BG/L in mai multe sisteme logice separate.
: pentru sistemul de fisiere, compilare, diagnostic, analiza si service. -gestionarea de utilizatori multipli simultan: partitionarea spatiului masinii astfel incat fiecare utilizator sa dispuna de un set dedicat de noduri pentru aplicatia sa, inclusiv resurse dedicate de retea. Partitionarea: prin cipuri de legatura („link chips ). Cip de legatura = ASIC cu doua functii: -comanda semnalele prin cabluri intre placi, refacand forma semnalelor distorsionate de cablurile lungi; -redirectioneaza semnalele intre diferite porturi => partitionarea sistemului BG/L in mai multe sisteme logice separate.")
47
Link chip: 6 porturi; -porturile A si B conectate direct la nodurile dintr-un midplane; -porturile C, D, E si F conectate la cabluri => se pot conecta oricare doua porturi intre ele.

48
O posibila partitionare a sistemului:
(liniile = cabluri conectand midplane-urile prin intermediul cipurilor de legatura, partitiile utilizatorilor prin culori diferite)
")
49
Retelele Blue Gene/L Tor 3D : pentru majoritatea aplicatiilor de transfer de mesaje (comunicarea oricarui nod cu oricare nod). Fiecare nod conectat la sase vecini imediati. Latenta hardware: 100 ns/nod => in configuratie max. 64K noduri (64x32x32) in cazul c.m.defavorabil se tranziteaza = 64 noduri => latenta = 6.4 μs.
. Fiecare nod conectat la sase vecini imediati. Latenta hardware: 100 ns/nod => in configuratie max. 64K noduri (64x32x32) in cazul c.m.defavorabil se tranziteaza = 64 noduri => latenta = 6.4 μs.")
50
Retea colectiva ("collective network") se extinde peste intreaga masina BG/L:
-un nod -> toate (broadcast) sau un nod -> subset de noduri (latenta<5 μs); -fiecare legatura are o rata de 2.8 Gb/s (atat pentru transmisie cat si pentru receptie). -operatii intregi de reducere (min, max, suma, sau-biti, si-biti, sau-ex-biti) implementate cu hardware aritmetic si logic inclus in reteaua colectiva => cresterea vitezei de executie (intarzieri < de zeci-100 de ori decat in alte supercalculatoare tipice) a aplicatiilor cu operatii colective (exemplu: insumare globala).
 sau un nod -> subset de noduri (latenta<5 μs); -fiecare legatura are o rata de 2.8 Gb/s (atat pentru transmisie cat si pentru receptie). -operatii intregi de reducere (min, max, suma, sau-biti, si-biti, sau-ex-biti) implementate cu hardware aritmetic si logic inclus in reteaua colectiva => cresterea vitezei de executie (intarzieri < de zeci-100 de ori decat in alte supercalculatoare tipice) a aplicatiilor cu operatii colective (exemplu: insumare globala).")
51
Reteaua colectiva: -pentru broadcast (mai performant decat daca s-ar utiliza reteaua tor); -operatie de adunare in virgula mobila, dar in doua treceri (necesita 10 μs): la primul pas se obtine maximul dintre exponenti, iar la al doilea pas se insumeaza toate mantisele deplasate; -transferarea fisierelor catre nodurile de I/E (identice cu nodurile procesor, cu diferenta ca reteaua Gigabit Ethernet este conectata in exterior la plasa de switch-uri externe utilizate pentru conectivitatea sistemului de fisiere); -routarea este statica (fiecare nod contine o tabela statica de routare); -hardware-ul suporta doua canale virtuale permitand operatii de evitare a blocarii intre doua comunicatii independente.
: la primul pas se obtine maximul dintre exponenti, iar la al doilea pas se insumeaza toate mantisele deplasate; -transferarea fisierelor catre nodurile de I/E (identice cu nodurile procesor, cu diferenta ca reteaua Gigabit Ethernet este conectata in exterior la plasa de switch-uri externe utilizate pentru conectivitatea sistemului de fisiere); -routarea este statica (fiecare nod contine o tabela statica de routare); -hardware-ul suporta doua canale virtuale permitand operatii de evitare a blocarii intre doua comunicatii independente.")
52
-micsoreaza considerabil intarzierea in cadrul operatiilor globale;
Reteaua bariera („barrier network”): -micsoreaza considerabil intarzierea in cadrul operatiilor globale; -contine patru canale independente fiind -> functie logica globala peste toate nodurile; => semnalele individuale de la noduri sunt preluate in hardware si propagate in cadrul unei structuri de tip arbore catre radacina, iar rezultatul este propagat inapoi la noduri: -operatie SI globala = bariera globala; -operatie SAU globala = intrerupere globala cand intreaga masina sau numai un subset trebuie oprit (exemplu: pentru diagnostic); -pentru 64 k noduri intarzierea 1.5 μs.
: -micsoreaza considerabil intarzierea in cadrul operatiilor globale; -contine patru canale independente fiind -> functie logica globala peste toate nodurile; => semnalele individuale de la noduri sunt preluate in hardware si propagate in cadrul unei structuri de tip arbore catre radacina, iar rezultatul este propagat inapoi la noduri: -operatie SI globala = bariera globala; -operatie SAU globala = intrerupere globala cand intreaga masina sau numai un subset trebuie oprit (exemplu: pentru diagnostic); -pentru 64 k noduri intarzierea 1.5 μs.")
53
Reteaua sistem de control („control system network”):
-in configuratia de 64 k noduri contine peste de dispozitive terminale (ASIC-uri, senzori de temperatura, surse de curent, diode luminiscente, ventilatoare, etc) => trebuie monitorizate. -monitorizarea cu un calculator extern (nod de serviciu), parte a calculatorului gazda; -accesul nodului de serviciu la dispozitivele terminale: prin retea intranet bazata pe Ethernet. Cu un FPGA pachetele Ethernet sunt convertite in format serial JTAG pentru accesul la fiecare nod => control simplu si eficient. JTAG permite accesul chiar si la registrele fiecarui procesor prin rularea pe host a software-ului IBM Risc Watch.
 => trebuie monitorizate. -monitorizarea cu un calculator extern (nod de serviciu), parte a calculatorului gazda; -accesul nodului de serviciu la dispozitivele terminale: prin retea intranet bazata pe Ethernet. Cu un FPGA pachetele Ethernet sunt convertite in format serial JTAG pentru accesul la fiecare nod => control simplu si eficient. JTAG permite accesul chiar si la registrele fiecarui procesor prin rularea pe host a software-ului IBM Risc Watch.")
54
JTAG (Joint Test Action Group) este standardul IEEE 1149
JTAG (Joint Test Action Group) este standardul IEEE (standard numit si „Standard Test Access Port and Boundary-Scan Architecture”). Interfata JTAG : 4/5 pini adaugati unui cip => cipuri multiple de pe o placa avand inlantuite liniile lor JTAG pot fi testate pe baza unui protocol serial prin conectarea numai la un singur port JTAG a dispozitivului de test. Pinii portului sunt: -TDI (Test Data In) -TDO (Test Data Out) -TCK (Test Clock) -TMS (Test Mode Select) -TRST (Test Reset) optional.
 este standardul IEEE (standard numit si „Standard Test Access Port and Boundary-Scan Architecture ). Interfata JTAG : 4/5 pini adaugati unui cip => cipuri multiple de pe o placa avand inlantuite liniile lor JTAG pot fi testate pe baza unui protocol serial prin conectarea numai la un singur port JTAG a dispozitivului de test. Pinii portului sunt: -TDI (Test Data In) -TDO (Test Data Out) -TCK (Test Clock) -TMS (Test Mode Select) -TRST (Test Reset) optional.")
55
Reteaua Ethernet Gigabit
-nodurile de I/E au interfata Ethernet Gigabit -> accesul la switch-urile Ethernet externe; -switch-urile: conectivitate noduri de I/E - sistem de fisiere extern; -numarul de noduri de I/E este configurabil, cu un raport maxim: (noduri de I/E) / (noduri de calcul) = 1:8 -daca se configureaza sistemul la un raport de 1:64 => 1024 noduri de I/E => rata de transfer > 1 Tb/s.
 / (noduri de calcul) = 1:8. -daca se configureaza sistemul la un raport de 1:64 => 1024 noduri de I/E => rata de transfer > 1 Tb/s.")
56
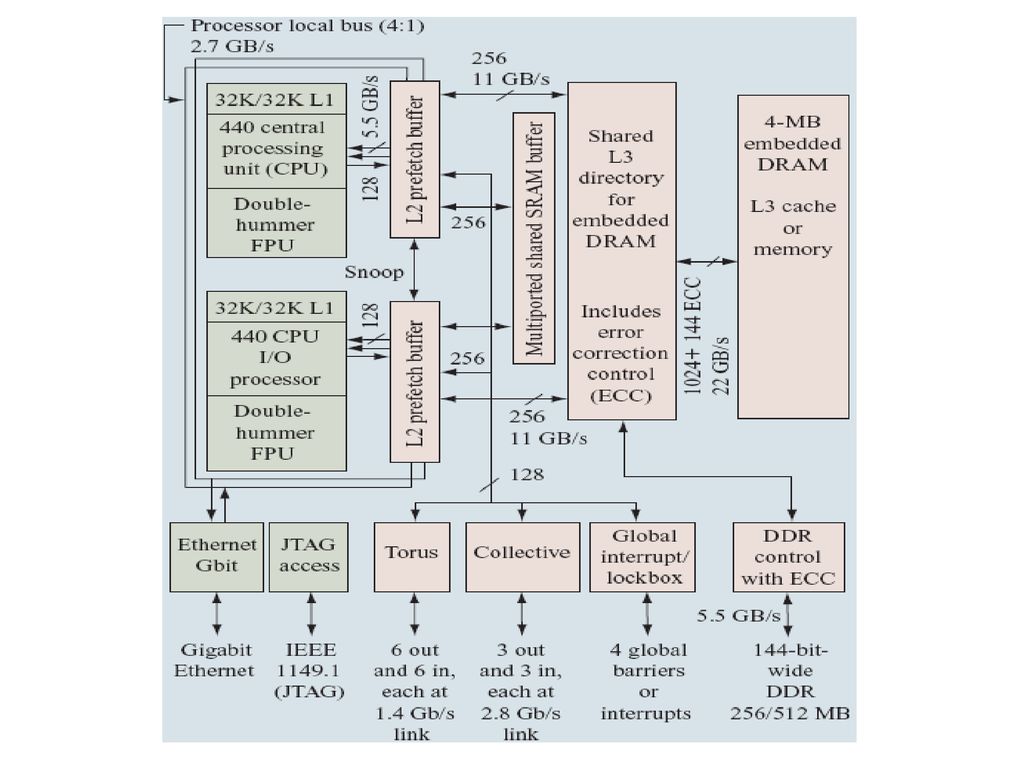
Nodul Blue Gene/L -se bazeaza pe BLC ASIC (SoC cu proces 130 nm CMOS), continand: doua core-uri IBM PowerPC 440 (PPC440), un core virgula mobila pentru fiecare procesor, controler integrat de memorie DDR externa, adaptor Gigabit Ethernet si toate controalele si bufferele retelelor colectiva si tor; -cele doua procesoare sunt simetrice (ca design, performanta si acces la resurse); -in aplicatii cu transfer simplu de mesaje se pot utiliza ambele procesoare (aplicatii cu raport crescut calcule/I-E sau cele avand comunicatii cu vecinii imediati); -in alte aplicatii un procesor dedicat transferului de mesaje, iar celalalt pentru calcule.
, continand: doua core-uri IBM PowerPC 440 (PPC440), un core virgula mobila pentru fiecare procesor, controler integrat de memorie DDR externa, adaptor Gigabit Ethernet si toate controalele si bufferele retelelor colectiva si tor; -cele doua procesoare sunt simetrice (ca design, performanta si acces la resurse); -in aplicatii cu transfer simplu de mesaje se pot utiliza ambele procesoare (aplicatii cu raport crescut calcule/I-E sau cele avand comunicatii cu vecinii imediati); -in alte aplicatii un procesor dedicat transferului de mesaje, iar celalalt pentru calcule.")
58
-„Double hummer FPU” = doua unitati FPU => performnata de varf de patru operatii v.m./ciclu;
-PPC440 = implementare performanta superscalara a arhitecturii de 32 biti Book-E Enhanced PowerPC Architecture, la 700 MHz (1.4 G operatii/sec) si 2.8 Gflops. Caracteristici: -microarhitectura in banda de asamblare 7 segmente; -fetch instructiuni dual; -planificare out-of-order; -predictie dinamica a ramificatiilor pe baza unei tabele BHT („branch history table”); -trei benzi de asamblare independente: banda load/store, banda simpla intregi si banda combinata intregi, sistem si ramificatie; -fisier 32x32 de registre de scop general (GPR), cu 6 porturi de citire si 3 porturi de scriere; -unitati de inmultire si inmultire-adunare cu rata de un singur ciclu; -cache-uri L1 independente de 32 KB de date si cod, avand linie (bloc) de 32 octeti si asociativitate de dimensiune 64, suportand functionare in mod „write-back” si „write-through”; -trei interfete independente de 128 de biti pentru citire instructiuni, citire date si scriere date („processor local bus” PLB).
 si 2.8 Gflops. Caracteristici: -microarhitectura in banda de asamblare 7 segmente; -fetch instructiuni dual; -planificare out-of-order; -predictie dinamica a ramificatiilor pe baza unei tabele BHT („branch history table ); -trei benzi de asamblare independente: banda load/store, banda simpla intregi si banda combinata intregi, sistem si ramificatie; -fisier 32x32 de registre de scop general (GPR), cu 6 porturi de citire si 3 porturi de scriere; -unitati de inmultire si inmultire-adunare cu rata de un singur ciclu; -cache-uri L1 independente de 32 KB de date si cod, avand linie (bloc) de 32 octeti si asociativitate de dimensiune 64, suportand functionare in mod „write-back si „write-through ; -trei interfete independente de 128 de biti pentru citire instructiuni, citire date si scriere date („processor local bus PLB).")
59
PPC440

60
Sistemul de memorie -ierarhia de cache pe-cip, memorie principala externa cipului si suport pe-cip pentru comunicatia intre cele doua procesoare. Pentru BG/L de 64 k noduri fiecare nod are 512 MB de memorie fizica (partajata intre cele doua procesoare), in total 32 TB. -cache-ul L1 in core-ul PPC440; -L2 (L2R si L2W) este foarte mic (2KB): serveste ca buffere prefetch si write-back pentru datele L1; -L3 este mare (4MB) => rata mare si latenta de acces mica; -memoria principala:DDR-SDRAM .
, in total 32 TB. -cache-ul L1 in core-ul PPC440; -L2 (L2R si L2W) este foarte mic (2KB): serveste ca buffere prefetch si write-back pentru datele L1; -L3 este mare (4MB) => rata mare si latenta de acces mica; -memoria principala:DDR-SDRAM .")
61
Software Schema arhitecturala de nivel inalt:

62
-65536 noduri de calcul si 1024 noduri de I/E;
-reteaua Gigabit Ethernet (functionala) conecteaza blocul de calcul la: -un nod de serviciu (pentru controlul masinii); -nodurile front-end (unde utilizatorii compileaza, lanseaza si interactioneaza cu aplicatiile lor); - servere paralele de fisiere; -reteaua Gigabit Ethernet (control): nod de serviciu - bloc de calcul (control direct al hardware-ului); -nodurile de calcul: impartite in 1024 seturi logice de prelucrare ( psets - „processing sets”); -pset = un nod de I/E (Linux) si 64 noduri calcul (ruland un nucleu CNK „custom compute node kernel”); -asignarea nodurilor de calcul la un nod de I/E este flexibila si chiar raportul noduri I/E / noduri calcul poate varia intre 1:8 si 1:128.
 conecteaza blocul de calcul la: -un nod de serviciu (pentru controlul masinii); -nodurile front-end (unde utilizatorii compileaza, lanseaza si interactioneaza cu aplicatiile lor); - servere paralele de fisiere; -reteaua Gigabit Ethernet (control): nod de serviciu - bloc de calcul (control direct al hardware-ului); -nodurile de calcul: impartite in 1024 seturi logice de prelucrare ( psets - „processing sets ); -pset = un nod de I/E (Linux) si 64 noduri calcul (ruland un nucleu CNK „custom compute node kernel ); -asignarea nodurilor de calcul la un nod de I/E este flexibila si chiar raportul noduri I/E / noduri calcul poate varia intre 1:8 si 1:128.")
63
Din p.d.v. software masina se poate imparti in : volum de calcul, arie functionala si arie de control, fiecare cu hardware dedicat (asemanator cu ASCI Red).
..")
64
Volumul de calcul: -implementat prin nuclee si biblioteci runtime pentru nodurile de calcul (executia aplicatiilor utilizator); -nodurile de calcul “vazute” ca atasate la nodul de I/E (coordonator pset). Aria functionala: -compilarea aplicatiilor, lansarea si controlul joburilor, depanarea aplicatiilor si operatiile de I/E la rularea aplicatiilor; -implementarea ariei functionale: software de sistem ruland pe nodurile de I/E, nodurile front-end si nodul de serviciu. Aria de control: -implementata exclusiv in nodul de serviciu; -executa operatii de tipul: lansarea masinii („booting”), monitorizarea datelor de mediu (temperatura, tensiune), raportarea erorilor critice.
. Aria functionala: -compilarea aplicatiilor, lansarea si controlul joburilor, depanarea aplicatiilor si operatiile de I/E la rularea aplicatiilor; -implementarea ariei functionale: software de sistem ruland pe nodurile de I/E, nodurile front-end si nodul de serviciu. Aria de control: -implementata exclusiv in nodul de serviciu; -executa operatii de tipul: lansarea masinii („booting ), monitorizarea datelor de mediu (temperatura, tensiune), raportarea erorilor critice.")
65
Software-ul sistem pentru nodurile de I/E
-nodurile de I/E ruleaza Linux -> roluri importante in sistem: -lansarea joburilor si controlul in pset-urile lor; -reprezinta dispozitivele de incarcare primare pentru majoritatea serviciilor sistem cerute de rularea aplicatiilor; -Linux pentru procesoarele PPC440 (modificari in secventa de boot, gestionarea intreruperilor, planul de memorie, suportul de FPU si drivere de dispozitive); -pe fiecare nod de I/E ruleaza un daemon CIOD („control and I/O daemon”): lansarea programelor, semnalizarea, terminarea si transferul de fisiere prin intermediul mesajelor punct la punct prin reteaua colectiva.
; -pe fiecare nod de I/E ruleaza un daemon CIOD („control and I/O daemon ): lansarea programelor, semnalizarea, terminarea si transferul de fisiere prin intermediul mesajelor punct la punct prin reteaua colectiva.")
66
Software-ul sistem pentru nodurile de calcul
-nodurile de calcul: ruleaza un nucleu minim single-user, dual-threaded (cate un fir de executie per procesor) CNK („compute node kernel”); -CNK prezinta o interfata POSIX (Portable Operating System Interface Standard); -suport pentru apelurile sistem privind transferurile I/E de fisiere; -operatiile de I/E nu sunt executate direct de CNK: acestea sunt transferate catre CIOD din nodul de I/E a pset-ului, iar rezultatele sunt primite inapoi. Software-ul de transfer de mesaje pentru comunicarea intre procesele de aplicatie ruland pe noduri de calcul -> trei niveluri: -nivelul pachet: o biblioteca mica furnizand functii pentru accesul direct la hardware-ul de retele BG/L; -nivelul mesaj: sistem de livrare de mesaje punct la punct cu intarziere mica si banda larga de transfer; -nivelul aplicatie: MPI.
 CNK („compute node kernel ); -CNK prezinta o interfata POSIX (Portable Operating System Interface Standard); -suport pentru apelurile sistem privind transferurile I/E de fisiere; -operatiile de I/E nu sunt executate direct de CNK: acestea sunt transferate catre CIOD din nodul de I/E a pset-ului, iar rezultatele sunt primite inapoi. Software-ul de transfer de mesaje pentru comunicarea intre procesele de aplicatie ruland pe noduri de calcul -> trei niveluri: -nivelul pachet: o biblioteca mica furnizand functii pentru accesul direct la hardware-ul de retele BG/L; -nivelul mesaj: sistem de livrare de mesaje punct la punct cu intarziere mica si banda larga de transfer; -nivelul aplicatie: MPI.")
67
Software sistem pentru nodurile front-end
-nodurile front-end: singurele la care se pot loga utilizatorii; -contin compilatoare si depanatoare; -furnizarea joburilor (lansarea - de catre nodul de serviciu); -disponibil setul de tool-uri GNU; -suport de optmizari avansate pentru Fortran 90, C si C++; -compilatoarele suporta generarea automata de cod pentru exploatarea FPU SIMD cu doua cai (atasata fiecarui procesor din nodul de calcul).
; -disponibil setul de tool-uri GNU; -suport de optmizari avansate pentru Fortran 90, C si C++; -compilatoarele suporta generarea automata de cod pentru exploatarea FPU SIMD cu doua cai (atasata fiecarui procesor din nodul de calcul).")
68
Software-ul sistem din nodul de serviciu
-nodul de serviciu: sistem de operare global CMCS („core management and control system”). Functii: -ia toate deciziile globale si colective; -interfateaza cu module de politica externa (ex: planificatorul de joburi); -executa o varietate de servicii de gestiune a sistemului (bootarea masinii, monitorizarea sistemului si lansarea joburilor). CMCS contine doua procese majore: -MMCS („midplane monitoring and control system”): utilzeaza reteaua de control pentru manipularea directa a hardware-ului pentru configurare, initializare si operare; -CIOMAN („control and I/O manager”): utilizeaza Ethernetul functional pentru interfatarea cu sistemele de operare locale in vederea executiei joburilor.
. Functii: -ia toate deciziile globale si colective; -interfateaza cu module de politica externa (ex: planificatorul de joburi); -executa o varietate de servicii de gestiune a sistemului (bootarea masinii, monitorizarea sistemului si lansarea joburilor). CMCS contine doua procese majore: -MMCS („midplane monitoring and control system ): utilzeaza reteaua de control pentru manipularea directa a hardware-ului pentru configurare, initializare si operare; -CIOMAN („control and I/O manager ): utilizeaza Ethernetul functional pentru interfatarea cu sistemele de operare locale in vederea executiei joburilor.")
69
Operatiile MMCS peste reteaua de control:
-operatii hardware de nivel scazut: pornirea surselor, monitorizarea senzorilor de temperatura si reactia corespunzatoare (inchiderea unei masini daca temperatura trece de un anumit prag); -configurarea si initializarea FPGA-ului de control, a cipurilor de legatura si a cipurilor BG/L (cu procesoare). -citirea si scrierea registrelor de configurare, SRAM si resetarea core-urilor unui cip BG/L
; -configurarea si initializarea FPGA-ului de control, a cipurilor de legatura si a cipurilor BG/L (cu procesoare). -citirea si scrierea registrelor de configurare, SRAM si resetarea core-urilor unui cip BG/L.")
70
SISTEME CU TRANSPUTERE
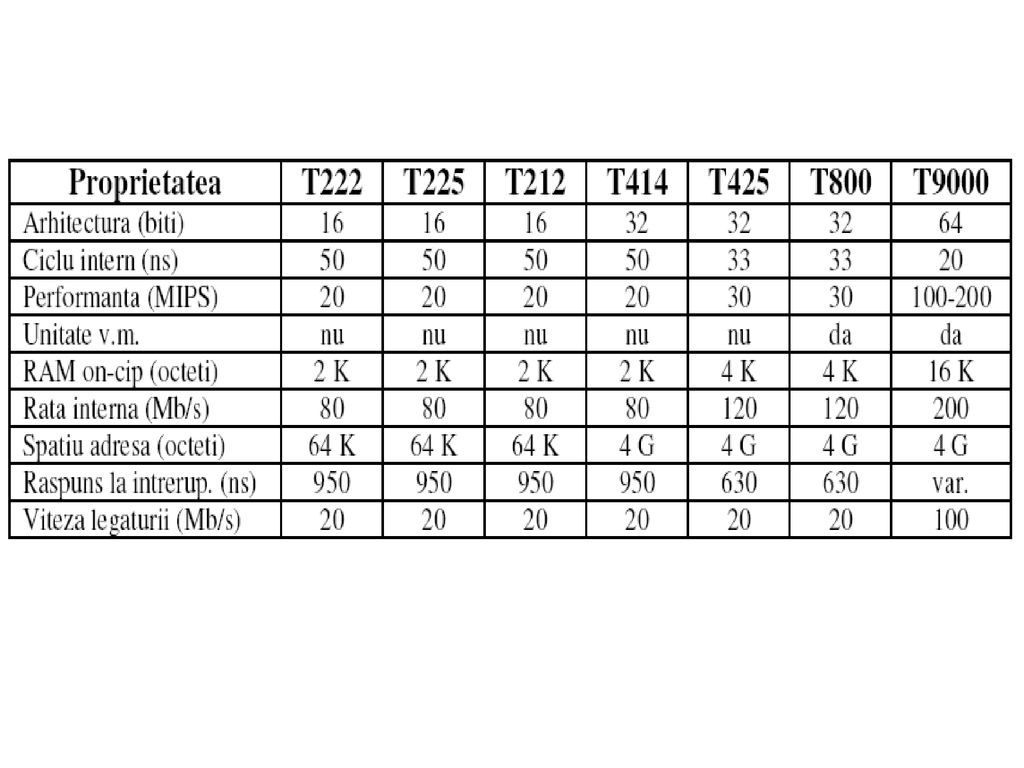
-procesoare de tip transputer de la firma INMOS; -familia de transputere: dispozitive VLSI -> sisteme de prelucrare concurente; -limbaj occam; -exemple: -IMS T222 procesor pe 16 biţi; -IMS T414 şi IMS T425 procesoare pe 32 de biţi; -IMS T800 procesor rapid pe 32 de biţi (v.m.); -IMS M212 controlor de periferice inteligent (procesor pe 16 biţi, memorie pe cip şi legături de comunicaţie, cu logică pentru interfaţarea de discuri sau periferice generale); -IMS C011 şi IMS C012 adaptoare de legături permiţând conectarea legăturilor seriale INMOS la porturi paralele sau magistrale -IMS C004 comutator de legături programabil ( reţea grilă de comutatoare cu 32 de intrări şi 32 de ieşiri).
; -IMS M212 controlor de periferice inteligent (procesor pe 16 biţi, memorie pe cip şi legături de comunicaţie, cu logică pentru interfaţarea de discuri sau periferice generale); -IMS C011 şi IMS C012 adaptoare de legături permiţând conectarea legăturilor seriale INMOS la porturi paralele sau magistrale. -IMS C004 comutator de legături programabil ( reţea grilă de comutatoare cu 32 de intrări şi 32 de ieşiri).")
71
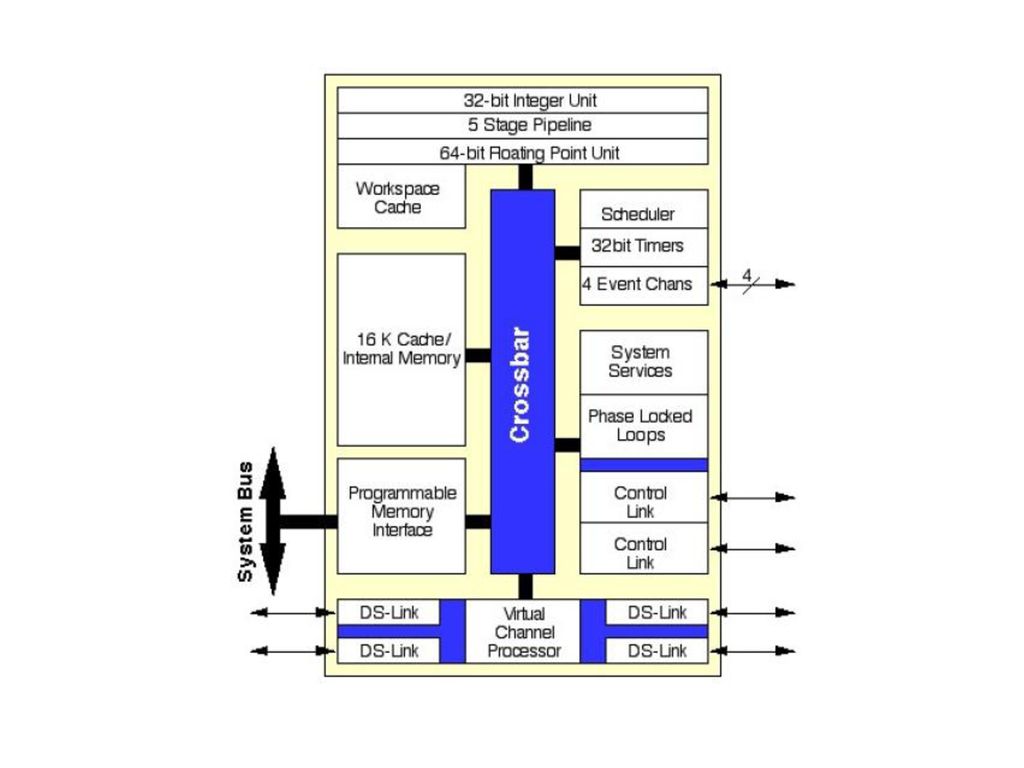
Arhitectura simplificată a unui transputer

73
Interfaţarea unei memorii
=> conectarea unei memorii la transputerul T414 (magistrală pe 32 de biţi, multiplexată pentru date şi adrese şi un spaţiu de adrese de 32 GB); Semnalele asociate cu interfaţa de memorie: -notMemWrB0-3 (ieşiri): comanda operaţia de scriere; -notMemRd (ieşire): comandă operaţia de citire; -notmemRf (ieşire): comandă operaţia de reîmprospătare la DRAM; -notMemS0-4 (ieşiri): linii de strob configurabile (temporizare programabilă); -MemNotWrD0 (bidirecţională): indicator de scriere / bitul 0 de date; -MemNotRfD1 (bidirecţională): indicator de reâmprospătare / bitul 1 de date; -MemAD2-31 (bidirecţionale): liniile de adrese şi date; -MemReq (intrare): linie de cerere externă; -MemGranted (ieşire): linie de acceptare a cererii externe; -MemWait (intrare): permite introducerea de stări suplimentare de aşteptare; -MemConfig (intrare): permite introducerea informaţiilor de configurare a semnalelor cu temporizare programabilă.
; Semnalele asociate cu interfaţa de memorie: -notMemWrB0-3 (ieşiri): comanda operaţia de scriere; -notMemRd (ieşire): comandă operaţia de citire; -notmemRf (ieşire): comandă operaţia de reîmprospătare la DRAM; -notMemS0-4 (ieşiri): linii de strob configurabile (temporizare programabilă); -MemNotWrD0 (bidirecţională): indicator de scriere / bitul 0 de date; -MemNotRfD1 (bidirecţională): indicator de reâmprospătare / bitul 1 de date; -MemAD2-31 (bidirecţionale): liniile de adrese şi date; -MemReq (intrare): linie de cerere externă; -MemGranted (ieşire): linie de acceptare a cererii externe; -MemWait (intrare): permite introducerea de stări suplimentare de aşteptare; -MemConfig (intrare): permite introducerea informaţiilor de configurare a semnalelor cu temporizare programabilă.")
74
Schema de principiu pentru conectarea unei memorii la transputerul T414:

75
Conectarea legăturilor INMOS
O legătură INMOS (“link”) = implementarea hardware a unui canal occam (fiecare legătură bidirecţională -> o pereche de canale occam, câte unul în fiecare sens).
 = implementarea hardware a unui canal occam (fiecare legătură bidirecţională -> o pereche de canale occam, câte unul în fiecare sens).")
76
-mesaj -> secvenţă de octeţi;
-după un octet de date, transmiţătorul aşteaptă o confirmare; Protocolul legăturii:

77
Exemplu: placa multitransputer IMS B003.

78
Reţele de interconectare => comutatoare grilă;
=> comutatoare grilă; Exemplu: circuitul IMS C004 (“crossbar switch” 32x32). -programare: legătură serială separată (legătură de configurare).
. -programare: legătură serială separată (legătură de configurare).")
79
Tipuri de mesaje: [0] [input] [output] : conectează input la output; [1] [link1] [link2] : conectează LinkIn1 la LinkOut2 şi LinkIn2 la LinkOut1; [2] [output] : cere numărul intrării care este conectată la output (IMS C004 răspunde cu numărul intrării, iar bitul cel mai semnificativ indică conectat/deconectat); [3] : încheie o secvenţă de configurare, iar circuitul este gata să accepte date pe intrările sale; [4] : resetează circuitul, care astfel poate fi reprogramat; [5] [output] : ieşirea output este deconectată şi ţinută la nivel logic coborât; [6] [link1] [link2] : deconecteză ieşirea lui link1 şi ieşirea lui link2.
![Tipuri de mesaje: [0] [input] [output] : conectează input la output; [1] [link1] [link2] : conectează LinkIn1 la LinkOut2 şi LinkIn2 la LinkOut1;](http://slideplayer.gr/slide/14105043/86/images/79/Tipuri+de+mesaje%3A+%5B0%5D+%5Binput%5D+%5Boutput%5D+%3A+conecteaz%C4%83+input+la+output%3B+%5B1%5D+%5Blink1%5D+%5Blink2%5D+%3A+conecteaz%C4%83+LinkIn1+la+LinkOut2+%C5%9Fi+LinkIn2+la+LinkOut1%3B.jpg "[2] [output] : cere numărul intrării care este conectată la output (IMS C004 răspunde cu numărul intrării, iar bitul cel mai semnificativ indică conectat/deconectat); [3] : încheie o secvenţă de configurare, iar circuitul este gata să accepte date pe intrările sale; [4] : resetează circuitul, care astfel poate fi reprogramat; [5] [output] : ieşirea output este deconectată şi ţinută la nivel logic coborât; [6] [link1] [link2] : deconecteză ieşirea lui link1 şi ieşirea lui link2.")
80
Soluţia generală de conectare a trei comutatoare (dimensiuni N-M/2, N-M/2 şi M) => un comutator de dimensiune N (N>M) :
 => un comutator de dimensiune N (N>M) :")
81
Comutator de capacitate foarte mare <= mai multe comutatoare de capacitate M:

82
Condiţie: existenţa a cel puţin M căi între oricare comutator de intrare şi oricare comutator de ieşire. Soluţia: bloc logic de interconectare = n comutatoare de dimensiune M. => comutator de dimensiune nM (nM).
.")
83
Comutatoare de dimensiune M => comutatoare de dimensiune max. M2.
In general => comutator de dimensiune n(M-M mod n). Utilizarea comutatoarelor IMS C004 pentru realizarea de comutatoare de capacitate mare (3n comutatoare IMS C004 => comutator de dimensiune n(32-32 mod n)) :
. Utilizarea comutatoarelor IMS C004 pentru realizarea de comutatoare de capacitate mare (3n comutatoare IMS C004 => comutator de dimensiune n(32-32 mod n)) :")
84
Reţea de transputere complet conectată

85
Transputerul T9000 Caracteristici: -a fost ultimul procesor din familie; -superscalar pe 32 biti si unitate de v.m. pe 64 biti; -procesor dedicat de comunicatie cu 4 legaturi (link-uri); -interfata de memorie externa; -16 KB de memorie pe cip; -performanta de 200 MIPS si 25 MFLOPS.
; -interfata de memorie externa; -16 KB de memorie pe cip; -performanta de 200 MIPS si 25 MFLOPS.")
87
Interfata de memorie (exemplu: 8 MB DRAM):
:")
88
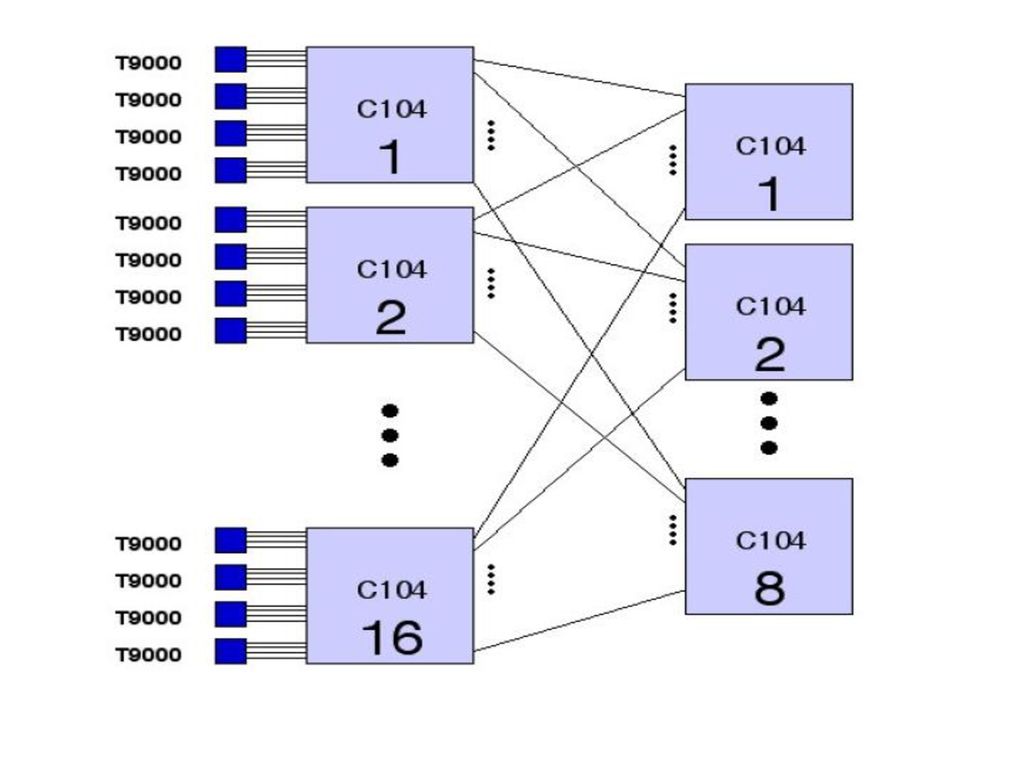
Interconectarea : circuitul crossbar C104 (32x32) -> ruterul procesorului T9000:
-conexiunile lucreaza la 100 Mb/s; -permite rutarea "wormhole" (cand header-ul pachetului a ajuns la un link, ruterul C104 determina link-ul de destinatie inainte sa receptionezez corpul principal al mesajului);
;")
89
-propus de Barnaby, May si Nicole;
Sistem MIMD cu transputere T9000 -propus de Barnaby, May si Nicole; -complet interconectat, bazat pe o arhitectura Clos; -doua niveluri de crossbar-uri => nu numai interconectare completa, dar chiar si cai multiple intre procesoare.

91
MULTICALCULATOARE COW
Multicalculatoarele COW (Cluster Of Workstation) - clustere de staţii de lucru. Cluster = multe PC-uri / staţii de lucru (sute) conectate într-o reţea comercială. Multicalculatoarele COW: Sisteme COW centralizate: -PC-urile montate într-un dulap, într-o singură cameră; -maşinile sunt omogene; -echipamente periferice: discuri şi interfeţe de reţea; -calculatoare fără proprietar. Sisteme COW descentralizate: -PC-urile răspândite într-o clădire sau campus; -calculatoarele sunt heterogene; -set complet de periferice; -cu proprietar.
 - clustere de staţii de lucru. Cluster = multe PC-uri / staţii de lucru (sute) conectate într-o reţea comercială. Multicalculatoarele COW: Sisteme COW centralizate: -PC-urile montate într-un dulap, într-o singură cameră; -maşinile sunt omogene; -echipamente periferice: discuri şi interfeţe de reţea; -calculatoare fără proprietar. Sisteme COW descentralizate: -PC-urile răspândite într-o clădire sau campus; -calculatoarele sunt heterogene; -set complet de periferice; -cu proprietar.")
92
Reţele de interconectare comerciale pentru sistemele COW:
Ethernet, cu tipurile: - clasic de 10 Mbps / 1.25 MB/s; - fast de 100 Mbps/ 12.5 MB/s; -gigabit de 1 Gbps/ 125 MB/s; ATM (Asynchronous Transfer Mode): -proiectat pentru sistemul telefonic; -viteze de 155 Mbps şi 622 Mbps; -pachete de 53 de octeţi (5 octeţi informaţii de identificare şi 48 de octeţi de date); Myrinet: -fiecare placă se conectează la un comutator; -comutatoarele -> topologie oarecare; -legături duplex de 1.28 Gbps pe fiecare sens; PCI Memory Channel: -dezvoltat de Digital Equipment.
: -proiectat pentru sistemul telefonic; -viteze de 155 Mbps şi 622 Mbps; -pachete de 53 de octeţi (5 octeţi informaţii de identificare şi 48 de. octeţi de date); Myrinet: -fiecare placă se conectează la un comutator; -comutatoarele -> topologie oarecare; -legături duplex de 1.28 Gbps pe fiecare sens; PCI Memory Channel: -dezvoltat de Digital Equipment.")
93
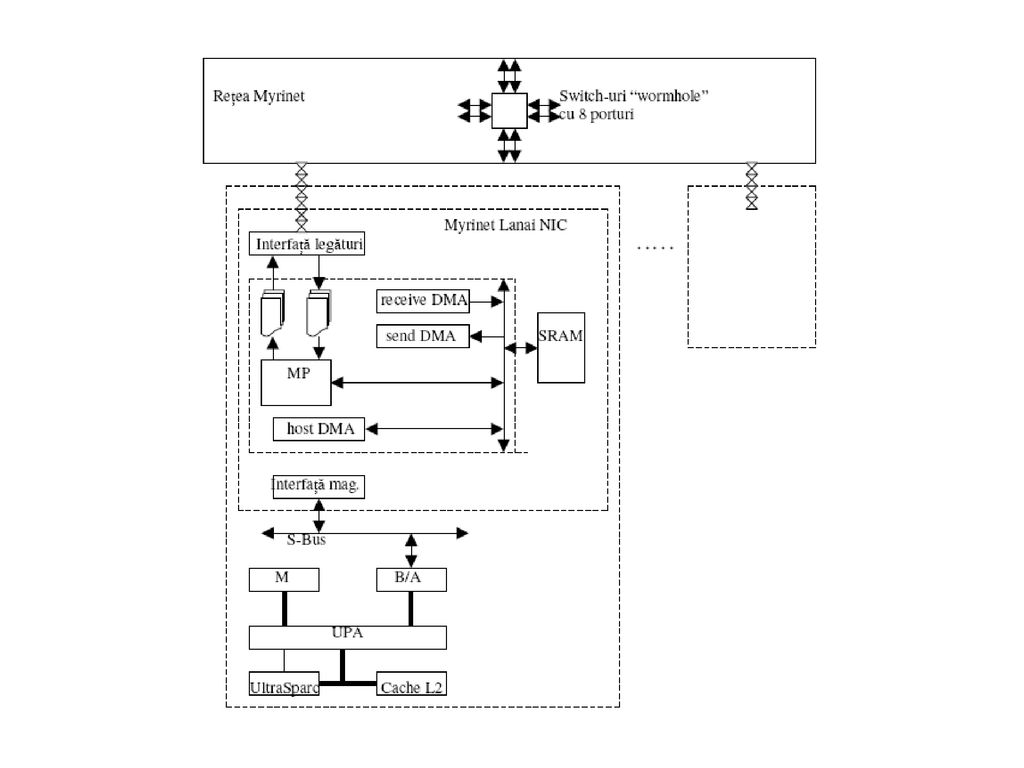
Reţea Myrinet Multicalculator COW cu staţii de lucru UltraSparc interconectate într-o reţea Myrinet. -placa de interfaţă de reţea NIC (Network Interface Card) cu procesor Lanai (controleaza fluxul de mesaje între procesorul principal şi reţea); -SRAM : stocarea temporară a mesajelor, cod şi date procesor Lanai; -placa NIC : trei module DMA (intrare din reţea, ieşire în reţea şi transferuri între procesorul principal şi memoria NIC); -comenzile pentru procesorul Lanai : scrise de procesorul principal în memoria NIC; -magistrală internă a cipului Lanai.
 cu procesor Lanai (controleaza fluxul de mesaje între procesorul principal şi reţea); -SRAM : stocarea temporară a mesajelor, cod şi date procesor Lanai; -placa NIC : trei module DMA (intrare din reţea, ieşire în reţea şi transferuri între procesorul principal şi memoria NIC); -comenzile pentru procesorul Lanai : scrise de procesorul principal în memoria NIC; -magistrală internă a cipului Lanai.")
95
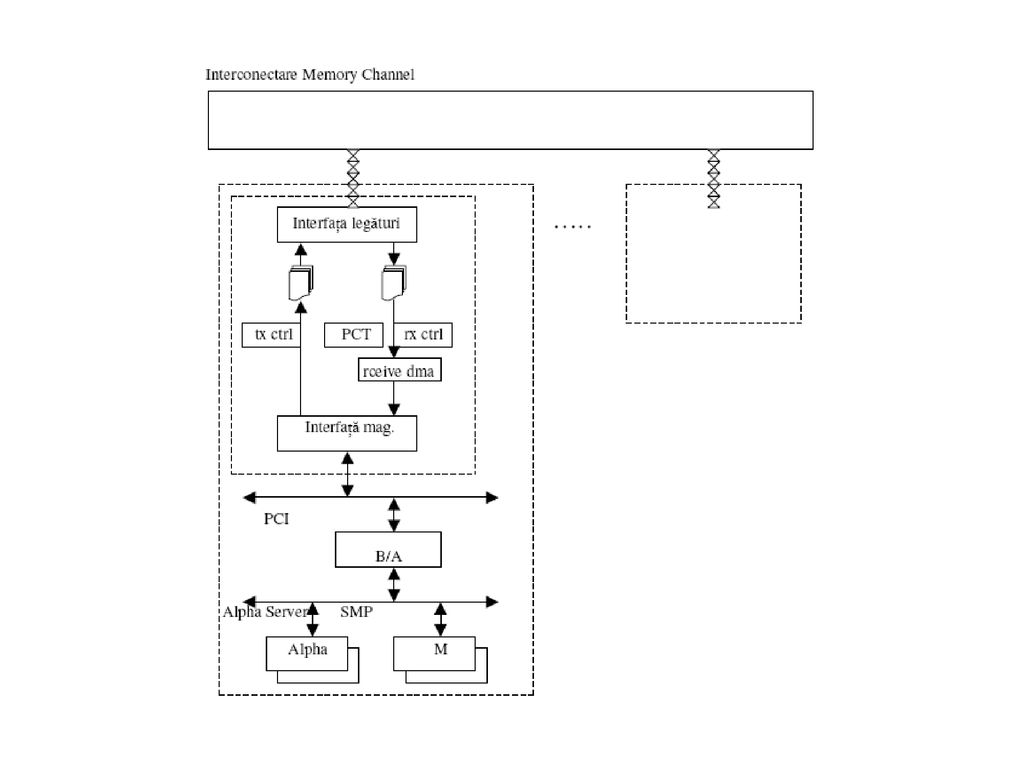
PCI Memory Channel -dezvoltat de Digital Equipment Corporation -interfaţa de comunicaţie : placă de interfaţă de reţea inserată într-un nod pe o extensie de magistrală de I/E; -ideea memoriei reflective: stabilirea unei conexiuni între o regiune a spaţiului de adresă a unui proces (“regiune de transmisie”) şi o “regiune de recepţie” din spaţiul altui proces => datele scrise în regiunea de transmisie să se reflecte (să se scrie şi) în regiunea de recepţie a destinaţiei ! -Memory Channel = NIC bazat pe magistala PCI, -> sistem multiprocesor simetric cu procesoare Alpha. Module: -cozi FIFO de transmisie şi recepţie; -tabelă de control a paginilor PCT (Page Control Table); -mecanism DMA pentru recepţie; -controloare de transmisie şi recepţie.
 şi o regiune de recepţie din spaţiul altui proces => datele scrise în regiunea de transmisie să se reflecte (să se scrie şi) în regiunea de recepţie a destinaţiei ! -Memory Channel = NIC bazat pe magistala PCI, -> sistem multiprocesor simetric cu procesoare Alpha. Module: -cozi FIFO de transmisie şi recepţie; -tabelă de control a paginilor PCT (Page Control Table); -mecanism DMA pentru recepţie; -controloare de transmisie şi recepţie.")
97
Clustere Beowulf -clusterele Beowulf = sisteme din categoria „high performance parallel computing”; -dezvoltat de Thomas Sterling si Donald Becker la NASA. Cluster Beowulf = grup de PC-uri identice ruland un sistem de operare „free open source” tip Unix (Linux, Solaris). Caracteristici: -calculatoarele echipate cu placa de retea Ethernet cu protocol TCP/IP, legate intr-o retea locala separata; -dispun de programe si biblioteci (cele mai utilizate MPI, PVM) -> permit partajarea lucrului; -pe calculatoare ruleaza copii ale aceluiasi program (model SPMD); -comunicatia: prin transfer de mesaje.
. Caracteristici: -calculatoarele echipate cu placa de retea Ethernet cu protocol TCP/IP, legate intr-o retea locala separata; -dispun de programe si biblioteci (cele mai utilizate MPI, PVM) -> permit partajarea lucrului; -pe calculatoare ruleaza copii ale aceluiasi program (model SPMD); -comunicatia: prin transfer de mesaje.")
98
Beowulf: arhitectura multicalculator -> un nod server si unul sau mai multe noduri client conectate prin retea Ethernet. Nu contine niciun hardware special! Nodul server: -controleaza intregul cluster; -furnizeaza fisiere nodurilor client; -este consola sistem si conexiune catre exterior. Nodurile client: -configurate si controlate de nodul server; -executa numai actiunile comandate de server; -in cazul unei configuratii fara disc, nodurile client nu cunosc adresele IP decat dupa ce le-au fost furnizate de server.

99
Diferenta principala intre Beowulf si un sistem COW:
-Beowulf opereaza ca o singura masina, nu ca un set de statii de lucru; -Beowulf dispune de propria sa retea locala dedicata pentru comunicatia intre noduri; -nodurile client nu au tastatura si nici monitor si pot fi accesate numai prin retea din nodul server.

100
In cazul sistemelor mari: mai multe noduri server si eventual noduri cu functii dedicate (monitorizare sistem, consola, etc):
:")
Παρόμοιες παρουσιάσεις