Κατέβασμα παρουσίασης
Η παρουσίαση φορτώνεται. Παρακαλείστε να περιμένετε

1
Συσταδοποίηση Δεδομένων

2
Εισαγωγικά Το πρόβλημα της συσταδοποίησης σχετίζεται με την τμηματοποίηση (partitioning, clustering) ενός συνόλου δεδομένων σε συστάδες έτσι ώστε τα στοιχεία του συνόλου των δεδομένων που ανήκουν σε μία συστάδα να είναι περισσότερο όμοια μεταξύ τους από ότι είναι με τα στοιχεία των άλλων συστάδων. Η συσταδοποίηση μπορεί να βρεθεί με διαφορετικά ονόματα σε διαφορετικά πεδία, όπως μη εποπτευόμενη μάθηση (unsupervised learning) στην αναγνώριση προτύπων, αριθμητική ταξονομία (numerical taxonomy) στην βιολογία, οικολογία, τυπολογία, στις κοινωνικές επιστήμες και τμηματοποίηση (segmentation, partitioning) στη θεωρία των γράφων και στις Βάσεις Δεδομένων
 ενός συνόλου δεδομένων σε συστάδες έτσι ώστε τα στοιχεία του συνόλου των δεδομένων που ανήκουν σε μία συστάδα να είναι περισσότερο όμοια μεταξύ τους από ότι είναι με τα στοιχεία των άλλων συστάδων. Η συσταδοποίηση μπορεί να βρεθεί με διαφορετικά ονόματα σε διαφορετικά πεδία, όπως μη εποπτευόμενη μάθηση (unsupervised learning) στην αναγνώριση προτύπων, αριθμητική ταξονομία (numerical taxonomy) στην βιολογία, οικολογία, τυπολογία, στις κοινωνικές επιστήμες και τμηματοποίηση (segmentation, partitioning) στη θεωρία των γράφων και στις Βάσεις Δεδομένων.")
3
Εφαρμογές Συσταδοποίησης
Summarization Compression Efficiently Finding Nearest Neighbors Μείωση Δεδομένων Παραγωγή/’Ελεγχος υπόθεσης Πρόβλεψη. Παραδείγματα: Επιχειρήσεις Βιολογία Χωρική Ανάλυση Στοιχείων Εξόρυξη στο Παγκόσμιο Ιστό Ψυχολογία και Ιατρική

4
Θέματα Συσταδοποίησης
Διαχείριση ακραίων σημείων Χειρισμός δυναμικών δεδομένων Διερμηνεία αποτελεσμάτων Αξιολόγηση αποτελεσμάτων Αριθμός ομάδων Εξελιξιμότητα

5
Μέθοδοι Συσταδοποίησης
Οι μέθοδοι μπορούν να κατηγοριοποιηθούν με βάση: Τον τύπο δεδομένων που εισάγονται στον αλγόριθμο. Τη μέθοδο που καθορίζει την συσταδοποίηση του συνόλου των δεδομένων. Τη θεωρία και τις θεμελιώδεις έννοιες στις οποίες είναι βασισμένες οι τεχνικές ανάλυσης συστάδας.

6
Κατηγοριοποίηση με βάση τύπο δεδομένων
Συσταδοποίηση αριθμητικών δεδομένων Κατηγορική Συσταδοποίηση Κειμενική Συσταδοποίηση

7
Κατηγοριοποίηση με βάση Μέδοδο Συσταδοποίησης
Ιεραρχική Συσταδοποίηση (Hierarchical Clustering) Συσταδοποίηση Διαμέρισης (Partitioning Clustering) Ασαφής συσταδοποίηση (Fuzzy Clustering) Συσταδοποίηση βασισμένη στα δίκτυα Kohonen (Kohonen Net Clustering) Συσταδοποίηση βασισμένη στην πυκνότητα (Density-based Clustering) Συσταδοποίηση βασισμένη σε πλέγμα (Grid-based Clustering) Συσταδοποίηση υποχώρων (Subspace Clustering).
 Συσταδοποίηση Διαμέρισης (Partitioning Clustering) Ασαφής συσταδοποίηση (Fuzzy Clustering) Συσταδοποίηση βασισμένη στα δίκτυα Kohonen (Kohonen Net Clustering) Συσταδοποίηση βασισμένη στην πυκνότητα (Density-based Clustering) Συσταδοποίηση βασισμένη σε πλέγμα (Grid-based Clustering) Συσταδοποίηση υποχώρων (Subspace Clustering).")
8
Διάκριση με βάση το Μέγεθος της Β.Δ.
Οι περισσότεροι αλγόριθμοι υποθέτουν μία μεγάλη δομή δεδομένων που είναι memory resident. Η ομαδοποίηση μπορεί να πραγματοποιηθεί πρώτα σε ένα δείγμα της Β.Δ. και στη συνέχεια να εφαρμοστεί σε όλη τη Β.Δ. Η ομαδοποίηση μπορεί να πραγματοποιηθεί πρώτα σε μία συμπιεσμένη αναπαράσταση Αλγόριθμοι BIRCH DBSCAN CURE

9
Έννοια της Συστάδας Well Separated (μία συστάδα είναι το σύνολο των αντικειμένων όπου κάθε αντικείμενο είναι πιο κοντά σε κάθε άλλο αντικείμενο της συστάδας, από ότι σε κάποιο άλλο αντικείμενο). Prototype Based (μία συστάδα είναι τα αντικείμενα που είναι πιο κοντά σε ένα πρωτότυπο (prototype) από ότι κάποιο άλλο αντικείμενο. Συνήθως σαν πρωτότυπο επιλέγεται το μέσο των σημείων μίας συστάδας). Graph Based (μία συνεκτική συνιστώσα ή μία κλίκα του γραφήματος). Density Based (μία πυκνή περιοχή αντικειμένων που περιβάλλεται από μία αραιή) Shared Property (conceptual clusters) ( σύνολο αντικειμένων που μοιράζονται μία ιδιότητα)
. Prototype Based (μία συστάδα είναι τα αντικείμενα που είναι πιο κοντά σε ένα πρωτότυπο (prototype) από ότι κάποιο άλλο αντικείμενο. Συνήθως σαν πρωτότυπο επιλέγεται το μέσο των σημείων μίας συστάδας). Graph Based (μία συνεκτική συνιστώσα ή μία κλίκα του γραφήματος). Density Based (μία πυκνή περιοχή αντικειμένων που περιβάλλεται από μία αραιή) Shared Property (conceptual clusters) ( σύνολο αντικειμένων που μοιράζονται μία ιδιότητα)")
10
Βασικές Έννοιες – Ορισμοί(1)
Ένα αντικείμενο x είναι ένα διάνυσμα d τιμών: x = (x1, ... xd), όπου xi είναι η τιμή τoυ i-οστού χαρακτηριστικού (feature) του αντικειμένου και d η διάσταση του αντικειμένου ή του χώρου που δημιουργείται από τα αντικείμενα.
, όπου xi είναι η τιμή τoυ i-οστού χαρακτηριστικού (feature) του αντικειμένου και d η διάσταση του αντικειμένου ή του χώρου που δημιουργείται από τα αντικείμενα.")
11
Αναπαράσταση Χαρακτηριστικών (1)
Τα features διακρίνονται σε: Quantitative features: continuous values (π.χ. βάρος), discrete values (π.χ. ο αριθμός των υπολογιστών), interval values (π.χ. η διάρκεια ενός γεγονότος). Qualitative features: Ονομαστικά (nominal) or unordered (π.χ. χρώμα), Ordinal (π.χ. στρατιωτική διάκριση ή ποιοτική αξιολόγηση της θερμοκρασίας (“ζεστό” or “κρύο”) ή της έντασης του ήχου (“ήσυχα” or “δυνατά”)). Structured features: (trees, symbolic objects)
, discrete values (π.χ. ο αριθμός των υπολογιστών), interval values (π.χ. η διάρκεια ενός γεγονότος). Qualitative features: Ονομαστικά (nominal) or unordered (π.χ. χρώμα), Ordinal (π.χ. στρατιωτική διάκριση ή ποιοτική αξιολόγηση της θερμοκρασίας ( ζεστό or κρύο ) ή της έντασης του ήχου ( ήσυχα or δυνατά )). Structured features: (trees, symbolic objects)")
12
Αναπαράσταση Χαρακτηριστικών (2)
Feature selection τεχνικές: αναγνωρίζουν ένα υποσύνολο από τα υπάρχοντα features για περαιτέρω χρήση Feature extraction τεχνικές: υπολογίζουν νέα features από το αρχικό σύνολο. Σε κάθε περίπτωση, στόχος είναι να βελτιωθεί η απόδοση της διαδικασίας ταξινόμησης και να γίνει πιο εύκολος ο υπολογισμός-υλοποίησή της.

13
Μετρικές Ομοιότητας (1)
Για patterns με συνεχή features η πιο συνηθισμένη μετρική απόστασης είναι η Ευκλείδεια απόσταση: που είναι ειδική περίπτωση (p=2) της μετρικής Minkowski.
 της μετρικής Minkowski.")
14
Μετρικές Ομοιότητας (2)
Μετρικές Minkowski: Μετρική Mahalanobis (για αντιμετώπιση linear correlation):
:")
15
Παράμετροι Ομαδοποίησης

16
Ιεραρχικοί Αλγόριθμοι
Συσσωρευτικοί (Agglomerative) Διαιρετικοί (Divisive)
 Διαιρετικοί (Divisive)")
17
Ιεραρχικοί Αλγόριθμοι Ομαδοποίησης
Κριτήρια σύνδεσης: Μονή σύνδεση(single linkage): μικρότερη απόσταση ανάμεσα σε ζεύγη συστάδων. Μέση σύνδεση(average linkage): μέση απόσταση ανάμεσα σε ζεύγη συστάδων. Πλήρης σύνδεση(complete linkage): μέγιστη απόσταση ανάμεσα σε ζεύγη συστάδων. Απόσταση μεταξύ centroids O single link αλγόριθμος έχει ως μειονέκτημα το καλούμενο chaining effect.
: μικρότερη απόσταση ανάμεσα σε ζεύγη συστάδων. Μέση σύνδεση(average linkage): μέση απόσταση ανάμεσα σε ζεύγη συστάδων. Πλήρης σύνδεση(complete linkage): μέγιστη απόσταση ανάμεσα σε ζεύγη συστάδων. Απόσταση μεταξύ centroids. O single link αλγόριθμος έχει ως μειονέκτημα το καλούμενο chaining effect.")
18
Διαμεριστικοί Αλγόριθμοι
Δημιουργούν ομάδες σε ένα βήμα Απαιτείται (κατά κανόνα) γνώση του μεγέθους της ομάδας Συνήθως διαχειρίζεται στατικά σύνολα Μερικοί ιεραρχικοί αλγόριθμοι μπορούν να μετατραπούν σε διαμεριστικούς, παράδειγμα ο MST
 γνώση του μεγέθους της ομάδας. Συνήθως διαχειρίζεται στατικά σύνολα. Μερικοί ιεραρχικοί αλγόριθμοι μπορούν να μετατραπούν σε διαμεριστικούς, παράδειγμα ο MST.")
19
Αλγόριθμος Τετραγωνικού σφάλματος
Αρχικό σύνολο από clusters centers επιλεγμένο τυχαία. Ανάθεσε τα αντικείμενα στα πιο κοντινά cluster centers Επαναϋπολόγισε το κέντρο του κάθε cluster Υπολόγισε το τετραγωνικό σφάλμα: Επανέλαβε την ανωτέρω διαδικασία μέχρις ότου η διαφορά μεταξύ δύο διαδοχικών τετραγωνικών σφαλμάτων, να είναι πιο μικρή από ένα όριο.

20
k-Means Αλγόριθμος K-Means
Αρχικό σύνολο από clusters centers επιλεγμένο τυχαία. Ανάθεσε τα αντικείμενα στα πιο κοντινά cluster centers Επαναϋπολόγισε το κέντρο του κάθε cluster Επαναληπτικά, αντικείμενα μετακινούνται ανάμεσα σε σύνολο από clusters έως ότου εντοπιστεί το επιθυμητό σύνολο. Ουσιαστικά ο αλγόριθμος επιχειρεί να ελαχιστοποιήσει τη μέση τετραγωνική απόσταση των δεδομένων από τα πλησιέστερα κέντρα των συστάδων και δίνεται από τον τύπο (άρα μπορεί να θεωρηθεί αλγόριθμος τετραγωνικού σφάλματος, αν και τα κριτήρια σύγκλισης ποικίλλουν)
")
21
Για κάθε επανάληψη r = 1, ..., rmax:
1. Ανάθεση των αρχικών κέντρων, vi i = 1, 2, ..., c, για τις c συστάδες. Για κάθε επανάληψη r = 1, ..., rmax: 2. Υπολογισμός της απόστασης κάθε στοιχείου του συνόλου δεδομένων από το κέντρο κάθε συστάδας dki = (xk - vi)2, k = 1, 2, .., n i = 1, 2, ..., c 3. Κάθε στοιχείο xk αντιστοιχίζεται στην συστάδα με την ελάχιστη απόσταση 4. Υπολογισμός των νέων κέντρων των συστάδων όπου ni ο αριθμός των στοιχείων που ανήκουν στην i συστάδα μέχρι στιγμής. then stop else r = r + 1, goto 2
2, k = 1, 2, .., n i = 1, 2, ..., c. 3. Κάθε στοιχείο xk αντιστοιχίζεται στην συστάδα με την ελάχιστη απόσταση. 4. Υπολογισμός των νέων κέντρων των συστάδων. όπου ni ο αριθμός των στοιχείων που ανήκουν στην i συστάδα μέχρι στιγμής. 5. then. stop. else. r = r + 1, goto 2.")
22
O Bisecting K-Means Αλγόριθμος
Initialize the list to contain the cluster with all points Repeat Remove a cluster from the list of clusters {perform several “trial” bissections} for i =1 to number of trials do bisect the selected cluster using basic k-means end for Select the two clusters with the lowest total SSE Add these clusters to the list of clusters. Until the list of clusters contains K clusters

23
Παραλλαγές του k-Means
Ο αλγόριθμος ISODATA ο οποίος περιλαμβάνει μία διαδικασία για αναζήτηση του καλύτερου αριθμού συστάδων με βάση κάποιο κόστος εκτέλεσης. Ο Fuzzy C-Means ο οποίος επεκτείνει τον κλασικό αλγόριθμο K-Means χρησιμοποιώντας την θεωρία της ασαφής λογικής και Ο SAS PROC FASTCLUS, ο οποίος ελέγχει την διαδικασία συσταδοποίησης υιοθετώντας δύο ακόμα παραμέτρους, την max_rad και min_size. Η πρώτη παράμετρος ελέγχει τον ελάχιστο αριθμό στοιχείων που μπορεί να έχει κάθε συστάδα ενώ η δεύτερη καθορίζει ότι η απόσταση κάθε στοιχείου μίας συστάδας από το κέντρο της συστάδας δεν πρέπει να είναι μεγαλύτερη του max_rad.

24
Fuzzy C-Means Clustering
1. Επέλεξε μία αρχικά fuzzy διαμέριση των N αντικειμένων σε k clusters επιλέγοντας ένα NxK πίνακα γειτνίασης U. H τιμή uij καθορίζει το βαθμό συμμετοχής του αντικειμένου xi στο cluster cj 2. Με βάση το U υπολόγισε την τιμή ενός fuzzy κριτηρίου: όπου 3. Επανυπολόγισε τα cluster centers για να μειώσεις το κριτήριο αυτό. 4. Επανέλαβε το βήμα 2.

25
Εκλέπτυνση αρχικών σημείων
Μία λύση στο πρόβλημα αρχικοποίησης συσταδοποίησης είναι η παραμετροποίηση κάθε συστάδας. Αυτή η παραμετροποίηση μπορεί να «τελεστεί» καθορίζοντας τα μέγιστα της συνάρτησης πυκνότητας πιθανότητας των δεδομένων και τοποθετώντας ένα κέντρο συστάδας σε κάθε μέγιστο. Η εκτίμηση όμως της πυκνότητας σε πολυδιάστατα δεδομένα είναι δύσκολη διαδικασία.

26
Αλγόριθμος Εκλέπτυνσης

27
PAM (Partitioning Around Medoids)
Partitioning Around Medoids (PAM) (K-Medoids) Αντιμετωπίζει ικανοποιητικά τους outliers. Η διάταξη εισόδου δεν επηρεάζει τα αποτελέσματα. Δεν κλιμακώνεται ικανοποιητικά. Κάθε cluster αντιπροσωπεύεται με ένα μόνο αντικείμενο που καλείται medoid. Το αρχικό σύνολο k medoids επιλέγεται τυχαία.
 (K-Medoids) Αντιμετωπίζει ικανοποιητικά τους outliers. Η διάταξη εισόδου δεν επηρεάζει τα αποτελέσματα. Δεν κλιμακώνεται ικανοποιητικά. Κάθε cluster αντιπροσωπεύεται με ένα μόνο αντικείμενο που καλείται medoid. Το αρχικό σύνολο k medoids επιλέγεται τυχαία.")
28
PAM 1. Τυχαία επιλογή Κ αντιπροσώπων για τις συστάδες.
1. Τυχαία επιλογή Κ αντιπροσώπων για τις συστάδες. 2. Υπολογισμός του συνολικού κόστους TCih για όλα τα ζεύγη των αντικειμένων Oi, Oh όπου το Oi είναι το τρέχον επιλεγμένο αντικείμενο και το Oh είναι ένα μη επιλεγμένο αντικείμενο. 3. Επιλέγουμε το ζεύγος Οi, Οh το οποίο αντιστοιχεί στο minOi, Oh TCih. Εάν το συνολικό κόστος είναι αρνητικό αντικαθιστούμε το Οi με το Οh και επιστρέφουμε στο βήμα 2. 4. Διαφορετικά, για κάθε μη επιλεγμένο αντικείμενο, βρίσκουμε το αντικείμενο αντιπρόσωπο που προσεγγίζει περισσότερο. Τότε ο αλγόριθμος σταματά.

29
PAM Cost Calculation Σε κάθε βήμα του αλγορίθμου τα medoids αλλάζουν εάν τα συνολικά κόστη βελτιώνονται. Cjih – η αλλαγή κόστους για ένα αντικείμενο tj συσχετίζεται με την εναλλαγή του medoid ti με το non-medoid th.

30
PAM Algorithm

31
Αλγόριθμος CLARA (Clustering LARge Applications)
2. Επιλέγουμε ένα δείγμα k αντικειμένων με τυχαίο τρόπο από το σύνολο των δεδομένων και καλούμε τον αλγόριθμο ΡΑΜ για να βρούμε τους k αντιπροσώπους για τις συστάδες. 3. Για κάθε αντικείμενο Οj στο σύνολο δεδομένων, καθορίζουμε πιο από τα k medoids προσεγγίζει περισσότερο το Οj. 4. Υπολογίζουμε την συνολική ανομοιότητα για την συσταδοποίηση που λαμβάνεται από το προηγούμενο βήμα. Εάν αυτή η τιμή είναι μικρότερη από το τρέχον ελάχιστο, χρησιμοποιούμε αυτή την τιμή του ελαχίστου σαν τρέχον ελάχιστο και διατηρούμε τα k medoids που βρήκαμε στο βήμα 2 σαν το καλύτερο σύνολο των medoids που έχουμε μέχρι στιγμής. 5. Επιστρέφουμε στο βήμα 1 και ξεκινάμε με την επόμενη επανάληψη.

32
Αλγόριθμος CLARANS (Clustering Large Applications based on Randomized Search)
1. Αρχικοποίηση των παραμέτρων numlocal (αριθμός τοπικών βέλτιστων που θα αναζητηθούν) και maxneighbor (μέγιστος αριθμός γειτόνων που μπορούν να εξεταστούν). Αρχικοποιούμε το i σε 1 και θέτουμε ως ελάχιστο κόστος mincost έναν μεγάλο αριθμό. 2. Καθορισμός της μεταβλητής current (τρέχον κόμβος προς εξέταση) ώστε να αναφέρεται σε έναν αρχικό κόμβο Gn,k. 3. Θέτουμε το j ίσο με 1. 4. Θεωρούμε έναν τυχαίο γείτονα S του τρέχοντος και υπολογίζουμε το κόστος αντικατάστασης του τρέχοντος κόμβου από τον γειτονικό κόμβο. 5. Εάν ο S έχει μικρότερο κόστος, θέτουμε ως τρέχον κόμβο (current) τον S και επιστρέφουμε στο βήμα 3. 6. Διαφορετικά, αυξάνουμε το j κατά 1. Εάν j maxneighbor, επιστρέφουμε στο βήμα 4. 7. Διαφορετικά, όταν το j > maxneighbor, συγκρίνουμε το κόστος του τρέχοντος κόμβου current με το ελάχιστο κόστος mincost. Εάν το πρώτο είναι μικρότερο από το mincost, θέτουμε ως mincost το κόστος του current και ορίζουμε ως καλύτερο κόμβο (bestnode) τον current. 8. Αυξάνουμε το i κατά 1. Εάν i > numlocal, εξάγουμε τον καλύτερο κόμβο και η διαδικασία σταματά. Διαφορετικά, επιστρέφουμε στο βήμα 2.
 και maxneighbor (μέγιστος αριθμός γειτόνων που μπορούν να εξεταστούν). Αρχικοποιούμε το i σε 1 και θέτουμε ως ελάχιστο κόστος mincost έναν μεγάλο αριθμό. 2. Καθορισμός της μεταβλητής current (τρέχον κόμβος προς εξέταση) ώστε να αναφέρεται σε έναν αρχικό κόμβο Gn,k. 3. Θέτουμε το j ίσο με Θεωρούμε έναν τυχαίο γείτονα S του τρέχοντος και υπολογίζουμε το κόστος αντικατάστασης του τρέχοντος κόμβου από τον γειτονικό κόμβο. 5. Εάν ο S έχει μικρότερο κόστος, θέτουμε ως τρέχον κόμβο (current) τον S και επιστρέφουμε στο βήμα Διαφορετικά, αυξάνουμε το j κατά 1. Εάν j maxneighbor, επιστρέφουμε στο βήμα Διαφορετικά, όταν το j > maxneighbor, συγκρίνουμε το κόστος του τρέχοντος κόμβου current με το ελάχιστο κόστος mincost. Εάν το πρώτο είναι μικρότερο από το mincost, θέτουμε ως mincost το κόστος του current και ορίζουμε ως καλύτερο κόμβο (bestnode) τον current. 8. Αυξάνουμε το i κατά 1. Εάν i > numlocal, εξάγουμε τον καλύτερο κόμβο και η διαδικασία σταματά. Διαφορετικά, επιστρέφουμε στο βήμα 2.")
33
Ομαδοποίηση Μεγάλου Όγκου Δεδομένων
Ένα σάρωμα των δεδομένων Online Αυξητικοί Δουλεύουν με περιορισμένη μνήμη Επεξεργασία κάθε πλειάδας μία φορά.

34
Γενική Μεθοδολογία Ανάγνωση ενός υποσυνόλου δεδομένων στην κύρια μνήμη
Εφαρμογή τεχνικών συσταδοποίησης στα δεδομένα της κύριας μνήμης Συνδυασμός αποτελεσμάτων με αυτά προηγουμένων δειγμάτων Διαχωρισμός σε τρεις τύπους: (α) στοιχεία που χρειάζονται συνεχώς, (β) στοιχεία που μπορούν να απορριφθούν, (γ) στοιχεία που αποθηκεύονται συμπιεσμένα
 στοιχεία που χρειάζονται συνεχώς, (β) στοιχεία που μπορούν να απορριφθούν, (γ) στοιχεία που αποθηκεύονται συμπιεσμένα.")
35
Αλγόριθμος CURE (Clustering Using Representatives)
Mπορεί να αναγνωρίζει συστάδες αυθαίρετων σχημάτων (π.χ. ελλειψοειδή) Eίναι εύρωστος στην παρουσία των outliers Oι απαιτήσεις του σε χώρο αποθήκευσης είναι γραμμική συνάρτηση του αριθμού των στοιχείων εισόδου και η χρονική πολυπλοκότητα του είναι O(n2) για δεδομένα μικρών διαστάσεων, όπου n είναι ο αριθμός των στοιχείων εισόδου. Ο αλγόριθμος μπορεί να εφαρμοστεί αποδοτικά και για συσταδοποίηση μεγάλων βάσεων δεδομένων συνδυάζοντας τεχνικές τυχαίας δειγματοποίησης (sampling) και τμηματοποίησης (partitioning)
 Eίναι εύρωστος στην παρουσία των outliers. Oι απαιτήσεις του σε χώρο αποθήκευσης είναι γραμμική συνάρτηση του αριθμού των στοιχείων εισόδου και η χρονική πολυπλοκότητα του είναι O(n2) για δεδομένα μικρών διαστάσεων, όπου n είναι ο αριθμός των στοιχείων εισόδου. Ο αλγόριθμος μπορεί να εφαρμοστεί αποδοτικά και για συσταδοποίηση μεγάλων βάσεων δεδομένων συνδυάζοντας τεχνικές τυχαίας δειγματοποίησης (sampling) και τμηματοποίησης (partitioning)")
36
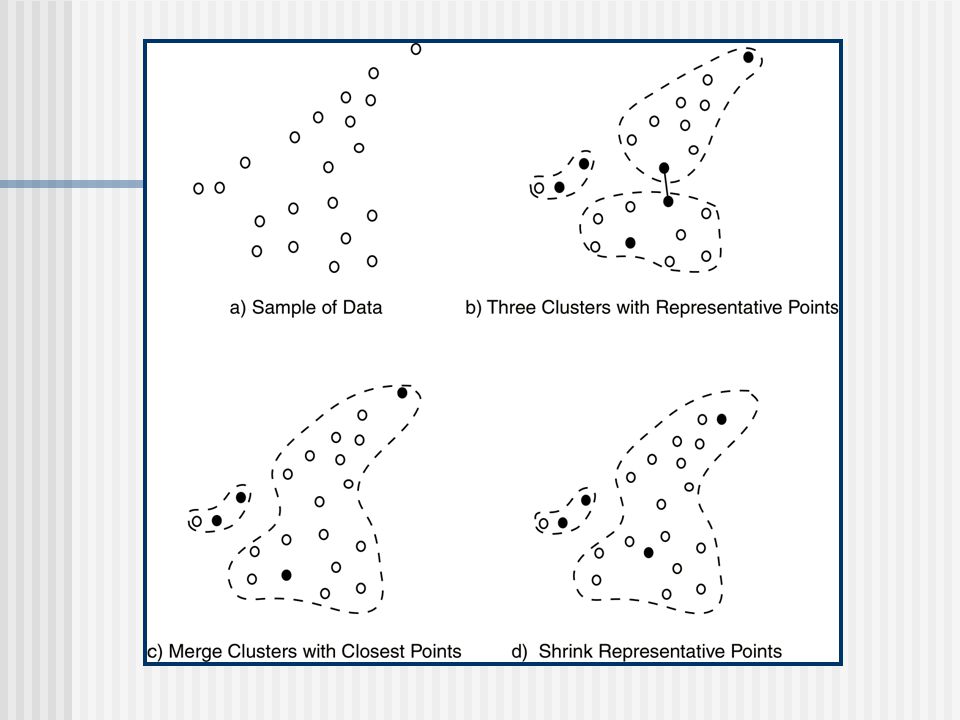
Βασική Ιδέα Ο αλγόριθμος αρχίζει λαμβάνοντας κάθε σημείο εισόδου σαν ξεχωριστή συστάδα και σε κάθε βήμα που ακολουθεί συγχωνεύει τα πλησιέστερα ζευγάρια συστάδων. Για να υπολογιστεί η απόσταση μεταξύ των συστάδων, αποθηκεύονται για κάθε συστάδα c αντιπρόσωποι (representatives). Οι αντιπρόσωποι αυτοί καθορίζονται επιλέγοντας αρχικά τα πιο διάσπαρτα σημεία μέσα σε μία συστάδα και στη συνέχεια μετακινούμε τα σημεία προς το μέσο της συστάδας κατά ένα ποσοστό α. Η απόσταση μεταξύ των συστάδων είναι η απόσταση μεταξύ των πιο κοντινών αντιπροσώπων δύο συστάδων. Έτσι μόνο τα σημεία αντιπρόσωποι μίας συστάδας χρησιμοποιούνται για να υπολογίσουμε την απόσταση της από μία άλλη συστάδα.
. Οι αντιπρόσωποι αυτοί καθορίζονται επιλέγοντας αρχικά τα πιο διάσπαρτα σημεία μέσα σε μία συστάδα και στη συνέχεια μετακινούμε τα σημεία προς το μέσο της συστάδας κατά ένα ποσοστό α. Η απόσταση μεταξύ των συστάδων είναι η απόσταση μεταξύ των πιο κοντινών αντιπροσώπων δύο συστάδων. Έτσι μόνο τα σημεία αντιπρόσωποι μίας συστάδας χρησιμοποιούνται για να υπολογίσουμε την απόσταση της από μία άλλη συστάδα.")
38
CURE Algorithm

39
Επεκτάσεις Το δείγμα του συνόλου των δεδομένων μας διαιρείται σε τμήματα στα οποία και εκτελείται ο αλγόριθμος συσταδοποίησης. Στην συνέχεια με βάση τις συστάδες που έχουν προσδιοριστεί στα τμήματα, εφαρμόζεται ο αλγόριθμος για την εύρεση των συστάδων του συνόλου των δεδομένων. Η βασική ιδέα είναι να τμηματοποιήσουμε το δείγμα μας σε p τμήματα, καθένα μεγέθους n/p. Στην συνέχεια εφαρμόζουμε συσταδοποίηση σε κάθε τμήμα μέχρι ο αριθμός των συστάδων σε κάθε τμήμα να μειωθεί σε n/pq για κάποια σταθερά q > 1.

40
CURE for Large Databases
Επιλογή τυχαίου δείγματος από τα δεδομένα. Διαμέριση του δείγματος σε p διαμερίσεις ίδιου μεγέθους Ομαδοποίησε τα σημεία σε κάθε διαμέριση, σε n/pq ομάδες, χρησιμοποιώντας την ιεραρχική εκδοχή του CURE λαμβάνοντας έτσι ένα σύνολο από n/q ομάδες. Εφάρμοσε στους εκπροσώπους των ομάδων τον αλγόριθμο CURE για να ομαδοποιήσεις n/q ομάδες, μέχρις ότου μείνουν μόνο K ομάδες. Απομάκρυνε ακραία σημεία Ανάθεσε τα υπόλοιπα σημεία, στην κοντινότερη ομάδα, για να παραχθεί μία πλήρης ομαδοποίηση.

41
BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies)
Ζυγισμένη επαναληπτικά μείωση και ομαδοποίηση με χρήση ιεραρχιών. Αυξητική, ιεραρχική, ένα σάρωμα δεδομένων Εφαρμόσιμο μόνο σε αριθμητικά δεδομένα Αποθήκευση πληροφορίας ομαδοποίησης σε ένα δέντρο. Κάθε στοιχείο σε ένα δέντρο εμπεριέχει πληροφορίας σχετικά με μία ομάδα. Νέοι κόμβοι εισέρχονται στο δέντρο.

42
Χαρακτηριστικό Ομαδοποίησης
Ο αλγόριθμος είναι αυξητικός και ιεραρχικός Το CF-tree λειτουργεί ως ένα B-tree. To CF-tree: CF (Clustering Feature) Τριπλέτα: (N,LS,SS) N: Αριθμός σημείων σε ένα cluster LS: Άθροισμα σημείων σε ένα cluster SS: Άθροισμα τετραγώνων σημείων σε ένα cluster άρα ακτίνα και διάμετρος υπολογίσιμη CF Tree Ζυγισμένο δέντρο ψαξίματος Ο κόμβος έχει CF τριπλέτα για κάθε παιδί Το φύλλο αναπαριστά συστάδα και έχει CF τιμή για κάθε υποσυστάδα. Η υποσυστάδα έχει μέγιστη διάμετρο
 Τριπλέτα: (N,LS,SS) N: Αριθμός σημείων σε ένα cluster. LS: Άθροισμα σημείων σε ένα cluster. SS: Άθροισμα τετραγώνων σημείων σε ένα cluster. άρα ακτίνα και διάμετρος υπολογίσιμη. CF Tree. Ζυγισμένο δέντρο ψαξίματος. Ο κόμβος έχει CF τριπλέτα για κάθε παιδί. Το φύλλο αναπαριστά συστάδα και έχει CF τιμή για κάθε υποσυστάδα. Η υποσυστάδα έχει μέγιστη διάμετρο.")
43
Node splitting Node splitting is done by choosing the farthest pair of entries as seeds, and redistributing the remaining entries Split always propagates to the root even without splits in intermediate nodes Sometimes when the split stops at node Nj we could employ merging refinement where we scan to find the two closest entries and merge them. If there are enough entries for the two children we are ok otherwise we split again.

44
Βελτίωση Συστάδων Δημιουργία αρχικού CF-tree. Αν δεν υπάρχει επαρκής χώρος, το κατώφλι αυξάνεται, και ένα νέο μικρότερο δέντρο κατασκευάζεται. Μετά το πέρας του αλγορίθμου, εφάρμοσε μία διαφορετική προσέγγιση, στα φύλλα του CF-tree. Η αρχική εργασία προτείνει έναν συσσωρευτικό ιεραρχικό αλγόριθμο, θα μπορούσαν να χρησιμοποιηθούν και άλλοι. Η τελευταία φάση (προαιρετική) επανασυσταδοποιεί τα σημεία με βάση την απόστασή τους από το νέο κέντρο.
 επανασυσταδοποιεί τα σημεία με βάση την απόστασή τους από το νέο κέντρο.")
45
Αλγόριθμος DBSCAN DBSCAN
Density Based Spatial Clustering για Εφαρμογές με Θόρυβο Outliers δεν θα επηρεάσουν τη δημιουργία του cluster. Είσοδος MinPts – ελάχιστος αριθμός σημείων στο cluster Eps – για κάθε σημείο στο cluster θα πρέπει να υπάρχει ένα άλλο σημείο με λiγότερη από αυτή την απόσταση.

46
Βασικές Έννοιες Ένα αντικείμενο p είναι άμεσα πυκνά-προσεγγίσιμο από ένα αντικείμενο q εάν 1. το αντικείμενο ανήκει στο υποσύνολο των αντικειμένων που βρίσκονται στη γειτονιά του q 2. ο αριθμός των αντικειμένων που περιέχονται στη γειτονιά του q είναι μεγαλύτερος από ένα όριο MinPts. Ένα αντικείμενο p είναι πυκνά-προσεγγίσιμο από ένα αντικείμενο q, p->D q, εάν υπάρχει μια ακολουθία από αντικείμενα p1,….,pn, p1=q, pn=p τέτοια ώστε το pi + 1 να είναι άμεσα πυκνά-προσεγγίσιμο από το pi. Ένα αντικείμενο p είναι πυκνά-σννδεδεμένο με ένα αντικείμενο q εάν υπάρχει ένα αντικείμενο o τέτοιο ώστε τόσο το p όσο και το q να είναι πυκνά-προσεγγίσιμα από το o. Μία συστάδα C στο σύνολο των δεδομένων D είναι ένα μη-κενό υποσύνολο του D το οποίο ικανοποιεί τις ακόλουθες συνθήκες: 1. Για κάθε p, q D: εάν p c και q- >D p, τότε q C 2. Για κάθε p, q D: το p είναι πυκνά-συνδεδεμένο με το q. Έστω ότι C1, C2,..., Cn είναι οι συστάδες του συνόλου δεδομένων D. Ορίζουμε ως θόρυβο το σύνολο των αντικειμένων στην βάση δεδομένων D τα οποία δεν ανήκουν σε καμία συστάδα Ci.

48
Αδυναμίες Αλγορίθμου Επηρεάζεται από τις τιμές των παραμέτρων Eps και MinPts, οι οποίες είναι δύσκολο να προσδιοριστούν. Όπως όλοι οι ιεραρχικοί αλγόριθμοι πάσχει από το πρόβλημα της μη ευρωστίας καθώς στην περίπτωση που υπάρχει μία πυκνή σειρά σημείων που συνδέει δύο συστάδες ο DBSCAN μπορεί να τελειώσει συγχωνεύοντας τις δύο συστάδες. Η χρήση δείγματος για να περιοριστεί το μέγεθος της εισόδου στην εφαρμογή των αλγορίθμων που βασίζονται στην πυκνότητα δεν είναι εφικτή. Ο λόγος είναι ότι ακόμα και αν το δείγμα είναι μεγάλο, μπορεί να υπάρχουν μεγάλες διακυμάνσεις στην πυκνότητα των σημείων μέσα σε κάθε συστάδα στο τυχαίο δείγμα Θετικό: χρόνος τρεξίματος O(nlogn).
.")
49
Αυξητικός DBSCAN Έχει αποδειχθεί ότι κατά την εισαγωγή ή διαγραφή ενός αντικειμένου p, το σύνολο των αντικειμένων που επηρεάζονται (δηλαδή αντικείμενα τα οποία μπορεί να μεταβάλλουν την συμμετοχή τους στις συστάδες), είναι τα αντικείμενα που ανήκουν στην γειτονιά του αντικειμένου p καθώς και όλα τα αντικείμενα που είναι πυκνά προσεγγίσιμα από ένα από τα αντικείμενα του συνόλου D {p}. Αντίθετα, η συμμετοχή των άλλων αντικειμένων, που δεν ανήκουν στο σύνολο των επηρεαζόμενων αντικειμένων, στις συστάδες δεν μεταβάλλεται. Συνεπώς, με βάση τον αλγόριθμο DBSCAN μπορούν να σχεδιαστούν αποδοτικοί αλγόριθμοι ώστε να υποστηρίξουν τις εισαγωγές και διαγραφές στην διαδικασία της συσταδοποίησης.
, είναι τα αντικείμενα που ανήκουν στην γειτονιά του αντικειμένου p καθώς και όλα τα αντικείμενα που είναι πυκνά προσεγγίσιμα από ένα από τα αντικείμενα του συνόλου D {p}. Αντίθετα, η συμμετοχή των άλλων αντικειμένων, που δεν ανήκουν στο σύνολο των επηρεαζόμενων αντικειμένων, στις συστάδες δεν μεταβάλλεται. Συνεπώς, με βάση τον αλγόριθμο DBSCAN μπορούν να σχεδιαστούν αποδοτικοί αλγόριθμοι ώστε να υποστηρίξουν τις εισαγωγές και διαγραφές στην διαδικασία της συσταδοποίησης.")
50
Συσταδοποίηση για σύνολα με Κατηγορικά Δεδομένα (1)
Η χρήση της ευκλείδιας απόστασης προβληματική, και η χρήση διαμεριστικού αλγορίθμου προβληματική, καθώς καθώς υπολογίζουμε κέντρα το κέντρο όλο και περισσότερο απλώνεται σε περισσότερα πεδία Η χρήση Jaccard coefficient όπου η ομοιότητα ανάμεσα από δύο συναλλαγές T1 και T2 είναι έχει το πρόβλημα ότι δεν ελέγχει την συνολική ποιότητα του cluster αλλά ελέγχει μόνο τοπικά.

51
Συσταδοποίηση για σύνολα με Κατηγορικά Δεδομένα (2)
ROCK (RΟbust Clustering Algorithm for Categorical Attribute) Εισάγει δύο νέες έννοιες: Γείτονες. Οι γείτονες ενός σημείου είναι εκείνα τα σημεία τα οποία παρουσιάζουν σημαντική ομοιότητα με αυτό. Θεωρούμε την sim (pi, pj) ως την συνάρτηση ομοιότητας με βάση την οποία εκτιμούμε την εγγύτητα μεταξύ δύο σημείων και η οποία κυμαίνεται μεταξύ του 0 και 1. Η συνάρτηση μπορεί να είναι ένα οποιαδήποτε καλά ορισμένο μέτρο απόστασης ή ακόμα και μία μη μετρική συνάρτηση (π.χ. μία συνάρτηση ομοιότητας που παρέχεται από ειδικούς στο πεδίο που ανήκουν τα στοιχεία που συγκρίνουμε). Δεδομένου λοιπόν μίας συνάρτησης ομοιότητας και ενός ορίου θ (θ [0,1]), ένα ζεύγος σημείων pi, pj είναι γείτονες εάν ισχύει η ακόλουθη ανισότητα: Δεσμοί. Ο δεσμός link(pi, pj) ορίζεται ως ο αριθμός των κοινών γειτόνων μεταξύ των στοιχείων pi, pj.
 Εισάγει δύο νέες έννοιες: Γείτονες. Οι γείτονες ενός σημείου είναι εκείνα τα σημεία τα οποία παρουσιάζουν σημαντική ομοιότητα με αυτό. Θεωρούμε την sim (pi, pj) ως την συνάρτηση ομοιότητας με βάση την οποία εκτιμούμε την εγγύτητα μεταξύ δύο σημείων και η οποία κυμαίνεται μεταξύ του 0 και 1. Η συνάρτηση μπορεί να είναι ένα οποιαδήποτε καλά ορισμένο μέτρο απόστασης ή ακόμα και μία μη μετρική συνάρτηση (π.χ. μία συνάρτηση ομοιότητας που παρέχεται από ειδικούς στο πεδίο που ανήκουν τα στοιχεία που συγκρίνουμε). Δεδομένου λοιπόν μίας συνάρτησης ομοιότητας και ενός ορίου θ (θ [0,1]), ένα ζεύγος σημείων pi, pj είναι γείτονες εάν ισχύει η ακόλουθη ανισότητα: Δεσμοί. Ο δεσμός link(pi, pj) ορίζεται ως ο αριθμός των κοινών γειτόνων μεταξύ των στοιχείων pi, pj.")
52
Συνάρτηση Κριτήριο Η ακόλουθη συνάρτηση κριτήριο θα πρέπει να μεγιστοποιείται για k συστάδες: f(θ) μία παράμετρος η οποία ελέγχει τους γείτονες ενός κόμβου, nf(θ) o μέσος όρος γειτόνων ενός κόμβου.
 μία παράμετρος η οποία ελέγχει τους γείτονες ενός κόμβου, nf(θ) o μέσος όρος γειτόνων ενός κόμβου.")
53
Μέτρα Ποιότητας Μπορούμε να ορίσουμε το μέτρο ποιότητας g(Ci,Cj) ως εξής:
 ως εξής:")
54
Συσταδοποίηση Kohonen Net
Τα νευρωνικά δίκτυα Kohonen παρέχουν έναν τρόπο κατηγοριοποίησης των δεδομένων μέσω αυτό-οργανωμένων (self-organizing) δικτύων τεχνητών νευρώνων. Δύο βασικές έννοιες που κυριαρχούν στα δίκτυα Kohonen και είναι σημαντικό να κατανοήσουμε είναι, η ανταγωνιστική μάθηση και η αυτό-οργάνωση. Ο όρος ανταγωνιστική μάθηση αφορά στην εύρεση ενός νευρώνα ο οποίος προσεγγίζει περισσότερο το πρότυπο εισόδου. Το δίκτυο στη συνέχεια τροποποιεί αυτό τον νευρώνα και τους γειτονικούς του (ανταγωνιστική μάθηση με αυτόοργάνωση) έτσι ώστε να μοιάζουν περισσότερο με το πρότυπο. Το επίπεδο ενεργοποίησης είναι:
 δικτύων τεχνητών νευρώνων. Δύο βασικές έννοιες που κυριαρχούν στα δίκτυα Kohonen και είναι σημαντικό να κατανοήσουμε είναι, η ανταγωνιστική μάθηση και η αυτό-οργάνωση. Ο όρος ανταγωνιστική μάθηση αφορά στην εύρεση ενός νευρώνα ο οποίος προσεγγίζει περισσότερο το πρότυπο εισόδου. Το δίκτυο στη συνέχεια τροποποιεί αυτό τον νευρώνα και τους γειτονικούς του (ανταγωνιστική μάθηση με αυτόοργάνωση) έτσι ώστε να μοιάζουν περισσότερο με το πρότυπο. Το επίπεδο ενεργοποίησης είναι:")
55
Αλγόριθμος Kohonen Τα βασικά βήματα του Kohonen αλγορίθμου είναι τα εξής: Βήμα 1ο : Για κάθε νευρώνα στο επίπεδο Kohonen λαμβάνεται ένα πλήρες αντίγραφο ενός προτύπου εισόδου. Βήμα 2ο : Βρίσκουμε το νευρώνα που είναι ο «νικητής». Ο νικητής είναι αυτός με το μικρότερο επίπεδο ενεργοποίησης: Βήμα 3ο : Για κάθε νευρώνα που είναι «νικητής» καθώς και για τους φυσικούς γειτονικούς του κόμβους, χρησιμοποιείται ο ακόλουθος κανόνας εκπαίδευσης για την τροποποίηση των βαρών: όπου α είναι ο ρυθμός μάθησης ο οποίος μειώνεται με το χρόνο (αρχίζει από την τιμή 1 και μειώνεται σταδιακά μέχρι την τιμή 0), rij είναι η απόσταση μεταξύ του νικητή και του κόμβου που πρόκειται να ενημερωθεί και sigma είναι η ακτίνα γειτονίας η οποία μειώνεται με το χρόνο. Βήμα 4ο : Επανάληψη των βημάτων 1-3 για κάθε νέο πρότυπο εισόδου. Βήμα 5ο : Επανάληψη βήματος 4 έως ότου όλα τα πρότυπα εισόδου εξεταστούν (αυτό καθορίζει την τιμή του 1). Βήμα 6ο : Επανάληψη βήματος 5 για ένα καθορισμένο αριθμό φορών
, rij είναι η απόσταση μεταξύ του νικητή και του κόμβου που πρόκειται να ενημερωθεί και sigma είναι η ακτίνα γειτονίας η οποία μειώνεται με το χρόνο. Βήμα 4ο : Επανάληψη των βημάτων 1-3 για κάθε νέο πρότυπο εισόδου. Βήμα 5ο : Επανάληψη βήματος 4 έως ότου όλα τα πρότυπα εισόδου εξεταστούν (αυτό καθορίζει την τιμή του 1). Βήμα 6ο : Επανάληψη βήματος 5 για ένα καθορισμένο αριθμό φορών.")
Παρόμοιες παρουσιάσεις










=α, κκπ(τ,σ)=ν, κκπ(λ,π)=η κκπ(π,σ)=γ, κκπ(ξ,ο)=κ ξο κκπ(ι,ξ)=β, κκπ(τ,θ)=θ, κκπ(ο,μ)=α.>")









