Κατέβασμα παρουσίασης
Η παρουσίαση φορτώνεται. Παρακαλείστε να περιμένετε

1
Κανόνες Συσχέτισης Σκοπός: Σύνοψη βασικών τεχνικών παραγωγής Κανόνων Συσχέτισης Σύνοψη Προβλημάτων Κανόνων Συσχέτισης Αλγόριθμοι Κανόνων Συσχέτισης Apriori Sampling Partitioning Parallel Algorithms Τεχνικές Σύγκρισης Αυξητικοί Αλγόριθμοι Προχωρημένες AR Τεχνικές

2
Ανάλυση Καλαθιού Αγορών Καταγραφή αντικειμένων που αγοράζονται μαζί Χρήσεις –Τοποθέτηση προϊόντων –Προώθηση προϊόντων –Διαχείριση αποθεμάτων Αντικειμενικός σκοπός: αύξηση πωλήσεων, μείωση κόστους Πολλές άλλες εφαρμογές: ρομποτική, διαδίκτυο.

3
Ορισμοί Κανόνων Συσχέτισης Σύνολo αντικειμένων: I={I 1,I 2,…,I m } Συναλλαγές: D={t 1,t 2, …, t n }, t j I Συνολοστοιχεία: {I i1,I i2, …, I ik } I Υποστήριξη συνολοστοιχείου: ποσοστό συναλλαγών που περιέχουν συνολοστοιχείο. Μεγάλα (Συχνά) συνολοστοιχεία: συνολοστοιχεία ο αριθμός εμφανίσεων των οποίων είναι πάνω από κάποιο όριο.
 συνολοστοιχεία: συνολοστοιχεία ο αριθμός εμφανίσεων των οποίων είναι πάνω από κάποιο όριο..")
4
Παράδειγμα Κανόνων Συσχέτισης I = { Beer, Bread, Jelly, Milk, PeanutButter} Υποστήριξη {Bread,PeanutButter} is 60%

5
Ορισμοί Κανόνων Συσχέτισης Κανόνας Συσχέτισης: συνεπαγωγή X Y όπου X,Y I και X Y = Υποστήριξη Κ.Σ. X Y: ποσοστό συναλλαγών που περιέχουν το σύνολο X Y, δηλαδή ίσο με P(X Y) Εμπιστοσύνη Κ.Σ. X Y: πηλίκο του αριθμού των συναλλαγών που περιέχουν το X Y προς αυτά που περιέχουν το X, δηλαδή ίσο με P(Υ/Χ) ‘Aξιο αναφοράς ότι δε ισχύει η μεταβατική ιδιότητα.
 Εμπιστοσύνη Κ.Σ. X Y: πηλίκο του αριθμού των συναλλαγών που περιέχουν το X Y προς αυτά που περιέχουν το X, δηλαδή ίσο με P(Υ/Χ) ‘Aξιο αναφοράς ότι δε ισχύει η μεταβατική ιδιότητα..")
6
Παράδειγμα Κανόνων Συσχέτισης

7
Πρόβλημα Κανόνα Συσχέτισης Δοθέντος συνόλου αντικειμένων I={I 1,I 2,…,I m } και μίας Βάσεως Δεδομένων συναλλαγών D={t 1,t 2, …, t n } όπου t i ={I i1,I i2, …, I ik } and I ij I, το Πρόβλημα Κανόνων Συσχέτισης είναι η ταυτοποίηση όλων των κανόνων συσχέτισης X Y με μία ελάχιστη υποστήριξη και εμπιστοσύνη. Παρατήρηση: Υποστήριξη X Y είναι ίδια με τη υποστήριξη Y X.

8
Γενικό Αλγοριθμικό Πλαίσιο 1.Εύρεση Μεγάλων Συνολοστοιχείων (με βάση κάποιο ελάχιστο support) 2.Παραγωγή Κανόνων από Συνολοστοιχεία (με βάση κάποιο ελάχιστο confidence) Γενικά, για κάθε συχνό υποσύνολο l εντόπισε όλα τα μη κενά υποσύνολά του α, και για κάθε τέτοιο υποσύνολο, παρουσίασε τον κανόνα α l-α, αν sup(l)/sup(α), μεγαλύτερο από κάποια τιμή.
 2.Παραγωγή Κανόνων από Συνολοστοιχεία (με βάση κάποιο ελάχιστο confidence) Γενικά, για κάθε συχνό υποσύνολο l εντόπισε όλα τα μη κενά υποσύνολά του α, και για κάθε τέτοιο υποσύνολο, παρουσίασε τον κανόνα α l-α, αν sup(l)/sup(α), μεγαλύτερο από κάποια τιμή.")
9
Αλγόριθμος Παραγωγής Κ.Σ.

10
Apriori Εκτελεί τόσο αριθμό περασμάτων όσο (το πολύ) το πλήθος των διαφορετικών αντικειμένων. Ιδιότητα Τερματισμού Υποσυνόλου: Κάθε υποσύνολο ενός συχνού συνολοστοιχείου είναι επίσης συχνό. Σε κάθε διαδοχική προσπέλαση χρησιμοποιούνται τα (συχνά) συνολοστοιχεία του προηγούμενου περάσματος με στόχο να δημιουργηθούν καινούργια συνολοστοιχεία
 συνολοστοιχεία του προηγούμενου περάσματος με στόχο να δημιουργηθούν καινούργια συνολοστοιχεία.")
11
Large Itemset Property

12
Πίνακας Παραμέτρων

13
Αλγόριθμος

14
Η Συνάρτηση Apriori Candidate Generation Η συνάρτηση αποτελείται από δύο βήματα, το join-step (ένωση) και το prune-step (αποκοπή): C k ={X Y | X,Y L k-1, |X Y|=k-2} (στάδιο ένωσης) Το στάδιο αποκοπής δίνεται παρακάτω:
 και το prune-step (αποκοπή): C k ={X Y | X,Y L k-1, |X Y|=k-2} (στάδιο ένωσης) Το στάδιο αποκοπής δίνεται παρακάτω:")
15
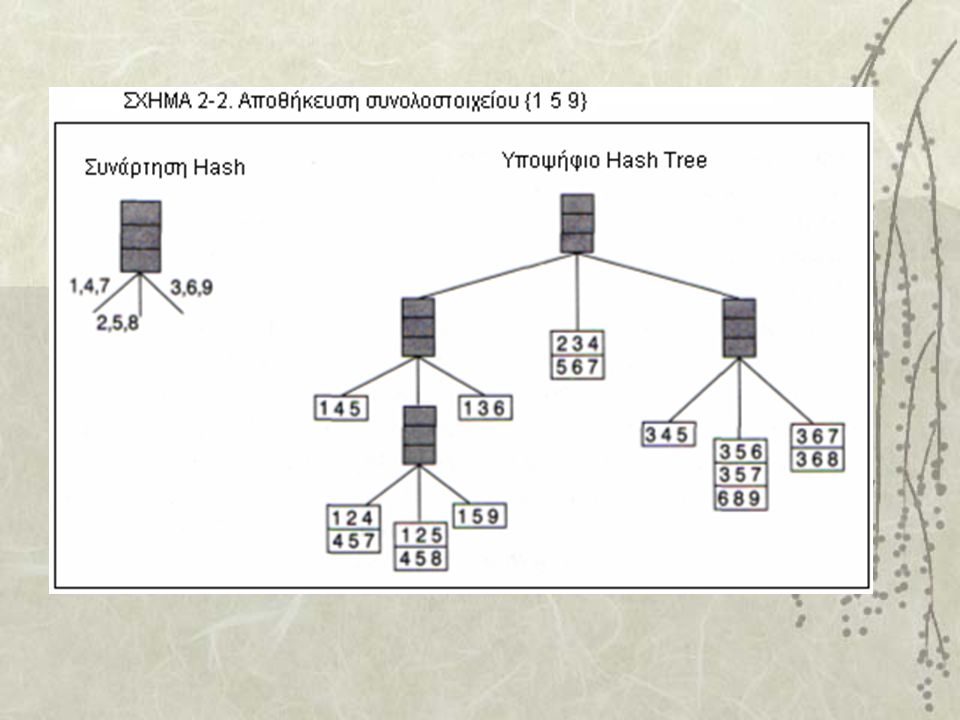
Μέτρηση Εμφανίσεων Τα υποψήφια συνολοστοιχεία C k αποθηκεύονται σε ένα hash-tree (δέντρο κατακερματισμού). Ένας κόμβος του δέντρου αυτού περιέχει είτε μια λίστα από συνολοστοιχεία, αν είναι κόμβος φύλλο, είτε έναν πίνακα κατακερματισμού (hash-table) αν πρόκειται για εσωτερικό κόμβο. Κάθε κουβάς (bucket) του πίνακα κατακερματισμού ενός εσωτερικού κόμβου δείχνει σε έναν άλλο κόμβο. Θεωρώντας ότι η ρίζα του hash-tree έχει βάθος 1, τότε ένας εσωτερικός κόμβος βάθους d δείχνει σε κόμβους βάθους d+1. Τα συνολοστοιχεία επομένως αποθηκεύονται μόνο στα φύλλα, ενώ οι υπόλοιποι κόμβοι περιέχουν πληροφορία για το πώς θα αναζητηθούν τα συνολοστοιχεία.
 αν πρόκειται για εσωτερικό κόμβο. Κάθε κουβάς (bucket) του πίνακα κατακερματισμού ενός εσωτερικού κόμβου δείχνει σε έναν άλλο κόμβο. Θεωρώντας ότι η ρίζα του hash-tree έχει βάθος 1, τότε ένας εσωτερικός κόμβος βάθους d δείχνει σε κόμβους βάθους d+1. Τα συνολοστοιχεία επομένως αποθηκεύονται μόνο στα φύλλα, ενώ οι υπόλοιποι κόμβοι περιέχουν πληροφορία για το πώς θα αναζητηθούν τα συνολοστοιχεία..")
17
Apriori Πλεονεκτήματα/Μειονεκτήματα Πλεονεκτήματα: –Αξιοποίηση ιδιότητας τερματισμού υποσυνόλου –Εύκολα παραλληλοποιήσιμη –Εύκολα υλοποιήσιμη Μειονεκτήματα: –Υποθέτει ότι η Βάση Δεδομένων συναλλαγών είναι αποθηκευμένη στη μνήμη transaction. –Απαιτεί πολλά σαρώματα στη Β.Δ.

18
Μέσω ενός παραδείγματος γίνεται περισσότερο κατανοητή η λειτουργία του αλγορίθμου AprioriTID. Τα ενδιάμεσα καθώς και τα τελικά σύνολα συνολοστοιχείων που προκύπτουν από την εφαρμογή του αλγορίθμου παρουσιάζονται στο Σχήμα 2-6. Η σειρά με την οποία δημιουργούνται τα παρακάτω σύνολα είναι D Ĉ1 L1 C2 Ĉ2 L2 C3 Ĉ3 L3.

20
Αλγόριθμος Δειγματοληψίας D s = Sample drawn from D; PL=Apriory(I,D S, smalls); C=PL BD - (PL); L= ; for each I i C do C i =0; for each t j D do for each I i C do if I i t j then c i =c i +1; Check if I i large and set L=L I i ; ML={x| x BD - (PL) x L} If ML then C=L; Repeat C=C BD - ( C ) until no new items are added to C; Check C for large itemsets.
; C=PL BD - (PL); L= ; for each I i C do C i =0; for each t j D do for each I i C do if I i t j then c i =c i +1; Check if I i large and set L=L I i ; ML={x| x BD - (PL) x L} If ML then C=L; Repeat C=C BD - ( C ) until no new items are added to C; Check C for large itemsets.")
21
Πλεονεκτήματα/Μειονεκτήματα Πλεονεκτήματα: –Μείωση αριθμού σαρωμάτων σε ένα (στην καλύτερη περίπτωση) και δύο (στη χειρότερη) –Κλιμακώνεται καλύτερα από Apriori. Μειονεκτήματα: –Πιθανή παραγωγή μεγάλου αριθμού υποψηφίων στη δεύτερη φάση.

22
Διαμέριση Διαμέρισε τη Βάση Δεδομένων σε διαμερίσεις D 1,D 2,…,D p Εφάρμοσε Apriori σε κάθε διαμέριση Κάθε μεγάλο συνολοστοιχείο πρέπει να είναι μεγάλο σε μία τουλάχιστον διαμέριση.

23
Αλγόριθμος Διαμέρισης 1. Διαμέρισε D σε ομάδες D 1,D 2,…,D p; 2. For i = 1 to p do 3. L i = Apriori(D i ); 4. C = L 1 … L p ; 5. Καταμέτρησε C στο D για παραγωγή L;
; 4. C = L 1 … L p ; 5. Καταμέτρησε C στο D για παραγωγή L;.")
24
Partitioning Πλεονεκτήματα/Μειονεκτήματα Πλεονεκτήματα: –Προσαρμόσιμο στη διαθέσιμη κύρια μνήμη –Εύκολα παραλληλοποιήσιμο –Μέγιστος αριθμός σαρωμάτων:2 Μειονεκτήματα: –Παραγωγή πολλών υποψηφίων στο δεύτερο σάρωμα. Χρήση για Δυναμοποίηση

25
Αυξητικοί Κανόνες Συσχέτισης Σκοπός: Με γνώση μεγάλων συνολοστοιχείων στο D Εντόπισε μεγάλα συνολοστοιχεία στο D {Δ D} Πρέπει να είναι μεγάλα στο D ή στο Δ D Αποθήκευσε L i και πληθικότητες εμφάνισης συνολοστοιχείων και στη συνέχεια μέτρησε μόνο στο ΔD.

26
Παραλληλοποίηση AR Αλγορίθμων Βασίζεται στον Apriori Οι τεχνικές διαφοροποιούνται στο: – τι προσμετρά κάθε κόμβος – πως τα δεδομένα (συναλλαγές) κατανέμονται Παραλληλοποίηση Δεδομένων –Κατανέμονται τα δεδομένα –Count Distribution Algorithm Παραλληλοποίηση Εργασιών –Διαμερίζονται δεδομένα και υποψήφια συνολοστοιχεία –Data Distribution Algorithm
 κατανέμονται Παραλληλοποίηση Δεδομένων –Κατανέμονται τα δεδομένα –Count Distribution Algorithm Παραλληλοποίηση Εργασιών –Διαμερίζονται δεδομένα και υποψήφια συνολοστοιχεία –Data Distribution Algorithm")
27
Count Distribution Algorithm(CDA) 1. Place data partition at each site. 2. In parallel at each site do 3. C 1 = itemsets of size one in i; 4. Count C 1 ; 5. Broadcast counts to all sites; 6. Determine global large itemsets of size 1, L 1 ; 7. i = 1; 8. Repeat 9. i = i + 1; 10. C i = Apriori-Gen(L i-1 ); 11. Count C i ; 12. Broadcast counts to all sites; 13. Determine global large itemsets of size i, L i ; 14. until no more large itemsets found;
; 11. Count C i ; 12. Broadcast counts to all sites; 13. Determine global large itemsets of size i, L i ; 14. until no more large itemsets found;.")
28
CDA Παράδειγμα

29
Κατάταξη Αλγορίθμων Παραγωγής Κ.Σ.

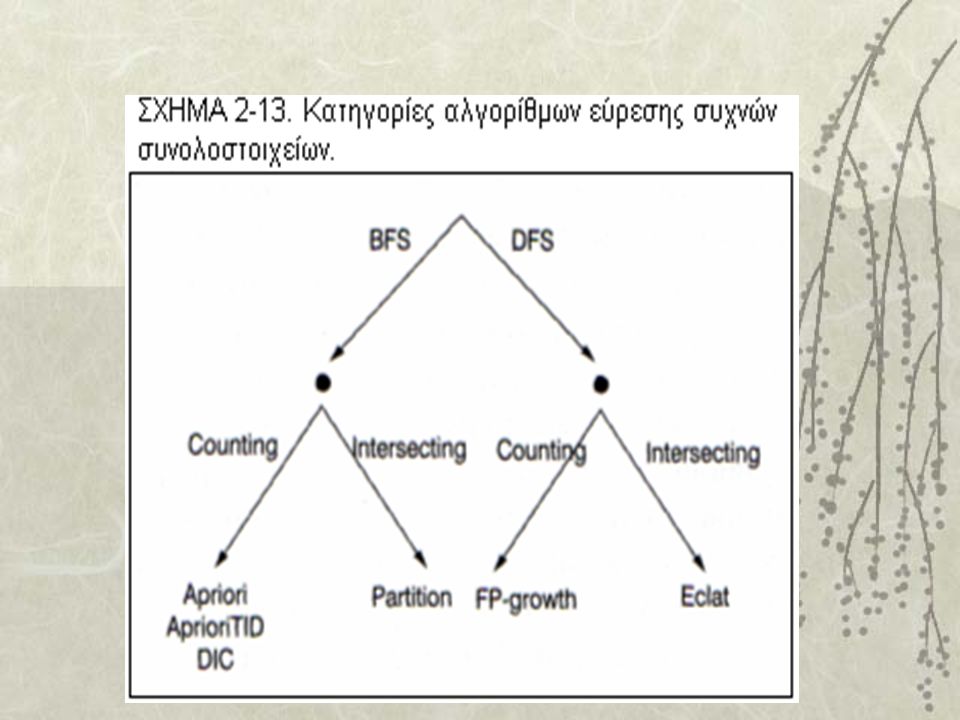
30
Κατάταξη Αλγορίθμων Οι αλγόριθμοι εύρεσης των συχνών συνολοστοιχείων χρησιμοποιούν δύο κυρίως μεθόδους επίσκεψης του παραπάνω δέντρου, την κατά πλάτος αναζήτηση (Breadth- First Search, BFS) και την κατά βάθος αναζήτηση (Depth-First Search, DFS). Με την πρώτη μέθοδο υπολογίζεται η υποστήριξη όλων των (k-1)-συνολοστοιχείων πριν υπολογιστεί η υποστήριξη των k-συνολοστοιχείων. Αντίθετα η δεύτερη μέθοδος χρησιμοποιεί αναδρομική επίσκεψη στο δέντρο μέχρι να βρεθεί κάποιο φύλλο. Ένας άλλος διαχωρισμός των αλγορίθμων είναι με βάση τον τρόπο με τον οποίο υπολογίζεται η υποστήριξη των υποψήφιων συνολοστοιχείων. Η μία μέθοδος είναι να μετριέται απευθείας από τον πίνακα δοσοληψιών πόσες φορές εμφανίζεται ένα συγκεκριμένο συνολοστοιχείο. Για το σκοπό αυτό, χρησιμοποιείται ένας μετρητής και δομές δεδομένων όπως αυτές στον αλγόριθμο Apriori (hash-trees), για να αποθηκεύονται τα υποψήφια συνολοστοιχεία. Η άλλη μέθοδος στηρίζεται στις τομές συνόλων (set intersections).
-συνολοστοιχείων πριν υπολογιστεί η υποστήριξη των k-συνολοστοιχείων. Αντίθετα η δεύτερη μέθοδος χρησιμοποιεί αναδρομική επίσκεψη στο δέντρο μέχρι να βρεθεί κάποιο φύλλο. Ένας άλλος διαχωρισμός των αλγορίθμων είναι με βάση τον τρόπο με τον οποίο υπολογίζεται η υποστήριξη των υποψήφιων συνολοστοιχείων. Η μία μέθοδος είναι να μετριέται απευθείας από τον πίνακα δοσοληψιών πόσες φορές εμφανίζεται ένα συγκεκριμένο συνολοστοιχείο. Για το σκοπό αυτό, χρησιμοποιείται ένας μετρητής και δομές δεδομένων όπως αυτές στον αλγόριθμο Apriori (hash-trees), για να αποθηκεύονται τα υποψήφια συνολοστοιχεία. Η άλλη μέθοδος στηρίζεται στις τομές συνόλων (set intersections)..")
32
Ποσοτικοί Κανόνες Συσχέτισης Μια λύση είναι η κατάτμηση του συνόλου τιμών των ποσοτικών γνωρισμάτων σε διαστήματα και η δημιουργία λογικών γνωρισμάτων που να έχουν την μορφή. Το πρόβλημα συνεπώς ανάγεται στην εύρεση της κατάλληλης κατάτμησης. Υπάρχουν δυο θέματα για τα οποία πρέπει να δοθεί η βέλτιστη λύση. «Minsup». Αν ο αριθμός των διαστημάτων για ένα ποσοτικό γνώρισμα είναι μεγάλος, τότε η υποστήριξη ενός διαστήματος μπορεί να είναι μικρή. Κατά συνέπεια αν δεν χρησιμοποιηθούν μεγαλύτερα διαστήματα μπορεί να μην παραχθούν κάποιοι κανόνες για αυτό το γνώρισμα καθώς δεν θα έχουν την ελάχιστη υποστήριξη. «Minconf». Υπάρχει κόστος που συνεπάγεται ο χωρισμός των τιμών σε διαστήματα. Πληροφορία χάνεται όσο το μέγεθος των διαστημάτων μεγαλώνει καθώς μερικοί κανόνες μπορεί να έχουν ελάχιστη εμπιστοσύνη (minimum confidence) μόνο όταν το πρώτο μέλος αποτελείται από μικρό διάστημα (μικρή εμπιστοσύνη). Η λύση που προτάθηκε είναι η κατάτμηση να δημιουργήσει μικρά διαστήματα τα οποία στη συνέχεια ενώνονται για να φτιάξουν καινούρια, μεγαλύτερα και με μεγαλύτερη υποστήριξη.
 μόνο όταν το πρώτο μέλος αποτελείται από μικρό διάστημα (μικρή εμπιστοσύνη). Η λύση που προτάθηκε είναι η κατάτμηση να δημιουργήσει μικρά διαστήματα τα οποία στη συνέχεια ενώνονται για να φτιάξουν καινούρια, μεγαλύτερα και με μεγαλύτερη υποστήριξη..")
33
Αντιπροσωπευτικοί Κ.Σ. Το σύνολο όλων των κανόνων συσχέτισης που ικανοποιούν τις απαιτήσεις για ελάχιστη υποστήριξη s και ελάχιστη εμπιστοσύνη c θα το αποκαλούμε εν συντομία AR(s,c). Εάν τα s και c εννοούνται τότε μπορούμε να γράφουμε απλά AR. Η κάλυψη C ενός κανόνα Χ Υ, ορίζεται ως εξής:
. Εάν τα s και c εννοούνται τότε μπορούμε να γράφουμε απλά AR. Η κάλυψη C ενός κανόνα Χ Υ, ορίζεται ως εξής:.")
34
Ιδιότητες (1) Ιδιότητα 1 Έστω r ένας κανόνας συσχέτισης με υποστήριξη s και εμπιστοσύνη c. Κάθε κανόνας r΄ που ανήκει στην κάλυψη C(r) είναι ένας κανόνας συσχέτισης που έχει υποστήριξη όχι μικρότερη από s και εμπιστοσύνη όχι μικρότερη από c. Η άμεση συνέπεια της ιδιότητας αυτής είναι ότι αν ένας κανόνας r ανήκει στο AR(s,c), τότε κάθε κανόνας r΄από το C(r) θα ανήκει επίσης στο AR(s,c). Ιδιότητα 2 Έστω δύο κανόνες συσχέτισης r : X Y και r΄= (Χ΄ Υ΄). Τότε ο r θα ανήκει στην κάλυψη του r΄ C(r΄) αν και μόνο αν X Y Χ΄ Υ΄ και Χ Χ΄. Δηλαδή r C(r΄) X Y Χ΄ Υ΄ Χ Χ΄.
 είναι ένας κανόνας συσχέτισης που έχει υποστήριξη όχι μικρότερη από s και εμπιστοσύνη όχι μικρότερη από c. Η άμεση συνέπεια της ιδιότητας αυτής είναι ότι αν ένας κανόνας r ανήκει στο AR(s,c), τότε κάθε κανόνας r΄από το C(r) θα ανήκει επίσης στο AR(s,c). Ιδιότητα 2 Έστω δύο κανόνες συσχέτισης r : X Y και r΄= (Χ΄ Υ΄). Τότε ο r θα ανήκει στην κάλυψη του r΄ C(r΄) αν και μόνο αν X Y Χ΄ Υ΄ και Χ Χ΄. Δηλαδή r C(r΄) X Y Χ΄ Υ΄ Χ Χ΄..")
35
Ιδιότητα 3 (i) Αν ένας κανόνας συσχέτισης r είναι μεγαλύτερος (περιέχει περισσότερα αντικείμενα) από έναν κανόνα συσχέτισης r΄ τότε r C(r΄). (ii) Αν ένας κανόνας συσχέτισης r : (X Y) είναι μικρότερος από έναν κανόνα συσχέτισης r΄: (Χ΄ Υ΄) τότε r C(r΄) αν και μόνο αν X Y Χ΄ Υ΄ και Χ Χ΄. (iii) Αν r : (X Y) και r΄: (Χ΄ Υ΄) είναι διαφορετικοί κανόνες συσχέτισης με το ίδιο μήκος (ίδιο αριθμό από αντικείμενα) τότε r C(r΄) αν και μόνο αν X Y = Χ΄ Υ΄ και Χ Χ΄. Αντιπροσωπευτικοί Κανόνες Συσχέτισης Ιδιότητα 1 Εάν r RR(s, c) τότε C(r) AR(s, c). Ιδιότητα 2 r AR(s, c) r΄ RR(s, c) : r C(r’).
 Αν ένας κανόνας συσχέτισης r : (X Y) είναι μικρότερος από έναν κανόνα συσχέτισης r΄: (Χ΄ Υ΄) τότε r C(r΄) αν και μόνο αν X Y Χ΄ Υ΄ και Χ Χ΄. (iii) Αν r : (X Y) και r΄: (Χ΄ Υ΄) είναι διαφορετικοί κανόνες συσχέτισης με το ίδιο μήκος (ίδιο αριθμό από αντικείμενα) τότε r C(r΄) αν και μόνο αν X Y = Χ΄ Υ΄ και Χ Χ΄. Αντιπροσωπευτικοί Κανόνες Συσχέτισης Ιδιότητα 1 Εάν r RR(s, c) τότε C(r) AR(s, c). Ιδιότητα 2 r AR(s, c) r΄ RR(s, c) : r C(r’)..")
36
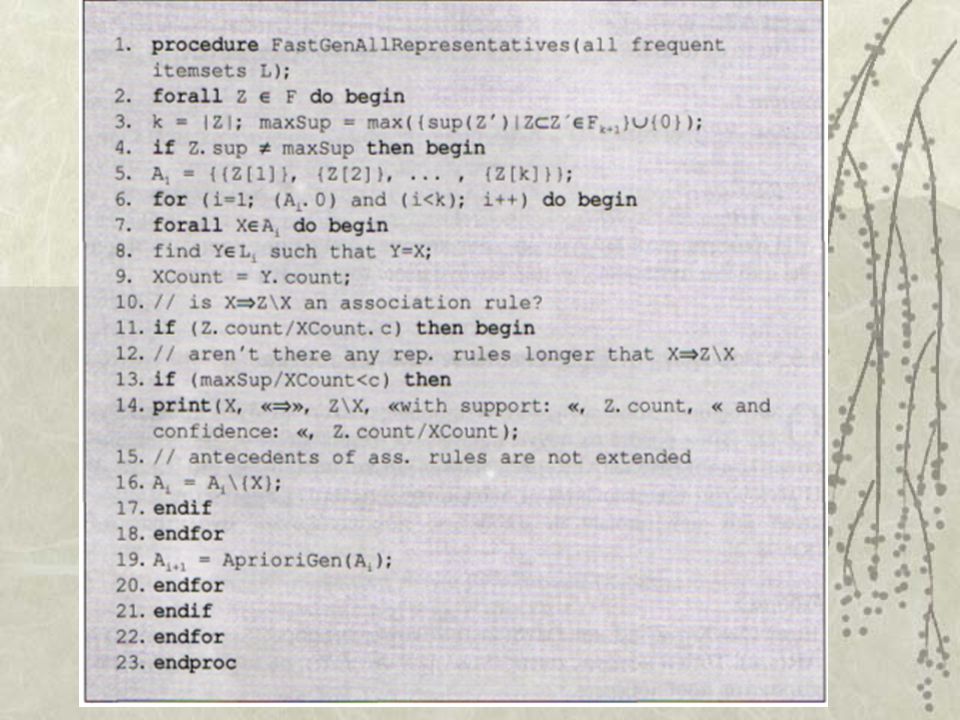
Παραγωγή Αντιπροσωπευτικών Κ.Σ. Ιδιότητα 1 Έστω X Z I και r είναι ένας κανόνας της μορφής r : (X Y) AR(s, c). Τότε ο κανόνας αυτός θα ανήκει στο RR(s,c), αν ισχύουν οι δυο επόμενες προϋποθέσεις. (i) maxSup s ή maxSup|sup(X) < c, όπου sup maxSup = max({sup(Z΄) | Z Z΄ (I} {0}) (ii) Χ΄, Χ΄ X τέτοιο ώστε (Χ΄ Ζ\Χ΄) AR(s,c) Η πρώτη συνθήκη εξασφαλίζει ότι ο κανόνας r δεν βρίσκεται στην κάλυψη κάποιου κανόνα μεγαλύτερου από τον r. Η δεύτερη συνθήκη εξασφαλίζει ότι ο κανόνας r δεν βρίσκεται στην κάλυψη κάποιου κανόνα με μήκος ίσο με τον r. Ιδιότητα 2 Έστω Z Z΄ I. Αν sup(Z) = sup(Z΄)τότε κανένας κανόνας της μορφής (Χ Ζ\Χ) AR(s,c) με X Z δεν ανήκει στο RR (s,c).
 AR(s, c). Τότε ο κανόνας αυτός θα ανήκει στο RR(s,c), αν ισχύουν οι δυο επόμενες προϋποθέσεις. (i) maxSup s ή maxSup|sup(X) < c, όπου sup maxSup = max({sup(Z΄) | Z Z΄ (I} {0}) (ii) Χ΄, Χ΄ X τέτοιο ώστε (Χ΄ Ζ\Χ΄) AR(s,c) Η πρώτη συνθήκη εξασφαλίζει ότι ο κανόνας r δεν βρίσκεται στην κάλυψη κάποιου κανόνα μεγαλύτερου από τον r. Η δεύτερη συνθήκη εξασφαλίζει ότι ο κανόνας r δεν βρίσκεται στην κάλυψη κάποιου κανόνα με μήκος ίσο με τον r. Ιδιότητα 2 Έστω Z Z΄ I. Αν sup(Z) = sup(Z΄)τότε κανένας κανόνας της μορφής (Χ Ζ\Χ) AR(s,c) με X Z δεν ανήκει στο RR (s,c)..")
38
Σύγκριση Τεχνικών Κ.Σ.

39
Παρατηρήσεις Πολλές εφαρμογές εκτός ανάλυσης καλαθιού αγορών Πρόβλεψη (telecom switch failure) Web usage mining Πολλοί διαφορετικοί τύποι Κ.Σ. Χρονικοί Χωρικοί

40
Μέτρα Ενδιαφέροντος Κανόνων Συσχέτισης Έστω ο κανόνας LHS -> RHS. Ορίζουμε: --Κάλυψη=n(LHS)/N=P(LHS) -- Leverage=p(RHS/LHS)-[p(LHS)p(RHS)] To leverage παίρνει τις τιμές στο διάστημα [-1, 1]. Οι τιμές κάτω από το 0 δείχνουν ισχυρή ανεξαρτησία LHS, και RHS. -- Lift= = Lift->1, τα RHS, LHS είναι ανεξάρτητα. Lift ->0, o κανόνας δεν είναι σημαντικός Lift -> ενδεχομένως ο κανόνας είναι ενδιαφέρων -- conviction= (1->A,B δεν σχετίζονται, αν ισχύουν)
/N=P(LHS) -- Leverage=p(RHS/LHS)-[p(LHS)p(RHS)] To leverage παίρνει τις τιμές στο διάστημα [-1, 1]. Οι τιμές κάτω από το 0 δείχνουν ισχυρή ανεξαρτησία LHS, και RHS. -- Lift= = Lift->1, τα RHS, LHS είναι ανεξάρτητα. Lift ->0, o κανόνας δεν είναι σημαντικός Lift -> ενδεχομένως ο κανόνας είναι ενδιαφέρων -- conviction= (1->A,B δεν σχετίζονται, αν ισχύουν).")
41
Προχωρημένες Τεχνικές Κ.Σ. Γενικευμένοι Κ.Σ. Χρησιμοποιώντας πολλαπλά minimum supports Correlation Rules (επιτρέπονται και αρνητικές συσχετίσεις)
.")
Παρόμοιες παρουσιάσεις






 TexPoint fonts used in EMF. Read the TexPoint manual before you delete this box.: AA A A A Έχουμε αποθηκεύσει.>")







=α, κκπ(τ,σ)=ν, κκπ(λ,π)=η κκπ(π,σ)=γ, κκπ(ξ,ο)=κ ξο κκπ(ι,ξ)=β, κκπ(τ,θ)=θ, κκπ(ο,μ)=α.>")


 (Ι) Είναι μια δομή στην οποία αποθηκεύονται τα ονόματα ενός προγράμματος και.>")


