Κατέβασμα παρουσίασης
Η παρουσίαση φορτώνεται. Παρακαλείστε να περιμένετε

1
Νευρωνικά Δίκτυα και Latent Semantic Indexing 1.Άλλα αλγεβρικά συστήματα που αξιοποιούν εξάρτηση όρων (α) Μοντέλο Νευρωνικών Δικτύων (β) Μοντέλο Λανθάνουσας Σημασιολογικής Δεικτοδότησης 2.Βασικές Έννοιες (α) Υπάρχει ιδεατός χώρος σε υψηλότερο επίπεδο από όρους (β)Οι όροι είναι εκφράσεις εννοιών (γ) Μετακίνηση από χώρο όρων σε χώρο υψηλότερου επιπέδου αναπαράστασης
 Μοντέλο Νευρωνικών Δικτύων (β) Μοντέλο Λανθάνουσας Σημασιολογικής Δεικτοδότησης 2.Βασικές Έννοιες (α) Υπάρχει ιδεατός χώρος σε υψηλότερο επίπεδο από όρους (β)Οι όροι είναι εκφράσεις εννοιών (γ) Μετακίνηση από χώρο όρων σε χώρο υψηλότερου επιπέδου αναπαράστασης")
3
1.Μοντέλο Νευρωνικών Δικτύων (α) προσομοίωση ανθρώπινου μυαλού (β) Input Layer: query terms (γ) Output Layer: documents (δ) ενεργοποίηση όρων και μετάδοση πληροφορίας προς κείμενα (ε) επικοινωνία αμφίδρομη 2. Latent Semantic Indexing (α) Δημιουργία χώρου μικρών διαστάσεων για έννοιες (β) Βασίζεται στο SVD (γ) Προσέγγιση μικρής τάξεως (δ) Προβολή του διανύσματος ερώτησης σε χώρου μικρής τάξεως
 Δημιουργία χώρου μικρών διαστάσεων για έννοιες (β) Βασίζεται στο SVD (γ) Προσέγγιση μικρής τάξεως (δ) Προβολή του διανύσματος ερώτησης σε χώρου μικρής τάξεως.")
4
1.Εξομοιώσεις (α) Artificial Neural Networks (β)Κατευθυνόμενοι Ζυγισμένοι Γράφοι (γ) Κόμβοι=Νευρώνες (δ)Οι κόμβοι έχουν επίπεδο ενεργοποίησης (ε)Ενεργοποίηση Κόμβου=Ζυγισμένο Άθροισμα των επιπέδων ενεργοποίησης Συνδεόμενων Κόμβων 2. Εφαρμόζεται σε: (α) Image and Speech Recoginition (β)Adaptive Control Systems (γ) Models of Human Behavior 3. Θεωρία Συνάψεων (α)Συσχετισμός stimulus-response προτύπων ενεργοποίησης (β)Δύο learning paradigms (supervised και unsupervised) (γ)Υλοποίηση συγκεκριμένων αλγορίθμων μάθησης (δ) Δομή Δικτύων Recurrent (SOM) Feedforward (perceptrons)
 Image and Speech Recoginition (β)Adaptive Control Systems (γ) Models of Human Behavior 3. Θεωρία Συνάψεων (α)Συσχετισμός stimulus-response προτύπων ενεργοποίησης (β)Δύο learning paradigms (supervised και unsupervised) (γ)Υλοποίηση συγκεκριμένων αλγορίθμων μάθησης (δ) Δομή Δικτύων Recurrent (SOM) Feedforward (perceptrons).")
5
Μοντέλο Νευρωνικού Δικτύου (1)
")
6
Μοντέλο Νευρωνικού Δικτύου (2)
")
7
Retrieval: Διαδικασία μετάδοσης Ενεργοποίησης

8
Retrieval (υπολογισμών μετρικών)
")
9
LSI (Latent Semantic Indexing) Μέθοδος ανάκτησης πληροφορίας βασισμένη στο εννοιολογικό περιεχόμενο των ερωτήσεων αναζήτησης. Αυτόματη μέθοδος. Ικανοποιητικά αποτελέσματα. Αντιμετώπιση προβλημάτων κλασικών μεθόδων ανάκτησης πληροφορίας. Πλήθος εφαρμογών.

10
Κλασικές μέθοδοι ανάκτησης πληροφορίας Χαρακτηριστικό: Ανάκτηση βασίζεται στη λέξη. Αναζητείται ταύτιση λέξεων μεταξύ της ερώτησης του χρήστη και των κειμένων αναζήτησης. Προβλήματα: Ανάκτηση άσχετης πληροφορίας (50% ή περισσότερο). Αποτυχία ανάκτησης σχετικής πληροφορίας (περίπου 80%).
. Αποτυχία ανάκτησης σχετικής πληροφορίας (περίπου 80%)..")
11
ΑΙΤΙΕΣ (1) Συνωνυμία: (Πολλοί τρόποι για να αναφερθούμε στο ίδιο αντικείμενο) Χρήστες με διαφορετικές ανάγκες, διαφορετικές γνώσεις ή διαφορετικές γλωσσικές συνήθειες θα περιγράψουν την ίδια πληροφορία με διαφορετικούς όρους. Στατιστικά δύο άνθρωποι εμφανίζουν την τάση να χρησιμοποιήσουν την ίδια λέξη κλειδί για να περιγράψουν ένα ευρέως γνωστό αντικείμενο σε ποσοστό μικρότερο από 20% τη φορά.

12
ΑΙΤΙΕΣ (2) Πολυσημία: Περισσότερες λέξεις δεν έχουν μόνο μία σημασία. Ένας όρος σε διαφορετικά έγγραφα ή όταν χρησιμοποιείται από διαφορετικούς ανθρώπους αποκτά διαφορετική αναφορική σημασία. Παρουσία ενός όρου στην ερώτηση κάποιου χρήστη δε σημαίνει απαραίτητα ότι το έγγραφο που περιέχει τον όρο αυτό ή τον έχει ως τίτλο είναι και σχετικό με την ερώτηση του χρήστη.

13
Συνέπειες συνωνυμία => αποτυχία ανάκτησης σημαντικού μέρους σχετιζόμενης πληροφορίας πολυσημία => ανάκτηση άσχετης πληροφορίας

14
Γιατί LSI; Αντιμετώπιση προβλημάτων συνωνυμίας και πολυσημίας. Οργάνωση αντικειμένων σε σημασιολογική δομή κατάλληλη για την ανάκτηση πληροφορίας. Τοποθέτηση εγγράφων με σημασιολογική συσχέτιση κοντά το ένα στο άλλο στο χώρο όρων-εγγράφων ανεξάρτητα από την ύπαρξη ή όχι κοινών όρων μεταξύ τους. Δυνατότητα διαχείρισης μεγάλων συνόλων δεδομένων. Γεωμετρική αναπαράσταση. Ευκολία στη χρήση

15
Βασικά στάδια LSI Δημιουργία πίνακα όρων-εγγράφων. Διάσπαση ιδιόμορφων τιμών (SVD). Μειωμένης διάστασης διάσπαση ιδιόμορφων τιμών (Reduced SVD). Αναπαράσταση-Συσχετισμός ερωτήσεων χρήστη.
. Μειωμένης διάστασης διάσπαση ιδιόμορφων τιμών (Reduced SVD). Αναπαράσταση-Συσχετισμός ερωτήσεων χρήστη..")
16
Δημιουργία πίνακα όρων-εγγράφων: Συγκέντρωση εγγράφων. Απομόνωση μοναδικών όρων-λέξεων από έγγραφα. Καταγραφή τους με πολλαπλότητα Εννοιολογική αποτύπωση σε διανυσματικό χώρο. Κριτήριο ομοιότητας δύο εγγράφων: Εσωτερικό γινόμενο ή συνημίτονο γωνίας διανυσμάτων αναπαράστασης των εγγράφων. Διανυσματικός χώρος αναπαρίσταται μαθηματικά από πίνακα όρων-εγγράφων. Εάν t όροι, d έγγραφα τότε: διάσταση πίνακα = t*d Κάθε γραμμή του πίνακα αντιστοιχεί σε έναν όρο. Για κάθε έγγραφο παραχωρείται μια στήλη του πίνακα. Πίνακας συνήθως αραιός Υπενθύμιση

17
SVD (Singular Value Decomposition): Διάσπαση πίνακα όρων-εγγράφων σε σύνολο ορθογώνιων παραγόντων. Πλήθος παραγόντων: 50-150. Προσέγγιση αρχικού πίνακα με γραμμικό συνδυασμό. Εάν X πίνακας όρων-εγγράφων διάστασης t*d τότε ισχύει: T 0,D 0 : ορθογώνιοι κανονικοποιημένοι πίνακες S 0 : διαγώνιος πίνακας

18
X = T0T0 S0S0 D0ΤD0Τ t*d t*m m*m m*d termsterms documents S 0 : πίνακας ιδιόμορφων τιμών Χ Τ 0 : πίνακας αριστερών ιδιόμορφων διανυσμάτων D 0 : πίνακας δεξιών ιδιόμορφων διανυσμάτων t: αριθμός γραμμών Χ d: αριθμός στηλών Χ m: τάξη Χ

19
Reduced SVD: Προσέγγιση πίνακα X από πίνακα μικρότερων διαστάσεων. Εάν οι ιδιόμορφες τιμές στον S 0 είναι ταξινομημένες κατά μέγεθος τότε διατηρούνται οι k μεγαλύτερες και οι υπόλοιπες θέτονται ίσες με μηδέν. Μηδενικές γραμμές και στήλες του S 0 διαγράφονται. Στήλες των T 0 και D 0 που περιέχουν τα αντίστοιχα ιδιόμορφα διανύσματα των μηδενικών τιμών διαγράφονται. Νέοι πίνακες T,S,D μετά τη διαγραφή. Νέος πίνακας:

20
X new = T SDΤDΤ t*d t*k k*kk*d termsterms documents S: πίνακας ιδιόμορφων τιμών μειωμένης διάστασης Τ: πίνακας αριστερών ιδιόμορφων διανυσμάτων μειωμένης διάστασης D: πίνακας δεξιών ιδιόμορφων διανυσμάτων μειωμένης διάστασης k: τάξη X hihat

21
Αναπαράσταση-Συσχετισμός ερωτήσεων χρήστη : Μετασχηματισμός ερωτήσεων χρήστη σε ψευδο-έγγραφα. Προσδιορισμός θέσης ερώτησης χρήστη στο διανυσματικό χώρο όρων-εγγράφων από το αντίστοιχο ψευδο-έγγραφο. Επιστροφή κοντινών στο διάνυσμα ερώτησης χρήστη εγγράφων ως σχετικών. Κριτήριο εγγύτητας διανυσμάτων ερώτησης-εγγράφων: Εσωτερικό γινόμενο ή συνημίτονο γωνίας διανυσμάτων. (όσο μεγαλύτερη η τιμή του συνημίτονου τόσο πιο «σχετικό» είναι το έγγραφο) Επιστροφή σχετικών εγγράφων σε διατεταγμένη λίστα με βάση το μέτρο ομοιότητας (συνημίτονο).
 Επιστροφή σχετικών εγγράφων σε διατεταγμένη λίστα με βάση το μέτρο ομοιότητας (συνημίτονο)..")
22
Τεχνικές Λεπτομέρειες Οι γραμμές του DS χρησιμοποιούνται για αναπαράσταση κειμένων. Με άλλα λόγια οι στήλες του Χ προβάλλονται στο χώρο που παράγεται από τις στήλες του Τ. Σύγκριση δύο όρων ΧΧ T = ΤS 2 T' Σύγκριση δύο εγγράφων Χ T Χ=DS 2 D' Σύγκριση ενός όρου και ενός εγγράφου Χ=ΤS 1/2 S 1/2 D' Ερωτήσεις (queries) q=q 0 T TS -1
 q=q 0 T TS -1.")
23
Βελτίωση απόδοσης LSI Παράμετροι απόδοσης. Συναρτήσεις βάρους. Relevance Feedback. Επιλογή αριθμού διαστάσεων.

24
Επιλογή αριθμού διαστάσεων: κρίσιμο θέμα πολύ μικρό μέγεθος => απώλεια δεδομένων πολύ μεγάλο μέγεθος => ασήμαντες λεπτομέρειες σημαντική αύξηση απόδοσης μετά τις 10-20 διαστάσεις κορύφωση απόδοσης στις 70-100 διαστάσεις πτώση απόδοσης πάνω από τις 100 διαστάσεις συνήθως επιλογή 100 διαστάσεων ως μεγέθους με αρκετά καλή απόδοση

25
Εφαρμογές LSI Πολυγλωσσικό λεξικό Μοντελοποίηση ανθρώπινης σκέψης Αυτόματη βαθμολόγηση εκθέσεων Information filtering

26
Cross-Language Retrieval με χρήση LSI: Μετάφραση αρχικού δείγματος κειμένων από άνθρωπο ή μηχανή και μετατροπή τους σε δοκιμαστικά πολυγλωσσικά κείμενα (training multilingual documents). Χρήση training documents για την κατασκευή εννοιολογικού LSI-χώρου. LSI-χώρος περιέχει όρους από όλες τις γλώσσες που χρησιμοποιούνται στην εφαρμογή. Εισαγωγή κειμένων (foldin) οποιασδήποτε γλώσσας στον LSI- χώρο ως διανυσμάτων αριθμών (ανεξάρτητων της γλώσσας του κειμένου). Πραγματοποίηση ερωτήσεων σε οποιαδήποτε γλώσσα και επιστροφή σχετικών κειμένων ανεξαρτήτως γλώσσας.
 οποιασδήποτε γλώσσας στον LSI- χώρο ως διανυσμάτων αριθμών (ανεξάρτητων της γλώσσας του κειμένου). Πραγματοποίηση ερωτήσεων σε οποιαδήποτε γλώσσα και επιστροφή σχετικών κειμένων ανεξαρτήτως γλώσσας..")
27
Χρήσεις Cross-Language Retrieval: Γλωσσολογική και λογοτεχνική έρευνα Σχεδιασμός μεταφραστικών συστημάτων Δημιουργία πολυγλωσσικών λεξικών Μεταφραστές Λεξικογράφοι

28
LSI και Διαδικασία μάθησης Το LSI εμφανίζει ομοιότητες με Μάθηση γλώσσας Μάθηση γραμματικής Νευρωνικά δίκτυα

29
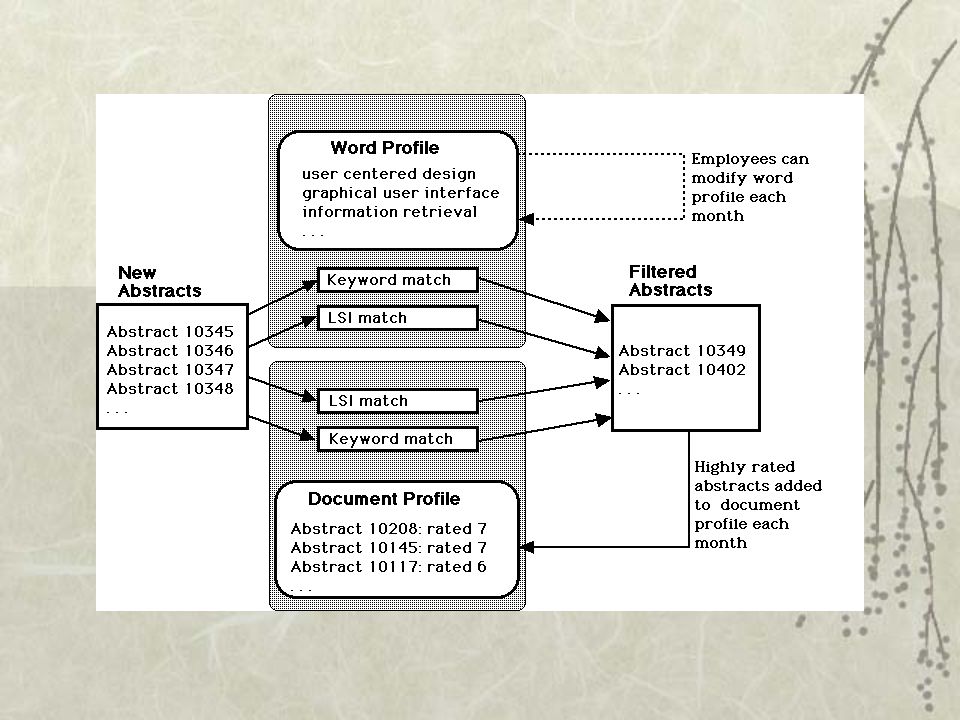
Φιλτράρισμα με χρήση του LSI Δημιουργία σημασιολογικού χώρου για άρθρα που έχουν κριθεί από τον χρήστη πως έχουν «ενδιαφέροντα» θέματα ή όχι στον οποίο αναδιπλώνεται κάθε αναζήτηση. Ο χώρος λοιπόν δομείται εξ’ ολοκλήρου από τη σημασιολογία της πληροφορίας. Δημιουργούνται πολλαπλές συγκεντρώσεις σχετικών άρθρων για διαφορετικούς τύπους σύμφωνα με τα ενδιαφέροντα κάθε χρήστη.

30
Ανάλυση μεθόδων φιλτραρίσματος πληροφορίας Ανάκτηση πληροφορίας με: Λέξεις-κλειδιά LSI Περιγραφή των τεχνικών ενδιαφερόντων του χρήστη με : Λέξεις-κλειδιά feedback

31
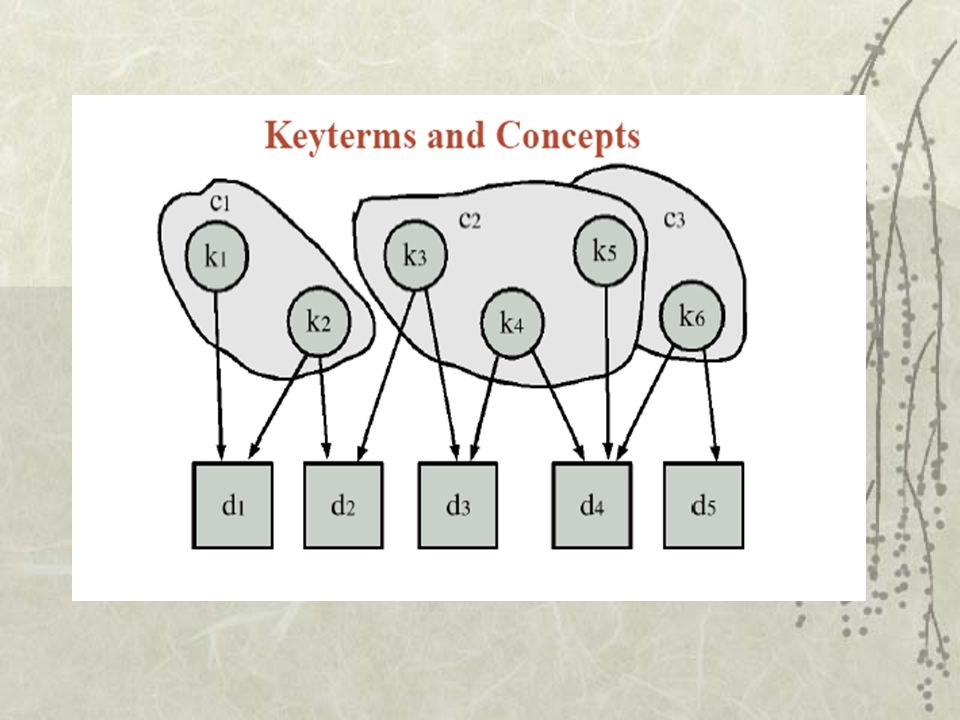
Matching Method Type of profile KeywordLSI WordsKeyword match - Word profile LSI match - Word profile DocumentsKeyword match - Document profile LSI match - Document profile 4 Μέθοδοι Φιλτραρίσματος

33
Συμπίεση (1) στην αποθήκευση στην μεταφορά δεδομένων μέσα από δίκτυα στην διαχείριση τους Οι μέθοδοι συμπίεσης διακρίνονται σε: Μεθόδους χωρίς απώλεια πληροφορίας που χρησιμοποιούν μη απωλεστικούς (lossless) αλγορίθμους. Οι συγκεκριμένες μέθοδοι συμπιέζουν τα δεδομένα με τέτοιοι τρόπο, ώστε να μην υπάρχει απώλεια πληροφορίας, ενώ επιτυγχάνουν μέτριο λόγο συμπίεσης. Έτσι μία εικόνα που συμπιέστηκε με μια τέτοια μέθοδο είναι ίδια με την αρχική, όταν αποσυμπιεστεί. Μεθόδους με απώλεια πληροφορίας που συμπιέζουν τα δεδομένα απορρίπτοντας μη ουσιώδη πληροφορία. Οι συγκεκριμένες μέθοδοι χρησιμοποιούν απωλεστικούς (lossy) αλγορίθμους και επιτυγχάνουν υψηλό λόγο συμπίεσης.
 αλγορίθμους και επιτυγχάνουν υψηλό λόγο συμπίεσης..")
34
Συμπίεση (2) Μία απλοποιημένη ταξινόμηση των τεχνικών συμπίεσης είναι: Κωδικοποίηση Εντροπίας (entropy coding) - δεν λαμβάνεται υπόψη το είδος της πληροφορίας που θα συμπιεστεί - αντιμετωπίζεται η πληροφορία ως απλή ακολουθία bits - κωδικοποίηση χωρίς απώλειες Κωδικοποίηση Πηγής (source encoding) - οι μετασχηματισμοί που υφίσταται το αρχικό σήμα εξαρτώνται άμεσα από το τύπο του - μπορούν να παράγουν μεγαλύτερα ποσοστά συμπίεσης - μειονεκτούν σε σταθερότητα - λειτουργεί με απώλειες και χωρίς απώλειες.
 Μία απλοποιημένη ταξινόμηση των τεχνικών συμπίεσης είναι: Κωδικοποίηση Εντροπίας (entropy coding) - δεν λαμβάνεται υπόψη το είδος της πληροφορίας που θα συμπιεστεί - αντιμετωπίζεται η πληροφορία ως απλή ακολουθία bits - κωδικοποίηση χωρίς απώλειες Κωδικοποίηση Πηγής (source encoding) - οι μετασχηματισμοί που υφίσταται το αρχικό σήμα εξαρτώνται άμεσα από το τύπο του - μπορούν να παράγουν μεγαλύτερα ποσοστά συμπίεσης - μειονεκτούν σε σταθερότητα - λειτουργεί με απώλειες και χωρίς απώλειες.")
35
Συμπίεση (3) Τεχνικές Κωδικοποίησης Εντροπίας - περιορισμός επαναλαμβανόμενων ακολουθιών - στατιστική κωδικοποίηση Τεχνικές Κωδικοποίησης Πηγής - κωδικοποίηση μετασχηματισμού - διαφορική ή προβλεπτική κωδικοποίηση - διανυσματική κβαντοποίηση.
 Τεχνικές Κωδικοποίησης Εντροπίας - περιορισμός επαναλαμβανόμενων ακολουθιών - στατιστική κωδικοποίηση Τεχνικές Κωδικοποίησης Πηγής - κωδικοποίηση μετασχηματισμού - διαφορική ή προβλεπτική κωδικοποίηση - διανυσματική κβαντοποίηση.")
36
Κωδικοποίηση Μετασχηματισμού Η κωδικοποίηση μετασχηματισμού χρησιμοποιείται συνήθως στη συμπίεση εικόνων. Στη κωδικοποίηση μετασχηματισμού, το σήμα υφίσταται ένα μαθηματικό μετασχηματισμό από το αρχικό πεδίο του χρόνου ή του χώρου σε ένα αφηρημένο πεδίο το οποίο είναι πιο κατάλληλο για συμπίεση. Αυτή η διαδικασία είναι αντιστρεπτή, δηλαδή υπάρχει ο αντίστροφος μετασχηματισμός που θα επαναφέρει το σήμα στην αρχική του μορφή. Ένα τέτοιος μετασχηματισμός είναι ο μετασχηματισμός Fourier. Μέσω του μετασχηματισμού Fourier μια συνάρτηση του χρόνου f(t) μπορεί να μετασχηματιστεί σε μια g(λ) στο πεδίο των συχνοτήτων. Στη φασματική (στο πεδίο των συχνοτήτων) αναπαράσταση των εικόνων, οι συχνότητες περιγράφουν πόσο γρήγορα μεταβάλλονται τα χρώματα και η απόλυτη φωτεινότητα. Εκτός από τον μετασχηματισμό Fourier υπάρχουν και άλλοι, όπως οι μετασχηματισμοί των Hadamar, Haar και των Karhunen-Loeve. Ανάλογα με τις ιδιότητες του τύπου της πληροφορίας που θέλουμε να συμπιέσουμε, επιλέγουμε και τον καταλληλότερο μετασχηματισμό.
 μπορεί να μετασχηματιστεί σε μια g(λ) στο πεδίο των συχνοτήτων. Στη φασματική (στο πεδίο των συχνοτήτων) αναπαράσταση των εικόνων, οι συχνότητες περιγράφουν πόσο γρήγορα μεταβάλλονται τα χρώματα και η απόλυτη φωτεινότητα. Εκτός από τον μετασχηματισμό Fourier υπάρχουν και άλλοι, όπως οι μετασχηματισμοί των Hadamar, Haar και των Karhunen-Loeve. Ανάλογα με τις ιδιότητες του τύπου της πληροφορίας που θέλουμε να συμπιέσουμε, επιλέγουμε και τον καταλληλότερο μετασχηματισμό..")
37
Διαφορική Κωδικοποίηση 1. Απλή Διαφορική Παλμοκωδική Διαμόρφωση (DPCM) Η διαφορική παλμοκωδική διαμόρφωση είναι η πιο απλή από τις τρεις μορφές διαφορικής κωδικοποίησης. Η προβλεπόμενη τιμή κάθε δείγματος είναι απλά η τιμή του προηγούμενου δείγματος. 2. Δέλτα Διαμόρφωση Στη δέλτα διαμόρφωση, η διαφορά μεταξύ της προβλεπόμενης και της τρέχουσας τιμής του δείγματος κωδικοποιείται με ένα μόνο bit. Αυτό σημαίνει ότι κάθε δείγμα μπορεί να είναι είτε μεγαλύτερο είτε μικρότερο κατά ένα κβάντο από το προηγούμενο του. Η δέλτα διαμόρφωση είναι κατάλληλη για σήματα χαμηλών συχνοτήτων. 3. Προσαρμοστική Διαφορική Παλμοκωδική Διαμόρφωση. Στην ADPCM, αντί να χρησιμοποιείται ένας σταθερός μηχανισμός πρόβλεψης, χρημοποιείται ένας δυναμικός μηχανισμός που προσαρμόζεται ανάλογα με τα χαρακτηριστικά του προς δειγματοληψία σήματος. Κατά τα άλλα, όπως και στην απλή DPCM, μόνο η διαφορά μεταξύ της πραγματικής και της προβλεπόμενης τιμής κάθε δείγματος μεταδίδεται.
 Η διαφορική παλμοκωδική διαμόρφωση είναι η πιο απλή από τις τρεις μορφές διαφορικής κωδικοποίησης. Η προβλεπόμενη τιμή κάθε δείγματος είναι απλά η τιμή του προηγούμενου δείγματος. 2. Δέλτα Διαμόρφωση Στη δέλτα διαμόρφωση, η διαφορά μεταξύ της προβλεπόμενης και της τρέχουσας τιμής του δείγματος κωδικοποιείται με ένα μόνο bit. Αυτό σημαίνει ότι κάθε δείγμα μπορεί να είναι είτε μεγαλύτερο είτε μικρότερο κατά ένα κβάντο από το προηγούμενο του. Η δέλτα διαμόρφωση είναι κατάλληλη για σήματα χαμηλών συχνοτήτων. 3. Προσαρμοστική Διαφορική Παλμοκωδική Διαμόρφωση. Στην ADPCM, αντί να χρησιμοποιείται ένας σταθερός μηχανισμός πρόβλεψης, χρημοποιείται ένας δυναμικός μηχανισμός που προσαρμόζεται ανάλογα με τα χαρακτηριστικά του προς δειγματοληψία σήματος. Κατά τα άλλα, όπως και στην απλή DPCM, μόνο η διαφορά μεταξύ της πραγματικής και της προβλεπόμενης τιμής κάθε δείγματος μεταδίδεται..")
38
Διανυσματική Κβαντοποίηση Το ρεύμα δεδομένων χωρίζεται σε τμήματα που ονομάζονται διανύσματα. Για παράδειγμα, αν τα δεδομένα μας αποτελούν μια εικόνα, κάθε διάνυσμα μπορεί να είναι ένα τετράγωνο ή παραλληλόγραμμο τμήμα της εικόνας. Υποθέτουμε ότι όλα τα διανύσματα έχουν το ίδιο μικρό μέγεθος και ότι αποτελούνται από v οκτάδες. Υπάρχει ένας πίνακας που περιέχει ένα σύνολο από πρότυπα διανύσματα. Αυτός ο πίνακας αποτελεί το λεξικό της μεθόδου και πρέπει να είναι διαθέσιμο τόσο κατά την συμπίεση, όσο και την αποσυμπίεση των δεδομένων. Το λεξικό μπορεί να είναι προκαθορισμένο, δηλαδή το ίδιο σε όλες τις διαδικασίες συμπίεσης ή δυναμικό. Στην τελευταία περίπτωση, κάθε φορά που ξεκινά η συμπίεση των δεδομένων, ένα νέο λεξικό δημιουργείται.. Η συμπίεση έγκειται στην αντικατάσταση κάθε διανύσματος της αρχικής πληροφορίας με το πιο ταιριαστό από τα πρότυπα του λεξικού. Κάνοντας χρήση του λεξικού, αντί για ολόκληρα τα πρότυπα, μόνο η ετικέτα τους ή ο αύξων αριθμός τους στο λεξικό είναι απαραίτητο να αποθηκευτεί.

Παρόμοιες παρουσιάσεις




. Αδυναμία πρώτων υπολογιστών να χειριστούν άλλη μορφή πληροφορίας. Πρόβλημα.>")









>")



 1 Τυχαία συνάρτηση Μία τυχαία συνάρτηση (ΤΣ) είναι ένας κανόνας με τον οποίο σε κάθε αποτέλεσμα ζ.>")
>")