Κατέβασμα παρουσίασης
Η παρουσίαση φορτώνεται. Παρακαλείστε να περιμένετε

1
ΠΑΝΕΠΙΣΤΗΜΙΟ ΠΕΙΡΑΙΩΣ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΜΠΣ ΠΡΟΗΓΜΕΝΑ ΣΥΣΤΗΜΑΤΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΜΕΤΑΠΤΥΧΙΑΚΗ ΔΙΑΤΡΙΒΗ ΑΚΑΔΗΜΑΪΚΟ ΕΤΟΣ: 2007 - 2008 NewsMiner ΣΥΛΛΟΓΗ ΚΑΙ ΤΑΞΙΝΟΜΗΣΗ ΕΙΔΗΣΕΟΓΡΑΦΙΚΩΝ ΠΗΓΩΝ ΕπιβλέπωνΓιάννης Θεοδωρίδης, Αναπληρωτής Καθηγητής Νίκος Πελέκης, Διδάσκων ΠΔ 407/80 ΦοιτητήςΔιονύσης Νινιός

2
ΣΚΟΠΟΣ ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ ΤΟ ΣΥΣΤΗΜΑ NEWSMINER CASE STUDY ΣΥΜΠΕΡΑΣΜΑΤΑ - ΕΠΕΚΤΑΣΕΙΣ ΚΥΡΙΑ ΣΗΜΕΙΑ

3
ΣΚΟΠΟΣ ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ ΤΟ ΣΥΣΤΗΜΑ NEWSMINER CASE STUDY ΣΥΜΠΕΡΑΣΜΑΤΑ - ΕΠΕΚΤΑΣΕΙΣ

4
Διαδίκτυο ΣΚΟΠΟΣ Πολλές χρήσεις Τεράστιος όγκος αδόμητης πληροφορίας Δυσκολία εύρεσης χρήσιμης πληροφορίας Ενημέρωση Δημοφιλής χρήση Διαδικτύου Πολλοί Διαδικτυακοί φορείς ενημέρωσης Διαφορετικές ειδήσεις και όψεις ειδήσεων

5
Η ανάπτυξη ενός συστήματος Ολοκληρωμένου Αυτοματοποιημένου Εύρεση άρθρων από Διαδίκτυο Ομαδοποίηση άρθρων σε θέματα Παρουσίαση θεμάτων - άρθρων ΣΚΟΠΟΣ

6
ΚΥΡΙΑ ΣΗΜΕΙΑ ΣΚΟΠΟΣ ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ ΤΟ ΣΥΣΤΗΜΑ NEWSMINER CASE STUDY ΣΥΜΠΕΡΑΣΜΑΤΑ - ΕΠΕΚΤΑΣΕΙΣ

7
ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ Εύρεση δομημένης πληροφορίας [1], [2] Κατηγοριοποίηση σελίδων [3], [4], [5] Συγκέντρωση πολλών πηγών [6], [7] Στοιχεία χρήστη [8], [9] Κοινωνιολογικά δεδομένα [10], [11]
![ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ Εύρεση δομημένης πληροφορίας [1], [2] Κατηγοριοποίηση σελίδων [3], [4], [5] Συγκέντρωση πολλών πηγών [6], [7] Στοιχεία χρήστη [8], [9] Κοινωνιολογικά δεδομένα [10], [11]](http://images.slideplayer.gr/7/1977818/slides/slide_7.jpg "ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ Εύρεση δομημένης πληροφορίας [1], [2] Κατηγοριοποίηση σελίδων [3], [4], [5] Συγκέντρωση πολλών πηγών [6], [7] Στοιχεία χρήστη [8], [9] Κοινωνιολογικά δεδομένα [10], [11]")
8
ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ Διάχυση πληροφορίας σε κοινωνικά δίκτυα [12], [13], [14] Εύρεση κοινοτήτων σε κοινωνικά δίκτυα [15], [16] Παρουσίαση δεδομένων [17]
![ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ Διάχυση πληροφορίας σε κοινωνικά δίκτυα [12], [13], [14] Εύρεση κοινοτήτων σε κοινωνικά δίκτυα [15], [16] Παρουσίαση δεδομένων [17]](http://images.slideplayer.gr/7/1977818/slides/slide_8.jpg "ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ Διάχυση πληροφορίας σε κοινωνικά δίκτυα [12], [13], [14] Εύρεση κοινοτήτων σε κοινωνικά δίκτυα [15], [16] Παρουσίαση δεδομένων [17]")
9
ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ CEBIL

10
ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ PALO

11
ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ NEEMO

12
ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ GOOGLE NEWS

13
ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ - ΣΥΝΟΨΗ Εξαγωγή πληροφορίας από WEB σελίδες Ερευνητικές Εργασίες Εφαρμογή σε μεγάλο όγκο δεδομένων Λήψη ικανοποιητικών αποτελεσμάτων NewsMiner Εφαρμογή σε περιορισμένο όγκο δεδομένων Λήψη αποτελεσμάτων με μεγάλη ακρίβεια

14
ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ - ΣΥΝΟΨΗ Κατηγοριοποίηση σελίδων Ερευνητικές Εργασίες Χρήση περιεχομένου σελίδας Ταξινόμηση σε γενικές κατηγορίες NewsMiner Χρήση επεξεργασμένου περιεχομένου σελίδας Ταξινόμηση σε βάθος

15
ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ - ΣΥΝΟΨΗ Cebil - Palo Ίδιο στόχο με NewsMiner Άγνωστες τεχνικές λειτουργίας Neemo Παρόμοιο στόχο - τεχνικές με NewsMiner Google News Ταξινόμηση σε γενικές κατηγορίες

16
ΚΥΡΙΑ ΣΗΜΕΙΑ ΣΚΟΠΟΣ ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ ΤΟ ΣΥΣΤΗΜΑ NEWSMINER CASE STUDY ΣΥΜΠΕΡΑΣΜΑΤΑ - ΕΠΕΚΤΑΣΕΙΣ

17
ΔΟΜΗ NEWSMINER

18
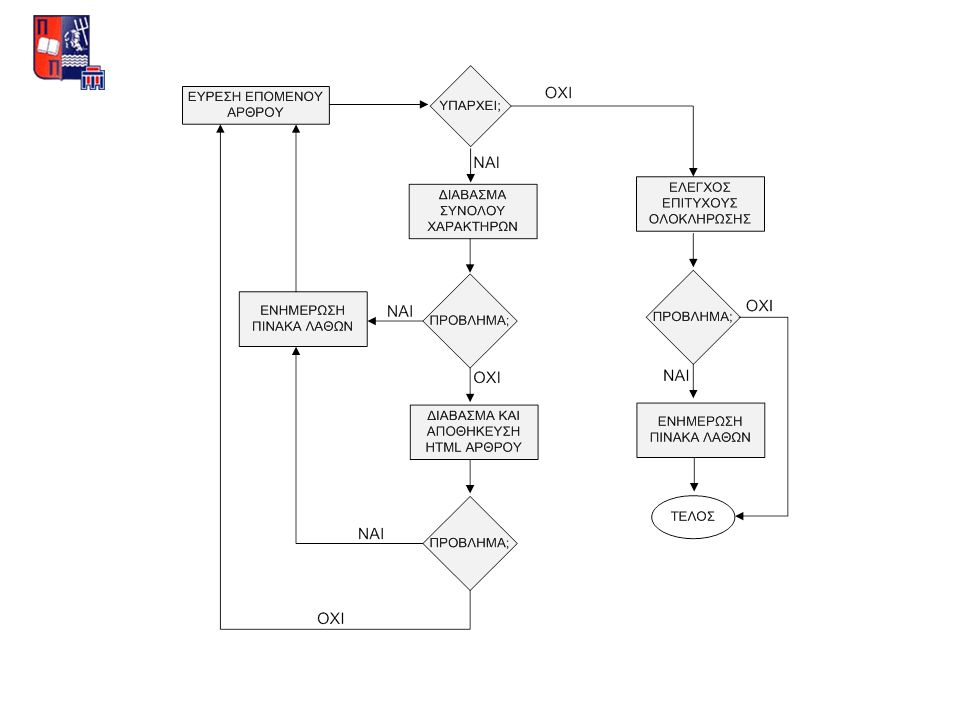
ΕΝΗΜΕΡΩΣΗ ΣΥΣΤΗΜΑΤΟΣ Γενικά χαρακτηριστικά Εννοιολογικός – Λογικός – Φυσικός Σχεδιασμός Υλοποίηση ρουτινών στη βάση δεδομένων

19
ΓΕΝΙΚΑ ΧΑΡΑΚΤΗΡΙΣΤΙΚΑ Εκμετάλλευση RSS FEEDS Εξαγωγή στοιχείων άρθρου Αυτοματοποίηση Ταχύτητα εκτέλεσης

22
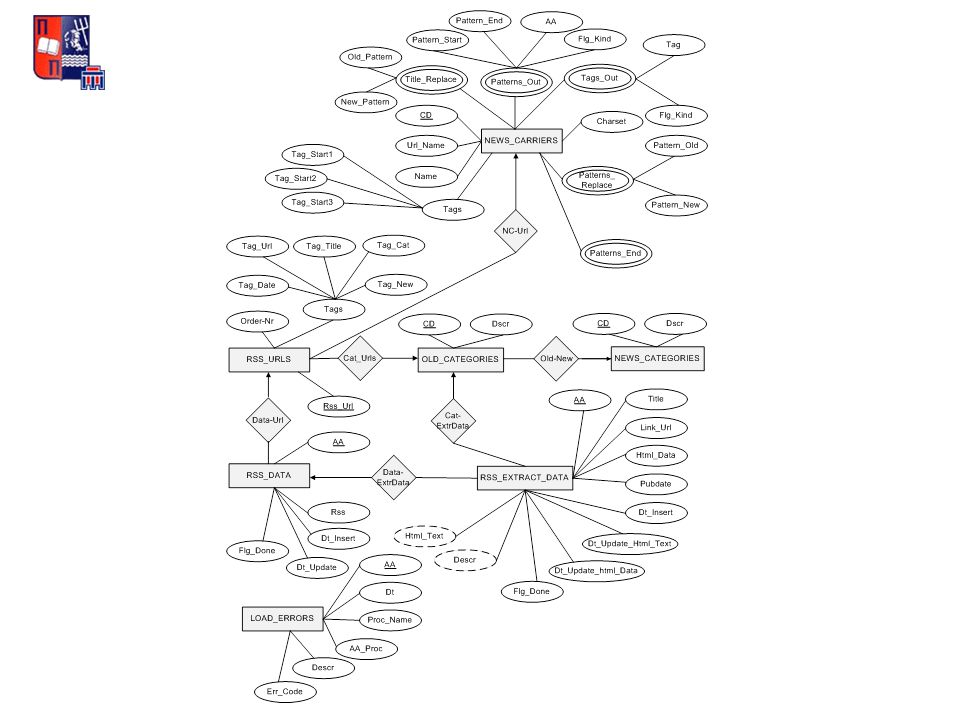
ΕΝΗΜΕΡΩΣΗ ΣΥΣΤΗΜΑΤΟΣ Χρήση RSS Feeds Really Simple Syndication XML τυποποίηση Αναπαράσταση πληροφοριών συνεχώς μεταβαλλόμενων Βασικές πληροφορίες είδησης (URL, τίτλος, δημοσίευση κ.α.)
")
23
ΕΝΗΜΕΡΩΣΗ ΣΥΣΤΗΜΑΤΟΣ Δύο κορίτσια εννέα ετών πνίγηκαν σε πισίνα κατασκήνωσης στη Λάρισα http://www.in.gr/news/article.asp?lngEntityID=1025323 Σε ένα τραγικό όσο και πρωτοφανές περιστατικό, δύο 9χρονα κοριτσάκια πνίγηκαν το απόγευμα της Παρασκευής σε πισίνα ιδιωτικής κατασκήνωσης στο νομό Λάρισας, κάτω από αδιευκρίνιστες συνθήκες. Συνελήφθησαν οι ιδιοκτήτες της κατασκήνωσης και διενεργείται προανάκριση από τις Αρχές. Fri, 19 Jun 2009 19:21:00 UTC ΑΠΕ-ΜΠΕ Δομή RSS Feeds

24
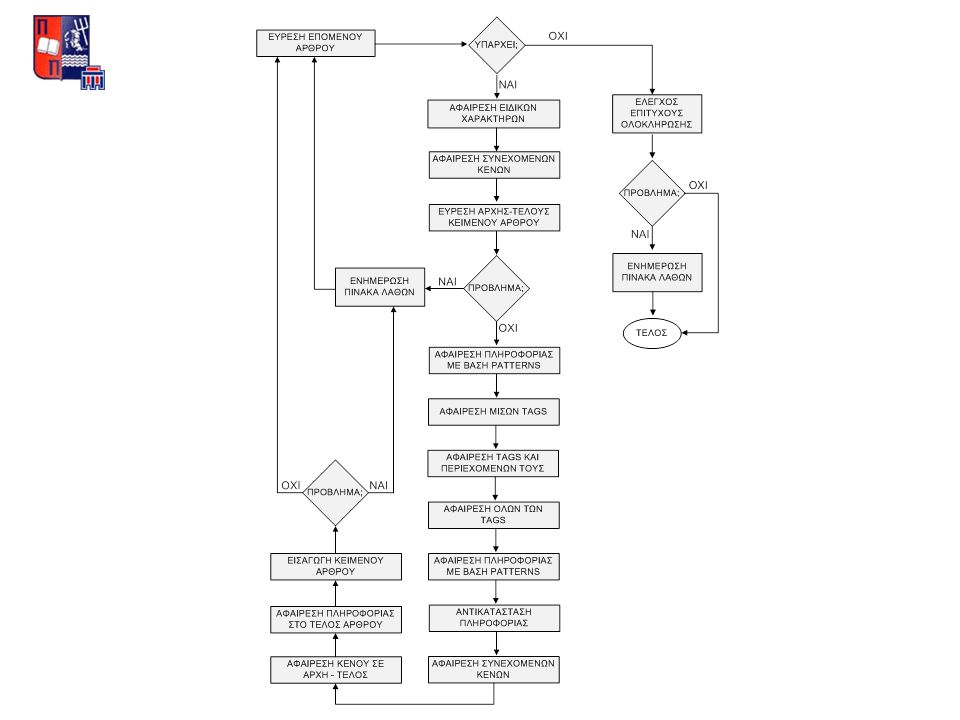
Επιλογή γενικών κατηγοριών άρθρων ΕΛΛΑΔΑΟΙΚΟΝΟΜΙΑ ΑΘΛΗΤΙΚΑΚΟΣΜΟΣ ΕΠΙΣΤΗΜΗΠΟΛΙΤΙΣΜΟΣ ΕΝΗΜΕΡΩΣΗ ΣΥΣΤΗΜΑΤΟΣ

29
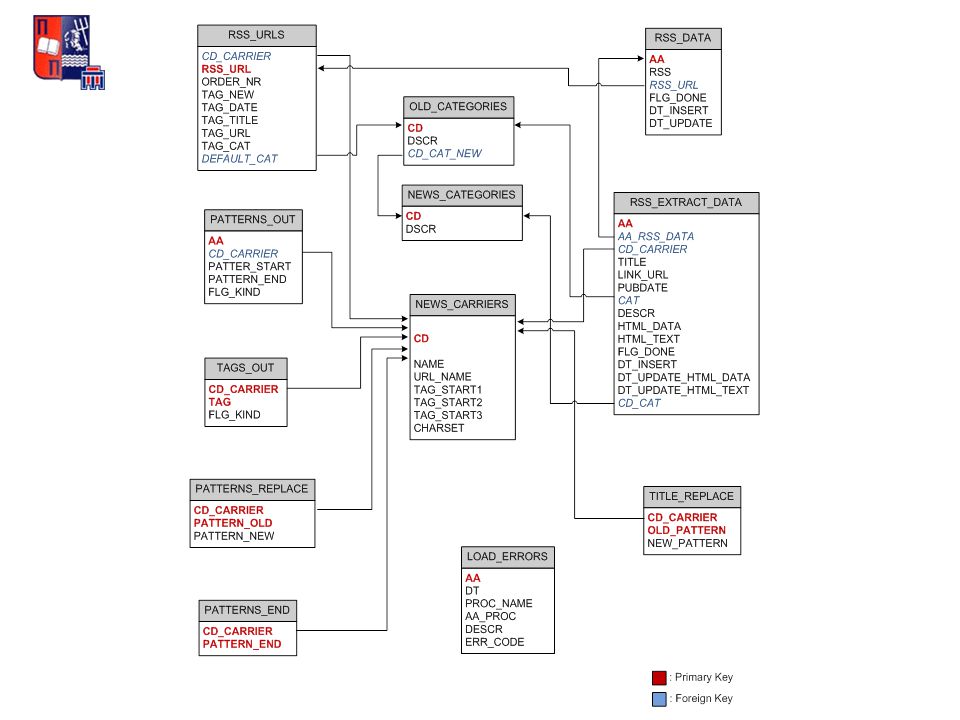
ΤΑΞΙΝΟΜΗΣΗ ΝΕΩΝ ΑΡΘΡΩΝ NEWS_TOPICS AA_TOPICΚωδικός θέματος (συστάδας) AA_FIRSTΚωδικός ενός σχετικού άρθρου RELATIVEΠλήθος σχετικών άρθρων NEWS_TOPICS_DTL AA_TOPICΚωδικός θέματος AA_ITEMΚωδικός άρθρου OLD_ITEMS AA_OLDΠαλαιό άρθρο AA_NEWΣχετικό ενεργό άρθρο
 AA_FIRSTΚωδικός ενός σχετικού άρθρου RELATIVEΠλήθος σχετικών άρθρων NEWS_TOPICS_DTL AA_TOPICΚωδικός θέματος AA_ITEMΚωδικός άρθρου OLD_ITEMS AA_OLDΠαλαιό άρθρο AA_NEWΣχετικό ενεργό άρθρο")
30
ΤΑΞΙΝΟΜΗΣΗ ΝΕΩΝ ΑΡΘΡΩΝ

31
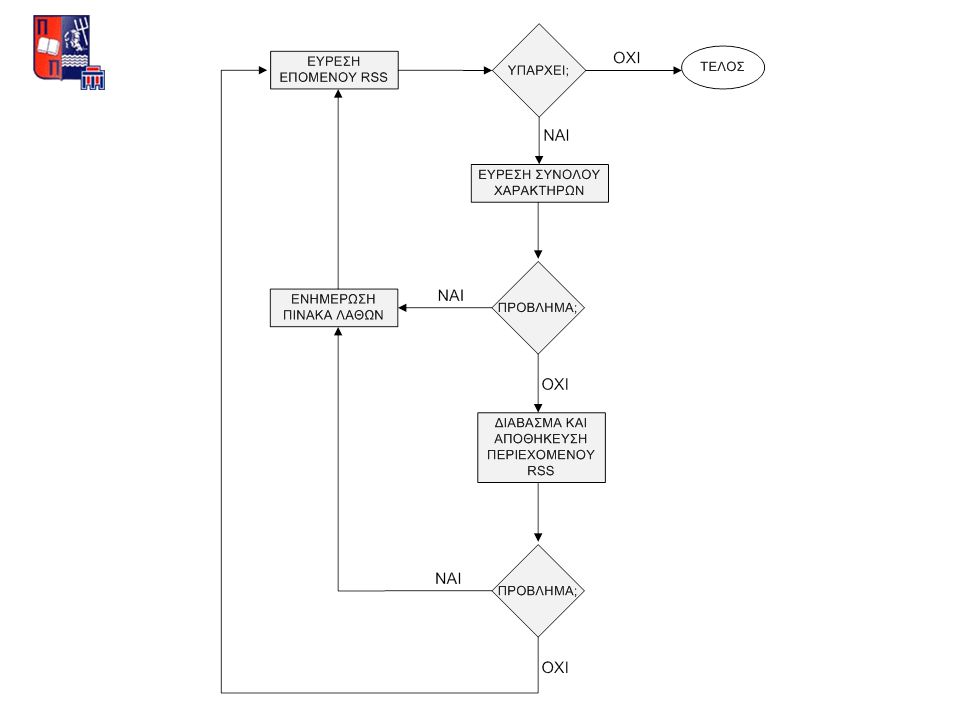
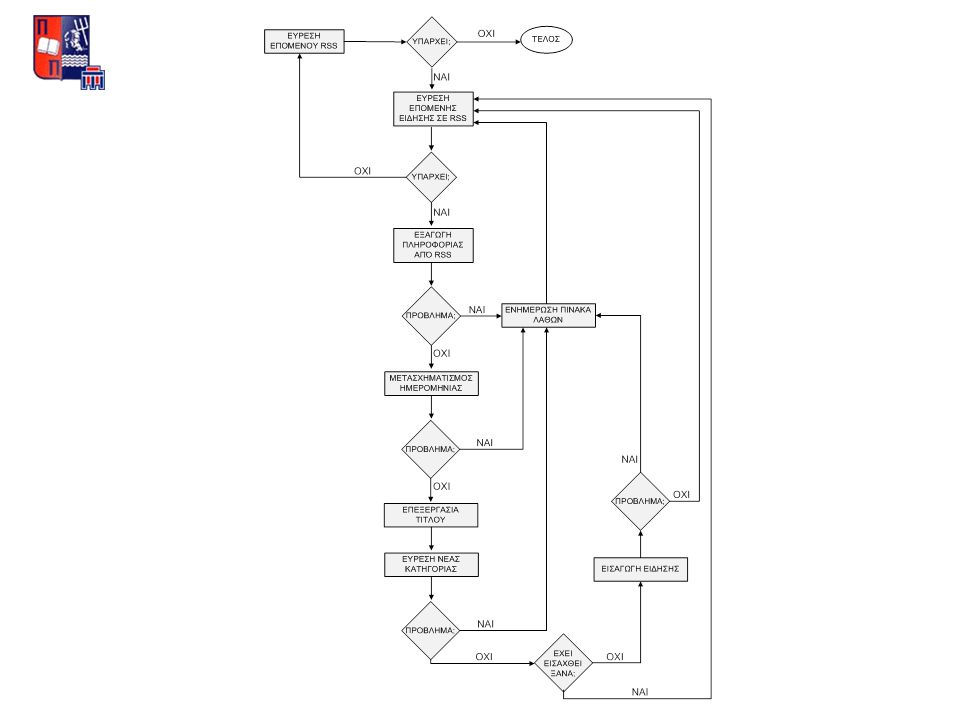
Δημιουργία διαδικασίας συνολικής ενημέρωσης Χρήση jobs ORACLE Ωριαία ενημέρωση συστήματος Ημερήσια διαγραφή παλαιών άρθρων (3:00 π.μ.) ΑΥΤΟΜΑΤΟΠΟΙΗΣΗ
 ΑΥΤΟΜΑΤΟΠΟΙΗΣΗ")
32
ΣΚΟΠΟΣ ΣΧΕΤΙΚΕΣ ΕΡΓΑΣΙΕΣ ΤΟ ΣΥΣΤΗΜΑ NEWSMINER CASE STUDY ΣΥΜΠΕΡΑΣΜΑΤΑ - ΕΠΕΚΤΑΣΕΙΣ ΚΥΡΙΑ ΣΗΜΕΙΑ

33
CASE STUDY Επισκόπηση περιβάλλοντος εργασίας Προετοιμασία διαδικασίας Κατηγοριοποίηση Συσταδοποίηση Ένταξη σε παραγωγική λειτουργία Ανάπτυξη Διεπαφής

34
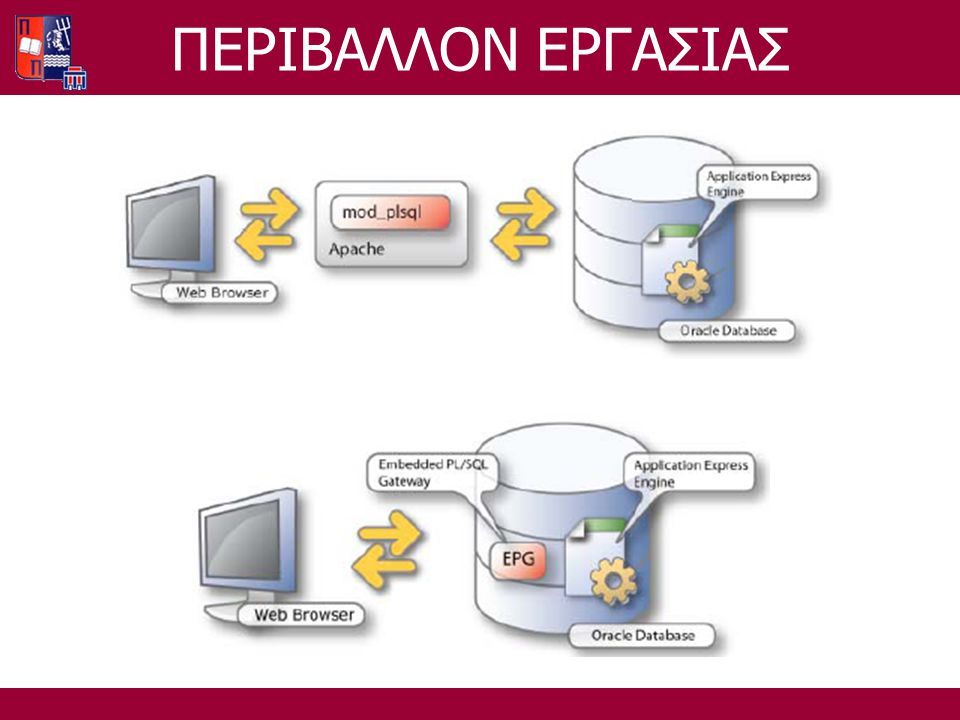
ΠΕΡΙΒΑΛΛΟΝ ΕΡΓΑΣΙΑΣ ORACLE 11G ORACLE TEXT ORACLE APPLICATION EXPRESS

35
ΠΕΡΙΒΑΛΛΟΝ ΕΡΓΑΣΙΑΣ ORACLE 11G Δημοφιλές εμπορικό ΣΔΒΔ Ενσωματωμένες διαδικασίες Data Mining Πακέτο UTL_HTTP για HTTP requests Τύπος δεδομένων CLOB Δυνατότητες αυτοματοποίησης διαδικασιών

36
ΠΕΡΙΒΑΛΛΟΝ ΕΡΓΑΣΙΑΣ ORACLE TEXT Αναζήτηση σε μεγάλες στατικές συλλογές εγγράφων: CONTEXT ευρετήριο Αναζήτηση μικρότερων μεταβαλλόμενων συλλογών εγγραφών: CTX_CAT ευρετήριο Ομαδοποίηση εγγράφων

37
ΠΕΡΙΒΑΛΛΟΝ ΕΡΓΑΣΙΑΣ Ομαδοποίηση εγγράφων Βάσει κανόνων Με επίβλεψη (κατηγοριοποίηση) Χωρίς επίβλεψη (συσταδοποίηση)
 Χωρίς επίβλεψη (συσταδοποίηση)")
38
ΠΕΡΙΒΑΛΛΟΝ ΕΡΓΑΣΙΑΣ Βάσει κανόνων Δημιουργία κλάσεων και κανόνων από χρήστη Ευρετήριο CTX_RULE σε κανόνες Κατηγοριοποίηση νέου εγγράφου με τελεστή MATCHES

39
ΠΕΡΙΒΑΛΛΟΝ ΕΡΓΑΣΙΑΣ Με επίβλεψη Δημιουργία κλάσεων από χρήστη και κανόνων από σύστημα Ευρετήριο CTX_RULE σε κανόνες και CONTEXT σε εκπαιδευτικό σύνολο Κατηγοριοποίηση νέου εγγράφου με τελεστή MATCHES Δέντρα Απόφασης και SVM

40
ΠΕΡΙΒΑΛΛΟΝ ΕΡΓΑΣΙΑΣ Χωρίς επίβλεψη Δημιουργία κλάσεων και κανόνων από σύστημα K-MEANS

41
ORACLE APPLICATION EXPRESS Εργαλείο ανάπτυξης WEB database centric εφαρμογών Αποθηκευμένο σε βάση δεδομένων (215 πίνακες και 200 PLS/SQL αντικείμενα) ΠΕΡΙΒΑΛΛΟΝ ΕΡΓΑΣΙΑΣ
 ΠΕΡΙΒΑΛΛΟΝ ΕΡΓΑΣΙΑΣ")
43
ΠΡΟΕΤΟΙΜΑΣΙΑ In.gr, Καθημερινή, Ελεύθερος Τύπος Παραμετροποίηση συστήματος Χρήση διαδικασίας ενημέρωσης Δημιουργία δεδομένων εκπαίδευσης και ελέγχου (12 μέρες, 766 άρθρα ΕΛΛΑΔΑ, 315 θέματα)
")
44
ΠΡΟΕΤΟΙΜΑΣΙΑ Δημιουργία λίστας κοινών λέξεων

45
ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ

46
ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – Δ.Α. ΔΕΝΤΡΑ ΑΠΟΦΑΣΗΣ Επιλογή ανάμεσα σε δυο εναλλακτικές αποφάσεις Ορατοί κανόνες Μετασχηματίζονται σε ειδικές αναζητήσεις Αντιστοίχηση εγγράφων με κατηγορίες Συγκεκριμένες παράμετροι

47
ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – Δ.Α. THRESHOLD Ελάχιστο όριο εμπιστοσύνης κανόνων MAX_TERMS Μέγιστος αριθμός όρων κανόνων ανά κλάση MEMORY_SIZE Χρησιμοποιούμενη μνήμη NT_THRESHOLD Ελάχιστο όριο αρχικής επιλογής όρων TERM_THRESHOLD Ελάχιστο όριο τελικής επιλογής όρων PRUNE_LEVEL Επίπεδο κλαδέματος δέντρου απόφασης

48
ΚΡΙΤΗΡΙΑ ΑΞΙΟΛΟΓΗΣΗΣ ΔΟΚΙΜΩΝ Συνολικό ποσοστό επιτυχίας Ποσοστό επιτυχίας ενεργών θεμάτων Ποσοστό επιτυχίας νέων θεμάτων Πολλαπλές κατηγοριοποιήσεις ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – Δ.Α.

49
MAX_TERMS (20-200, βήμα 10) <= MAX_TERMS (30-50, βήμα 1) =>=> ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – Δ.Α.
 <= MAX_TERMS (30-50, βήμα 1) =>=> ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – Δ.Α.")
50
NT_THRESHOLD (0.05-0.9, βήμα 0.05) <= TERM_THRESHOLD (10-100, βήμα 5) =>=> ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – Δ.Α.
 <= TERM_THRESHOLD (10-100, βήμα 5) =>=> ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – Δ.Α.")
51
TERM_THRESHOLD (25-35, βήμα 1) <= THRESHOLD (5-95, βήμα 5) =>=> ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – Δ.Α.
 <= THRESHOLD (5-95, βήμα 5) =>=> ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – Δ.Α.")
52
THRESHOLD (5-20, βήμα 1) <= PRUNE_LEVEL (5-100, βήμα 5) =>=> ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – Δ.Α.
 <= PRUNE_LEVEL (5-100, βήμα 5) =>=> ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – Δ.Α.")
53
PRUNE_LEVEL (5-80, βήμα 1) <= ΣΥΝΟΛΟΕΝΕΡΓΑΝΕΑΠΟΛΛΑΠΛΕΣ 70%55%80%3% ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – Δ.Α.
 <= ΣΥΝΟΛΟΕΝΕΡΓΑΝΕΑΠΟΛΛΑΠΛΕΣ 70%55%80%3% ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – Δ.Α.")
54
SUPPORT VECTOR MACHINE Μηχανική μάθηση (στατιστική εκπαίδευση) Αόρατοι κανόνες Μετασχηματίζονται σε ειδικές αναζητήσεις Αντιστοίχηση εγγράφων με κατηγορίες (πιθανότητα) Συγκεκριμένες παράμετροι ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – SVM
 Αόρατοι κανόνες Μετασχηματίζονται σε ειδικές αναζητήσεις Αντιστοίχηση εγγράφων με κατηγορίες (πιθανότητα) Συγκεκριμένες παράμετροι ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – SVM")
55
MAX_DOCTERMS Μέγιστος αριθμός όρων ανά κείμενο MAX_FEATURES Μέγιστος συνολικός αριθμός διακριτών χαρακτηριστικών THEME_ON – TOKEN_ON – STEM_ON Γλωσσολογικές παράμετροι MEMORY_SIZE Χρησιμοποιούμενη μνήμη SECTION_WEIGHT Βάρη σε τμήματα του εγγράφου (HTML, XML) ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – SVM
 ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – SVM")
56
MAX_FEATURES (1.000-30.000, βήμα 1.000) <= Όριο πιθανότητας 30% =>=> ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – SVM
 <= Όριο πιθανότητας 30% =>=> ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – SVM")
57
Όριο πιθανότητας 25% <= Όριο πιθανότητας 35% =>=> ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – SVM

58
MAX_DOCTERMS 100 <= MAX_DOCTERMS 120 =>=> ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – SVM

59
ΑΛΟΓΡΙΘΜΟΣΣΥΝΟΛΟΕΝΕΡΓΑΝΕΑΠΟΛΛΑΠΛΕΣ DECISION TREE 70%55%80%3% SVM75%65%81.5%9% ΚΑΤΗΓΟΡΙΟΠΟΙΗΣΗ – SVM

60
ΣΥΣΤΑΔΟΠΟΙΗΣΗ K – MEANS Μέτρηση απόστασης μεταξύ σημείων Ιεραρχική συσταδοποίηση Εύρεση κλάσεων και εγγράφων (ποσοστό) Συγκεκριμένες παράμετροι
 Συγκεκριμένες παράμετροι")
61
MAX_DOCTERMS Μέγιστος αριθμός όρων ανά κείμενο MAX_FEATURES Μέγιστος συνολικός αριθμός διακριτών χαρακτηριστικών THEME_ON – TOKEN_ON – STEM_ON Γλωσσολογικές παράμετροι MEMORY_SIZE Χρησιμοποιούμενη μνήμη SECTION_WEIGHT Βάρη σε τμήματα του εγγράφου (HTML, XML) CLUSTER_NUM Πλήθος τελικών συστάδων ΣΥΣΤΑΔΟΠΟΙΗΣΗ
 CLUSTER_NUM Πλήθος τελικών συστάδων ΣΥΣΤΑΔΟΠΟΙΗΣΗ")
62
MAX_FEATURES (1.000 – 30.000, βήμα 1.000) <= MAX_FEATURES (100 – 2.000, βήμα 100) =>=> ΣΥΣΤΑΔΟΠΟΙΗΣΗ
 <= MAX_FEATURES (100 – 2.000, βήμα 100) =>=> ΣΥΣΤΑΔΟΠΟΙΗΣΗ")
63
MAX_DOCTERMS 40 <= MAX_DOCTERMS 60=>=> ΣΥΣΤΑΔΟΠΟΙΗΣΗ

64
MAX_DOCTERMS 70 <= MAX_FEATURES (1 – 100, βήμα 5) =>=> ΣΥΣΤΑΔΟΠΟΙΗΣΗ
 =>=> ΣΥΣΤΑΔΟΠΟΙΗΣΗ")
65
ΕΝΤΑΞΗ ΣΕ ΠΑΡΑΓΩΓΗ Επιλογή μοντέλων SVM (MAX_FEATURES = 1000, MAX_DOCTERMS = 100) K – MEANS (CLUSTER_NUM = 20, MAX_DOCTERMS = 70 MAX_FEATURES = 80) Ενημέρωση διαδικασιών συστήματος
 K – MEANS (CLUSTER_NUM = 20, MAX_DOCTERMS = 70 MAX_FEATURES = 80) Ενημέρωση διαδικασιών συστήματος")
66
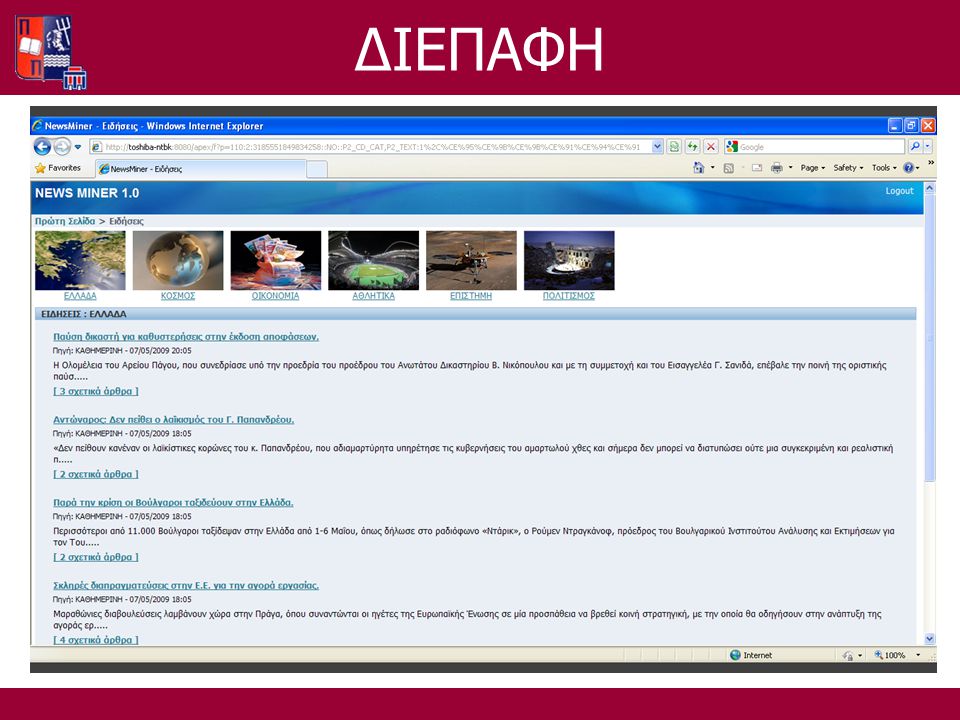
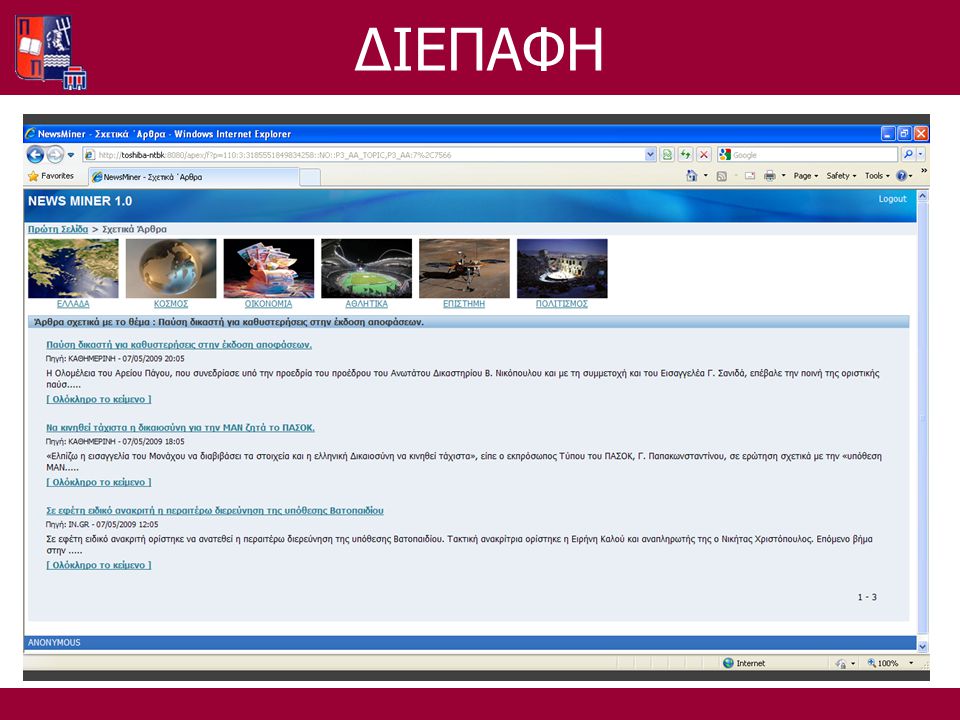
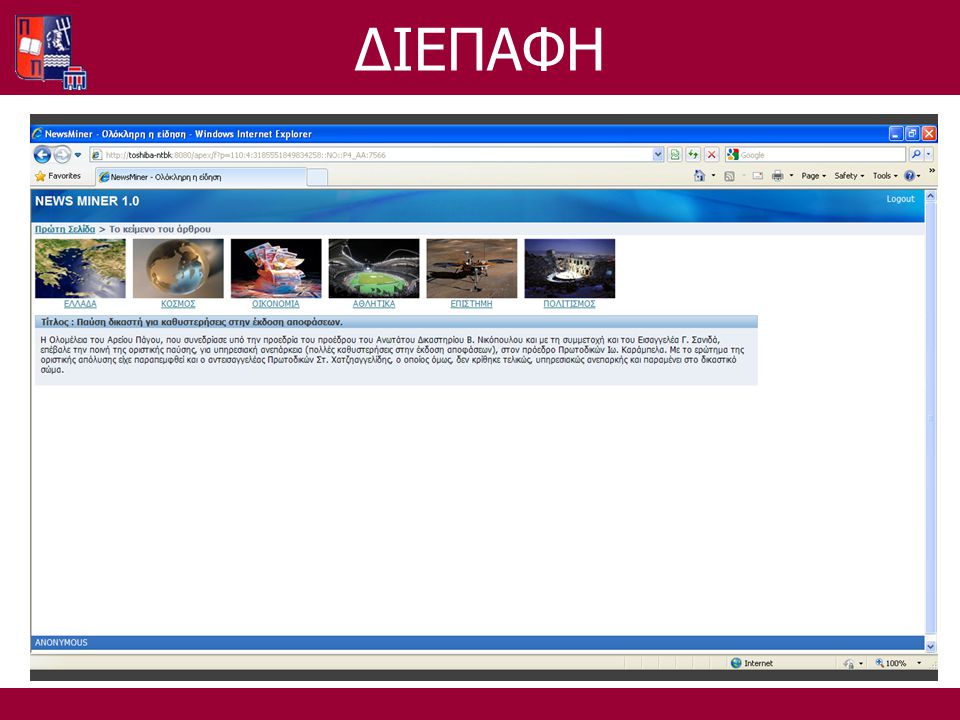
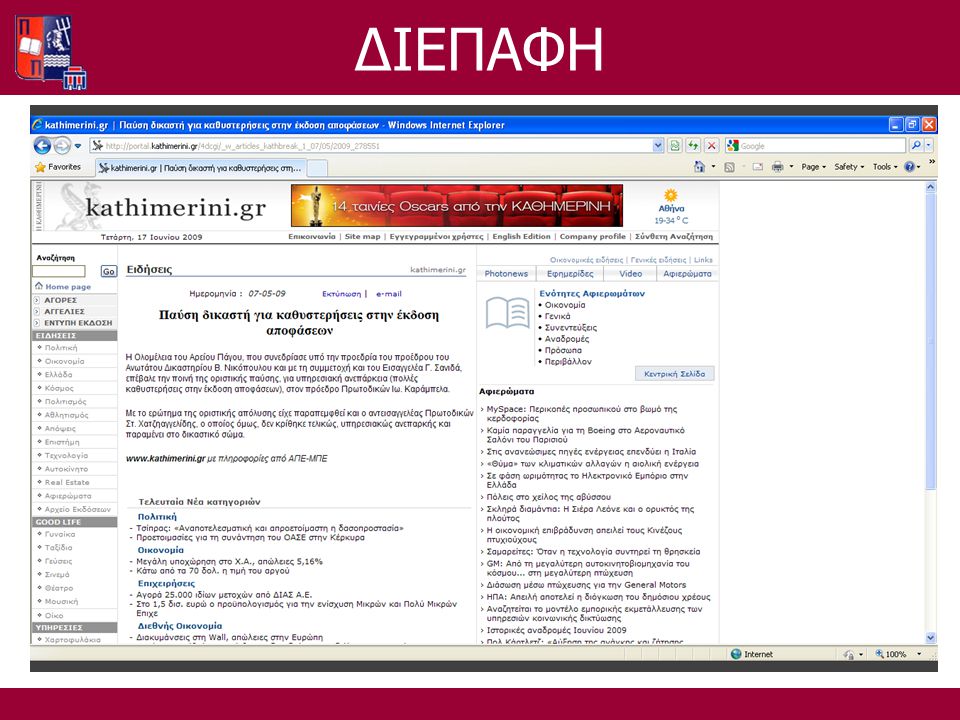
ΔΙΕΠΑΦΗ

71
ΣΥΜΠΕΡΑΣΜΑΤΑ Εξόρυξη γνώσης από WEB Δύσκολη και χρονοβόρα διαδικασία Προετοιμασία δεδομένων Ταξινόμηση δεδομένων Αξιολόγηση συστήματος Διαδικασία ενημέρωσης: Εξαιρετικά Ταξινόμηση άρθρων: Ικανοποιητικά

72
ΣΥΜΠΕΡΑΣΜΑΤΑ Δυσκολίες σε ταξινόμηση άρθρων Αδόμητη πληροφορία Γλωσσολογικές δυσκολίες Ταξινόμηση σε βάθος Μικρός αριθμός άρθρων ανά κατηγορία Μεταβαλλόμενα δεδομένα και κατηγορίες

73
Χρήση λεξικού συνωνύμων Δημιουργία stemmer βάσει κανόνων Εμπλουτισμός λίστας κοινών λέξεων Περιεκτικότερη αναπαράσταση άρθρων Χρήση του τίτλου της είδησης Περαιτέρω δοκιμές σε αλγόριθμους ΕΠΕΚΤΑΣΕΙΣ

74
ΑΝΑΦΟΡΕΣ [1]Davi de Castro Reis, Paulo B. Golgher, Altigran S. da Silva, Alberto H. F. Laender: Automatic Web News Extraction Using Tree Edit Distance. International Conference on World Wide Web, (2004) [2]Cai-Nicolas Ziegler, Michal Skubacz: Content Extraction from News Pages Using Particle Swarm Optimization on Linguistic and Structural Features. IEEE / WIC / ACM International Conference on Web Intelligence, (2007) [3]Smriti Bhagat, Irina Rozenbaum, Graham Cormode: Applying Link- based Classification to Label Blogs. WEBKDD International Conference, (2007) [4] Eric Glover, Kostas Tsioutsiouliklis, Steve Lawrence, David Pennock, Gary Flake: Using Web Structure for Classifying and Describing Web Pages. International Conference on World Wide Web, (2002) [5]Beibei Li, Beibei Li, Jun Zhang: Enhancing Clustering Blog Documents by Utilizing Author / Reader Comments. ACMSE International Conference (2007)
![ΑΝΑΦΟΡΕΣ [1]Davi de Castro Reis, Paulo B. Golgher, Altigran S.](http://images.slideplayer.gr/7/1977818/slides/slide_74.jpg "da Silva, Alberto H. F. Laender: Automatic Web News Extraction Using Tree Edit Distance. International Conference on World Wide Web, (2004) [2]Cai-Nicolas Ziegler, Michal Skubacz: Content Extraction from News Pages Using Particle Swarm Optimization on Linguistic and Structural Features. IEEE / WIC / ACM International Conference on Web Intelligence, (2007) [3]Smriti Bhagat, Irina Rozenbaum, Graham Cormode: Applying Link- based Classification to Label Blogs. WEBKDD International Conference, (2007) [4] Eric Glover, Kostas Tsioutsiouliklis, Steve Lawrence, David Pennock, Gary Flake: Using Web Structure for Classifying and Describing Web Pages. International Conference on World Wide Web, (2002) [5]Beibei Li, Beibei Li, Jun Zhang: Enhancing Clustering Blog Documents by Utilizing Author / Reader Comments. ACMSE International Conference (2007).")
75
ΑΝΑΦΟΡΕΣ [6]Ismail Sengor Altingovde, Rifat Ozcan, Suleyman Cetintas, Hakan Yilmaz, Özgür Ulusoy: An Automatic Approach to Construct Domain- Specific Web Portals. CIKM International Conference, (2007) [7]Benjamin E. Teitler, Michael D. Lieberman, Daniele Panozzo, Jagan Sankaranarayanan, Hanan Samet, Jon Sperling: NewsStand: A New View on News. ACM GIS International Conference, (2008) [8]Riddhiman Ghosh, Mohamed Dekhil: Discovering User Profiles. International Conference on World Wide Web, (2009) [9]Evgeniy Gabrilovich, Susan Dumais, Eric Horvitz: Newsjunkie: Providing Personalized Newsfeeds via Analysis of Information Novelty. International Conference on World Wide Web, (2004) [10]Matthew S. Smith: Social Capital in Online Communities. PIKM International Workshop, (2008) [11]Xin Li, Lei Guo, Yihong (Eric) Zhao: Tag-based Social Interest Discovery. International Conference on World Wide Web, (2008)
![ΑΝΑΦΟΡΕΣ [6]Ismail Sengor Altingovde, Rifat Ozcan, Suleyman Cetintas, Hakan Yilmaz, Özgür Ulusoy: An Automatic Approach to Construct Domain- Specific Web Portals.](http://images.slideplayer.gr/7/1977818/slides/slide_75.jpg "CIKM International Conference, (2007) [7]Benjamin E. Teitler, Michael D. Lieberman, Daniele Panozzo, Jagan Sankaranarayanan, Hanan Samet, Jon Sperling: NewsStand: A New View on News. ACM GIS International Conference, (2008) [8]Riddhiman Ghosh, Mohamed Dekhil: Discovering User Profiles. International Conference on World Wide Web, (2009) [9]Evgeniy Gabrilovich, Susan Dumais, Eric Horvitz: Newsjunkie: Providing Personalized Newsfeeds via Analysis of Information Novelty. International Conference on World Wide Web, (2004) [10]Matthew S. Smith: Social Capital in Online Communities. PIKM International Workshop, (2008) [11]Xin Li, Lei Guo, Yihong (Eric) Zhao: Tag-based Social Interest Discovery. International Conference on World Wide Web, (2008).")
76
ΑΝΑΦΟΡΕΣ [12]Lei Zhang, Wanqing Tu: Six Degrees of Separation in Online Society. WebSci International Conference, (2009) [13]S. Navlakha, R. Rastogi, and N. Shrivastava: Graph summarization with bounded error. ACM SIGMOD International Conference, (2008) [14]Masahiro Kimura, Hiroshi Motoda: Blocking Links to Minimize Contamination Spread in a Social Network. ACM Transactions on Knowledge Discovery from Data: Vol. 3, (2009) [15]J.M. Kleinberg: Authoritative sources in a hyperlinked environment. ACM: Vol. 46. [16]M. Toyoda, M. Kitsuregawa: Extracting evolution of web communities from a series of web archives. ACM Conference on Hypertext and Hypermedia, (2003) [17]Marc Smith, Vladimir Barash: Social SQL: Tools for exploring social databases. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, (2008)
![ΑΝΑΦΟΡΕΣ [12]Lei Zhang, Wanqing Tu: Six Degrees of Separation in Online Society.](http://images.slideplayer.gr/7/1977818/slides/slide_76.jpg "WebSci International Conference, (2009) [13]S. Navlakha, R. Rastogi, and N. Shrivastava: Graph summarization with bounded error. ACM SIGMOD International Conference, (2008) [14]Masahiro Kimura, Hiroshi Motoda: Blocking Links to Minimize Contamination Spread in a Social Network. ACM Transactions on Knowledge Discovery from Data: Vol. 3, (2009) [15]J.M. Kleinberg: Authoritative sources in a hyperlinked environment. ACM: Vol. 46. [16]M. Toyoda, M. Kitsuregawa: Extracting evolution of web communities from a series of web archives. ACM Conference on Hypertext and Hypermedia, (2003) [17]Marc Smith, Vladimir Barash: Social SQL: Tools for exploring social databases. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, (2008).")
77
NEWS MINER ΕΡΩΤΗΣΕΙΣ ;

Παρόμοιες παρουσιάσεις