Κατέβασμα παρουσίασης
Η παρουσίαση φορτώνεται. Παρακαλείστε να περιμένετε

1
Φροντιστήριο 2 Οκτώβριος 2013

2
Querying Lexicon access Inverted file indexing – Inverted file compression 2

3
3

4
Πως χρησιμοποιούμε ένα ευρετήριο για να εντοπίσουμε πληροφορίες για το κείμενο που περιγράφει ; • Boolean queries • Ranked queries 4

5
Boolean query Ένα Boolean query εμπεριέχει μία λίστα όρων που συνδυάζονται χρησιμοποιώντας τις πράξεις AND, OR, και NOT Οι απαντήσεις στο query είναι τα κείμενα που ικανοποιούν τις συνθήκες 5

6
Π. χ. ’text’ AND ’compression’ AND ’retrieval’ Και οι 3 λέξεις πρέπει να υπάρχουν σε κάθε απάντηση. • ”the compression and retrieval of large amounts of text is an interesting problem” • ”this text describes the fractional distillation scavenging technique for retrieving argon from compressed air” 6

7
Προβλήματα με όλα τα συστήματα ανάκτησης : • Επιστρέφονται άσχετες απαντήσεις • Πρέπει να αφαιρεθούν « με το χέρι » Εκτενές query -> high recall Περιορισμένο query -> high precision Στόχος μας είναι να βρούμε μια σωστή ισορροπία μεταξύ των δυο αυτών τιμών ανάλογα με την εφαρμογή που θα έχουμε 7

8
Μικρές παραλλαγές σε ένα query οδηγούν σε πολύ διαφορετικά αποτελέσματα • data AND compression AND retrieval • text AND compression AND retrieval • Ο χρήστης πρέπει να είναι σε θέση να θέτει πολύπλοκα ερωτήματα όπως (text OR data OR image) AND (compression OR compaction OR decompression) AND (archiving OR retrieval OR storage) 8
 AND (compression OR compaction OR decompression) AND (archiving OR retrieval OR storage) 8")
9
Παρά τα μειονεκτήματα τα boolean retrieval systems ήταν οι αρχικοί μηχανισμοί που χρησιμοποιήθηκαν για την πρόσβαση σε online πληροφορίες για περισσότερες από 3 δεκαετίες τόσο σε οικονομικές όσο και σε επιστημονικές εφαρμογές. 9

10
High recall ~ High precision Αποφυγή της χρήσης του “OR” μπορεί να βελτιώσει τα αποτελέσματα των ερωτήσεων μας 10

11
ranked query Λύση : ένα ranked query • Εμπεριέχει ένα heuristic (computational method) που εφαρμόζεται για να μετρά την ομοιότητα κάθε εγγράφου με το ερώτημα. r πλησιέστερα έγγραφα • Βασιζόμενοι σε αυτό το δείκτη τα r πλησιέστερα έγγραφα επιστρέφονται σαν απάντηση. 11

12
σχετικών documentshigh precision Αν ο δείκτης είναι καλός ή το rank είναι μικρό ή και τα δυο, τότε έχουμε επικράτηση σχετικών documents στην απάντηση –high precision θα εμφανιστούν στα r high recall Αν ο δείκτης είναι καλός και το rank είναι μεγάλο τα περισσότερα documents της συλλογής που είναι σχετικά, θα εμφανιστούν στα r –high recall 12

13
Πρακτικά το low precision συνυπάρχει με το high recall Όταν το precision είναι μεγάλο τότε το recall είναι χαμηλό. • Μεγάλη ακρίβεια -> μόνο στην αρχή της βαθμολογούμενης λίστας θα έχουμε σχετικά αποτελέσματα. 13

14
υψηλό recall και precision Υπάρχουν πολλές προσπάθειες για τεχνικές ranking και στρατηγικές ώστε να πετυχαίνουν υψηλό recall και precision. Σκοπός των τεχνικών εδώ είναι υψηλό recall και precision 14

15
Απλές τεχνικές • Μετράμε τον αριθμό από τους όρους του query που συναντάμε μέσα στο έγγραφο (coordinate matching) Ένα έγγραφο που περιέχει 5 όρους ερωτήματος κατατάσσεται ψηλότερα από ένα που περιέχει 3 όρους. Μειονέκτημα Μειονέκτημα εδώ είναι η υπεροχή μεγάλων εγγράφων έναντι μικρών και η παρουσία λιγότερων όρων σε πιο σχετικά κείμενα. 15

16
Προχωρημένες τεχνικές Λαμβάνουμε υπόψη το μήκος του εγγράφου και αναθέτουν ένα βάρος σε κάθε όρο π. χ. το cosine measure * Οι όροι των ερωτημάτων μπορούν να χρησιμοποιούν *. Search for : lab*r Labor Labour 16

17
Για ενα σύνολο από 50 ερωτήματα στη συλλογή TREC(750.000 documents) η τεχνική του cosine measure πετυχαίνει precision 40%, σε κάθε ερώτημα. • Όταν εφαρμόζουμε ένα ερώτημα στο TREC40 από τα 100 πρώτα αποτελέσματα (top results), τα 40 θα είναι σχετικά. • Αυτό είναι δύσκολο να το πετύχει ένα Boolean ερώτημα. 17
, τα 40 θα είναι σχετικά. • Αυτό είναι δύσκολο να το πετύχει ένα Boolean ερώτημα. 17.")
18
18

19
Το λεξικό για ένα inverted file index αποθηκεύει • Τους όρους που χρησιμοποιούνται για αναζήτηση στη συλλογή • Απαιτούμενες πληροφορίες για να επεξεργαστούμε τα ερωτήματα για έναν όρο είναι : Διεύθυνση στο inverted file Τη λίστα με τα έγγραφα Συνήθως χρησιμοποιούνται : Το Ft, ο αριθμός των κειμένων που περιέχουν κάθε όρο, δηλαδή η συχνότητα εμφάνισης του όρου. Παράμετροι συμπίεσης κ. α. 19

20
20 Λεξικό Εμφανίσεις

21
κατάλληλης τεχνικής αποθήκευσης λεξικών. Επιλογή κατάλληλης τεχνικής αποθήκευσης λεξικών. Ακόμα και μια απλή δομή μπορεί να μειώσει αισθητά τον διαθέσιμο χώρο προς αποθήκευση κατά την εκτέλεση ερωτημάτων και τη χρήση βασικής μνήμης. 21

22
Απαιτήσεις σε χώρο για λεξικό με 1.000.000 όρους με διάφορες δομές δεδομένων (Front Coding: 15,5 Mbytes, Minimal Perfect Hashing: 13 Mbytes) το λεξικό τοποθετείται στο δίσκο. Για να μην έχουμε ειδικές απαιτήσεις μνήμης κατά τα ερωτήματα, το λεξικό τοποθετείται στο δίσκο. 22

23
Μία απλή δομή • Ένας πίνακας από εγγραφές, που καθεμία περιέχει ένα string και 2 integer πεδία • Σε διατεταγμένα λεξικά, μία λέξη εντοπίζεται με binary search στα strings( λεξικογραφικά με logn πολυπλοκότητα ) • Σπαταλά πολύ χώρο, αλλά εκτελείται σε σύντομο χρόνο 23
 • Σπαταλά πολύ χώρο, αλλά εκτελείται σε σύντομο χρόνο 23")
24
24 20 Mbytes 4 Mbytes

25
Με τη δομή της εικόνας ο χώρος αποθήκευσης είναι αρκετά μεγάλος ( ένα κλασικό λεξικό μπορεί να έχει εκατομμύρια όρους ) • Στην 2Gb TREC συλλογή υπάρχουν n=535.246 μοναδικοί όροι, και μια συλλογή με 1.000. οοο όρους μπορεί να φτάσει τα 5Gb. 20-byte strings • Αν οι όροι αποθηκεύονται σαν 20-byte strings και με ένα 4-byte inverted file address και ένα 4-byte f t, τότε χρειαζόμαστε 28Mbytes. 25

26
Ο χώρος για τα strings μειώνεται εάν αυτά συνενωθούν σε ένα συνεχές string 4-byte character pointers • Ένας πίνακας με 4-byte character pointers χρησιμοποιείται για πρόσβαση Κάθε όρος : χρησιμοποιεί τον ακριβή αριθμό χαρακτήρων του + 4 για τον pointer. Δεν είναι απαραίτητο να αποθηκεύουμε τα μήκη των strings: ο επόμενος pointer δείχνει στο τέλος του string • Εδώ αντίστοιχα χρειαζόμαστε περίπου 20Mb για το λεξικό. 26

27
27 Ο επόμενος δείκτης ορίζει το τέλος του string

28
Ο χώρος που χρησιμοποιείται μειώνεται και άλλο εάν απαλλαχθούμε από τους πολλούς string pointers 1 λέξη στις 4 είναι indexed, και κάθε αποθηκευμένη λέξη έχει σαν πρόθεμα ένα 1- byte length πεδίο. Το πεδίο μήκους μας βοηθά στην αναγνώριση της αρχής του επόμενου string και του block από strings που διατρέχουμε 28

29
29

30
Σε κάθε group, γλιτώνουμε 12 bytes ( από τα 16) για pointers. Με επιπλέον κόστος 4 bytes για πληροφορίες μήκους των λέξεων. Άρα ανά 4 λέξεις κερδίζουμε 8 bytes, συνεπώς συνολικά κερδίζουμε 8 Mbytes / 4 = 2 Mbytes. Ο συνολικός απαιτούμενος χώρος λοιπόν γίνεται 18Mb. Η ίδια διαδικασία μπορεί να γίνει με blocks από 8 λέξεις και να μειωθεί παραπάνω ο απαιτούμενος χώρος.(13 Mbytes) 30
 30.")
31
Η διαδικασία αναζήτησης γίνεται πιο πολύπλοκη για τον εντοπισμό ενός όρου. • Β inary-search στον πίνακα από string pointers για την εύρεση του σωστού block από λέξεις • Το block σαρώνεται με γραμμικό τρόπο για να βρούμε τον όρο. • Η εύρεση του όρου γίνεται από το συνδυασμό του αριθμού του block και της θέσης στο block • Η χρήση των block με 4 όρους είναι το πιο αποδοτικό ( σε αναζήτηση ) στην τεχνική αυτή μιας και μια γραμμική αναζήτηση στις 3 τελευταίες λέξεις του block απαιτεί κατά μέσο όρο 2 string comparisons ( με μέσο όρο 1.7 συγκρίσεις αν όλα τα strings είχαν γίνει index και γινόταν binary search). 31
 στην τεχνική αυτή μιας και μια γραμμική αναζήτηση στις 3 τελευταίες λέξεις του block απαιτεί κατά μέσο όρο 2 string comparisons ( με μέσο όρο 1.7 συγκρίσεις αν όλα τα strings είχαν γίνει index και γινόταν binary search). 31.")
32
Συνεχόμενες λέξεις σε διατεταγμένη λίστα είναι πιθανό να έχουν κάποιο κοινό πρόθεμα. Σκεπτικό : Συνεχόμενες λέξεις σε διατεταγμένη λίστα είναι πιθανό να έχουν κάποιο κοινό πρόθεμα. • 2 integers αποθηκεύονται με κάθε λέξη ένας που δείχνει πόσοι προθεματικοί χαρακτήρες είναι ίδιοι με αυτούς της προηγούμενης λέξης • Ο άλλος δείχνει πόσοι επιθεματικοί χαρακτήρες απομένουν όταν αφαιρεθεί το πρόθεμα Οι integers ακολουθούνται από επιθεματικούς χαρακτήρες. 32

33
33

34
πιο μεγάλο είναι το λεξικό πιο πολλά προθέματα χαρακτήρων Όσο πιο μεγάλο είναι το λεξικό τόσα πιο πολλά προθέματα χαρακτήρων συναντάμε μιας και περισσότερα strings βρίσκονται μέσα σε ένα σύνολο από πιθανούς χαρακτήρες. 34

35
Αυτό αποδεικνύεται αν αναπαραστήσουμε κάθε χαρακτήρα με αριθμούς (radix- 36) μεταξύ 0 και 1. • Ο χαρακτήρας 0 είναι το ψηφίο 0, ο χαρακτήρας 1 είναι το ψηφίο 1, τα γράμματα a-z είναι ψηφία από 10 ως 35 αντίστοιχα. • a = 10*36 0 =10 • bed = (11*36 2 +14*36 1 +13*36 0 ) 10 1/n • Λεξικό με n όρους έχει σαν μέσο κενό μεταξύ των strings ( όταν τους μετατρέψουμε σε radix-x) λιγότερο από 1/n, άρα λεξικό με n=1.000.000 έχει μέσο όρο επιθεμάτων log361.000.000-1=2.9 χαρακτήρες 35
 10 1/n • Λεξικό με n όρους έχει σαν μέσο κενό μεταξύ των strings ( όταν τους μετατρέψουμε σε radix-x) λιγότερο από 1/n, άρα λεξικό με n= έχει μέσο όρο επιθεμάτων log =2.9 χαρακτήρες 35.")
36
Το Front coding οδηγεί στην εξοικονόμηση περίπου 40% του απαιτούμενου χώρου για ένα λεξικό της αγγλικής γλώσσας Πρόβλημα του πλήρους front coding: • Η δυαδική αναζήτηση δεν είναι εφικτή. Ακόμα και η εύρεση μιας εγγραφής 3,4,ebel δεν δείχνει ποιος είναι ολόκληρος ο όρος. Λύση : partial 3-in-4 front coding 36

37
Partial 3-in-4 front coding • Κάθε 4 η λέξη (the one indexed by the block pointer) αποθηκεύεται χωρίς front coding, ώστε η δυαδική αναζήτηση να είναι εφικτή • Σε ένα μεγάλο λεξικό, αποφεύγονται 4 bytes σε καθεμία από τις 3 λέξεις, και χρησιμοποιούνται 2 επιπλέον bytes για επιθεματικούς χαρακτήρες 37
 αποθηκεύεται χωρίς front coding, ώστε η δυαδική αναζήτηση να είναι εφικτή • Σε ένα μεγάλο λεξικό, αποφεύγονται 4 bytes σε καθεμία από τις 3 λέξεις, και χρησιμοποιούνται 2 επιπλέον bytes για επιθεματικούς χαρακτήρες 37")
38
38

39
χρονική απόδοση για ανάκτηση δεδομένων Επιτυγχάνει χρονική απόδοση για ανάκτηση δεδομένων Είναι απαραίτητη για την εφαρμογή ερωτήσεων και για την εξαγωγή σχετικών κειμένων σε σύντομο χρονικό διάστημα λέξη Συνήθης μονάδα ευρετηριοποίησης είναι η λέξη λέξη, πρόταση, παράγραφος, κείμενο, block Θέματα για ευρετηριοποίηση είναι : λέξη, πρόταση, παράγραφος, κείμενο, block

40
Οι μηχανισμοί δεικτοδότησης – ευρετήρια χρησιμοποιούνται για να επιταχύνουν την πρόσβαση σε επιθυμητά δεδομένα • Π.χ., κατάλογος συγγραφέων στη βιβλιοθήκη Ένα ευρετήριο (index) αποτελείται από εγγραφές της μορφής: • κλειδί διάταξης - δείκτης Τα ευρετήρια συνήθως είναι αρκετά μικρότερα από το αρχείο που δεικτοδοτούν.
 αποτελείται από εγγραφές της μορφής: • κλειδί διάταξης - δείκτης Τα ευρετήρια συνήθως είναι αρκετά μικρότερα από το αρχείο που δεικτοδοτούν.")
41
BibleTREC Subset (2G) DocumentsN31,101741,856 No. of terms F884,994333,338,738 Distinct terms n8,965535,346 Index pointers f701,412134,994,414 Total size (MB) 4.332070.29
")
42
μειωθεί δίσκο Το ποσοστό της κύριας μνήμης που απαιτείται από το λεξικό μπορεί να μειωθεί τοποθετώντας το λεξικό στο δίσκο • Στη κύρια μνήμη απομένει μικρή πληροφορία για την αναγνώριση του block που βρίσκεται κάθε όρος

44
ο αριθμός του block Για την εύρεση του block ενός όρου, αναζητείται στο ευρετήριο της κύριας μνήμης ο αριθμός του block • To block τοποθετείται σε buffer • Η αναζήτηση συνεχίζεται μέσα στο block • Ένα B-tree ή κάποια άλλη δομή μπορεί να χρησιμοποιηθεί

45
Αυτή η προσέγγιση είναι απλή και απαιτεί μικρό ποσοστό κύριας μνήμης Ένα λεξικό που βασίζεται στην αποθήκευση του στο δίσκο είναι λίγο πιο αργό σε πρόσβαση σε σχέση με ένα λεξικό που αποθηκεύεται στην κύρια μνήμη • Απαιτείται μια πρόσβαση στο δίσκο σε κάθε αναζήτηση • Είναι ανεκτός o πρόσθετος χρόνος όταν γίνεται αναζήτηση κάποιων όρων ( π. χ. Λιγότεροι από 50 όροι ) • Δεν είναι κατάλληλη προσέγγιση για τη διαδικασία ευρετηριοποίησης
 • Δεν είναι κατάλληλη προσέγγιση για τη διαδικασία ευρετηριοποίησης.")
46
Ενώ μια πρόσβαση στο δίσκο γίνεται σε 10 milliseconds στη μνήμη γίνεται σε λίγα microseconds Για αυτό το σκοπό γίνεται και η χρήση ερωτημάτων Τα κλασικά ερωτήματα δεν εμπλέκουν πάνω από 50 όρους οπότε η αναζήτηση στο λεξικό δεν γίνεται σε πάνω από ένα δευτερόλεπτο Γενικά προτιμάται η αποθήκευση των λεξικών στο δίσκο και ειδικά όταν η ανάκτηση πληροφορίας γίνεται σε μικρούς σταθμούς εργασίας ή προσωπικούς υπολογιστές

47
Υποθέτουμε πως έχουμε τους όρους t Θέλουμε να τους βρούμε στο λεξικό Οι όροι μπορεί να έχουν * • Αν το * είναι στο τέλος τότε με δυαδική αναζήτηση αναζητούμε όρους με το πρόθεμα του t • Αν το * είναι αλλού τότε απαιτούνται διαφορετικές τεχνικές Όλα αυτά δεν είναι συμβατά με το OPMPHF (order preserving minimal perfect hashing function) γιατί απαιτούν πρόσβαση στις ίδιες τις λέξεις
 γιατί απαιτούν πρόσβαση στις ίδιες τις λέξεις")
48
σάρωση των όρων με το πρότυπο χρησιμοποιώντας έναν αλγόριθμο ταιριάσματος προτύπου Έχοντας το λεξικό στην μνήμη είναι δυνατόν να γίνει σάρωση των όρων με το πρότυπο χρησιμοποιώντας έναν αλγόριθμο ταιριάσματος προτύπου (pattern matching algorithm) Δεν απαιτείται επιπλέον χώρος 3 in 4 Front Coding Είναι δυνατή η χρήση 3 in 4 Front Coding Αν το λεξικό είναι διατεταγμένο, κάθε αρχικός χαρακτήρας μπορεί να χρησιμοποιηθεί για να μειώσει το σύνολο αναζήτησης Οι αναζητήσεις με τέτοιου είδους αλγόριθμους είναι εξαντλητική
 Δεν απαιτείται επιπλέον χώρος 3 in 4 Front Coding Είναι δυνατή η χρήση 3 in 4 Front Coding Αν το λεξικό είναι διατεταγμένο, κάθε αρχικός χαρακτήρας μπορεί να χρησιμοποιηθεί για να μειώσει το σύνολο αναζήτησης Οι αναζητήσεις με τέτοιου είδους αλγόριθμους είναι εξαντλητική")
49
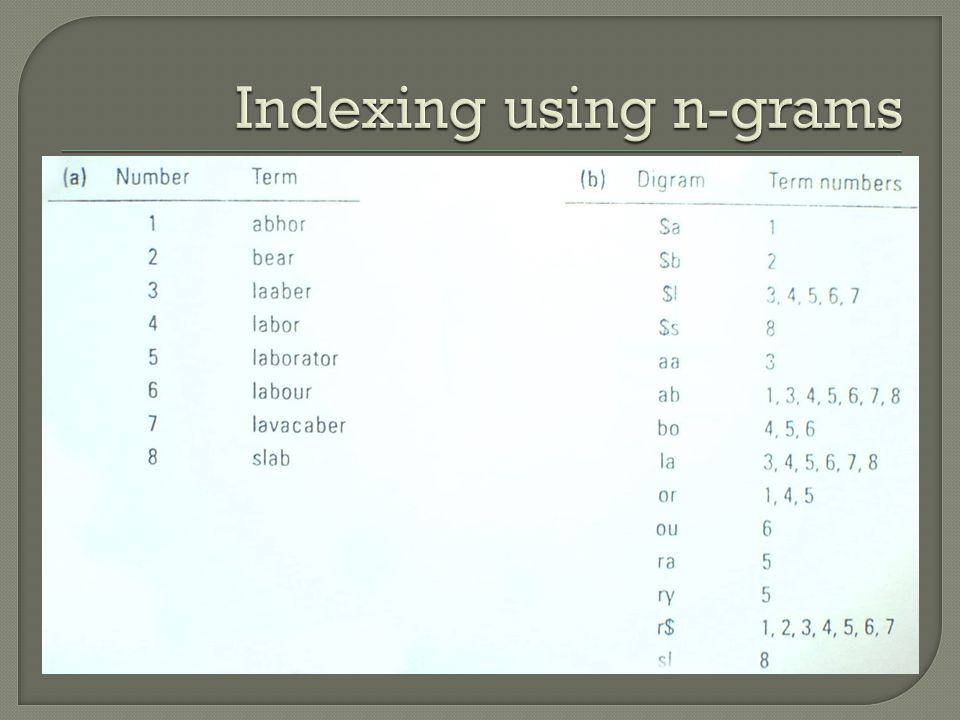
Καλύτερη αναζήτηση με ταίριασμα προτύπων μπορεί να επιτευχθεί αν χρησιμοποιήσουμε επιπλέον μνήμη n-grams για n πολύ μικρό • Δημιουργία των n-grams για n πολύ μικρό Η λέξη labor αποτελείται από τα digrams la, ab, bo, or, $l, r$. Για να βρούμε τον όρο στο λεξικό που ταιριάζει με το lab*r κάνουμε το ερώτημα : $l AND la AND ab AND r$

51
Οι λέξεις laaber, lavacaber είναι λάθος αν και έχουν όσα λέει το ερώτημα αλλά με λάθος σειρά Ο μηχανισμός αυτός λειτουργεί σαν φίλτρο που μειώνει τον αριθμό των strings που πρέπει να ελεγχθούν με τον pattern matcher Η λέξη labrador είναι σωστή σαν απάντηση αλλά όχι απαραίτητα επιθυμητή απάντηση Τα * βοηθούν στην εφαρμογή ερωτημάτων εύκολα και γρήγορα αλλά δεν ικανοποιούν πάντα τον χρήστη Η ανεστραμμένη λίστα των n-grams μπορεί να αποθηκευτεί συμπιεσμένη με κάποια γνωστή τεχνική Υπάρχει tradeoff χρόνου για το χώρο που πρέπει να διατεθεί για τους ελέγχους για λανθασμένα ταιριάσματα

52
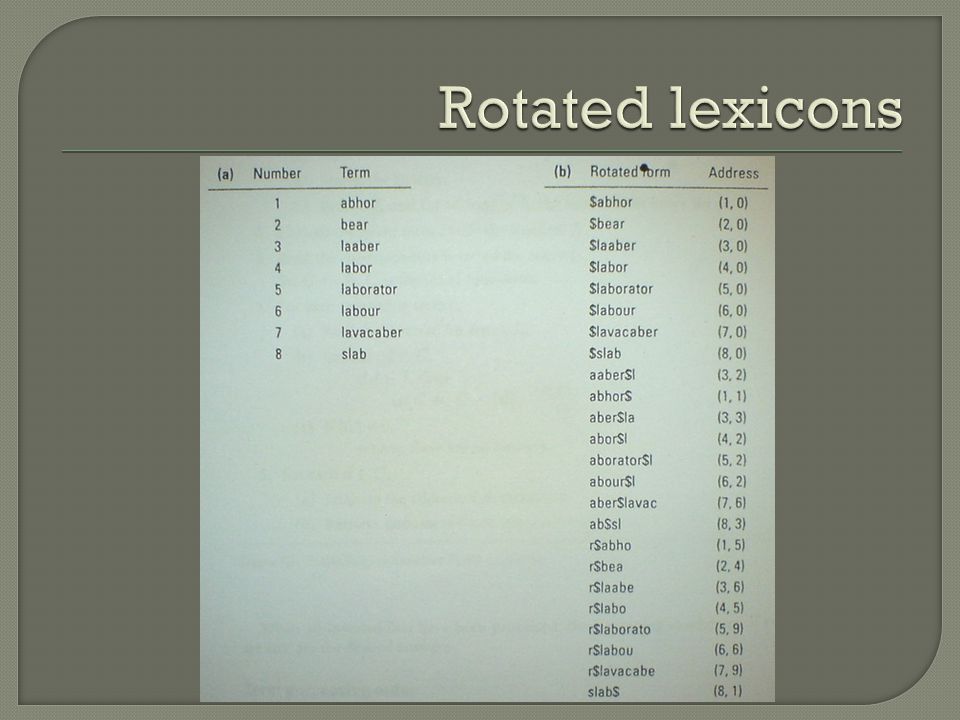
Καλύτερα αποτελέσματα έχουμε αν χρησιμοποιήσουμε περισσότερη μνήμη Ευρετηριοποίηση κάθε χαρακτήρα κάθε όρου του λεξικού ( αντί για κάθε λέξη ) • Για τη λέξη labor έχουμε 6 δείκτες (5 για τους χαρακτήρες και έναν για τον χαρακτήρα τερματισμού ) Ταξινόμηση κάθε δείκτη των χαρακτήρων βάση της περιστροφής των όρων • Για τη λέξη labor έχουμε τα 6 strings που δείχνουν οι δείκτες : labor$, abor$l, bor$la, or$lab, r$labo, $labor)
 • Για τη λέξη labor έχουμε 6 δείκτες (5 για τους χαρακτήρες και έναν για τον χαρακτήρα τερματισμού ) Ταξινόμηση κάθε δείκτη των χαρακτήρων βάση της περιστροφής των όρων • Για τη λέξη labor έχουμε τα 6 strings που δείχνουν οι δείκτες : labor$, abor$l, bor$la, or$lab, r$labo, $labor)")
53
Αν γίνει αυτό, εύκολα εφαρμόζονται ερωτήματα με χρήση * αφού θα γίνεται δυαδική αναζήτηση • Για την αναζήτηση του προτύπου lab*r το lab*r περιστρέφεται μέχρι το * να πάει στο τέλος ( δηλαδή r$lab*) Μετά γίνεται αναζήτηση για strings που έχουν πρόθεμα το r$lab*
 Μετά γίνεται αναζήτηση για strings που έχουν πρόθεμα το r$lab*")
55
Επίσης το *lab* περιστρέφεται σε lab* και η αναζήτηση γίνεται όπως και πριν Αναζήτηση του r$labo* επιστρέφει τις • r$labo • r$laborato • r$labou Όταν αναστραφούν δίνουν τις απαντήσεις

56
Η τεχνική αυτή έχει αποδειχθεί ως γρηγορότερη Στο ίδιο σύνολο του TREC το πείραμα αναζήτησης τρέχει 10 φορές γρηγορότερα επιβαρύνοντας 250% την μνήμη

57
Τέλος κεφαλαίου Querying

58
Τέλος

Παρόμοιες παρουσιάσεις











.>")








>")