Κατέβασμα παρουσίασης
Η παρουσίαση φορτώνεται. Παρακαλείστε να περιμένετε

1
Μεθοδολογία της έρευνας Εισαγωγή στη χρήση του λογισμικού SPSS

2
SPSS Data editor Viewer Syntax editor

3
Data editor Data view Καταχώρηση δεδομένων Variable view Καθορίζω τα χαρακτηριστικά των μεταβλητών Στατιστικές αναλύσεις

4
Ενεργό (Active) Η τιμή του ενεργού κελιού (cell) Βρισκόμαστε στο “Data view” Click για να πάμε στο “Variable view”
 Η τιμή του ενεργού κελιού (cell) Βρισκόμαστε στο Data view Click για να πάμε στο Variable view")
5
Data editor File: Save data, graphs, or output, open files, print graphs or output Edit: Cut/Copy and Paste View: System specifications (e.g., display value labels) Data: Make changes in the data editor Insert variable, Insert cases, Split file, Select cases Transform: Manipulate one of the variables Recode, Compute Analyze: The fun begins here Statistical procedures Graphs Window: Switch from window to window Utilities: Data File Comments Help: Online help on the system itself and the statistical tests
 Data: Make changes in the data editor Insert variable, Insert cases, Split file, Select cases Transform: Manipulate one of the variables Recode, Compute Analyze: The fun begins here Statistical procedures Graphs Window: Switch from window to window Utilities: Data File Comments Help: Online help on the system itself and the statistical tests")
6
Data editor Καταχώρηση δεδομένων Row: Δεδομένα ενός ατόμου Column: Μεταβλητή (Variable)
")
7
Variable view Δημιουργία μεταβλητών Πριν την καταχώρηση δεδομένων Χαρακτηριστικά των μεταβλητών Name Type: Numeric, String, Currency, Data Width (default: 8) Decimals (default: 2) Label: Longer variable description Values: Numbers that represent groups of people Missing: Missing data Columns: How many characters are displayed in the column Align: Left, Right, Center Measure: Nominal, Ordinal, Scale
 Decimals (default: 2) Label: Longer variable description Values: Numbers that represent groups of people Missing: Missing data Columns: How many characters are displayed in the column Align: Left, Right, Center Measure: Nominal, Ordinal, Scale")
8
Creating a string variable Move the on-screen arrow (using the mouse) to the first white cell in the column labelled Name. Type the word Name. Move off this cell using the arrow keys on the keyboard or click on a different cell. Αλλάζω τον τύπο (type) της μεταβλητής: Numeric String Measure Nominal
 της μεταβλητής: Numeric String Measure Nominal.")
9
Creating a date variable Move to the cell in row 2 and type the word “Birth_Date” Move to the column Type Αλλάζω τον τύπο (type) της μεταβλητής: Numeric Date
 της μεταβλητής: Numeric Date")
10
Creating a coding variable Coding variable or grouping variable Χρησιμοποιώ αριθμούς οι οποίοι αντιστοιχούν σε ομάδες δεδομένων (π.χ., άντρες – γυναίκες, πειραματική ομάδα – ομάδα ελέγχου) Είναι numeric variable αλλά οι αριθμοί αντιστοιχούν σε ονόματα (δηλ. Είναι nominal variable) Αντιστοιχούν σε ανεξάρτητες μεταβλητές (between-subjects) Move in the third row and type the word “Group” Move in the third row to the column called ‘Label’ and give the variable a full description, e.g., “Is the person a lecturer or a student?” To define the group codes move along the row to the column labeled ‘Values’ 1 for Lecturer, 2 for student Measure Nominal or Ordinal (if the groups have a meaningful order)
 Αντιστοιχούν σε ανεξάρτητες μεταβλητές (between-subjects) Move in the third row and type the word Group Move in the third row to the column called ‘Label’ and give the variable a full description, e.g., Is the person a lecturer or a student To define the group codes move along the row to the column labeled ‘Values’ 1 for Lecturer, 2 for student Measure Nominal or Ordinal (if the groups have a meaningful order).")
11
Number of friends Variable view ‘Friends’ Αλλάζω τον τύπο (type) της μεταβλητής Numeric Decimals ‘0’ Measure Scale Creating a numeric variable
 της μεταβλητής Numeric Decimals ‘0’ Measure Scale Creating a numeric variable")
12
Missing values We choose a numeric value to represent the missing data point This value tells the SPSS that there is no recoded value for a participant for a certain variable. The computer then ignores that cell of the data editor. Be careful: the chosen code not to correspond to any naturally occurring data. Click in the column labeled ‘Missing’ Select discrete values Assign a different meaning to each discrete value (e.g., 8 ‘not applicable’, 9 ‘don’t know’, 99 ‘no response’) Select a range of values To have a range of values and one discrete value
 Select a range of values To have a range of values and one discrete value.")
13
The SPSS Viewer Tree Diagram of the Current Output Results of Statistical Analysis

14
The Syntax Editor Usually for doing advanced things If you often carry out very similar analyses on data sets Quicker to do the analysis and save the syntax Paste button Run Selection Current To End File New Syntax

15
The Syntax Editor

16
Saving files Data analysis.sav Output.spv Syntax file.sps

17
Retrieving a file File Open Data Output Syntax

18
Είδη έρευνας Υποθέσεις (Hypotheses): Το να μιλάμε μπροστά σε άλλους μας προκαλεί άγχος. Το κάπνισμα προκαλεί καρκίνο. Η παρακολούθηση του μαθήματος της Μεθοδολογίας ΙΙ βοηθά τους φοιτητές να κάνουν καλές διπλωματικές Correlational/Observational Research (Συσχετιστική έρευνα) Experimental Research (Πειραματική έρευνα)
 Experimental Research (Πειραματική έρευνα).")
19
Είδη Μεταβλητών Υπόθεση: Το να μιλάμε μπροστά σε άλλους μας προκαλεί άγχος. Αιτία και Αποτέλεσμα = Μεταβλητές (Variables) Ανεξάρτητη Μεταβλητή (Independent Variable) Εξαρτημένη Μεταβλητή (Dependent Variable) Ο ερευνητής χειρίζεται την IV και μετράει την DV Χειρισμός = Δημιουργία Επιπέδων (levels) ή Συνθηκών (conditions) Πόσα πρέπει να είναι τα επίπεδα;
 Ανεξάρτητη Μεταβλητή (Independent Variable) Εξαρτημένη Μεταβλητή (Dependent Variable) Ο ερευνητής χειρίζεται την IV και μετράει την DV Χειρισμός = Δημιουργία Επιπέδων (levels) ή Συνθηκών (conditions) Πόσα πρέπει να είναι τα επίπεδα;.")
20
Μετρήσεις και Δεδομένα Μη Παραμετρικά Δεδομένα (Non-Parametric Data) Nominal Data (Κατηγορικά) π.χ., 1: άντρας, 2: γυναίκα π.χ., χρώμα μαλλιών Ordinal Data (Διατακτικά) π.χ., 1: διαφωνώ απόλυτα, 2: διαφωνώ, 3: ούτε διαφωνώ ούτε συμφωνώ, 4: συμφωνώ, 5: συμφωνώ απόλυτα
 Nominal Data (Κατηγορικά) π.χ., 1: άντρας, 2: γυναίκα π.χ., χρώμα μαλλιών Ordinal Data (Διατακτικά) π.χ., 1: διαφωνώ απόλυτα, 2: διαφωνώ, 3: ούτε διαφωνώ ούτε συμφωνώ, 4: συμφωνώ, 5: συμφωνώ απόλυτα")
21
Μετρήσεις και Δεδομένα Παραμετρικά Δεδομένα (Parametric Data) Interval Data (Ισοδιαστημικά) Δεν υπάρχει απόλυτο μηδέν Δεν έχουν νόημα οι αναλογίες (ratios) π.χ., θερμοκρασία Ratio Data (Αναλογίας) π.χ., βάρος, βαθμοί σε εξέταση, χρόνος αντίδρασης, ακρίβεια Continuous vs Discrete Variables
 Interval Data (Ισοδιαστημικά) Δεν υπάρχει απόλυτο μηδέν Δεν έχουν νόημα οι αναλογίες (ratios) π.χ., θερμοκρασία Ratio Data (Αναλογίας) π.χ., βάρος, βαθμοί σε εξέταση, χρόνος αντίδρασης, ακρίβεια Continuous vs Discrete Variables")
22
Πληθυσμός και Δείγμα Πληθυσμός (Population): π.χ., όλοι οι άνθρωποι στον κόσμο, παιδιά με σύνδρομο ελλειμματικής προσοχής. Δείγμα (Sample): π.χ., 20 φοιτητές του Πανεπιστημίου Κύπρου Το δείγμα πρέπει να είναι αντιπροσωπευτικό (representative)
: π.χ., 20 φοιτητές του Πανεπιστημίου Κύπρου Το δείγμα πρέπει να είναι αντιπροσωπευτικό (representative).")
23
Περιγραφική Στατιστική Κατανομή Συχνότητας (Frequency Distribution) π.χ., 10,6,7,8,9,7,10,2,8,6,8,3,8,9,8,5,7,5,4,9 Πόσες φορές εμφανίζεται το κάθε σκορ;
 π.χ., 10,6,7,8,9,7,10,2,8,6,8,3,8,9,8,5,7,5,4,9 Πόσες φορές εμφανίζεται το κάθε σκορ;")
24
Ιστόγραμμα (Histogram) Τι μπαίνει στον άξονα ψ; Τι πληροφορίες μας δίνει το ιστόγραμμα;
 Τι μπαίνει στον άξονα ψ; Τι πληροφορίες μας δίνει το ιστόγραμμα;")
25
Η καμπύλη της φυσικής κατανομής (the normal curve)
")
26
The Kolmogorov-Smirnov (K-S) test Έχουν τα δεδομένα μας φυσική κατανομή; Υπάρχουν outliers; Analyze ⇒ Descriptive Statistics ⇒ Explore
 test Έχουν τα δεδομένα μας φυσική κατανομή; Υπάρχουν outliers; Analyze ⇒ Descriptive Statistics ⇒ Explore")
27
The K-S test Εάν το p-value από το τεστ είναι μικρότερο από.05 τότε τα δεδομένα μας αποκλίνουν από τη φυσική κατανομή.

28
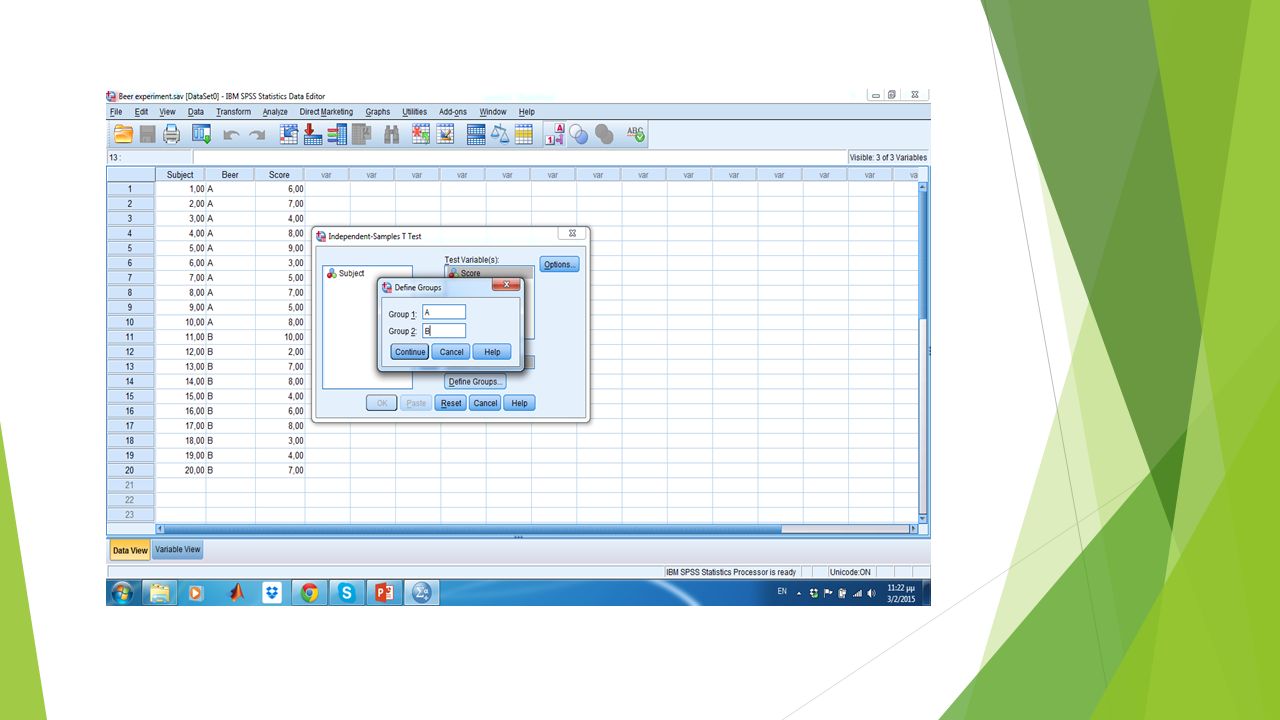
Student’s t-test Το πρόβλημα του “Student”: Έχω 2 συνταγές μπύρας, την Α και τη Β. Ποια από τις δύο προτιμά ο κόσμος; Πως θα τον βοηθούσατε;

29
Πείραμα μπύρας Ανοίξτε το πρόγραμμα SPSS και καταχωρήστε τα εξής δεδομένα (data). Τι θα κάνω για να δω εάν υπάρχει προτίμηση για μια από τις δύο μπύρες;

30
Υπολογισμός Μέσου Όρου στο SPSS Analyze -> Compare Means -> Means

31
Υπάρχει διαφορά στην προτίμηση για τις δύο μπύρες στο δείγμα (sample); Στον πληθυσμό (population);
; Στον πληθυσμό (population);")
32
Μηδενική και Εναλλακτική Υπόθεση Μηδενική Υπόθεση (Null Hypothesis): Δεν υπάρχει διαφορά στην απώλεια βάρους στις δύο ομάδες. Μπύρα Α = Μπύρα Β Εναλλακτική υπόθεση (Alternative Hypothesis): Υπάρχει διαφορά. Μπύρα Α ≠ Μπύρα Β Αρχίζουμε από τη Μηδενική Υπόθεση και προσπαθούμε να την απορρίψουμε. Προσπαθούμε να δούμε εάν η διαφορά που βρίσκουμε (π.χ..3) οφείλεται στην τύχη.
: Υπάρχει διαφορά. Μπύρα Α ≠ Μπύρα Β Αρχίζουμε από τη Μηδενική Υπόθεση και προσπαθούμε να την απορρίψουμε. Προσπαθούμε να δούμε εάν η διαφορά που βρίσκουμε (π.χ..3) οφείλεται στην τύχη..")
33
Μηδενική και Εναλλακτική Υπόθεση Μπύρα Α: 6.2 Μπύρα Β: 5.9 Ποια η πιθανότητα (p) η διαφορά του.3 να οφείλεται στην τύχη; Για να απορρίψουμε τη Μηδενική Υπόθεση θέλουμε το p να είναι μικρό ή μεγάλο;
 η διαφορά του.3 να οφείλεται στην τύχη; Για να απορρίψουμε τη Μηδενική Υπόθεση θέλουμε το p να είναι μικρό ή μεγάλο;")
34
Student’s t-test Υπολογίζει την πιθανότητα (p) να οφείλεται στην τύχη η ύπαρξη της διαφοράς μεταξύ 2 μέσων όρων. Εάν η πιθανότητα αυτή είναι αρκετά μικρή (π.χ., p <.05) τότε δεχόμαστε ότι η διαφορά είναι στατιστικά σημαντική (significant). Απορρίπτουμε δηλαδή τη Μηδενική Υπόθεση.
 τότε δεχόμαστε ότι η διαφορά είναι στατιστικά σημαντική (significant). Απορρίπτουμε δηλαδή τη Μηδενική Υπόθεση..")
35
Είδη πειραματικών σχεδίων Μεταξύ των υποκειμένων (Διομαδικό Σχέδιο) [Between-subjects design] Εντός των υποκειμένων (Ενδοομαδικό Σχέδιο) [Within-subjects design] Μικτά πειραματικά σχέδια [Mixed Designs]
![Είδη πειραματικών σχεδίων Μεταξύ των υποκειμένων (Διομαδικό Σχέδιο) [Between-subjects design] Εντός των υποκειμένων (Ενδοομαδικό Σχέδιο) [Within-subjects design] Μικτά πειραματικά σχέδια [Mixed Designs]](http://images.slideplayer.gr/40/11155338/slides/slide_35.jpg "Είδη πειραματικών σχεδίων Μεταξύ των υποκειμένων (Διομαδικό Σχέδιο) [Between-subjects design] Εντός των υποκειμένων (Ενδοομαδικό Σχέδιο) [Within-subjects design] Μικτά πειραματικά σχέδια [Mixed Designs]")
36
T-test Διομαδικού σχεδίου στο SPSS Analyze -> Compare Means -> Independent Samples T-test

38
p =.77. Η διαφορά που βρήκαμε (.3) οφείλεται κατά 77% στην τύχη.
 οφείλεται κατά 77% στην τύχη.")
39
Θέλετε να κάνετε ένα πείραμα για να δείτε εάν έχουμε καλύτερη μνήμη για λέξεις με υλική υπόσταση (concrete words) παρά για αφηρημένες λέξεις (abstract words). Πως θα το κάνατε;

40
Πείραμα μνήμης Ανοίξτε το πρόγραμμα SPSS και καταχωρήστε τα εξής δεδομένα (data). SubjectConcreteAbstract 166 21510 3137 4148 5128 61612 71410 81510 91811 10179 11128 78 13158 Προσέξτε πως διαφέρει η διαρρύθμιση των δεδομένων στα δύο είδη σχεδίου. Υπολογίστε τους μέσους όρους για την κάθε συνθήκη.

41
T-test ενδο-ομαδικού σχεδίου στο SPSS Analyze -> Compare means -> Paired Samples T-test

42
p =.000. Είναι στατιστικά σημαντική η διαφορά των 4.54 λέξεων; Τι σημαίνει αυτό για τη Μηδενική Υπόθεση;

43
T-test vs ANOVA Πότε κάνουμε T-test και πότε ANOVA; Πολλά T-tests 5% πιθανότητα να αποδεχτούμε μια επίδραση που δεν ισχύει (Type I error) Λύση;
 Λύση;")
44
ANOVA Όταν θέλουμε να συγκρίνουμε 3 ή περισσότερους μέσους όρους ”way” = ανεξάρτητες μεταβλητές, π.χ. One-way ANOVA, Two-way ANOVA, Three-way ANOVA κλπ Independent, Repeated-Measures, Mixed, π.χ., Three-way Mixed ANOVA

45
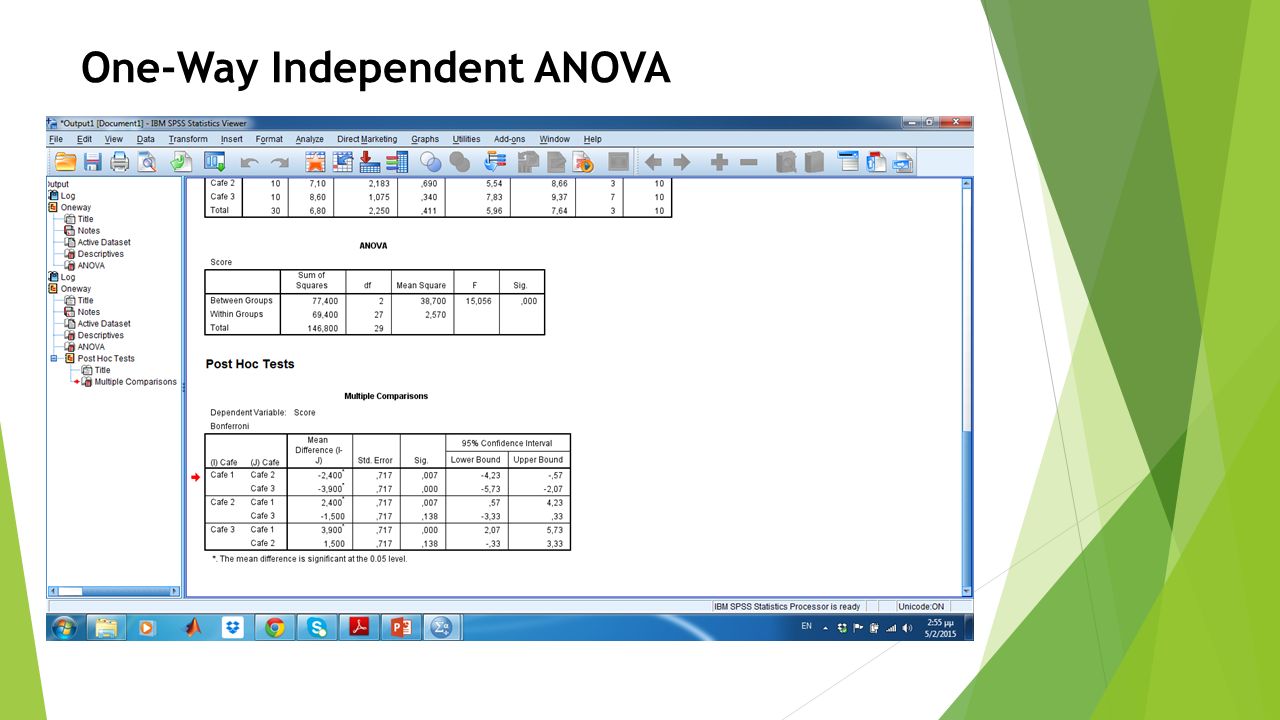
One-Way Independent ANOVA Όταν θέλουμε να συγκρίνουμε 3 ή περισσότερους μέσους όρους. Σε κάθε ομάδα έχουμε διαφορετικούς συμμετέχοντες (Διομαδικό σχέδιο/Between- subjects design).
..")
46
One-Way Independent ANOVA Θέλετε να συγκρίνετε τη γεύση των φραπέ 3 café της Λευκωσίας χρησιμοποιώντας διομαδικό σχέδιο (between-subjects design). Πως θα το κάνετε;

47
One-Way Independent ANOVA Ανοίξτε το SPSS και καταχωρήστε τα πιο κάτω δεδομένα (data):
:")
48
One-Way Independent ANOVA Analyze -> Compare Means -> One-way ANOVA Στα ‘Options’ επιλέξτε ‘Descriptive’ για να πάρετε τους μέσους όρους και ‘Homogeneity of Variance Test’ για εξετάσετε αν ισούνται οι διακυμάνσεις στις ομάδες (αν p <.05 τότε οι διακυμάνσεις διαφέρουν στατιστικά σημαντικά).
.")
49
One-Way Independent ANOVA p-value Κύρια επίδραση (Main effect) F (2, 29) = 15.05, p <.05 Τι σημαίνει το p-value στην περίπτωση αυτή;
 F (2, 29) = 15.05, p <.05 Τι σημαίνει το p-value στην περίπτωση αυτή;")
50
One-Way Independent ANOVA Εάν p <.05 τότε προχωρούμε για να συγκρίνουμε το κάθε επίπεδο με τα υπόλοιπα. Analyze -> Compare Means -> ANOVA -> Post Hoc… Διαλέγουμε κάποιο τεστ. Bonferroni και Tukey είναι τα πιο γνωστά.

51
One-Way Independent ANOVA

53
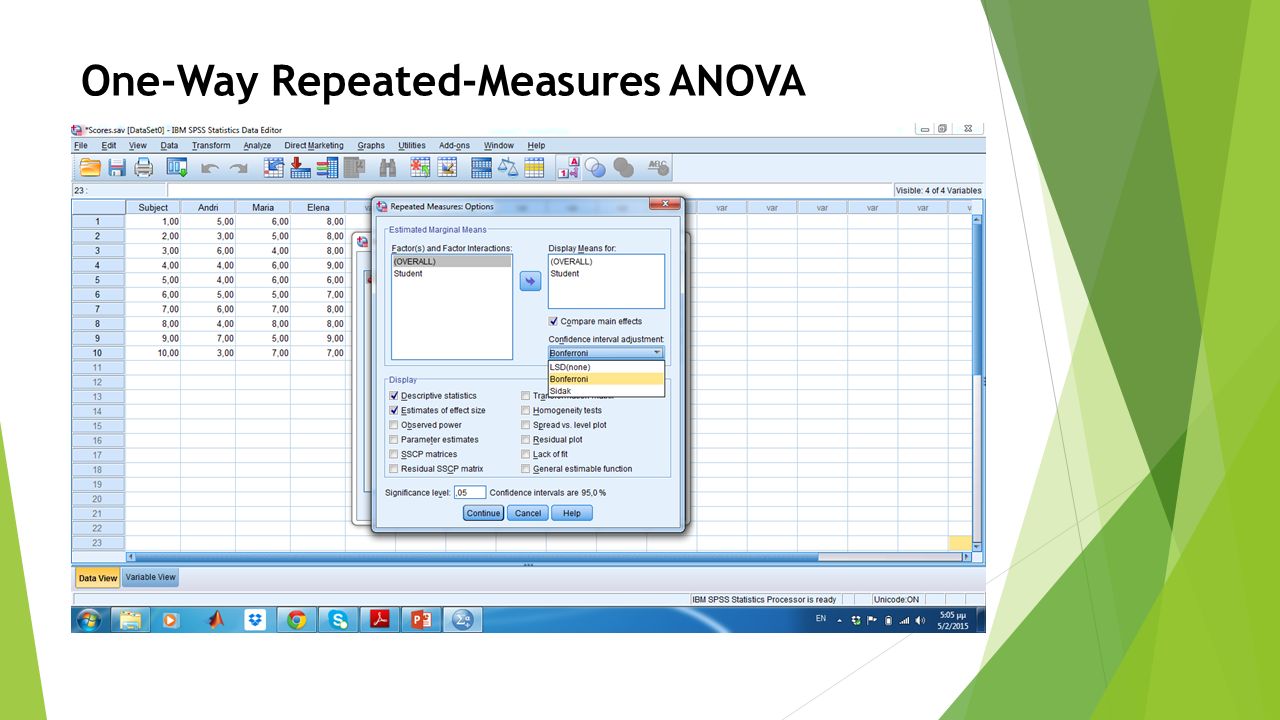
One-Way Repeated-Measures ANOVA ANOVA για ενδο-ομαδικό σχέδιο (within-subjects design)
")
54
One-Way Repeated-Measures ANOVA Analyze -> General Linear Model -> Repeated Measures…

55
One-Way Repeated-Measures ANOVA

57
Πατάτε το ‘Contrast’, διαλέξτε μια επιλογή (π.χ., ‘Repeated’), και μετά πατάτε το ‘Change’.
, και μετά πατάτε το ‘Change’.")
58
One-Way Repeated-Measures ANOVA p-value Υπάρχει κύρια επίδραση (main effect) της ανεξάρτητης μεταβλητής;
 της ανεξάρτητης μεταβλητής;")
59
One-Way Repeated-Measures ANOVA

60
p-value

61
Συσχετιστική Έρευνα Συσχετιστική Έρευνα (Correlational Research) Δεν υπάρχει διάκριση αιτίας και αιτιατού Δεν υπάρχουν ανεξάρτητες και εξαρτημένες μεταβλητές Όλες οι μεταβλητές είναι ποσοτικές (συνήθως) Υπόθεση: Η συσχέτιση είναι διαφορετική από το 0 (δηλ. διαφορετική από το «καμία συσχέτιση»)
.")
62
Πως μετρούμε τις σχέσεις μεταξύ των μεταβλητών; Συμμεταβλητότητα (Covariance) Αλλαγές στις τιμές της μιας μεταβλητής συμβαίνουν παράλληλα με αλλαγές στις τιμές της άλλης μεταβλητής. Συσχετιστική Έρευνα

63
Bivariate correlation Μέτρηση δύο μεταβλητών και εντοπισμού της σχέσης μεταξύ τους. π.χ., IQ γονιών και IQ παιδιών Προβλεψιμότητα Πρόβλημα τρίτων μεταβλητών: οι μεταβλητές μπορεί να συσχετίζονται έμμεσα κι όχι άμεσα. π.χ. Κάπνισμα κατά τη διάρκεια της εγκυμοσύνης και προβλήματα συμπεριφοράς των παιδιών.

64
Θετική Συσχέτιση (Positive Correlation)
")
65
Negative Correlation (Αρνητική Συσχέτιση)
")
66
No correlation (Μη συσχετισμός) Όταν οι τιμές της μιας μεταβλητής αλλάζουν, οι τιμές της άλλης δεν επηρεάζονται. Παραδείγματα; Πόσες φορές βγαίνεις έξω – πόσο σ’ αρέσουν τα λουλούδια

67
Δύναμη Συσχέτισης

68
Δείκτες Συσχέτισης Parametric Pearson's correlation coefficient: r Προϋποθέσεις του Pearson r Interval data

69
Δείκτες Συσχέτισης Τιμές μεταξύ -1 και 1 Το πρόσημο δείχνει την κατεύθυνση Όσο πιο μεγάλη είναι η απόλυτη τιμή του δείκτη τόσο πιο δυνατή (strong) είναι η συσχέτιση p-value Ποια είναι η πιο δυνατή συσχέτιση από τις πιο κάτω; .4, -.5,.8, -.9
 είναι η συσχέτιση p-value Ποια είναι η πιο δυνατή συσχέτιση από τις πιο κάτω; .4, -.5,.8, -.9")
70
Δείκτες Συσχέτισης στο SPSS Analyze -> Correlate -> Bivariate

71
Δείκτες Συσχέτισης στο SPSS Options -> Means and standard deviations

72
Δείκτες Συσχέτισης στο SPSS

73
Scatter plot in SPSS Graphs -> Legacy Dialogs -> Scatter/Dot…

74
Περιορισμοί Δεν μπορούμε να γνωρίζουμε την αιτιώδη σχέση μεταξύ δύο μεταβλητών (Correlation is not causation!). Δε δουλεύει με όλες τις μεταβλητές. Πρέπει να είναι ποσοτικές.

75
Γραμμική παλινδρόμηση Προβλεπτικός παράγοντας (Predicting variable) Αποτέλεσμα (Outcome) Παράδειγμα;
 Αποτέλεσμα (Outcome) Παράδειγμα;")
76
Ταιριάζουμε (fit) το μοντέλο στα δεδομένα μας Το χρησιμοποιούμε για να προβλέψουμε τις τιμές της εξαρτημένης μεταβλητής (DV) από μία ανεξάρτητη μεταβλητή (IV). Γραμμική παλινδρόμηση

77
Το μοντέλο που ταιριάζουμε (fit) στα δεδομένα μας -> Γραμμικό (Linear) Διαλέγουμε το μοντέλο που περιγράφει τα δεδομένα μας με τον καλύτερο δυνατό τρόπο. Γραμμική παλινδρόμηση

78
Ευθεία γραμμή (Straight line) Συντελεστές παλινδρόμησης (Regression coefficients) Κλίση (Slope) -> b1 Τομή (Intercept) ->b0 Γραμμική παλινδρόμηση
 Συντελεστές παλινδρόμησης (Regression coefficients) Κλίση (Slope) -> b1 Τομή (Intercept) ->b0 Γραμμική παλινδρόμηση")
79
Method of least squares Επιλέγει τη γραμμή με το ελάχιστο άθροισμα των διαφορών υψωμένων στο τετράγωνο (squared differences). Η γραμμή που αντιπροσωπεύει καλύτερα τα δεδομένα μας

80
Assessing individual predictors Αν μια μεταβλητή προβλέπει σημαντικά ένα αποτέλεσμα -> b-value ≠ 0 (<.05) T-statistic test: Εξετάζει τη μηδενική υπόθεση (null hypothesis) -> b = 0
 T-statistic test: Εξετάζει τη μηδενική υπόθεση (null hypothesis) -> b = 0")
81
Doing simple regression on SPSS Analyze -> Regression -> Linear

82
Dependent -> Outcome (sales) Independent(s) -> Predictor (adverts) Doing simple regression on SPSS
 Independent(s) -> Predictor (adverts) Doing simple regression on SPSS")
83
Interpreting a simple regression Overall fit of the model R =.578: Συσχέτιση predictor και outcome R² =.335: To Advertising Budget εξηγεί το 33,5% της διακύμανσης των πωλήσεων (record sales) -> Το 66% της διακύμανσης;
 -> Το 66% της διακύμανσης;")
84
F-ratio Significance (Sig.) value of the F-ratio Interpreting a simple regression
 value of the F-ratio Interpreting a simple regression")
85
Model parameters Interpreting a simple regression B 0 = 134,140, p <.001 B 1 =.096, p <.001

86
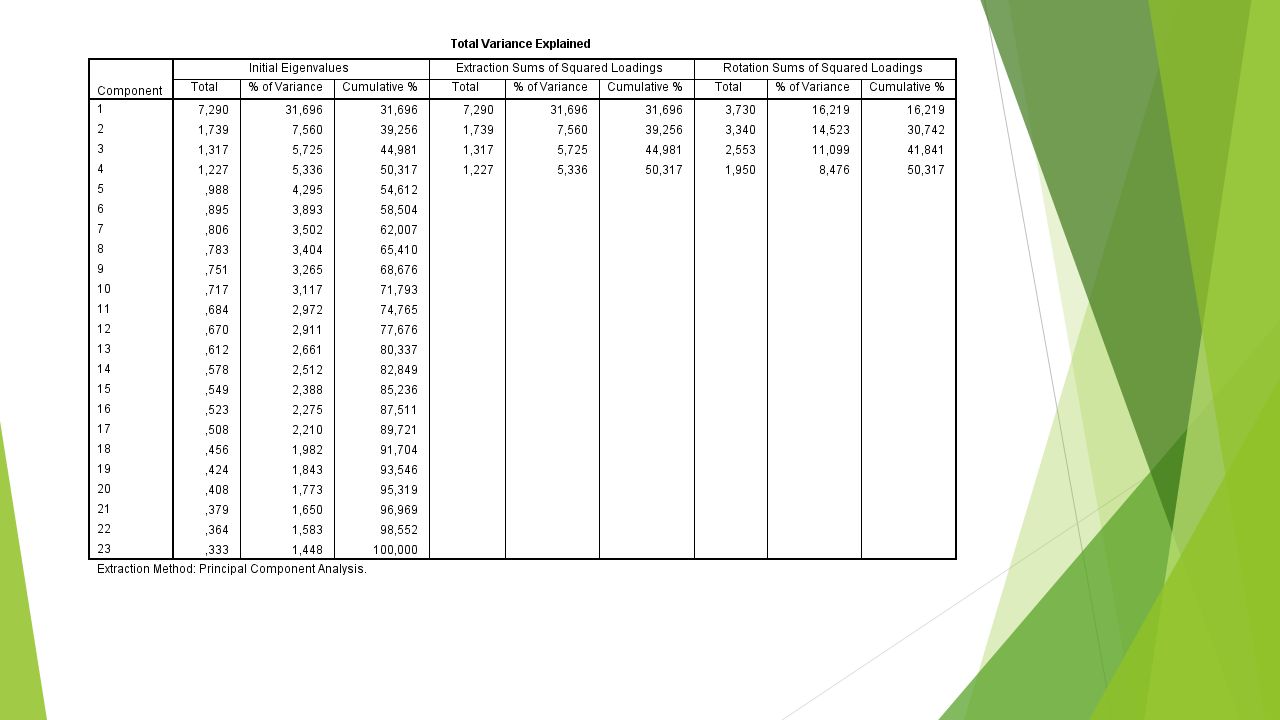
Exploratory factor analysis (Διερευνητική ανάλυση παραγόντων) Πότε το χρησιμοποιούμε; Κατανόηση της δομής ενός σετ μεταβλητών. Κατασκευή ερωτηματολογίου για μέτρηση μιας μεταβλητής. Μείωση ενός σετ δεδομένων σε μέγεθος που να είναι πιο εύκολο να το χειριστεί ο ερευνητής διατηρώντας όσα περισσότερα από τα αρχικά δεδομένα.

87
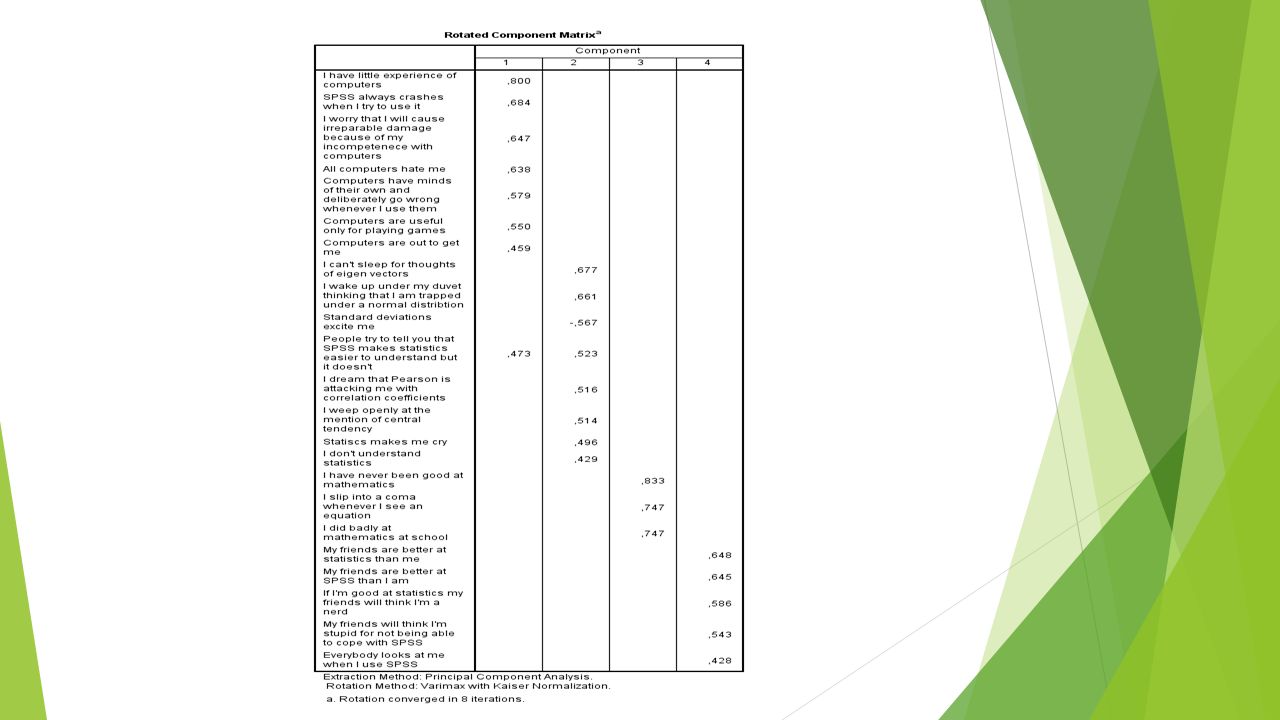
R-matrix: συσχέτιση μεταξύ ζευγών μεταβλητών Ομάδες μεταβλητών που συσχετίζονται μεταξύ τους Μετρούν την ίδια διάσταση -> Παράγοντες (Factors) / Λανθάνουσες μεταβλητές (Latent variables) Δε συσχετίζονται με μεταβλητές έξω από την ομάδα Ανάλυση παραγόντων -> Εξοικονόμηση: Επεξηγεί το μέγιστο ποσοστό της κοινής διακύμανσης στη συσχέτιση χρησιμοποιώντας το μικρότερο αριθμό επεξηγηματικών εννοιών. Παράδειγμα; Factor analysis

88
Factor analysis -> Μας ενδιαφέρει η κοινή διακύμανση (common variance) Communality: Μέτρηση του μεγέθους της διακύμανσης που εξηγείται από τους παράγοντες (factors). Communality

89
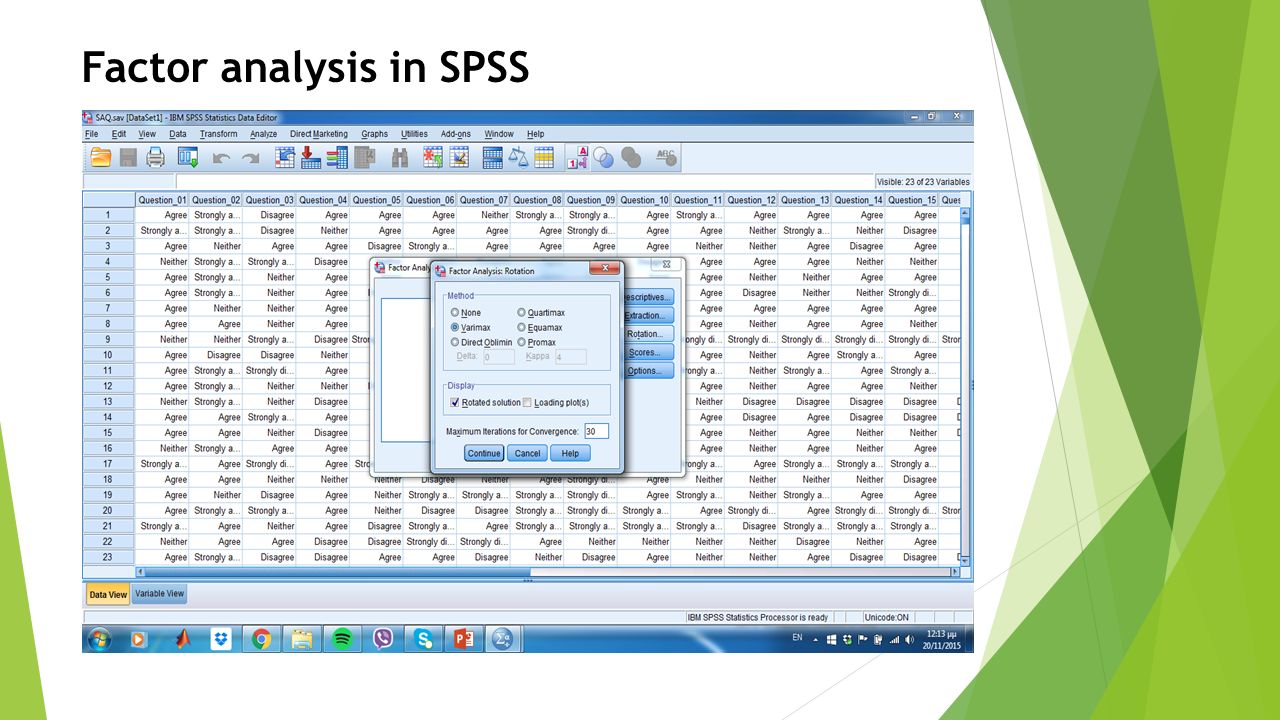
Factor rotation Περιστρέφει τους άξονες των παραγόντων ούτως ώστε οι μεταβλητές να φορτίζουν στο μέγιστο βαθμό μόνο σε ένα παράγοντα. Orthogonal rotation (varimax, quartimax, equamax) Varimax: Μεγιστοποιεί τη διασπορά των φορτίσεων εντός των παραγόντων. Oblique rotation (direct oblimin, promax)
 Varimax: Μεγιστοποιεί τη διασπορά των φορτίσεων εντός των παραγόντων. Oblique rotation (direct oblimin, promax).")
90
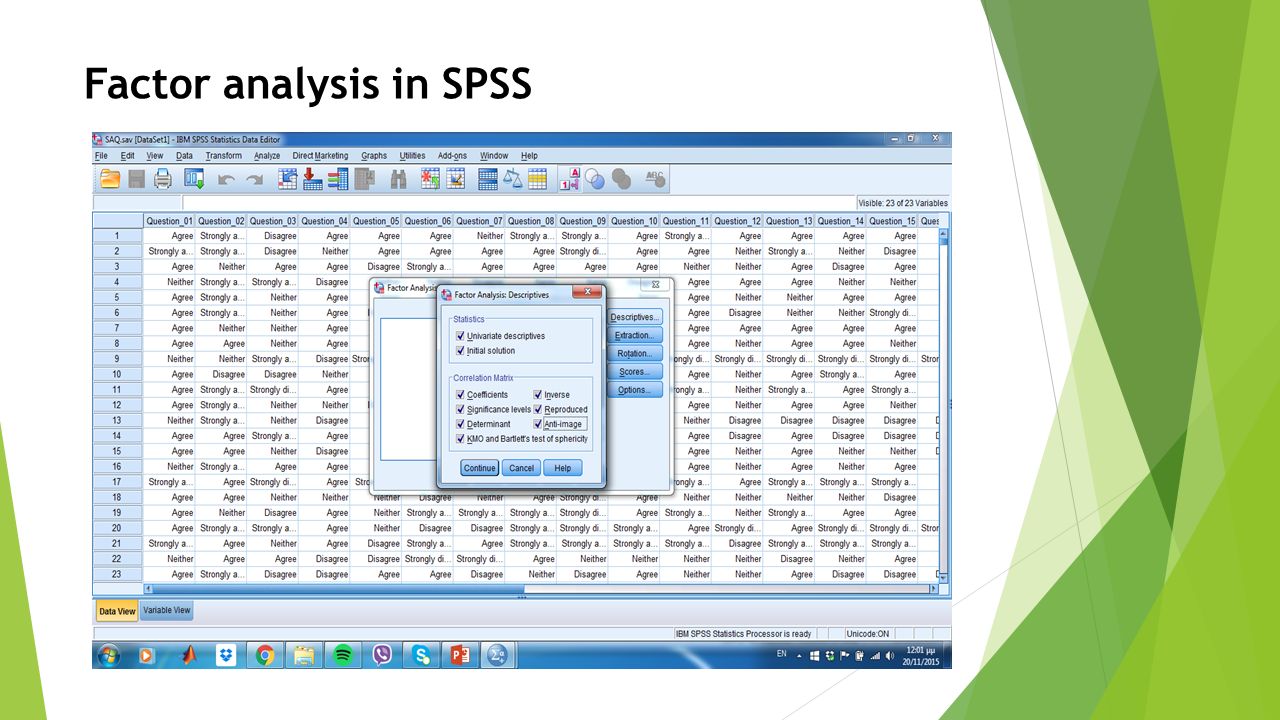
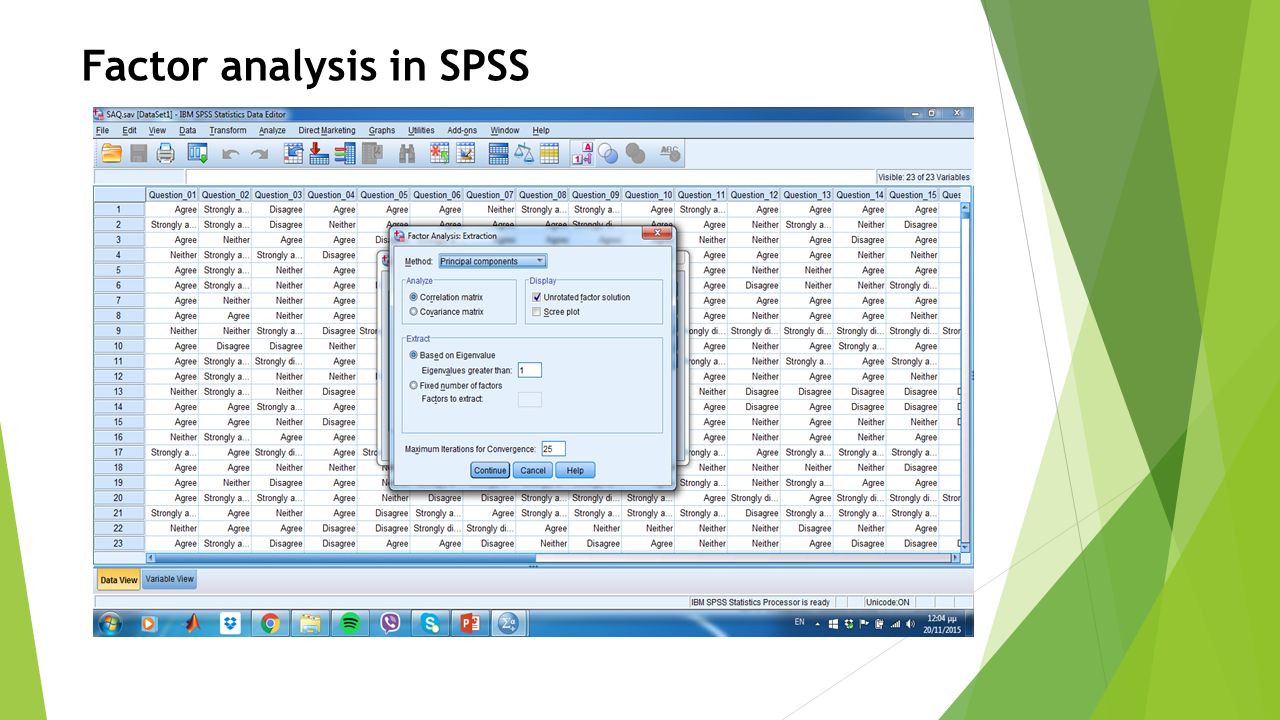
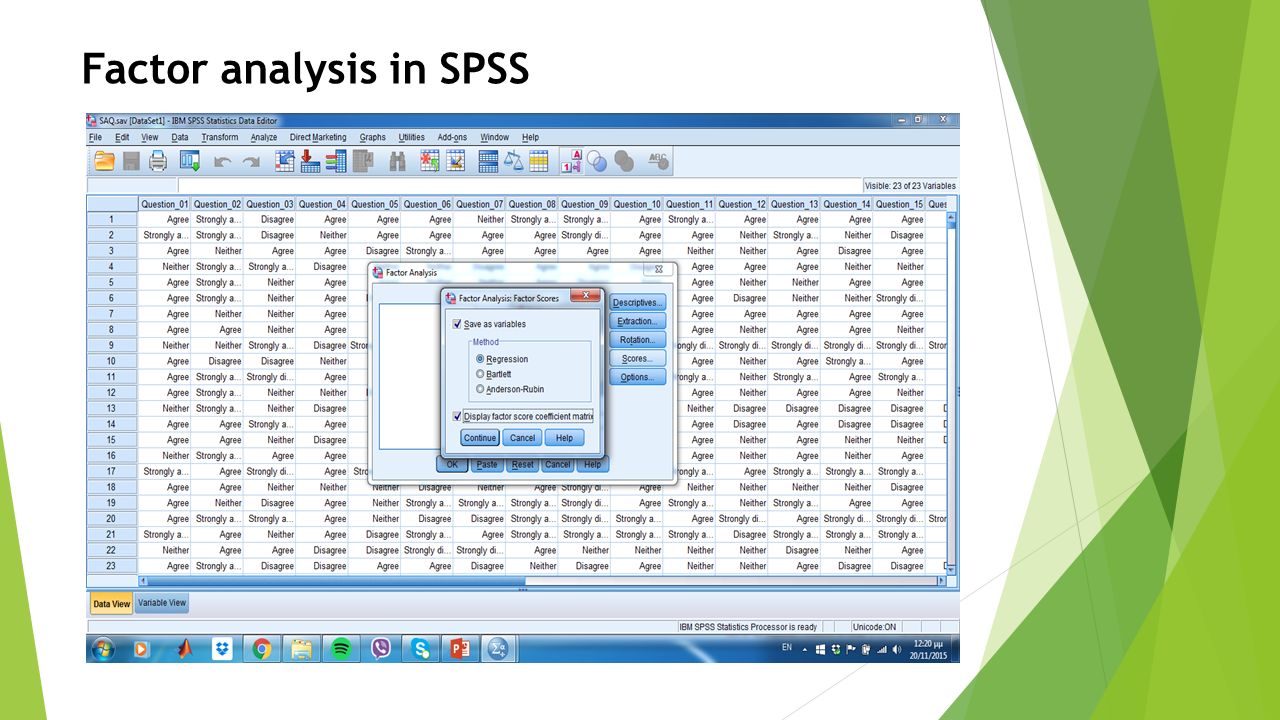
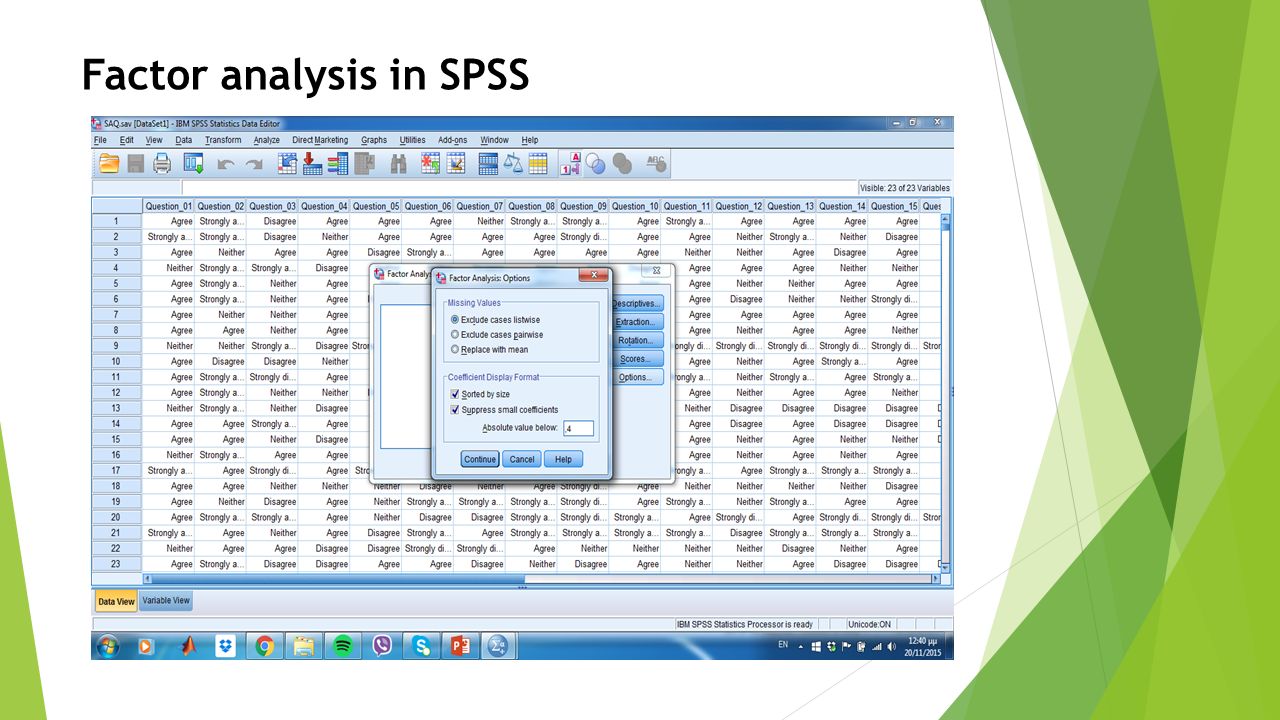
Factor analysis in SPSS Analyze -> Dimension Reduction -> Factor

91
Factor analysis in SPSS

Παρόμοιες παρουσιάσεις




>")

 Δρ. Παντελής Μ.>")






>")





 Διάλεξη 4 Πολλαπλή γραμμική παλινδρόμηση>")

