Κατέβασμα παρουσίασης
Η παρουσίαση φορτώνεται. Παρακαλείστε να περιμένετε

1
Υπολογιστική Βιολογία ΕΠΛ 450
ΠΑΝΕΠΙΣΤΗΜΙΟ ΚΥΠΡΟΥ Υπολογιστική Βιολογία ΕΠΛ 450

2
Ομάδα μαθήματος Δικτυακός τόπος μαθήματος
Δημήτρης Βογιατζής, Διαλέξεις, εργαστήριο Άθως Αντωνιάδης, Εργαστήριο Παύλος Αντωνίου, Σημειώσεις Δικτυακός τόπος μαθήματος

3
Τι είναι η Βιοπληροφορική;
Συγχώνευση Βιολογίας και Πληροφορικής Πρώτη αναφορά στον όρο το 1991 Η σχεδίαση και η εφαρμογή μεθόδων για συλλογή, οργάνωση, κατηγοριοποίηση, αποθήκευση και ανάλυση βιολογικών ακολουθιών(DNA,RNA, πρωτεϊνικών)
")
4
Χαρακτηριστικά τα μεγέθη...
PDB: πληροφορίες για 23,997 τριδιάστατες δομές πρωτεϊνών (20-Ιαν-2004). PubMed περιλαμβάνει πάνω από 14M περιλήψεις βιοιατρικών άρθρων (από το 1950). GenBank 28 GBps (δισεκατομμύρια ζεύγη βάσεων) Trembl 1 M καταχωρήσεις (16-Ιαν-2004) Οι καταχωρήσεις αυξάνονται με εκθετικό βαθμό. Ανάγκη εργαλείων ανάλυσης δεδομένων.
. PubMed περιλαμβάνει πάνω από 14M περιλήψεις βιοιατρικών άρθρων (από το 1950). GenBank. 28 GBps (δισεκατομμύρια ζεύγη βάσεων) Trembl. 1 M καταχωρήσεις (16-Ιαν-2004) Οι καταχωρήσεις αυξάνονται με εκθετικό βαθμό. Ανάγκη εργαλείων ανάλυσης δεδομένων.")
5
Στόχοι μαθήματος Βιοπληροφορικής α’
Κατανόηση των πληροφοριακών συστημάτων διαχείρισης βιολογικών πληροφοριών Γνωριμία με εργαλεία ανάλυσης των δεδομένων Ανάπτυξη και εφαρμογή αλγορίθμων στα προβλήματα γενετικής

6
Στόχοι μαθήματος Βιοπληροφορικής β’
Εφαρμοσμένη βιοπληροφορική επαφή και γνωριμία με Εργαλεία και βάσεις. Αλγοριθμική βιοπληροφορική Ανάλυση, μελέτη και σχεδίαση αλγορίθμων Η προσέγγιση μας, συνδυασμός δύο μεθόδων.

7
Στόχοι μαθήματος Βιοπληροφορικής γ’
Εργαστήρια 9 εργαστήρια, λύση ασκήσεων με χαρτί και μολύβι, προγραμματισμός 7 ασκήσεις, που θα αξιολογηθούν (βασικά θέματα από τη θεωρία) 1 εργασία (ομαδική) Φροντιστήρια Ανάλογα με τις ανάγκες Αξιολόγηση Εργαστηριακές ασκήσεις/Εργασία 40% Εξέταση ημιεξαμήνου % (18/3) Τελική εξέταση %
 1 εργασία (ομαδική) Φροντιστήρια. Ανάλογα με τις ανάγκες. Αξιολόγηση. Εργαστηριακές ασκήσεις/Εργασία 40% Εξέταση ημιεξαμήνου 20% (18/3) Τελική εξέταση 40%")
8
Θέματα Εισαγωγή στη βιοπληροφορική Συλλογή και αποθήκευση ακολουθιών
Alignment ζεύγους ακολουθιών Multiple Sequence Alignment Πρόβλεψη δευτερεύουσας δομής πρωτεϊνών Εισαγωγή στην ανάλυση δεδομένων από microarrays Φυλογενετική πρόβλεψη Έλεγχος βάσεων για όμοιες ακολουθίες

9
Προτεινόμενες πηγές Bioinformatics: Sequence and Genome Analysis, David Mount, Cold Spring Harbor Laboratory Press, 2001, Introduction to Bioinformatics, Arthur M. Lesk, Oxford, 2002, (μπορείτε να κατεβάσετε το κεφ. 1) Δοκιμάστε στο Η ιστοσελίδα του μαθήματος, σύντομα κοντά σας...
 Δοκιμάστε στο. Η ιστοσελίδα του μαθήματος, σύντομα κοντά σας...")
10
Εργαλεία/Αλγόριθμοι Δυναμικός προγραμματισμός (για sequence alignment). Τεχνητά Νευρωνικά Δίκτυα (για κατασκευή μοντέλων πρόβλεψης τριδιάστατης δομής) Τεχνικές clustering για ομαδοποίηση gene expression data Τεχνικές text data mining για εξαγωγή πληροφορίας από συλλογές κειμένων. Matlab Perl/C
 Τεχνικές clustering για ομαδοποίηση gene expression data. Τεχνικές text data mining για εξαγωγή πληροφορίας από συλλογές κειμένων. Matlab. Perl/C.")
11
Στοιχειώδη Μοριακής βιολογίας
Στοιχειώδη Μοριακής βιολογίας

12
Στοιχειώδεις γνώσεις Μοριακής Βιολογίας
Για την κατανόηση των πληροφοριακών συστημάτων διαχείρισης βιολογικών πληροφοριών που γίνεται με την Βιοπληροφορικής πρέπει πρωταρχικά να γίνουν κατανοητές βασικές έννοιες της Μοριακής Βιολογίας. Ακολουθεί μια ανασκόπηση-υπενθύμιση βασικών εννοιών της μοριακής βιολογίας

13
Μοριακή βιολογία Δομικό στοιχείο κάθε οργανισμού είναι το κύτταρο.
Δομικό στοιχείο κάθε οργανισμού είναι το κύτταρο. Το κύτταρο πραγματοποιεί τις λειτουργίες του σύμφωνα με μια σειρά πληροφοριών που έχει κληρονομήσει από τους προγόνους του. Οι πληροφορίες αυτές είναι καταγραμμένες στο DNA που βρίσκεται στον πυρήνα του κυττάρου και είναι το γενετικό υλικό.

14
Το ζωικό κύτταρο

15
Μοριακή βιολογία Το συνολικό DNA σε κάθε διπλοειδές κύτταρο του ανθρώπου έχει μήκος περίπου 2 μέτρα και συσπειρώνεται σε τέτοιο βαθμό ώστε να χωράει στον πυρήνα του κυττάρου που έχει διάμετρο δέκα εκατομμυριοστά του μέτρου

16
Ποίες οι λειτουργίες του DNA;
Το DNA προσδιορίζει την παραγωγή των διαφόρων ειδών RNA και μέσω αυτών των πρωτεϊνών. Οι πρωτεΐνες είναι υπεύθυνες για τα βασικά δομικά και λειτουργικά χαρακτηριστικά των κυττάρων.

17
Τι ακριβώς είναι το DNA;
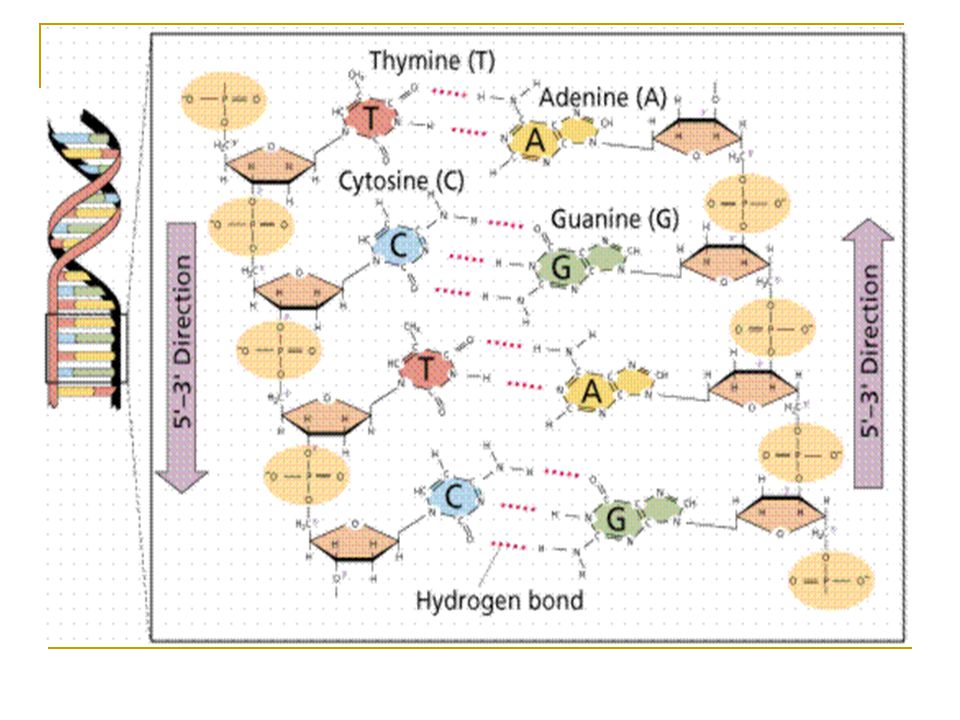
Το DNA είναι το Δεοξυριβονουκλεϊνικό οξύ. Deoxyribonucleic Acid Είναι δυο πολυνουκλεϊνικές αλυσίδες που σχηματίζουν στο χώρο μια δεξιόστροφη διπλή έλικα. Η ανακάλυψη της διπλής έλικας του DNA έγινε μόλις το 1953 από τους Watson και Crick γεγονός για το οποίο τους απονεμήθηκε βραβείο Νόμπελ. Watson και Crick

18
Τι ακριβώς είναι το DNA;
Αποτελείται από νουκλεοτίδια. Τα νουκλεοτίδια αποτελούνται από μια πεντόζη,τη δεοξυριβόζη η οποία είναι ενωμένη με μία φωσφορική ομάδα και μία αζωτούχο βάση. Το μόνο που διαφέρει το ένα νουκλεοτίδιο με το άλλο είναι η αζωτούχα βάση με την οποία είναι συνδεδεμένο.

19
Τι ακριβώς είναι το DNA;
Α - Αδενίνη (Adenine) G - Γουανίνη (Guanine) T - Θυμίνη (Thymine) C - Κυτοσίνη (Cytosine)
 G - Γουανίνη (Guanine) T - Θυμίνη (Thymine) C - Κυτοσίνη (Cytosine)")
20
Νουκλεοτίδιο του DNA

21
Τι ακριβώς είναι το DNA;
Τα νουκλεοτίδια αυτά συνδέονται μεταξύ τους σχηματίζοντας μια πολυνουκλεοτιδική αλυσίδα. Το DNA αποτελείται από δύο τέτοιες αλυσίδες συνδεδεμένες μεταξύ τους σχηματίζοντας έλικα. Οι αζωτούχες βάσεις της μίας αλυσίδας συνδέονται με τις βάσεις της άλλης σύμφωνα με τον κανόνα της συμπληρωματικότητας.

22
Τι ακριβώς είναι το DNA;
Η Αδενίνη συνδέεται μόνο με τη Θυμίνη και αντίστροφα(Α-Τ, Τ-Α) ενώ η κυτοσίνη συνδέεται μόνο με τη Γουανίνη και αντίστροφα (G-C, C-G) Οι δυο αλυσίδες είναι συμπληρωματικές και αντιπαράλληλες. Η συμπληρωματικότητα έχει μεγάλη σημασία στον αυτοδιπλασιασμό του DNA.
 ενώ η κυτοσίνη συνδέεται μόνο με τη Γουανίνη και αντίστροφα (G-C, C-G) Οι δυο αλυσίδες είναι συμπληρωματικές και αντιπαράλληλες. Η συμπληρωματικότητα έχει μεγάλη σημασία στον αυτοδιπλασιασμό του DNA.")
24
Λειτουργίες DNA Το DNA έχει τη δυνατότητα να αυτοδιπλασιάζεται, να αντιγράφεται καθώς και να μεταγράφεται. H αντιγραφή γίνεται με ξετύλιγμα του DNA και απέναντι από τις βάσεις των μητρικών αλυσίδων προσθέτονται νέες συμπληρωματικές τους και έτσι δημιουργούνται δύο θυγατρικές αλυσίδες DNA.

25
Αντιγραφή DNA

26
Κεντρικό δόγμα της μοριακής βιολογίας
O F.Crick διατύπωσε το 1958 το κεντρικό δόγμα της μοριακής βιολογίας το οποίο αφορά τη ροή της γενετικής πληροφορίας Το DNA με τη διαδικασία της μεταγραφής μεταφέρει την πληροφορία του στο RNA. To RNA μεταφέρει τη πληροφορία με τη διαδικασία της μετάφρασης στις πρωτεΐνες . DNA RNA πρωτεΐνες

27
Τι είναι το RNA; Το RNA είναι το ριβονουκλεϊνικό οξύ (Ribonucleic acid) το οποίο αποτελείται κι αυτό από νουκλεϊνικά οξέα με τη διαφορά ότι οι αζωτούχες βάσεις του περιέχουν την Ουρακίλη U (Uracil) αντί της θυμίνης Τ. Υπάρχει αντιστοιχία ανάμεσα στις βάσεις του DNA και του RNA : A-U,G-C,C-G,T-A To RNA δημιουργείται από τα μόρια DNA κατά τη διαδικασία της μεταγραφής.
 το οποίο αποτελείται κι αυτό από νουκλεϊνικά οξέα με τη διαφορά ότι οι αζωτούχες βάσεις του περιέχουν την Ουρακίλη U (Uracil) αντί της θυμίνης Τ. Υπάρχει αντιστοιχία ανάμεσα στις βάσεις του DNA και του RNA : A-U,G-C,C-G,T-A. To RNA δημιουργείται από τα μόρια DNA κατά τη διαδικασία της μεταγραφής.")
28
Ροή γενετικής πληροφορίας
Η γενετική πληροφορία είναι η καθορισμένη σειρά βάσεων του DNA η οποία σειρά είναι αυτό που διαφοροποιεί τη μια αλυσίδα DNA από την άλλη. Βρίσκεται στα γονίδια. Το κάθε ανθρώπινο κύτταρο περιέχει γύρω στα γονίδια. Τα γονίδια δια μέσου της μεταγραφής και της μετάφρασης καθορίζουν τη σειρά των αμινοξέων που θα δημιουργήσουν την πρωτεΐνη.

29
Μετατροπή πληροφορίας DNA σε πρωτεΐνες
Γίνεται με τις διαδικασίες Μεταγραφής και Μετάφρασης Κατά τη μεταγραφή παράγονται τρία είδη RNA: 1. m RNA 2. t RNA 3. snRNA

30
Μετατροπή πληροφορίας DNA σε πρωτεΐνες
To m RNA (messenger RNA) περιέχει την πληροφορία του DNA που την αποκτά με την συμπληρωματική αντιστοιχία των βάσεων του DNA με τις δικές του ξετυλίγοντας τη διπλή έλικα του DNA. Αφού πάρει την πληροφορία την μεταφέρει στο ριβόσωμα όπου θα γίνει η πρωτεϊνοσύνθεση.
 περιέχει την πληροφορία του DNA που την αποκτά με την συμπληρωματική αντιστοιχία των βάσεων του DNA με τις δικές του ξετυλίγοντας τη διπλή έλικα του DNA. Αφού πάρει την πληροφορία την μεταφέρει στο ριβόσωμα όπου θα γίνει η πρωτεϊνοσύνθεση.")
31
Μεταγραφή DNA

32
Μετατροπή πληροφορίας DNA σε πρωτεΐνες
Έτσι με το τέλος της μεταγραφής η αλληλουχία (σειρά) των βάσεων του m RNA είναι ακριβώς η ίδια με την αλληλουχία των βάσεων του DNA με τη μόνη διαφορά ότι στη θέση της Τ (Θυμίνης) υπάρχει η U (Ουρακίλη).
 των βάσεων του m RNA είναι ακριβώς η ίδια με την αλληλουχία των βάσεων του DNA με τη μόνη διαφορά ότι στη θέση της Τ (Θυμίνης) υπάρχει η U (Ουρακίλη).")
33
Πρωτεϊνοσύνθεση Η αντιστοίχιση των νουκλεοτιδίων του m RNA με τα αμινοξέα των πρωτεϊνών γίνεται μέσω του γενετικού κώδικα. Η αλληλουχία των βάσεων του m RNA καθορίζει την αλληλουχία των αμινοξέων στις πρωτεΐνες. Κάθε 3 βάσεις του m RNA κωδικοποιούν ένα αμινοξύ. Για αυτό το λόγο ο γενετικός κώδικας ονομάζεται και κώδικας τριπλέτας. Έχει τρία στάδια. Έναρξη, επιμήκυνση και λήξη.

34
Πρωτεϊνοσύνθεση

35
Πρωτεϊνοσύνθεση Έναρξη: Σύνδεση m RNA με ριβόσωμα. Το t RNA μεταφέρει το πρώτο αμινοξύ στην τριπλέτα (κωδικόνιο) έναρξης. Επιμήκυνση: Τα t RNA μεταφέρουν τα αμινοξέα που αντιστοιχούν στα κωδικόνια τα οποία συνδέονται μεταξύ τους. Λήξη: Στο κωδικόνιο λήξης σταματά η Πρωτεϊνοσύνθεση και ελευθερώνεται η πολυπεπτιδική αλυσίδα.

36
Γενετικός κώδικας

37
Καρυότυπος ανθρώπου Ανθρώπινο γονιδίωμα σε ένα γαμέτη αποτελείται από 3x10^8 ζεύγη βάσεων DNA που είναι οργανωμένα σε 23 χρωματοσώματα. Τα χρωματοσώματα ταξινομούνται σε ζεύγη κατά ελαττούμενο μέγεθος.22 μορφολογικά και το 23ο φυλετικό. ΧΥ στον άντρα και ΧΧ στη γυναίκα.

38
Τέλος ανασκόπησης της μοριακής βιολογίας
Τέλος ανασκόπησης της μοριακής βιολογίας

39
Περιήγηση στα θέματα

40
1: Portals

42
2: Πρωτεϊνες Αν δοθεί η ακολουθία των αμινοξέων, μπορούμε να προβλέψουμε την τριδιάστατη δομή της πρωτεϊνης? Δηλαδή αν δοθεί το 1 mmkmegialk krlswisvcl lvlvsaagml fstaaktets shkahteaqv intfdgvady 61 lqtyhklpdn yitkseaqal gwvaskgnla dvapgksigg difsnregkl pgksgrtwre 121 adinytsgfr nsdrilyssd wliykttdhy qtftkir Μπορούμε να πάρουμε με υπολογιστικές μεθόδους τη δομή που φαίνεται στην επόμενη διαφάνεια;

43
Βασικές δομές πρωτεϊνών
sheets helices

44
Γιατί θέλουμε πρόβλεψη δομής πρωτεϊνης;
Διότι υπάρχουν πληροφορίες για πρωτεϊνες,πειραματικά καθορισμένες (Release 42.8 of 15-Jan-2004 of Swiss-Prot) και για 1M (Trembl) Ενώ υπάρχουν πληροφορίες για δομές πρωτεϊνών, πειραματικά καθορισμένες (Last Update: 20-Jan-2004 PDB Statistics). Δηλαδή υπάρχει πληροφορία για το 16.7% (2.4%) των πρωτεϊνών. Ο προσδιορισμός δομής είναι ακριβή μέθοδος (κρυσταλλογραφία). Πολύ σημαντική η τριδιάστατη δομή διότι προσδιορίζει λειτουργία και συνεπώς είναι σημαντικότατη για σχεδιασμό φαρμάκων.
 και για 1M (Trembl) Ενώ υπάρχουν πληροφορίες για δομές πρωτεϊνών, πειραματικά καθορισμένες (Last Update: 20-Jan-2004 PDB Statistics). Δηλαδή υπάρχει πληροφορία για το 16.7% (2.4%) των πρωτεϊνών. Ο προσδιορισμός δομής είναι ακριβή μέθοδος (κρυσταλλογραφία). Πολύ σημαντική η τριδιάστατη δομή διότι προσδιορίζει λειτουργία και συνεπώς είναι σημαντικότατη για σχεδιασμό φαρμάκων.")
45
Υπολογιστικές μέθοδοι πρόβλεψης τριδιάστατης δομής
Νευρωνικά δίκτυα

46
3: Alignment ακολουθιών
Ευθυγράμμιση δυο ακολουθιών είναι η διαδικασία σύγκρισης δυο ακολουθιών για εύρεση ατομικών χαρακτήρων ή προτύπων χαρακτήρων με την ίδια σειρά στις δύο ακολουθίες. Οι ακολουθίες μπορούν να αφορούν DNA ή πρωτεϊνες. Πχ. gctgaacg και ctataatc Find maximum degree of likeness Find minimum evolutionary distance

47
Alignment ακολουθιών Πχ. Έστω δύο πρωτεΐνες οι: gctgaacg και ctataatc. Πόσο όμοιες είναι; Ευθυγράμμιση με κενά 1: g c t g a - a - - c g - - c t - a t a a t c Ευθυγράμμιση χωρίς κενά: g c t g a a c g c t a t a a t c Ευθυγράμμιση με κενά 2: g c t g - a a - c g - c t a t a a t c -

48
Alignment ακολουθιών Μέτρα ομοιότητας (Hamming, Levenshein)
Αλγόριθμοι: Dot Plots, Δυναμικός προγραμματισμός Αποτίμηση της ευθυγράμμισης

49
Φυλογενετική Περιγραφή βιολογικών σχέσεων υπό μορφή δένδρου.
Πηγή ομοιότητας είναι ο κοινός πρόγονος (αλλά όχι πάντα). Για την κατασκευή του χρησιμοποιούμε alignments. Οι αριθμοί δηλώνουν την απόσταση (similarity)
. Για την κατασκευή του χρησιμοποιούμε alignments. Οι αριθμοί δηλώνουν την απόσταση (similarity)")
50
4. Φυλογενετική πρόβλεψη
Δηλαδή δοσμένης κάποιας DNA ή πρωτεϊνικής αλληλουχίας πως μπορούμε να εξαγάγουμε τις σχέσεις τις σχέσεις τους; Πχ. ΑΤCC, ATGC, TTCG, TCGG προκύπτει το ATCC ATGC TTCG TCGG

51
Εφαρμογές φυλογενετικής
Μελέτη αλλαγών σε σειρά οργανισμών Μελέτη της εξέλιξης μίας οικογένειας οργανισμών Παρακολούθηση αλλαγών σε είδη που μεταβάλλονται γρήγορα (π.χ. Ιοί) Εφαρμογές στην επιδημιολογία (αν ένα γονίδιο επιλέγεται).
 Εφαρμογές στην επιδημιολογία (αν ένα γονίδιο επιλέγεται).")
52
Φυλογενετική πρόβλεψη μέθοδοι
Clustering methods (ιεραρχικό clustering) Μειονέκτημα Βρίσκει πάντα evolutionary tree ακόμη και αν δεν υπάρχει Cladistic methods Maximum parsimony Fewest mutations Maximum likelyhood Probabilities to mutations Θεωρητικοί και πειραματικοί λόγοι μας οδηγούν στις cladistic Θα εξετάσουμε και υπολογιστική πολυπλοκότητα
 Μειονέκτημα Βρίσκει πάντα evolutionary tree ακόμη και αν δεν υπάρχει. Cladistic methods. Maximum parsimony. Fewest mutations. Maximum likelyhood. Probabilities to mutations. Θεωρητικοί και πειραματικοί λόγοι μας οδηγούν στις cladistic. Θα εξετάσουμε και υπολογιστική πολυπλοκότητα.")
53
Σενάριο ! Φανταστείτε ότι ένας νέος ιός προκαλεί μία θανατηφόρα επιδημία. Στο εργαστήριο οι βιολόγοι ανακαλύπτουν το γενετικό υλικό του ιού. Δηλαδή βρίσκουν τα νουκλεϊκά οξέα από τα οποία αποτελείται Κάτι του είδους: …aataatcgg …. Στην συνέχεια αναλαμβάνουν οι υπολογιστές...

54
Σενάριο υπολογιστική φάση α
Το γονιδίωμα του ιού συγκρίνεται με τις καταχωρήσεις μία βάσης (π.χ. GenBank) προκειμένου να εντοπιστούν ομοιότητες με άλλους παρόμοιους ιούς (10) Από την ακολουθία DNA, μπορούμε να συνάγουμε την ακολουθία αμινοξέων κάποιων πρωτεϊνών (01) Από τη σειρά των αμινοξέων μπορεί να υπολογιστεί η δομή ....
 προκειμένου να εντοπιστούν ομοιότητες με άλλους παρόμοιους ιούς (10) Από την ακολουθία DNA, μπορούμε να συνάγουμε την ακολουθία αμινοξέων κάποιων πρωτεϊνών (01) Από τη σειρά των αμινοξέων μπορεί να υπολογιστεί η δομή ....")
55
Σενάριο υπολογιστική φάση β
Έρευνα για παρόμοιες πρωτεΐνες (ως προς τη σειρά των αμινοξέων) (15) Παρόμοιες σειρές αμινοξέων δηλώνουν πρωτεΐνες με παρόμοια δομή (το αντίστροφο δεν ισχύει) Εαν βρεθούν, τότε πάμε Differential form, και homology modeling (25) Εαν δε βρεθούν, τότε ψάχνουμε με μοντέλα για τη δομή (50)
 (15) Παρόμοιες σειρές αμινοξέων δηλώνουν πρωτεΐνες με παρόμοια δομή (το αντίστροφο δεν ισχύει) Εαν βρεθούν, τότε πάμε Differential form, και homology modeling (25) Εαν δε βρεθούν, τότε ψάχνουμε με μοντέλα για τη δομή (50)")
56
Σενάριο Γνώση της δομής των πρωτεϊνών σχεδιασμός φαρμάκων
Οι πρωτεΐνες έχουν περιοχές στην επιφάνεια τους που μπορούν να χρησιμεύσουν για την ανάσχεση της δράσης τους. Ένα μικρό μόριο συμπληρωματικό ως προς την επιφάνεια και το φορτίο της επιβλαβούς πρωτεΐνης μπορεί να τη απενεργοποιήσει. Ένα τέτοιο μόριο θα σχεδιαστεί (50)
")
57
Το σενάριο αυτό σήμερα Το σημεία με βαθμό μεγαλύτερο του (30) αποτελούν αντικείμενο έρευνας.
 αποτελούν αντικείμενο έρευνας.")
58
Σχετικά με το σενάριο Παράδοξο Μεταγραφή από ακολουθία DNA σε αμινοξύ,
Απλή στην περιγραφή Απαιτεί εξαιρετικά πολύπλοκο μηχανισμό (tRNA, ribosomes) Folding of proteins (Δηλαδή η υιοθέτηση 3 διάστατης δομής) Πολύ δύσκολη στην περιγραφή Προκύπτει αυθόρμητα
 Folding of proteins (Δηλαδή η υιοθέτηση 3 διάστατης δομής) Πολύ δύσκολη στην περιγραφή. Προκύπτει αυθόρμητα.")
59
Κεντρικό Δόγμα Ακολουθία DNA προσδιορίζει ακολουθία πρωτεΐνης
Ακολουθία πρωτεΐνης προσδιορίζει δομή πρωτεΐνης Δομή πρωτεΐνης προσδιορίζει λειτουργία πρωτεΐνης.

60
Ερευνητικά Προγράμματα βιοπληροφορικής του τμήματος
GeneStream BioGrid ΕΡΩΤΗΜΑ

61
BioGrid Project IST (5o Πλαίσιο) www.bio-grid.net Partners:
City University (London) University of Groningen (NL) University of Cyprus (UCY) Medical Research Council (Cambridge, UK) ZooRobotics (NL)
 University of Groningen (NL) University of Cyprus (UCY) Medical Research Council (Cambridge, UK) ZooRobotics (NL)")
62
BioGrid ABSTRACT: The ambition of the BioGRID system is to conduct a trial for the introduction of a GRID approach in the biotechnology industry. The trial consists of two major steps: The integration of three existing technologies: Classification Server, PSIMAP & SpaceExplorer. The production of a working prototype. The project is focussed on the development of an information & knowledge GRID allowing knowledge discovery & access to multiple types of structured & unstructured data, effectively visualised & accessible in a structured data model. In the initial phase of the project, the required biotechnology domain was analysed & existing structures & standards identified. These results were used to create a logical information structure of the scientific area. In the current phase of the project, the three existing technologies are being integrated consecutively to the common data structure defined previously. This involves the implementing the logic of the metadata model with agent technology to source relevant data & position it in the developed & existing classifications.. The final phase of the project will be to benchmark & evaluate the BioGRID system in a real laboratory setting.

63
ExpressionSpace: SpaceExplorer InteractionSpace: PSIMAP PathwaySpace Literature Space: Classification Server

64
Current Status User requirements analysis, with use cases.
Development of domain & metadata models. Architecture diagram of bioGRID system. Algorithm optimisation for data analysis. Utilisation of distributed resources for pre-processing data. Intelligent agent-based data sourcing & mediating. Graphical representation of knowledge domain. First prototype showing integration of gene expression, protein interaction and document data. Current Status Expression Space Interaction

65
BioGRID Vision For the prototype, the BioGRID system integrates data from: Genomics - microarray data. Proteomics - Protein interactions data. Literature - Classified PubMed abstracts.

66
isation of target sequence
BioGrid Interaction data Metabolic pathway data Expression data Sequences Character- isation of target sequence Scientific literature

67
Computer does not “understand” data.
Challenges: Semantic Complexity: Computer does not “understand” data. DBs and systems cannot inter-operate. Computational complexity: Generating protein interaction map takes ca. 7 days. Analysing large sets of gene expression data can take up to an hour. Analysis of large text bodies complex. Solutions: Semantic Web: Global and local ontologies to capture metadata and facilitate semantic inter-operability. GRID technology: Transparent access to distributed resources. Agent technology: Personal information agent collecting and presenting relevant information on behalf of its user.

68
Genestream IST (5ο πλαίσιο) www.genestream.net Partners:
City University (London) Fraunhofer (Germany) University of Cyprus (UCY) Medical Research Council (Cambridge, UK) FORTH (Foundation for Research & Technology, Greece) ZooRobotics (NL)
 Fraunhofer (Germany) University of Cyprus (UCY) Medical Research Council (Cambridge, UK) FORTH (Foundation for Research & Technology, Greece) ZooRobotics (NL)")
69
Οντολογίες Μία οντολογία αποτελεί τυπική περιγραφή κάποιων εννοιών καθώς και των σχέσεων τους. Της «μόδας» για το semantic web Χρήσιμες για τον αυτόματο χειρισμό δεδομένων.

70
Ontologies used GO (Gene Ontology) www.geneontology.org
Purpose database annotation Grown out of databases Codifies knowledge in a domain Proteins in SwissProt database are annotated according to GO

71
GO hierarchical 3 separate hirarchies (DAG) Biological process
Cellular component Molecular function

72
Βιβλιογραφικές έρευνες
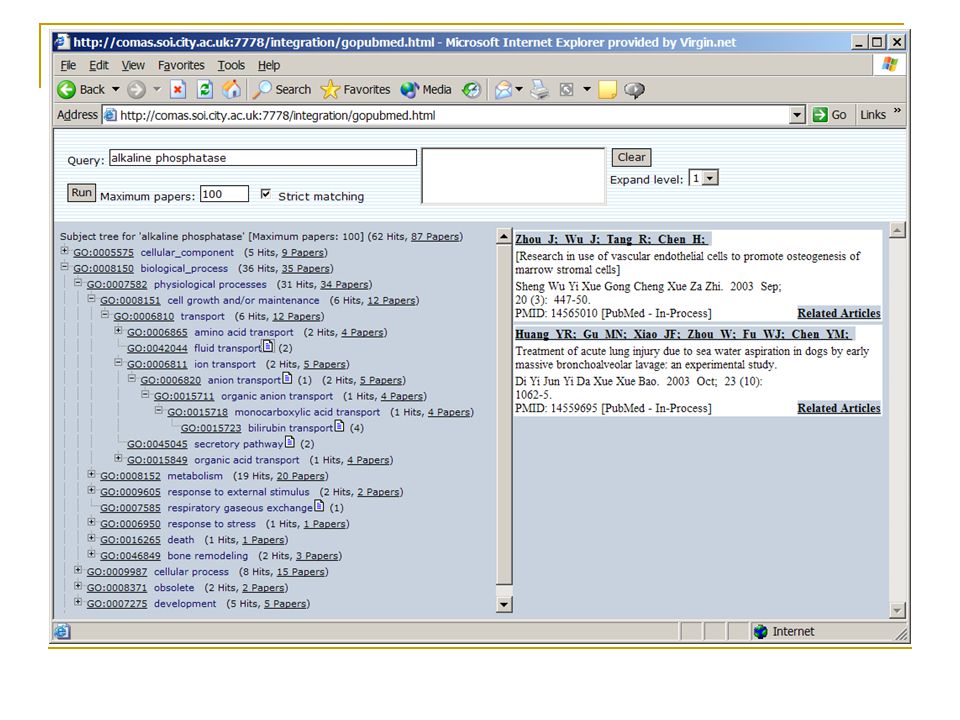
Η βάση PubMed έχει 12Μ περιλήψεις άρθρων από 4000 journals στον τομέα της βιοιατρικής Έχει interface στο οποίο ο χρήστης βάζει τους όρους που τον ενδιαφέρουν και παίρνει τα αποτελέσματα. Αλλά....

73
PubMed Τα αποτελέσματα μπορούν να είναι πάρα πολλά, ο χρήστης επικεντρώνεται σε πολύ λίγα που εμφανίζονται στην αρχή Προκειμένου να πάρεις καλά αποτελέσματα, πρέπει να δώσεις τα κατάλληλα keywords Λύση: Απεικόνιση των αποτελεσμάτων στην GO ontology, δηλαδή σε ένα δέντρο

74
Go PubMed Go + PubMed Χρήσιμο εάν δεν ξέρεις πολλά για τον τομέα που ψάχνεις, διότι το Go PubMed κατηγοριοποιεί τα αποτελέσματα και δίνει μία επισκόπηση του τομέα Χρήσιμο εάν θέλεις να δεις αποτελέσματα που βρίσκονται σε ευρύτερη κατηγορία. (Αδύνατο με το υπάρχον PubMed interface).
.")
76
Most prominent authors in a subject

77
Research profile of a prominent author

78
ΕΡΩΤΗΜΑ μέθοδοι εντοπισμού απαντήσεων σε συστήματα ερωταποκρίσεων για συλλογές εγγράφων βιοτεχνολογίας Απαντήσεις και όχι κείμενα Δηλαδή επιστρέφει το κομμάτι του κειμένου που σχετίζεται με την ερώτηση και όχι όλο το κείμενο

79
Μεθδολογία Υπολογιστική Γλωσσολογία Μηχανική μάθηση Σώμα κειμένων
για εκπαίδευση του μοντέλου Για έλεγχο του μοντέλου

80
Μεθοδολογία β Είναι σχετικά κατορθωτό για ερωτήσεις του είδους
Ποιός (αφορά πρόσωπα) Πότε έγινε κάτι (χρονικές ερωτήσεις) Αρκετά δύσκολο για τροπικές ερωτήσεις Τι προκαλεί την τάδε λειτουργία στο κύτταρο; Πως σχετίζονται δύο πρωτεϊνες; Σώμα κειμένων που θα χρησιμοποιηθεί: NCBI bookself (20 βιβλία σε ηλεκτρονική μορφή)
 Πότε έγινε κάτι (χρονικές ερωτήσεις) Αρκετά δύσκολο για τροπικές ερωτήσεις. Τι προκαλεί την τάδε λειτουργία στο κύτταρο; Πως σχετίζονται δύο πρωτεϊνες; Σώμα κειμένων που θα χρησιμοποιηθεί: NCBI bookself (20 βιβλία σε ηλεκτρονική μορφή)")
81
Παρόμοιες προσεγγίσεις
Σύστημα Suiseki Μπορώ να κατασκευάσω ένα χάρτη αλληλεπιδράσεων των πρωτεϊνών. Δηλαδή ένα γράφο, όπου κάθε κόμβος είναι μία πρωτεΐνη και κάθε ακμή δηλώνει αλληλεπιδράσεις. Σημαντικό πεδίο έρευνας Χρήσιμο εντέλει στο σχεδιασμό φαρμάκων

82
Suiseki Το σύστημα suiseki προσπαθεί να εξαγάγει τέτοιες πληροφορίες από κείμενα. Επιτυγχάνει αυτό με templates Π.χ. Prot1 <stop words>^n interacts/binds Prot2 Οι templates πρέπει να κατασκευαστούν από ανθρώπους. Δεν υπάρχει κατάλογος ονομάτων πρωτεϊνών (άρα πρέπει να εξαχθούν τα ονόματα τους). Υπάρχουν και υπολογιστικές μέθοδοι.
. Υπάρχουν και υπολογιστικές μέθοδοι.")
Παρόμοιες παρουσιάσεις

οξυριβο(ζο)νουκλεϊ(νι)κό οξύ (Deoxyribonucleic acid - DNA)>")

















